In einem früheren Blog hatten wir besprochen, wie man ein eigenständiges Moodle-Setup auf ein skalierbares Setup basierend auf einer geclusterten Datenbank migriert. Der nächste Schritt, über den Sie nachdenken müssen, ist der Failover-Mechanismus – was tun Sie, wenn Ihr Datenbankdienst ausfällt?
Ein ausgefallener Datenbankserver ist nicht ungewöhnlich, wenn Sie MySQL Replication als Backend-Moodle-Datenbank haben, und wenn es passiert, müssen Sie einen Weg finden, Ihre Topologie wiederherzustellen, indem Sie zum Beispiel einen Standby-Server zu hochstufen ein neuer primärer Server werden. Ein automatisches Failover für Ihre Moodle-MySQL-Datenbank hilft bei der Betriebszeit der Anwendung. Wir erklären, wie Failover-Mechanismen funktionieren und wie Sie automatisches Failover in Ihr Setup einbauen.
Hochverfügbarkeitsarchitektur für MySQL-Datenbank
Hochverfügbarkeitsarchitektur kann erreicht werden, indem Sie Ihre MySQL-Datenbank auf verschiedene Arten gruppieren. Sie können MySQL Replication verwenden und mehrere Replikate einrichten, die Ihrer primären Datenbank eng folgen. Darüber hinaus können Sie einen Datenbank-Load-Balancer einsetzen, um den Lese-/Schreibverkehr aufzuteilen und den Verkehr auf Lese-/Schreib- und Nur-Lese-Knoten zu verteilen. Die Hochverfügbarkeitsarchitektur einer Datenbank mit MySQL-Replikation kann wie folgt beschrieben werden:
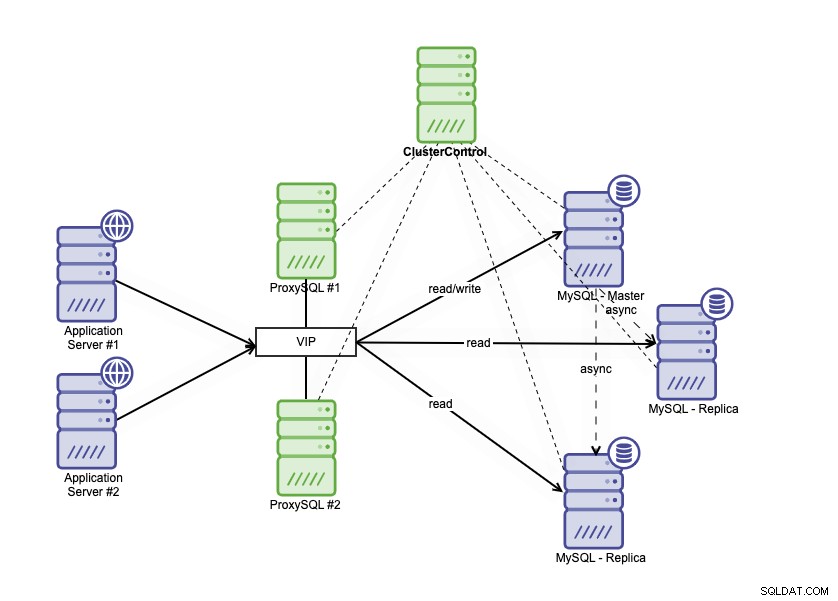
Es besteht aus einer primären Datenbank, zwei Datenbankreplikaten und Datenbank-Load-Balancern (in diesem Blog verwenden wir ProxySQL als Datenbank-Load-Balancer) und keepalived als Dienst zur Überwachung der ProxySQL-Prozesse. Wir verwenden die virtuelle IP-Adresse als einzelne Verbindung von der Anwendung. Der Datenverkehr wird basierend auf dem Rollen-Flag in Keepalived an den aktiven Load Balancer verteilt.
