Heutzutage ist es ziemlich üblich, eine Datenbank auf einem anderen Server/Rechenzentrum zu replizieren, und in einigen Fällen ist es auch ein Muss. Es gibt verschiedene Gründe, Ihre Datenbanken in eine völlig separate Umgebung zu replizieren.
- Migrieren Sie zu einem anderen Rechenzentrum.
- Upgrade-Anforderungen (Hardware/Software).
- Bewahren Sie ein vollständig synchronisiertes Betriebssystem an einem Disaster Recovery (DR)-Standort, der jederzeit übernehmen kann
- Halten Sie eine Slave-Datenbank als Teil eines kostengünstigeren DR-Plans.
- Für Geolokalisierungsanforderungen (Daten müssen lokal in einem bestimmten Land vorliegen).
- Haben Sie eine Testumgebung.
- Zweck der Fehlerbehebung.
- Berichtsdatenbank.
Und es gibt verschiedene Möglichkeiten, diese Replikationsaufgabe auszuführen:
- Sichern/Wiederherstellen :Das Sichern einer Produktionsdatenbank und das Wiederherstellen auf einem neuen Server/einer neuen Umgebung ist die klassische Methode, aber es ist auch eine altmodische Methode, da Sie Ihre Daten nicht auf dem neuesten Stand halten und warten müssen für jeden Wiederherstellungsvorgang, wenn Sie aktuelle Daten benötigen. Wenn Sie einen Cluster (Master-Slave, Multi-Master) haben und ihn neu erstellen möchten, sollten Sie die ursprüngliche Sicherung wiederherstellen und dann die restlichen Knoten neu erstellen, was eine zeitaufwändige Aufgabe sein kann.
- Cluster klonen :Es ähnelt dem vorherigen, aber der Sicherungs- und Wiederherstellungsprozess gilt für den gesamten Cluster, nicht nur für einen bestimmten Datenbankserver. Auf diese Weise können Sie den gesamten Cluster in derselben Aufgabe klonen und müssen die restlichen Knoten nicht manuell neu erstellen. Diese Methode hat immer noch das Problem, Daten zwischen Klonen aktuell zu halten.
- Replikation :Dieser Weg beinhaltet die Sicherungs-/Wiederherstellungsoption, aber nach der anfänglichen Wiederherstellung hält der Replikationsprozess Ihre Daten mit dem Master-Knoten synchronisiert. Auf diese Weise müssen Sie bei einem Datenbank-Cluster die Sicherung auf einem Knoten wiederherstellen und alle Knoten manuell neu erstellen.
In diesem Blog werden wir eine neue Funktion von ClusterControl 1.7.4 sehen, die es Ihnen ermöglicht, eine Mischung aus der zuvor erwähnten Methode zu verwenden, um diese Aufgabe zu verbessern.
Was ist Cluster-zu-Cluster-Replikation?
Die Replikation zwischen zwei Clustern ist nicht dasselbe wie die Erweiterung eines Clusters zur Ausführung über zwei Rechenzentren. Beim Einrichten der Replikation zwischen zwei Clustern haben wir tatsächlich zwei separate Systeme, die autonom arbeiten können. Replikation wird verwendet, um sie synchron zu halten, sodass das Slave-System einen aktualisierten Zustand hat und übernehmen kann.
Ab ClusterControl 1.7.4 ist es möglich, einen neuen Cluster durch direktes Klonen eines laufenden Quellclusters oder durch Verwenden einer aktuellen Sicherung des Quellclusters zu erstellen.
