ProxySQL ist ein dedizierter Load Balancer für MySQL, der mit einer Vielzahl von Funktionen ausgestattet ist, einschließlich, aber nicht beschränkt auf Abfrageumleitung, Abfrage-Caching oder Traffic-Shaping. Es kann verwendet werden, um auf einfache Weise eine Lese-Schreib-Aufteilung einzurichten und Abfragen an separate Backend-Knoten umzuleiten. Infolgedessen bietet es viele überzeugende Gründe für die Verwendung. Auf der anderen Seite ist HAProxy ein großartiger Load-Balancer, aber er ist nicht für Datenbanken bestimmt, und obwohl er verwendet werden kann, kann er in Bezug auf die Funktionen nicht wirklich mit ProxySQL verglichen werden. Dies könnte der Grund dafür sein, dass Umgebungen, die immer noch auf HAProxy angewiesen sind, versuchen, zu ProxySQL zu migrieren.
In diesem kurzen Blogbeitrag teilen wir einige Vorschläge zum Migrationsprozess.
Planung Ihres Upgrades
Das ist ziemlich offensichtlich und sollte selbstverständlich sein, aber wir hätten es trotzdem gerne schriftlich. Planen Sie Ihr Upgrade. Stellen Sie sicher, dass Sie mit dem Prozess vertraut sind, dass Sie alles ausgiebig getestet haben. Richten Sie eine Testumgebung ein, in der Sie verschiedene Ansätze für das Upgrade überprüfen und entscheiden können, welche für Sie am besten geeignet ist.
Testen Sie die Lese-/Schreib-Aufteilung in ProxySQL, wenn Sie erwägen, es zu verwenden