ProxySQL ist in der Lage, den Datenverkehr zu analysieren und zu verstehen, ob eine Anfrage ein Lese- oder ein Schreibvorgang ist. Anschließend leitet er die Anfrage an den/die entsprechenden Host(s) weiter.
Failover bei MySQL-Replikation
MySQL Replication verwendet die binäre Protokollierung, um Daten von der Primärdatenbank zu den Replikaten zu replizieren. Die Replikate stellen eine Verbindung zum primären Knoten her und jede Änderung wird repliziert und über IO_THREAD in die Relay-Protokolle der Replikatknoten geschrieben. Nachdem die Änderungen im Relaisprotokoll gespeichert wurden, fährt der SQL_THREAD-Prozess damit fort, Daten in die Replikatdatenbank zu übernehmen.
Die Standardeinstellung für den Parameter read_only in einem Replikat ist EIN. Es wird verwendet, um das Replikat selbst vor direkten Schreibvorgängen zu schützen, sodass die Änderungen immer aus der primären Datenbank stammen. Dies ist wichtig, da wir nicht möchten, dass das Replikat vom primären Server abweicht. Das Failover-Szenario in der MySQL-Replikation tritt auf, wenn der primäre Server nicht erreichbar ist. Dafür kann es viele Gründe geben; B. Serverabstürze oder Netzwerkprobleme.
