Heutzutage sind Datenbanken, die sich über mehrere Clouds erstrecken, weit verbreitet. Sie versprechen eine hohe Verfügbarkeit und die Möglichkeit, Notfallwiederherstellungsverfahren einfach zu implementieren. Sie sind auch eine Methode, um eine Anbieterbindung zu vermeiden:Wenn Sie Ihre Datenbankumgebung so gestalten, dass sie über mehrere Cloud-Anbieter hinweg betrieben werden kann, sind Sie höchstwahrscheinlich nicht an Funktionen und Implementierungen gebunden, die für einen bestimmten Anbieter spezifisch sind. Dies erleichtert Ihnen das Hinzufügen eines weiteren Infrastrukturanbieters zu Ihrer Umgebung, sei es eine andere Cloud oder ein On-Premises-Setup. Eine solche Flexibilität ist sehr wichtig, da es einen harten Wettbewerb zwischen Cloud-Anbietern gibt und die Migration von einem zum anderen durchaus machbar sein könnte, wenn dies durch eine Reduzierung der Kosten unterstützt würde.
Wenn Sie Ihre Infrastruktur über mehrere Rechenzentren (vom selben Anbieter oder nicht, das spielt keine Rolle) erstrecken, müssen ernsthafte Probleme gelöst werden. Wie kann man die gesamte Infrastruktur so gestalten, dass die Daten sicher sind? Wie gehen Sie mit Herausforderungen um, denen Sie sich bei der Arbeit in einer Multi-Cloud-Umgebung stellen müssen? In diesem Blog werfen wir einen Blick auf einen, aber wohl den schwerwiegendsten – das Potenzial eines Split-Brains. Was bedeutet das? Lassen Sie uns ein wenig darüber nachdenken, was Split-Brain ist.
Was ist „Split-Brain“?
Split-Brain ist ein Zustand, in dem eine Umgebung, die aus mehreren Knoten besteht, unter Netzwerkpartitionierung leidet und in mehrere Segmente aufgeteilt wurde, die keinen Kontakt miteinander haben. Der einfachste Fall sieht so aus:
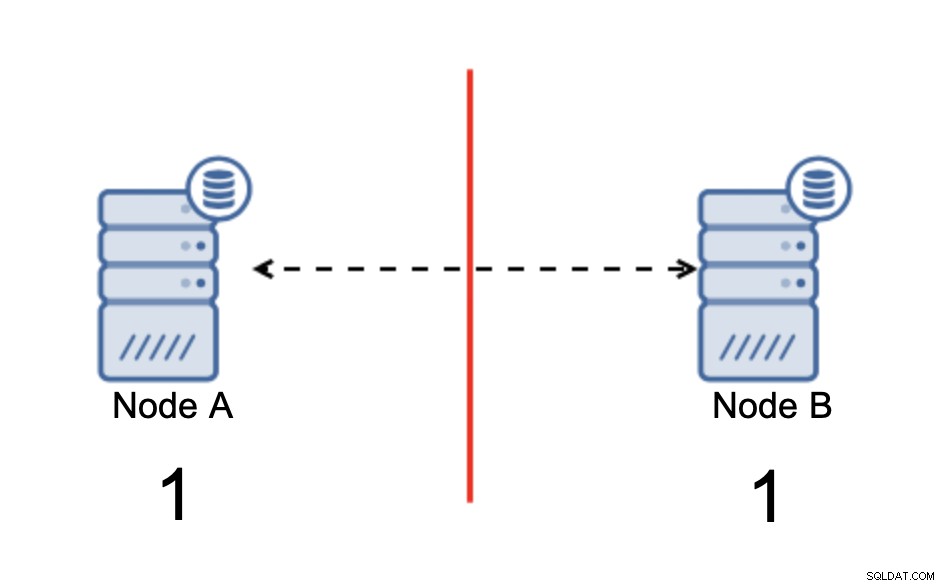
Wir haben zwei Knoten, A und B, die über ein Netzwerk mit bi verbunden sind -direktionale asynchrone Replikation. Dann wird die Netzwerkverbindung zwischen diesen Knoten getrennt. Infolgedessen können sich beide Knoten nicht miteinander verbinden und Änderungen, die auf Knoten A ausgeführt werden, können nicht an Knoten B übertragen werden und umgekehrt. Beide Knoten, A und B, sind aktiv und akzeptieren Verbindungen, sie können nur keine Daten austauschen. Dies kann zu schwerwiegenden Problemen führen, da die Anwendung möglicherweise Änderungen an beiden Knoten vornimmt und erwartet, den vollständigen Status der Datenbank anzuzeigen, während sie tatsächlich nur mit einem teilweise bekannten Datenstatus arbeitet. Infolgedessen können von der Anwendung falsche Aktionen ausgeführt werden, dem Benutzer können falsche Ergebnisse angezeigt werden und so weiter. Wir denken, dass es klar ist, dass Split-Brain ein potenziell sehr gefährlicher Zustand ist, und eine der Prioritäten wäre, bis zu einem gewissen Grad damit umzugehen. Was kann man dagegen tun?