Abhängig von Ihren Anforderungen sollten Sie die Verwendung einer Lese-/Schreib-Aufteilung in ProxySQL in Betracht ziehen. Dies ist wahrscheinlich einer der überzeugendsten Gründe für ein Upgrade. Anstatt es auf der Anwendungsseite zu implementieren (oder gar nicht zu implementieren, wenn Sie es in der Anwendung nicht erreichen können), können Sie sich darauf verlassen, dass ProxySQL die Lese-/Schreibaufteilung für Sie durchführt. Die Einrichtung ist sehr einfach, besonders wenn Sie ProxySQL mit ClusterControl bereitstellen - es geschieht ziemlich automatisch.
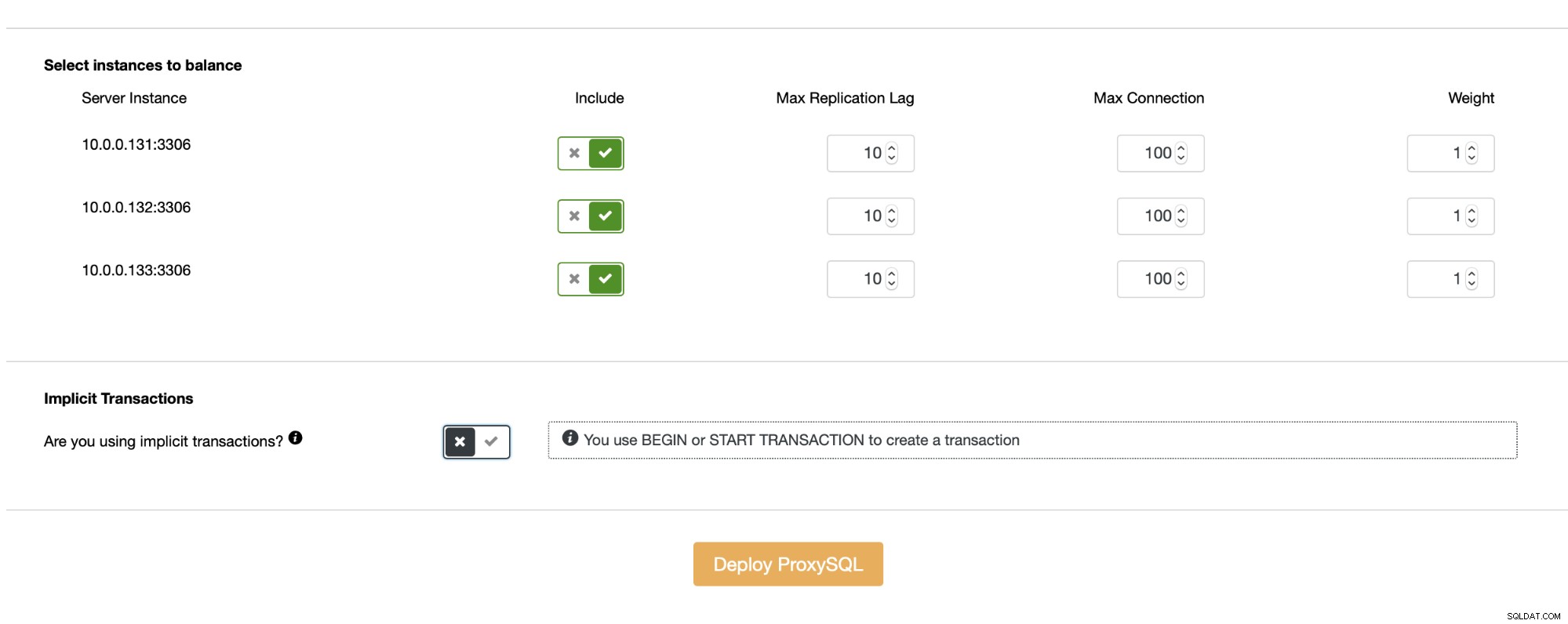
Solange Sie keine impliziten Transaktionen verwenden, richtet ClusterControl die Lese-/Schreibaufteilung für Sie mithilfe einer Reihe von Abfrageregeln:
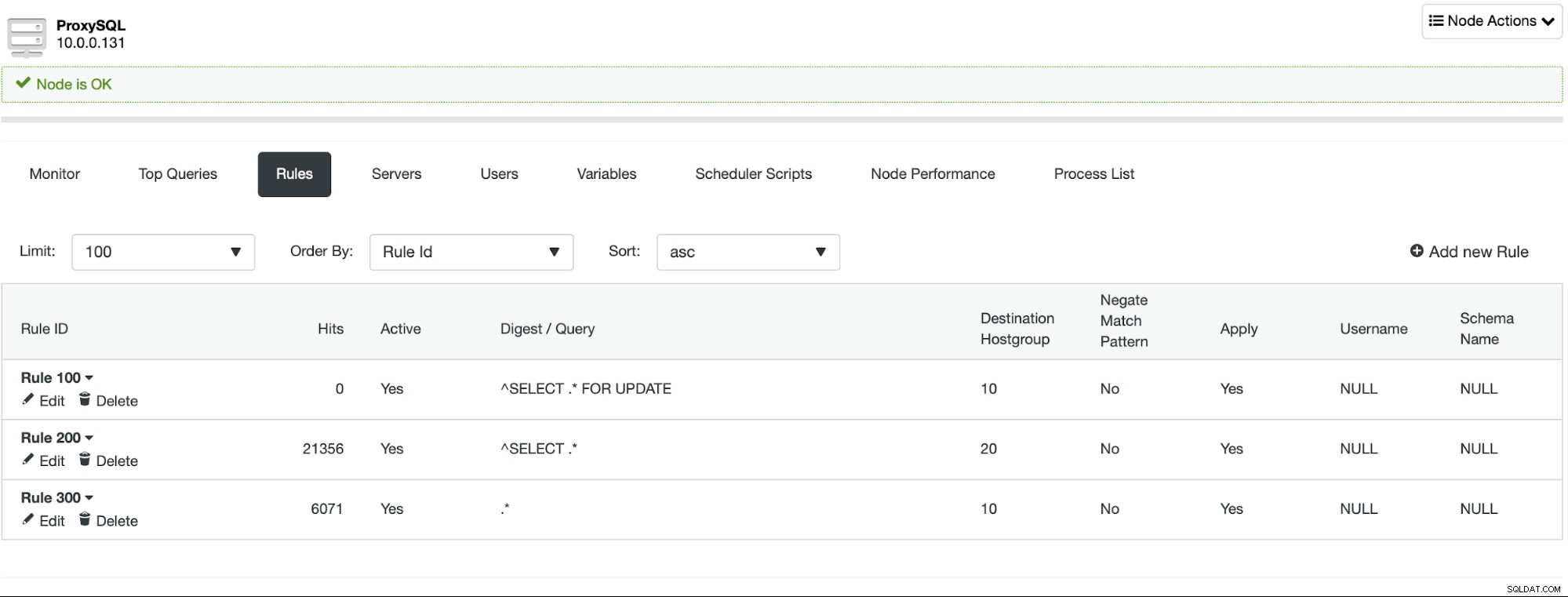
Obwohl es sehr einfach ist, eine Lese-/Schreibaufteilung zu implementieren, sollten Sie dies tun Seien Sie vorsichtig, wenn Sie dies vorhaben. Anwendungen können auf einige Funktionen angewiesen sein, die in ProxySQL nicht wirklich sofort einsatzbereit sind. In den meisten Fällen können Sie durch eine zusätzliche Konfiguration von dieser Funktion profitieren, aber es ist sehr wichtig, während der Testphase festzustellen, ob Ihre App nur funktioniert oder ob Sie eine benutzerdefinierte Konfiguration hinzufügen müssen. Besonders knifflige Teile sind Read-after-Write-Probleme - in diesem Fall müssen Sie möglicherweise ProxySQL neu konfigurieren, um das Multiplexen von Verbindungen für einige der Abfragen zu deaktivieren.