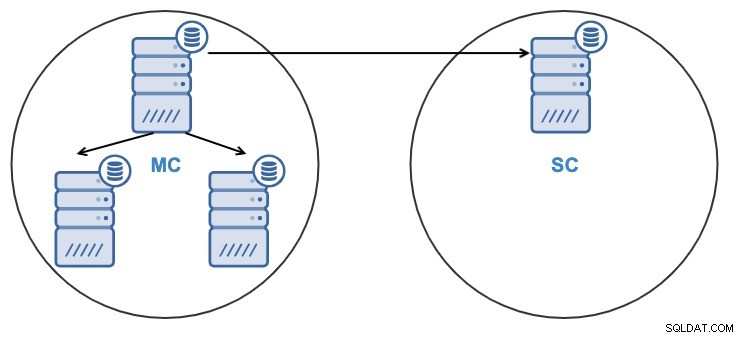
Nach dem Klonen des Clusters haben Sie einen Slave-Cluster (SC), der Daten empfängt, und einen Master-Cluster (MC), der Änderungen an den Slave-Cluster sendet.
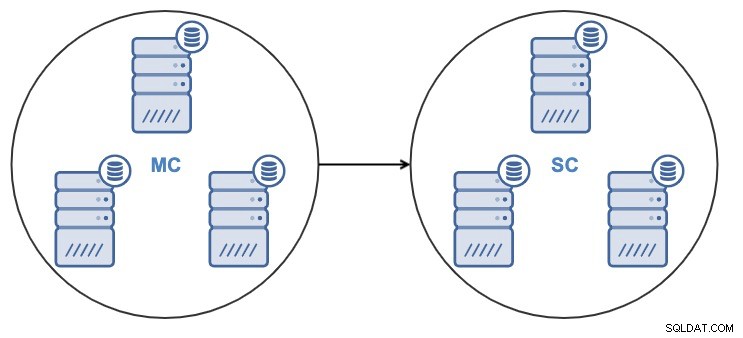
ClusterControl unterstützt die Cluster-zu-Cluster-Replikation für die folgenden Clustertypen:
- Percona XtraDB Cluster Version 5.6.x und höher.
- MariaDB Galera Cluster Version 10.x und höher.
- PostgreSQL 9.6 und höher.
Cluster-zu-Cluster-Replikation für Percona XtraDB / MariaDB Galera Cluster
Für MySQL-basierte Engines ist GTID erforderlich, um diese Funktion zu verwenden, und es wird eine asynchrone Replikation zwischen dem Master- und dem Slave-Cluster verwendet.
Es müssen einige Aktionen durchgeführt werden, um den aktuellen Cluster für diesen Job vorzubereiten. Zunächst müssen auf mindestens einem Knoten im aktuellen Cluster die Binärprotokolle aktiviert sein. Anschließend müssen Sie den im Datenbankknoten konfigurierten Backup-Benutzer in der ClusterControl-Konfigurationsdatei hinzufügen, die für Verwaltungsaufgaben verwendet wird. Alle diese Aktionen können mithilfe der ClusterControl-Benutzeroberfläche oder der ClusterControl-CLI ausgeführt werden.
Jetzt können Sie die Percona XtraDB/MariaDB Galera Cluster-zu-Cluster-Replikation erstellen. Wenn der Job abgeschlossen ist, haben Sie:
- Ein Knoten im Slave-Cluster wird von einem Knoten im Master-Cluster replizieren.
- Die Replikation erfolgt bidirektional zwischen den Clustern.
- Alle Knoten im Slave-Cluster sind standardmäßig schreibgeschützt. Es ist möglich, das Nur-Lesen-Flag auf den Knoten einzeln zu deaktivieren.
- Aktiv-Aktiv-Clustering wird nur empfohlen, wenn Anwendungen nur unzusammenhängende Datensätze auf einem der beiden Cluster berühren, da die Engine keine Konflikterkennung oder -lösung bietet.