Wie man Split-Brain vermeidet
Kurz gesagt, es kommt darauf an. Das Hauptproblem, das behandelt werden muss, ist die Tatsache, dass Knoten betriebsbereit sind, aber keine Konnektivität zwischen ihnen besteht, weshalb sie den Status des anderen Knotens nicht kennen. Im Allgemeinen hat die asynchrone MySQL-Replikation keinen Mechanismus, der das Problem des Split-Brain intern lösen würde. Sie können versuchen, einige Lösungen zu implementieren, die Ihnen helfen, Split-Brain zu vermeiden, aber sie sind mit Einschränkungen verbunden oder lösen das Problem immer noch nicht vollständig.
Wenn wir uns von der asynchronen Replikation entfernen, sieht es anders aus. MySQL Group Replication und MySQL Galera Cluster sind Technologien, die von der Build-it-Cluster-Awareness profitieren. Diese beiden Lösungen halten die Kommunikation zwischen den Knoten aufrecht und stellen sicher, dass der Cluster den Zustand der Knoten kennt. Sie implementieren einen Quorum-Mechanismus, der bestimmt, ob Cluster betriebsbereit sind oder nicht.
Lassen Sie uns diese beiden Lösungen (asynchrone Replikation und Quorum-basierte Cluster) genauer besprechen.
Quorum-basiertes Clustering
Wir werden hier nicht auf die Implementierungsunterschiede zwischen MySQL Galera Cluster und MySQL Group Replication eingehen, wir werden uns auf die Grundidee hinter dem Quorum-basierten Ansatz konzentrieren und darauf, wie er entwickelt wurde, um das Problem zu lösen Split-Brain in Ihrem Cluster.