Sie müssen eines der Replikate zum primären Replikat heraufstufen, den schreibgeschützten Parameter auf dem heraufgestuften Replikat deaktivieren, damit es beschreibbar ist. Sie müssen auch das andere Replikat ändern, um eine Verbindung mit dem neuen primären Replikat herzustellen. Im GTID-Modus müssen Sie den Namen und die Position des Binärprotokolls nicht notieren, von wo aus die Replikation fortgesetzt werden soll. Bei der traditionellen Binlog-basierten Replikation müssen Sie jedoch unbedingt den Namen und die Position des letzten Binärlogs kennen, von dem aus Sie fortfahren können. Failover bei der binlogbasierten Replikation ist ein ziemlich komplexer Prozess, aber selbst Failover bei der GTID-basierten Replikation ist ebenfalls nicht trivial, da Sie auf Dinge wie fehlerhafte Transaktionen achten müssen. Einen Ausfall zu erkennen ist das eine, und dann innerhalb kurzer Zeit auf den Ausfall zu reagieren, ist ohne Automatisierung wahrscheinlich nicht möglich.
Wie ClusterControl automatisches Failover ermöglicht
ClusterControl kann ein automatisches Failover für Ihre Moodle-MySQL-Datenbank durchführen. Es gibt eine automatische Wiederherstellung für Cluster und Knoten, die den Failover-Prozess auslöst, wenn die primäre Datenbank abstürzt.
Wir werden simulieren, wie das automatische Failover in ClusterControl abläuft. Wir werden die primäre Datenbank zum Absturz bringen und nur auf dem ClusterControl-Dashboard sehen. Unten ist die aktuelle Topologie des Clusters:
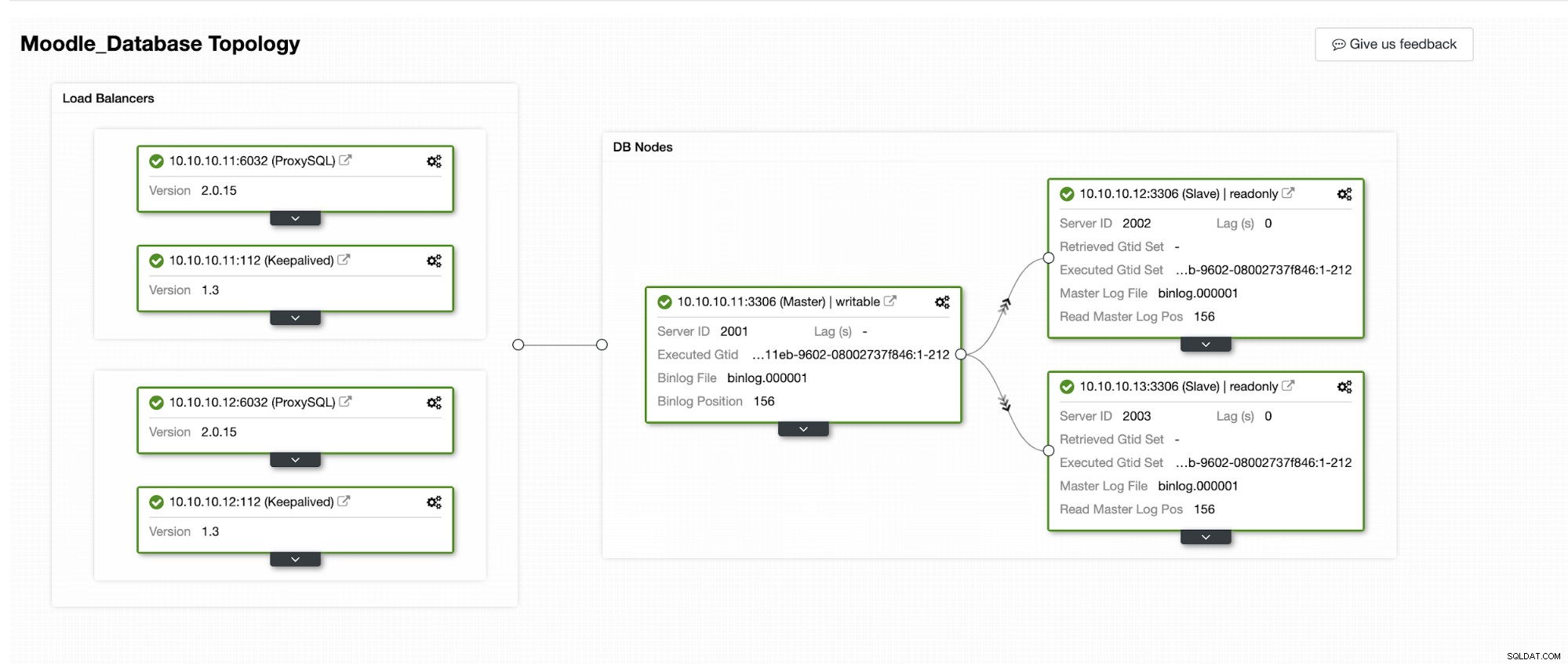
Die primäre Datenbank verwendet die IP-Adresse 10.10.10.11 und die Replikate sind:10.10.10.12 und 10.10.10.13. Wenn der Absturz auf dem primären Server auftritt, löst ClusterControl eine Warnung aus und ein Failover beginnt, wie im folgenden Bild gezeigt:
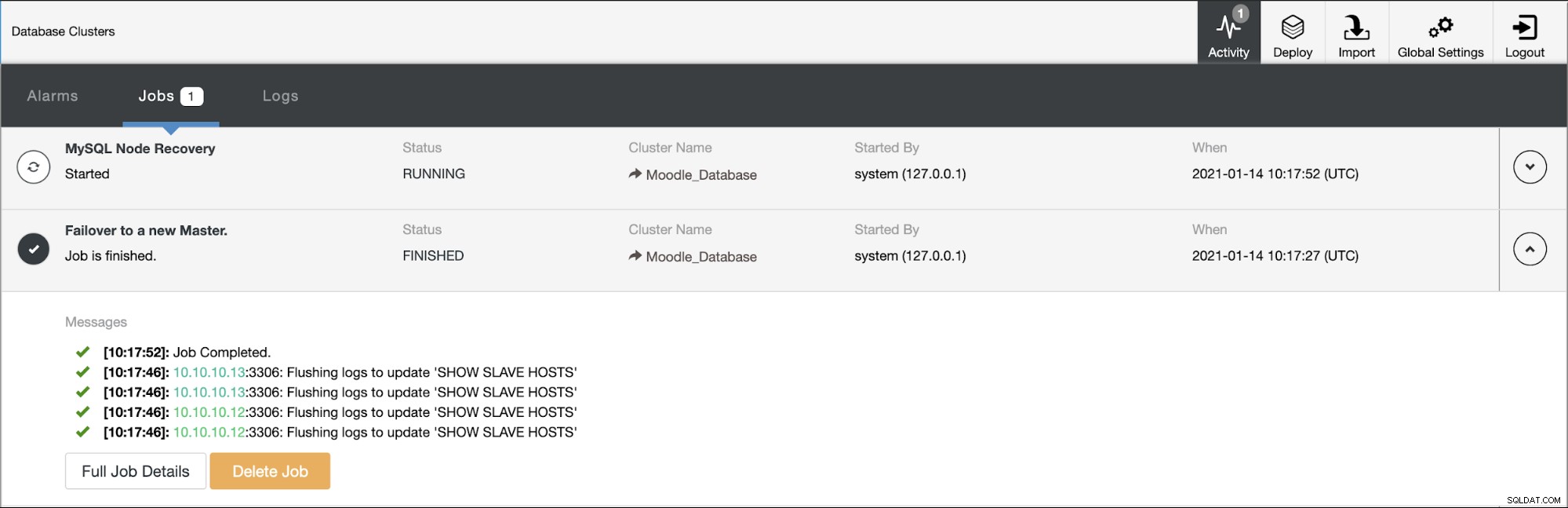
Eines der Replikate wird zum primären heraufgestuft, was zur Topologie als führt im unteren Bild:
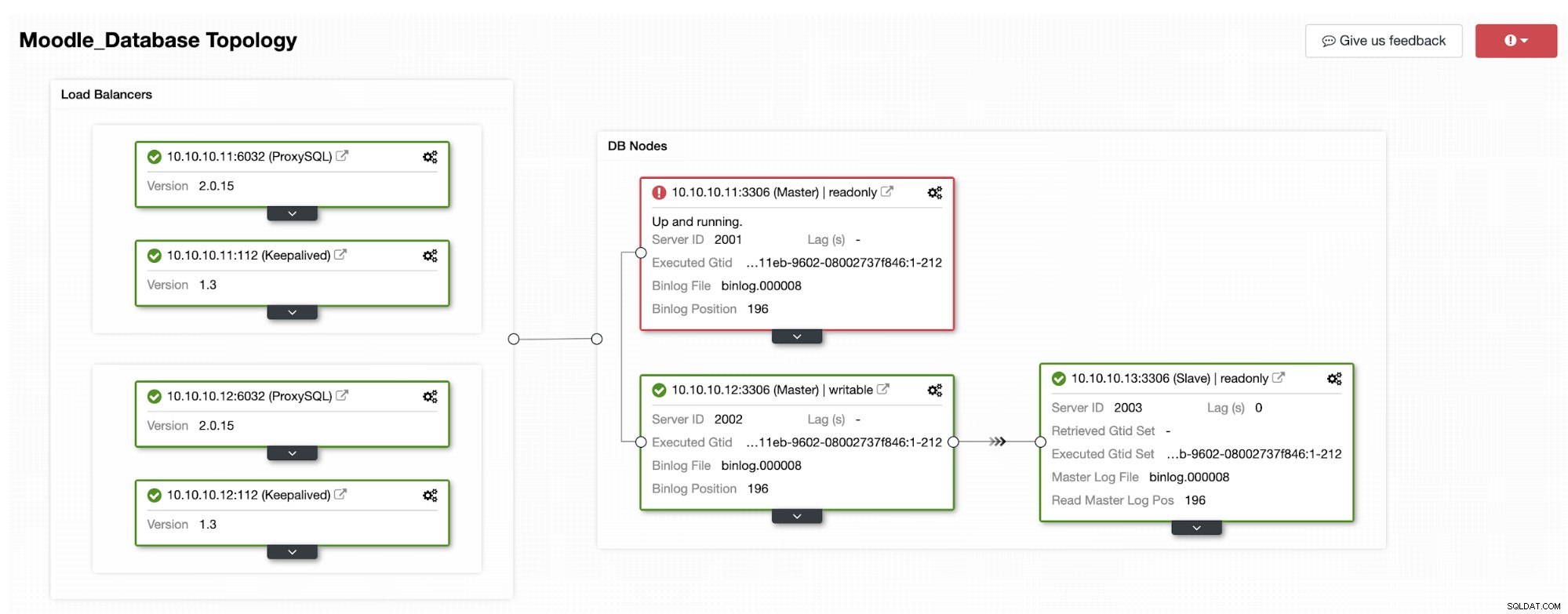
Die IP-Adresse 10.10.10.12 dient jetzt dem Schreibverkehr als primär, und wir haben auch nur ein Replikat mit der IP-Adresse 10.10.10.13. Auf der ProxySQL-Seite erkennt der Proxy den neuen primären Server automatisch. Die Hostgruppe (HG10) bedient weiterhin den Schreibverkehr mit dem Mitglied 10.10.10.12, wie unten gezeigt:

Hostgroup (HG20) kann immer noch Leseverkehr bedienen, aber wie Sie sehen können der Knoten 10.10.10.11 ist wegen des Absturzes offline :
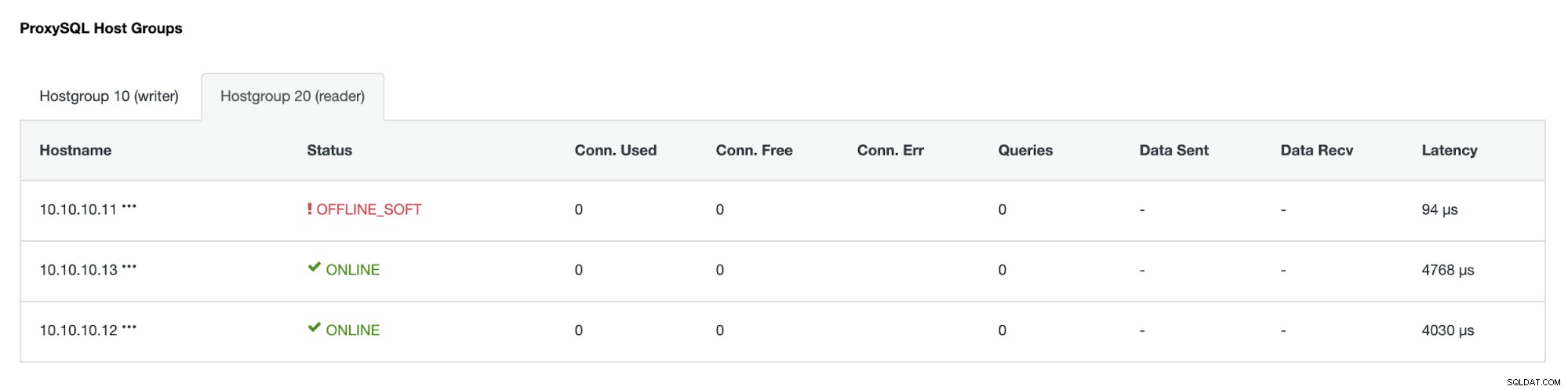
Sobald der primäre ausgefallene Server wieder online ist, wird er nicht automatisch wiederhergestellt -in der Datenbank-Topologie eingeführt. Dadurch soll vermieden werden, dass Informationen zur Fehlerbehebung verloren gehen, da die Wiedereinführung des Knotens als Replik möglicherweise das Überschreiben einiger Protokolle oder anderer Informationen erfordern könnte. Es ist jedoch möglich, die automatische Wiederverbindung des ausgefallenen Knotens zu konfigurieren.