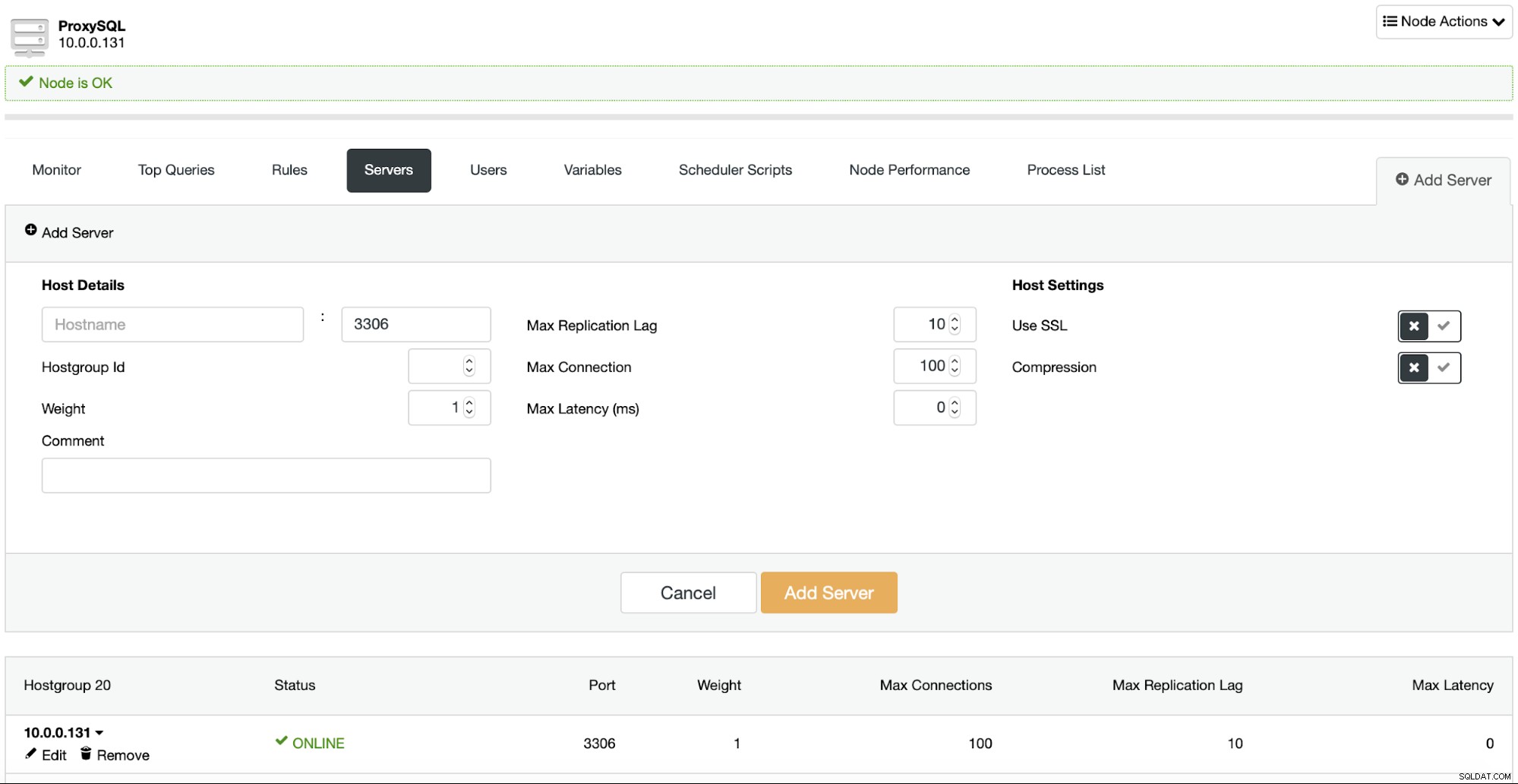
Vergiss die Konfigurationsdatei in ProxySQL
Dies ist eines der Dinge, die für neue Benutzer von ProxySQL überraschend kommen. Es verwendet nicht wirklich Konfigurationsdateien. Es gibt einen, ja, aber er dient so ziemlich dazu, ProxySQL beim ersten Start zu booten. ProxySQL verwendet eine SQLite-Datenbank, die seine Konfiguration enthält, und die richtige Art, Konfigurationsänderungen vorzunehmen, ist über einen MySQL-Client, der mit dem administrativen Port von ProxySQL verbunden ist. Von dort aus können Sie die Konfigurationsänderungen zur Laufzeit vornehmen, ohne ProxySQL neu starten zu müssen.