Die Quintessenz ist, dass ein Cluster, um zu funktionieren, erfordert, dass die Mehrheit seiner Knoten verfügbar ist. Mit dieser Anforderung können wir sicher sein, dass die Minderheit den Rest des Clusters niemals wirklich beeinflussen kann, da die Minderheit keine Aktionen ausführen können sollte. Das bedeutet auch, dass ein Cluster mindestens drei Knoten haben sollte, um den Ausfall eines Knotens bewältigen zu können. Wenn Sie nur zwei Knoten haben:
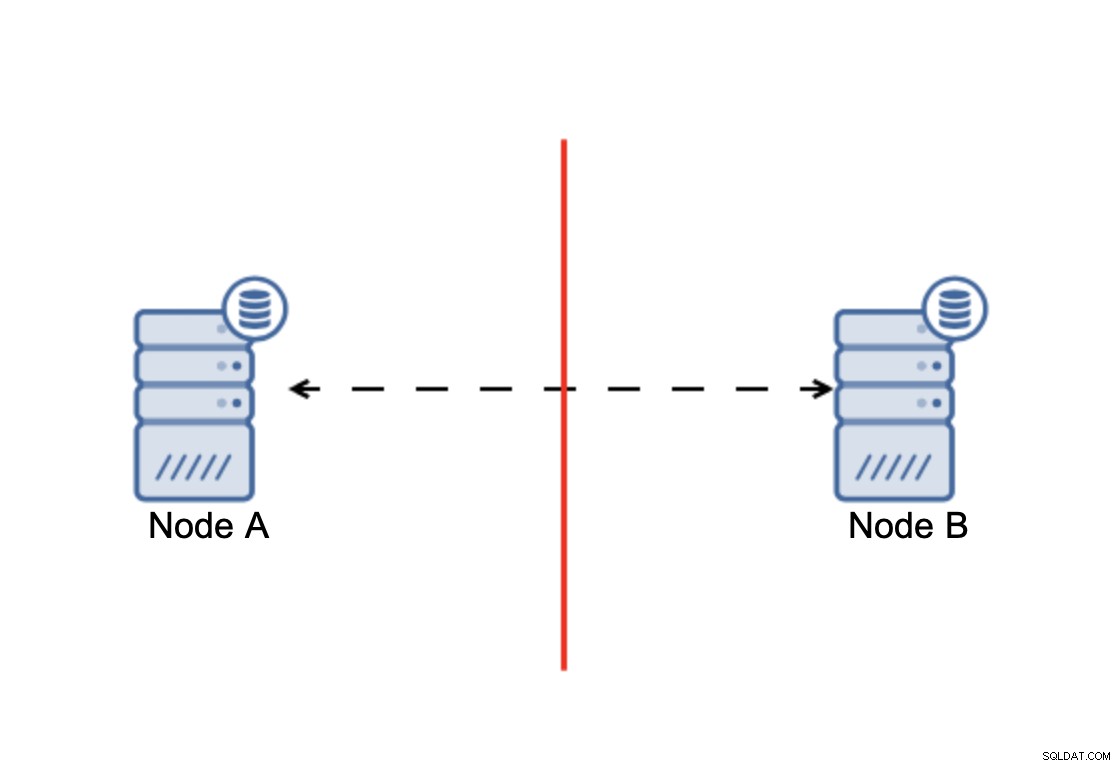
Bei einer Netzwerkaufteilung erhalten Sie am Ende zwei Teile der Cluster, die jeweils aus genau 50 % der gesamten Knoten im Cluster bestehen. Keiner dieser Teile hat eine Mehrheit. Wenn Sie jedoch drei Knoten haben, sind die Dinge anders:
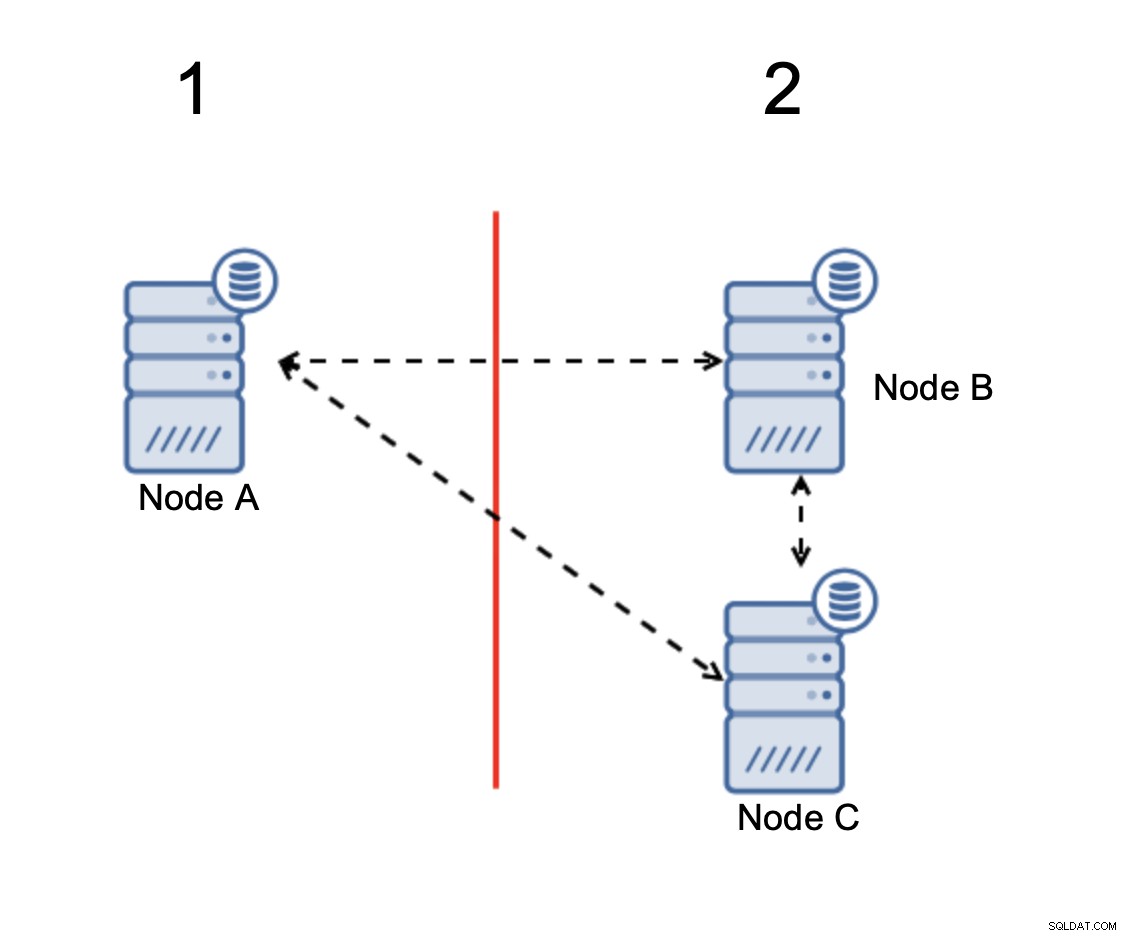
Knoten B und C haben die Mehrheit:Dieser Teil besteht aus zwei ausgehenden Knoten von drei somit kann es weiter betrieben werden. Andererseits stellt Knoten A nur die 33 % der Knoten im Cluster dar, daher hat er keine Mehrheit und wird den Verkehr einstellen, um die Gehirnteilung zu vermeiden.
Bei einer solchen Implementierung ist es sehr unwahrscheinlich, dass Split-Brain auftritt (es müsste durch einige seltsame und unerwartete Netzwerkzustände, Race-Bedingungen oder eindeutige Fehler im Clustering-Code eingeführt werden. Obwohl es nicht unmöglich ist, darauf zu stoßen Unter solchen Bedingungen ist die Verwendung einer der quorumbasierten Lösungen die beste Option, um die derzeitige Spaltung des Gehirns zu vermeiden.