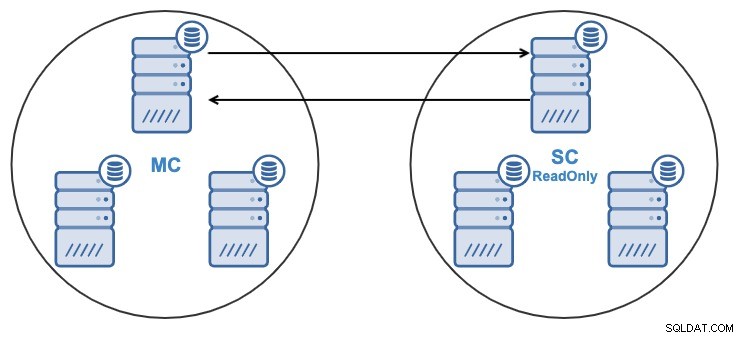
Sowohl über die ClusterControl-Benutzeroberfläche als auch über die ClusterControl-CLI können Sie:
- Diesen Replikationscluster erstellen.
- Aktivieren Sie die Aktiv-Aktiv-Konfiguration.
- Cluster-Topologie ändern.
- Erstellen Sie einen Replikationscluster neu.
- Stoppen/Starten Sie einen Replikations-Slave.
- Replication Slave zurücksetzen (nur mit ClusterControl CLI atm implementiert).
Überlegungen
- Der Backup-Benutzer muss manuell in der ClusterControl-Konfigurationsdatei hinzugefügt werden.
- Die Anmeldedaten des Sicherungsbenutzers müssen im aktuellen und im neuen Cluster identisch sein.
- Das beim Erstellen des Slave-Clusters angegebene MySQL-Root-Passwort muss dasselbe sein wie das auf dem Master-Cluster verwendete Root-Passwort.
Bekannte Einschränkungen
- Automatisches Failover wird noch nicht unterstützt. Wenn der Master ausfällt, liegt es in der Verantwortung des Administrators, ein Failover auf einen anderen Master durchzuführen.
- Es ist nur möglich, einen Replikations-Slave von der ClusterControl-CLI aus „zurückzusetzen“, da es noch nicht in der ClusterControl-Benutzeroberfläche implementiert ist.
- Es ist nur möglich, einen Cluster neu aufzubauen, der sich im schreibgeschützten Modus befindet. Alle Knoten in einem Cluster müssen schreibgeschützt sein, um als schreibgeschützter Cluster zu zählen.
Cluster-zu-Cluster-Replikation für PostgreSQL
ClusterControl-Cluster-zu-Cluster-Replikation wird auf PostgreSQL mit Streaming-Replikation unterstützt.
Als Voraussetzung muss ein PostgreSQL-Server mit der ClusterControl-Rolle „Master“ vorhanden sein, und wenn Sie den Slave-Cluster einrichten, müssen die Admin-Anmeldeinformationen mit denen des Master-Clusters identisch sein.
Jetzt können Sie die PostgreSQL-Cluster-zu-Cluster-Replikation erstellen. Wenn der Job abgeschlossen ist, haben Sie:
- Ein Knoten im Slave-Cluster wird von einem Knoten im Master-Cluster replizieren.
- Die Replikation erfolgt unidirektional zwischen den Clustern.
- Der Knoten im Slave-Cluster ist schreibgeschützt.
Sowohl über die ClusterControl-Benutzeroberfläche als auch über die ClusterControl-CLI können Sie:
- Diesen Replikationscluster erstellen.
- Erstellen Sie einen Replikationscluster neu.
- Stoppen/Starten Sie einen Replikations-Slave.
Gegenleistung
- Die Admin-Zugangsdaten müssen im Master- und Slave-Cluster identisch sein.
Bekannte Einschränkungen
- Die maximale Größe des Slave-Clusters ist ein Knoten.
- Der Slave-Cluster kann nicht von einem Backup bereitgestellt werden.
- Topologieänderungen werden nicht unterstützt.
- Nur unidirektionale Replikation wird unterstützt.
Fazit
Mit dieser neuen ClusterControl-Funktion müssen Sie nicht jeden Schritt zum Erstellen einer Cluster-Replikation separat oder manuell ausführen, und als Ergebnis ihrer Verwendung sparen Sie Zeit und Mühe. Probieren Sie es aus!