Natürlich erlaubt Ihnen die ClusterControl-Benutzeroberfläche auch, ProxySQL neu zu konfigurieren:
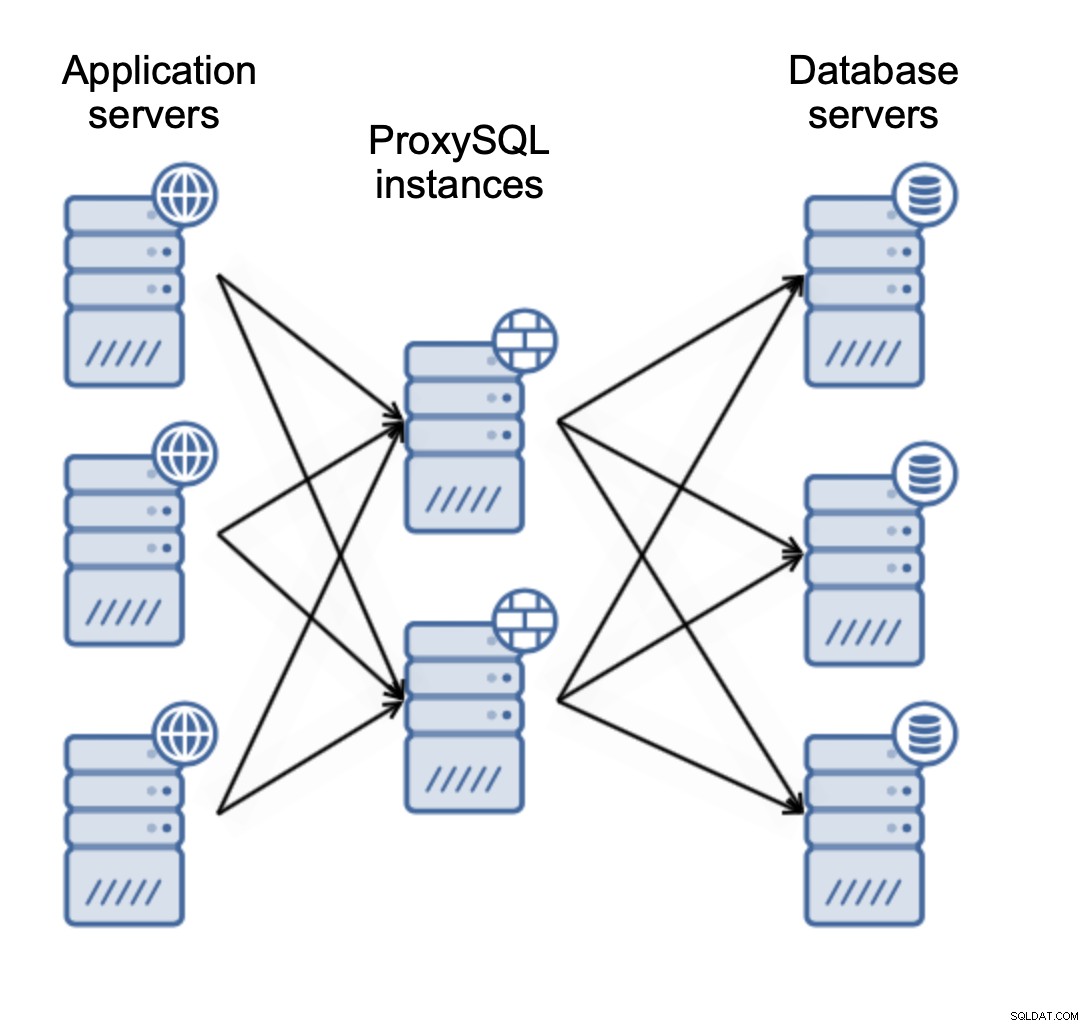
ProxySQL-Bereitstellungsmuster
Es gibt im Wesentlichen zwei Möglichkeiten, wie Sie ProxySQL bereitstellen möchten. Sie können entweder einen dedizierten Server verwenden, um ProxySQL bereitzustellen auf:
Oder Sie können ProxySQL mit Anwendungsservern verbinden:
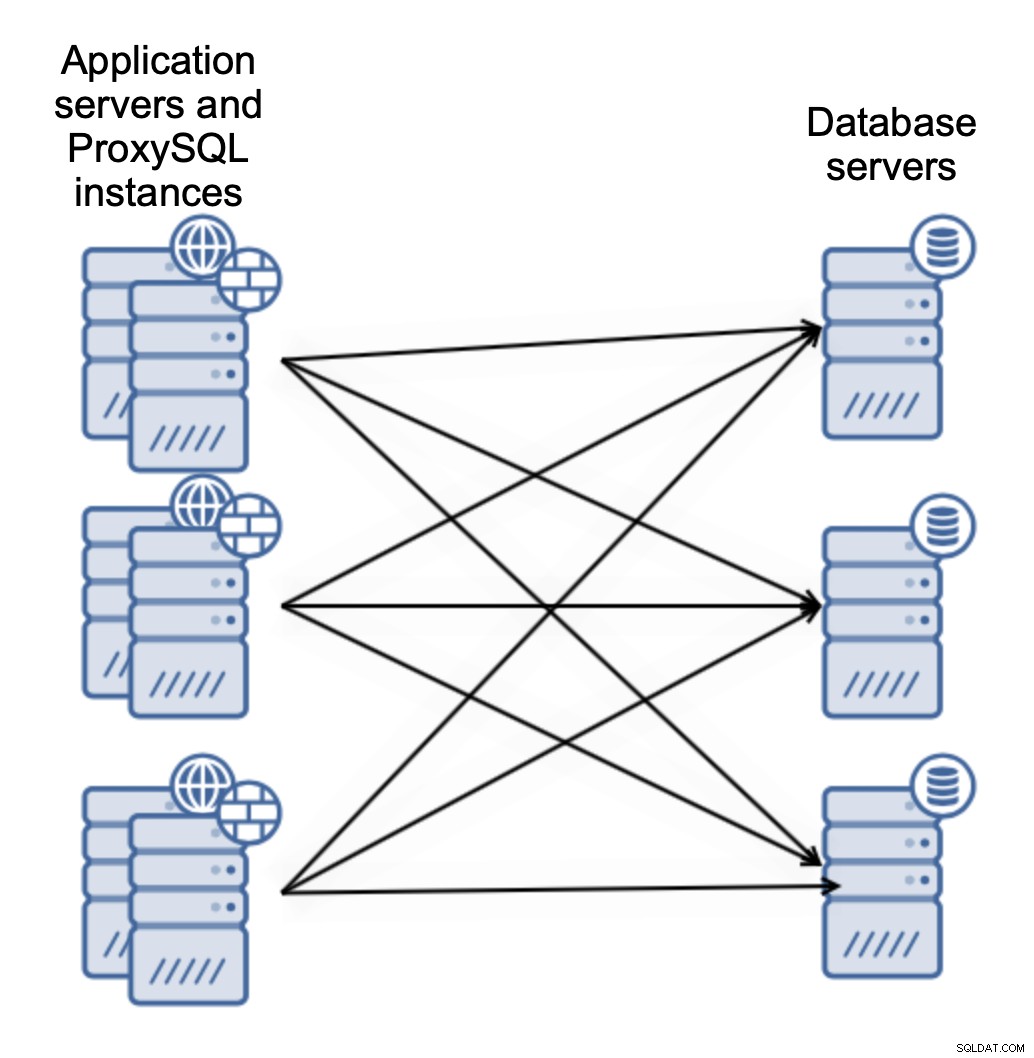
Dadurch kann Ihre Anwendung über Unix-Socket eine Verbindung zur lokalen ProxySQL-Instanz herstellen ist leistungsmäßig besser als die Verwendung einer Remote-TCP-Verbindung. Es vereinfacht auch die Einrichtung – es ist nicht erforderlich, Keepalived oder einen anderen virtuellen IP-Anbieter zu implementieren, um die Last auf ProxySQL-Instanzen auszugleichen. Die Anwendung stellt nur eine Verbindung zum lokalen ProxySQL her und das war es auch schon.