Asynchrone Replikation
Die asynchrone Replikation ist zwar nicht die ideale Wahl, wenn es um den Umgang mit Split-Brain geht, aber dennoch eine praktikable Option. Es gibt mehrere Dinge, die Sie berücksichtigen sollten, bevor Sie eine Multi-Cloud-Datenbank mit asynchroner Replikation implementieren.
Zuerst Failover. Die asynchrone Replikation kommt mit einem Schreiber – nur der Master sollte beschreibbar sein und andere Knoten sollten nur schreibgeschützten Datenverkehr bedienen. Die Herausforderung besteht darin, wie man mit dem Master-Fehler umgeht?
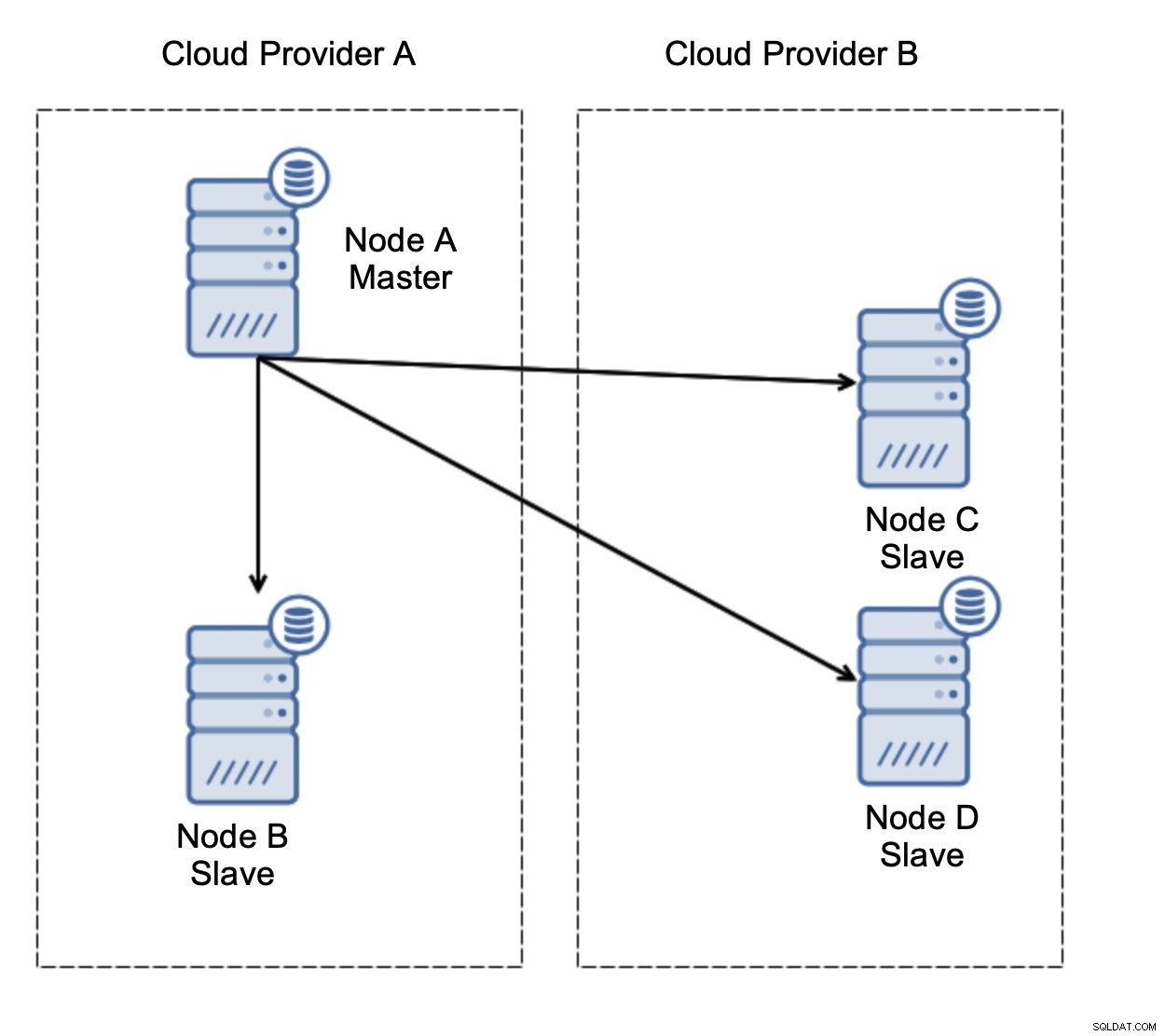
Betrachten wir die Einrichtung wie im Diagramm oben. Wir haben zwei Cloud-Anbieter, jeweils zwei Knoten. Provider A hostet auch den Master. Was soll passieren, wenn der Master ausfällt? Einer der Slaves sollte befördert werden, um sicherzustellen, dass die Datenbank weiterhin betriebsbereit ist. Idealerweise sollte es ein automatisierter Prozess sein, um die Zeit zu reduzieren, die benötigt wird, um die Datenbank in den Betriebszustand zu versetzen. Was würde aber passieren, wenn es eine Netzwerkpartitionierung geben würde? Wie sollen wir den Status des Clusters überprüfen?