Verwenden Sie ProxySQL-Cluster für größere Bereitstellungen
Sicherzustellen, dass Ihre ProxySQL-Instanzen immer dieselbe Konfiguration enthalten, kann schwierig sein, besonders wenn ihre Anzahl groß ist. Es gibt zahlreiche Möglichkeiten, mit solchen Herausforderungen umzugehen - Ansible/Chef/Puppet, Shell-Skripte und so weiter. Wir empfehlen, sich auf die integrierte Lösung ProxySQL Cluster zu verlassen. Mit nur wenigen Konfigurationsänderungen können Sie ProxySQL-Knoten so konfigurieren, dass sie einen Cluster bilden, in dem eine Konfigurationsänderung auf einem der Knoten an alle Mitglieder des Clusters weitergegeben wird.
Basteln Sie mit SO_REUSEPORT für einen reibungslosen Load-Balancer-Wechsel
Einer der schwierigeren Teile könnte darin bestehen, sicherzustellen, dass Sie den Datenverkehr von HAProxy auf ProxySQL so umstellen, dass die Auswirkungen auf die Anwendung minimiert werden. Normalerweise müssten Sie mindestens eine Einstellung ändern – Hostname oder Port, mit dem sich die Anwendung verbinden soll. Abhängig von Ihrer Umgebung ist dies möglicherweise nicht ideal, insbesondere wenn die Datenbankkonnektivitätskonfiguration in der Anwendung integriert ist. Es würde ziemlich viel erfordern, eine Änderung in der Codebasis vorzunehmen und einen neuen Code in die Produktion zu bringen. Nicht das größte Angebot, aber Sie können es besser machen.
Der interessante Teil ist, dass sowohl ProxySQL als auch neuere Versionen von HAProxy (ab 1.8) in der Lage sind, SO_REUSEPORT zu verwenden. Diese Socket-Option ist in Linux ab Kernel 3.9 verfügbar und ermöglicht es mehreren Prozessen, denselben Port zu teilen. ProxySQL kann es für reibungslose Upgrades zwischen ProxySQL-Versionen verwenden, HAProxy verwendet es, um die Konfiguration ohne Auswirkungen auf die Anwendung neu zu laden. Interessanterweise ist es möglich, ProxySQL so zu konfigurieren, dass es den Port mit HAProxy teilt, um eine nahtlose Migration zwischen diesen beiden Load Balancern zu ermöglichen.
Es gibt ein paar Dinge, die Sie beachten müssen, wenn Sie dies versuchen - erstens verwendet ProxySQL diese Option nicht standardmäßig, Sie müssen ProxySQL beim Start das Flag -r hinzufügen. Sie können dies tun, indem Sie die Unit-Datei des ProxySQL-Systems bearbeiten:
example@sqldat.com:~# systemctl edit proxysql --fullund Änderung der ExecStart-Direktive in:
ExecStart=/usr/bin/proxysql -c /etc/proxysql.cnf -rEine weitere Einschränkung, die Sie unter Linux beachten sollten, ist, dass nur Prozesse, die von derselben Benutzer-ID gestartet werden, den Port gemeinsam nutzen dürfen. Dies bedeutet, dass Sie ProxySQL neu konfigurieren müssen, um als „Haproxy“-Benutzer ausgeführt zu werden.
Wie üblich sollten Sie Tests durchführen, bevor Sie versuchen, diesen Vorgang in einer Produktionsumgebung auszuführen. Es ist definitiv möglich, dieses Kunststück zu vollbringen, aber Sie sollten Vorsicht walten lassen und sich vergewissern, dass es Ihre Produktion nicht aufgrund einer nicht standardmäßigen Konfiguration in Bezug auf Ihre Umgebung beeinträchtigt.
Wir hoffen, dass dieser kurze Blog Ihnen einen Einblick in den Migrationsprozess von HAProxy zu ProxySQL geben wird. Für die Datenbank-Backends wird diese Änderung sehr vorteilhaft sein, auch wenn der Vorbereitungsteil zeitaufwändig sein könnte. Wenn Sie die richtigen Tests durchlaufen, sollte die endgültige Migration ziemlich unkompliziert und sicher sein.