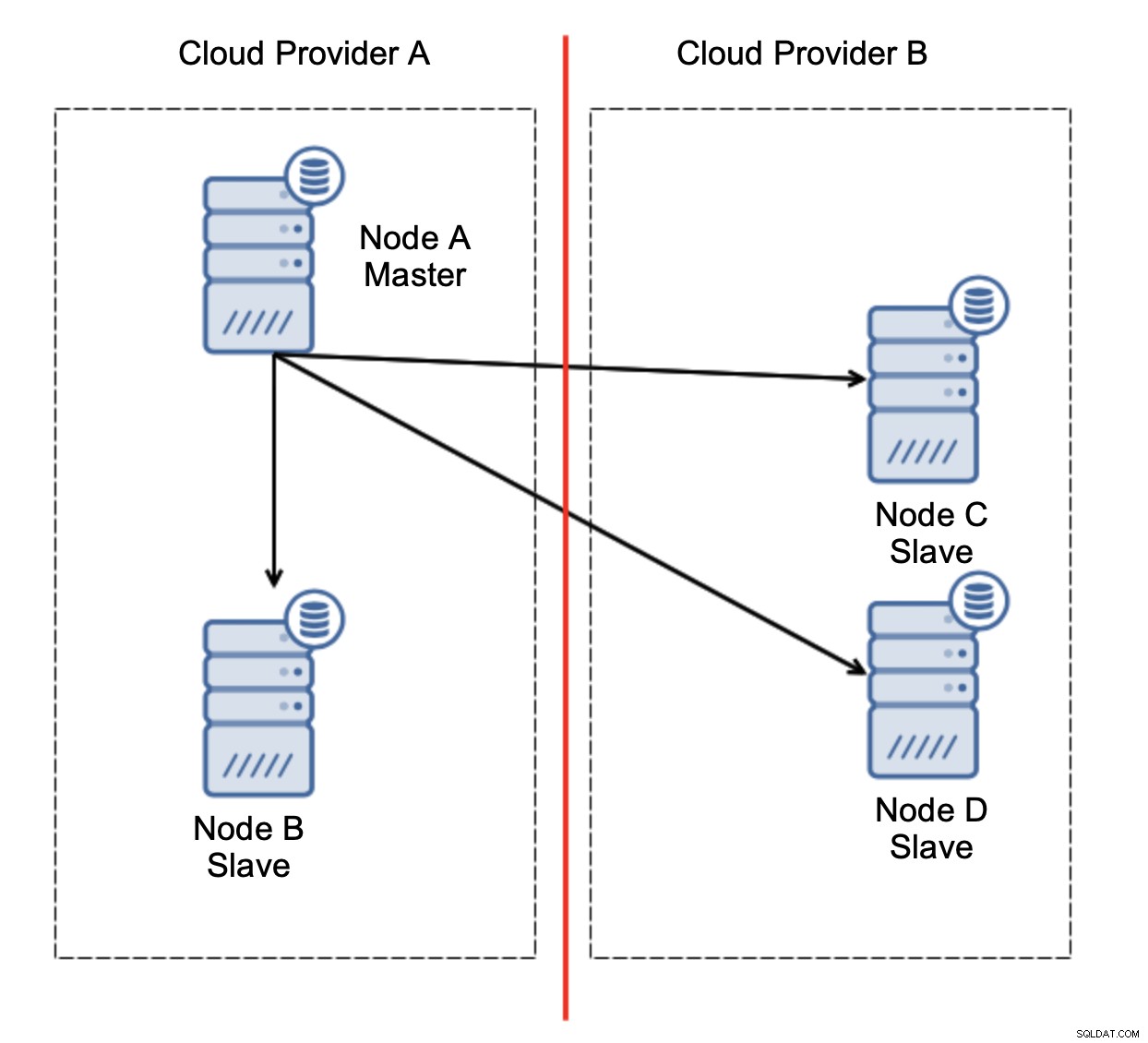
Hier ist die Herausforderung. Die Netzwerkkonnektivität zwischen zwei Cloud-Anbietern geht verloren. Aus Sicht der Knoten C und D sind sowohl Knoten B als auch Master, Knoten A offline. Soll Knoten C oder D zum Master befördert werden? Aber der alte Master ist immer noch aktiv - er ist nicht abgestürzt, er ist nur nicht über das Netzwerk erreichbar. Wenn wir einen der Knoten beim Anbieter B promoten würden, würden wir am Ende zwei beschreibbare Master, zwei Datensätze und Split Brain haben:
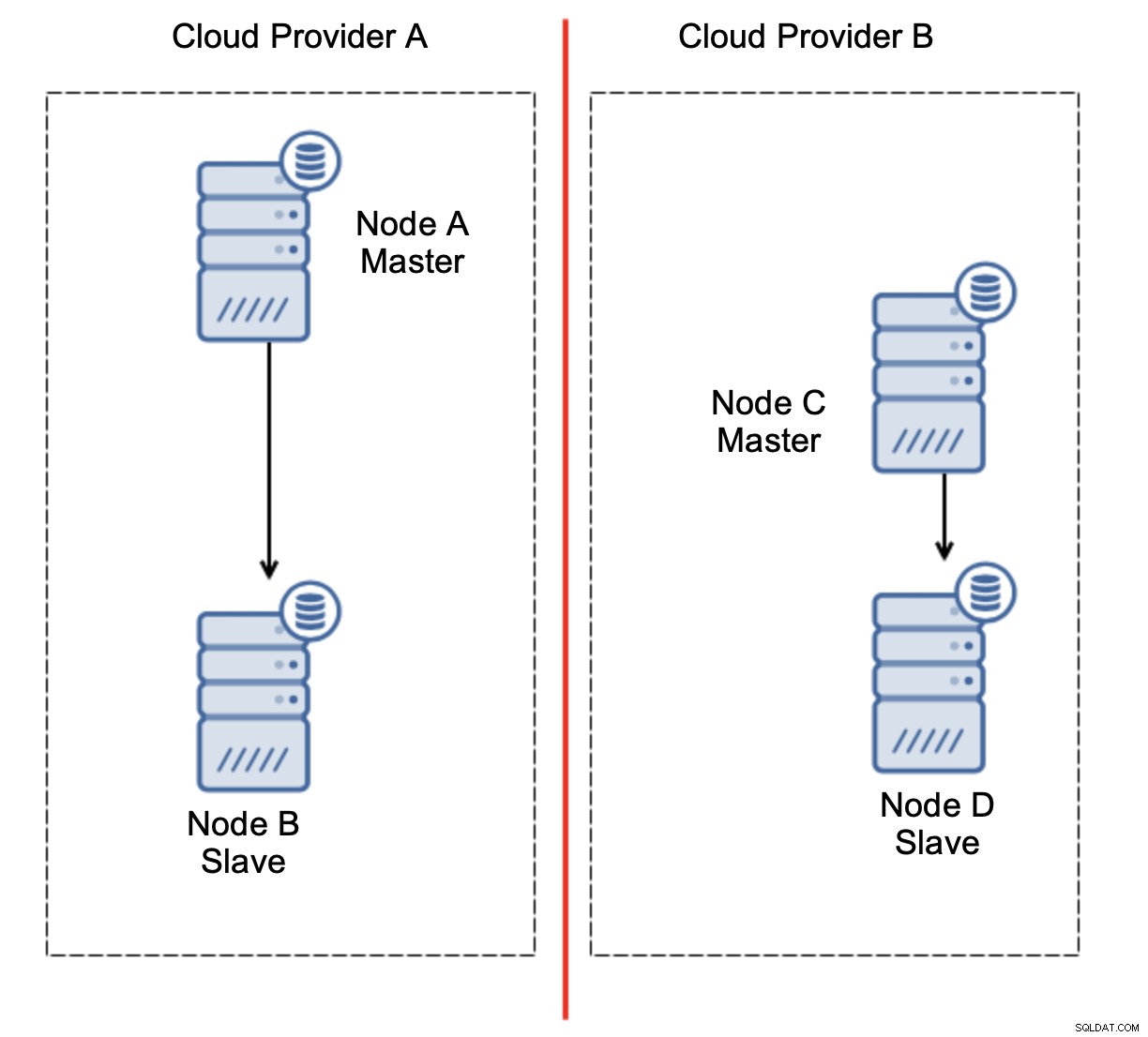
Das wollen wir definitiv nicht. Hier gibt es ein paar Optionen. Erstens können wir Failover-Regeln so definieren, dass das Failover nur in einem der Netzwerksegmente stattfinden darf, in dem sich der Master befindet. In unserem Fall würde dies bedeuten, dass nur Knoten B automatisch zum Master befördert werden könnte. Auf diese Weise können wir sicherstellen, dass das automatische Failover stattfindet, wenn Knoten A ausgefallen ist, aber keine Maßnahmen ergriffen werden, wenn eine Netzwerkpartitionierung vorhanden ist. Einige der Tools, die Ihnen beim Umgang mit automatisierten Failovern helfen können (wie ClusterControl), unterstützen White- und Blacklists, sodass Benutzer definieren können, welche Knoten als Kandidaten für ein Failover betrachtet werden können und welche niemals als Master verwendet werden sollten.
Eine andere Option wäre die Implementierung einer Art „Topology Awareness“-Lösung. Beispielsweise könnte man versuchen, den Master-Zustand mit externen Diensten wie Load-Balancern zu überprüfen.
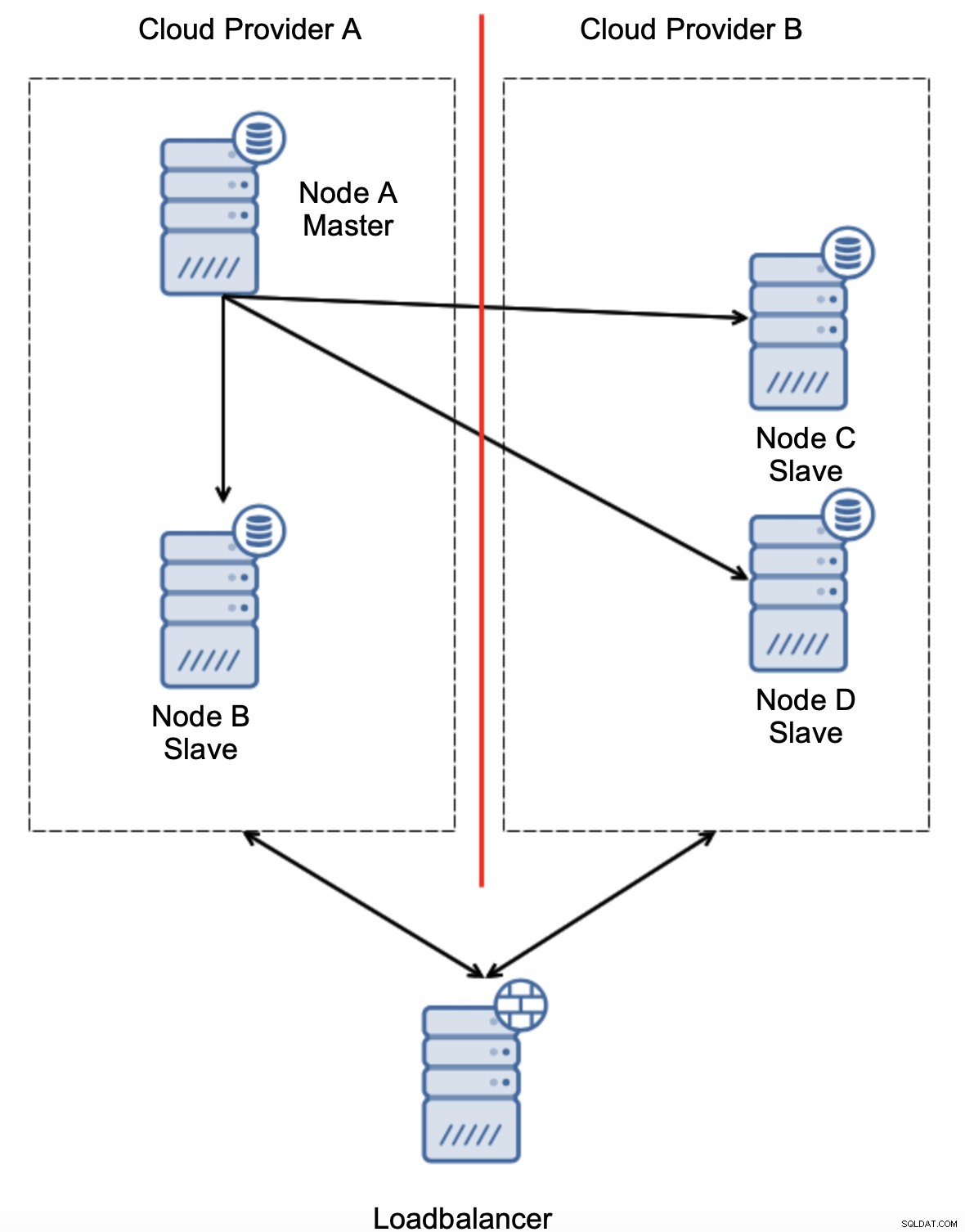
Wenn die Failover-Automatisierung den Status der Topologie aus Sicht der Load Balancer kann es sein, dass der Load Balancer, der sich an einem dritten Standort befindet, tatsächlich beide Rechenzentren erreichen und deutlich machen kann, dass Knoten im Cloud-Anbieter A nicht ausgefallen sind, sie können nur nicht vom Cloud-Anbieter B erreicht werden eine zusätzliche Überprüfungsschicht ist in ClusterControl implementiert.
Schließlich, egal welches Tool Sie verwenden, um automatisiertes Failover zu implementieren, es kann auch so entworfen werden, dass es Quorum-fähig ist. Dann können Sie mit drei Knoten an drei Standorten leicht erkennen, welcher Teil der Infrastruktur am Leben erhalten werden sollte und welcher nicht.
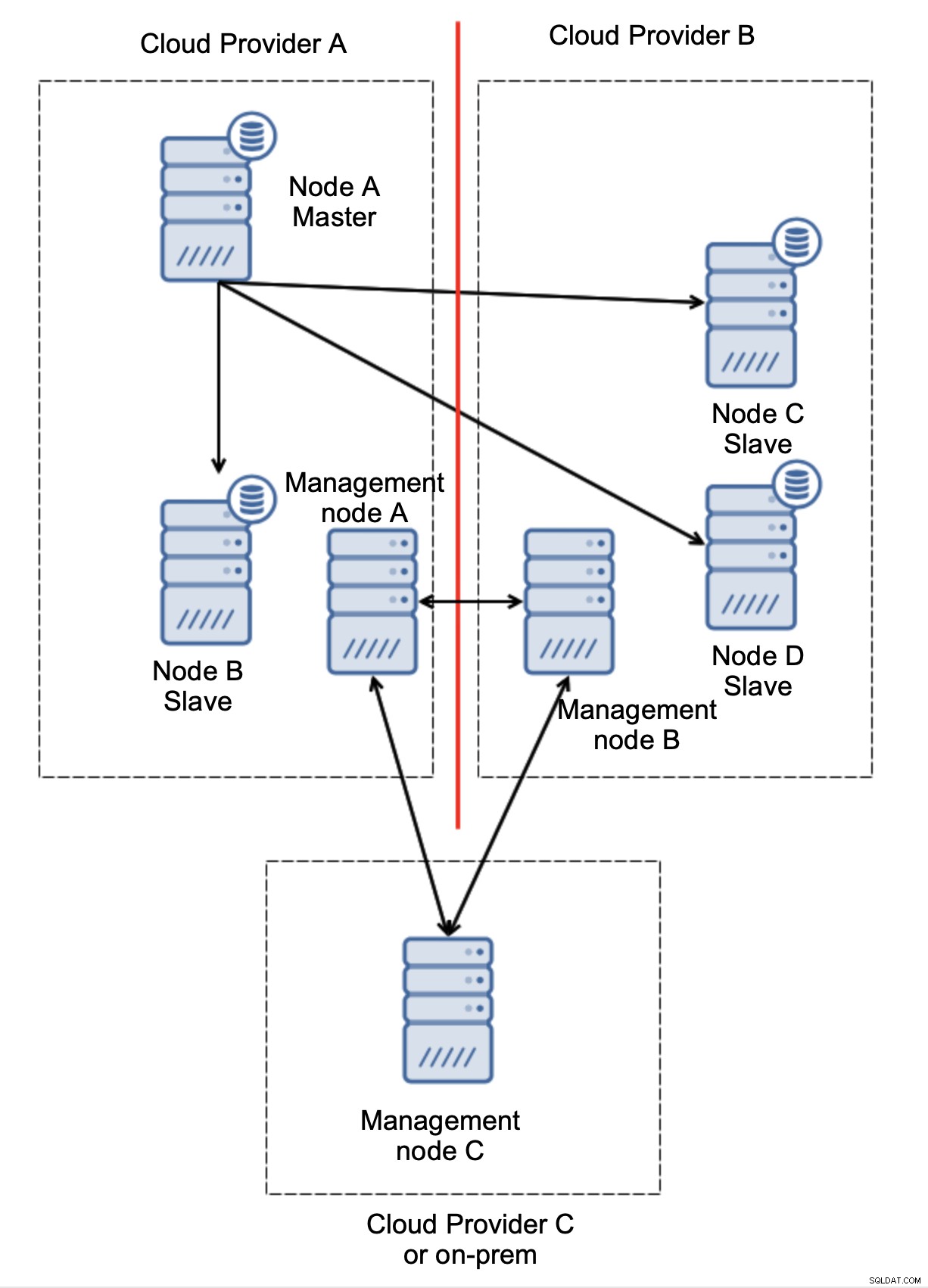
Hier können wir deutlich sehen, dass das Problem nur mit der Konnektivität zusammenhängt zwischen den Anbietern A und B. Der Verwaltungsknoten C fungiert als Relais, daher sollte kein Failover gestartet werden. Wenn andererseits ein Rechenzentrum vollständig abgeschaltet ist:

Es ist auch ziemlich klar, was passiert ist. Verwaltungsknoten A meldet, dass er die Mehrheit des Clusters nicht erreichen kann, während die Verwaltungsknoten B und C die Mehrheit bilden. Darauf kann man aufbauen und beispielsweise Skripte schreiben, die die Topologie entsprechend dem Zustand des Managementknotens verwalten. Das könnte bedeuten, dass die in Cloud-Anbieter A ausgeführten Skripts erkennen würden, dass Verwaltungsknoten A nicht die Mehrheit bildet, und alle Datenbankknoten stoppen, um sicherzustellen, dass keine Schreibvorgänge im partitionierten Cloud-Anbieter stattfinden.
ClusterControl kann, wenn es im Hochverfügbarkeitsmodus bereitgestellt wird, als Verwaltungsknoten behandelt werden, die wir in unseren Beispielen verwendet haben. Drei ClusterControl-Knoten, zusätzlich zum RAFT-Protokoll, können Ihnen dabei helfen festzustellen, ob ein bestimmtes Netzwerksegment partitioniert ist oder nicht.
Fazit
Wir hoffen, dass dieser Blogbeitrag Ihnen eine Vorstellung von Split-Brain-Szenarien gibt, die bei MySQL-Bereitstellungen auftreten können, die sich über mehrere Cloud-Plattformen erstrecken.