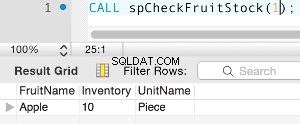
Release-Tests sind normalerweise einer der Schritte im gesamten Bereitstellungsprozess. Sie schreiben den Code und überprüfen dann, wie er sich in einer Staging-Umgebung verhält, und schließlich stellen Sie den neuen Code in der Produktion bereit. Datenbanken sind für jede Art von Anwendung intern, und daher ist es wichtig zu überprüfen, wie die datenbankbezogenen Änderungen die Anwendung verändern. Es ist möglich, dies auf verschiedene Arten zu überprüfen; Eine davon wäre die Verwendung einer dedizierten Replik. Schauen wir uns an, wie es gemacht werden kann.
Natürlich möchten Sie nicht, dass dieser Prozess manuell erfolgt – er sollte Teil der CI/CD-Prozesse Ihres Unternehmens sein. Abhängig von der genauen Anwendung, Umgebung und den eingesetzten Prozessen können Sie ad hoc erstellte Replikate oder Replikate verwenden, die immer Teil der Datenbankumgebung sind.
Galera Cluster funktioniert so, dass es Schemaänderungen auf eine bestimmte Weise handhabt. Es ist möglich, eine Schemaänderung auf einem einzelnen Knoten im Cluster auszuführen, aber es ist schwierig, da es nicht alle möglichen Schemaänderungen unterstützt, und es wird die Produktion beeinträchtigen, wenn etwas schief geht. Ein solcher Knoten müsste mit SST vollständig neu aufgebaut werden, was bedeutet, dass einer der verbleibenden Galera-Knoten als Spender fungieren und alle seine Daten über das Netzwerk übertragen muss.
Alternative wird es sein, eine Replik oder sogar einen ganzen zusätzlichen Galera-Cluster zu verwenden, der als Replik fungiert. Offensichtlich muss der Prozess automatisiert werden, um ihn in die Entwicklungspipeline einzufügen. Dafür gibt es viele Möglichkeiten:Skripte oder zahlreiche Infrastructure Orchestration Tools wie Ansible, Chef, Puppet oder Salt Stack. Wir werden sie nicht im Detail beschreiben, aber wir möchten, dass Sie die Schritte zeigen, die erforderlich sind, damit der gesamte Prozess ordnungsgemäß funktioniert, und wir überlassen Ihnen die Implementierung in einem der Tools.
Freigabetests automatisieren
Zunächst möchten wir in der Lage sein, eine neue Datenbank einfach bereitzustellen. Es sollte mit den aktuellen Daten bereitgestellt werden, und dies kann auf viele Arten erfolgen – Sie können die Daten aus der Produktionsdatenbank auf den Testserver kopieren; das geht am einfachsten. Alternativ können Sie die neueste Sicherung verwenden – ein solcher Ansatz hat zusätzliche Vorteile beim Testen der Wiederherstellung der Sicherung. Die Backup-Überprüfung ist ein Muss in jeder Art von ernsthaften Bereitstellungen, und die Neuerstellung von Test-Setups ist eine großartige Möglichkeit, die Arbeit Ihres Wiederherstellungsprozesses zu überprüfen. Es hilft Ihnen auch, den Wiederherstellungsprozess zeitlich zu planen – wenn Sie wissen, wie lange die Wiederherstellung Ihrer Sicherung dauert, können Sie die Situation in einem Notfallwiederherstellungsszenario richtig einschätzen.
Sobald die Daten in der Datenbank bereitgestellt wurden, möchten Sie diesen Knoten möglicherweise als Replik Ihres primären Clusters einrichten. Es hat seine Vor- und Nachteile. Wenn Sie Ihren gesamten Datenverkehr zum eigenständigen Knoten erneut ausführen könnten, wäre das perfekt – in einem solchen Fall besteht keine Notwendigkeit, die Replikation einzurichten. Einige der Load Balancer, wie ProxySQL, ermöglichen es Ihnen, den Datenverkehr zu spiegeln und seine Kopie an einen anderen Ort zu senden. Andererseits ist die Replikation das Nächstbeste. Ja, Sie können Schreibvorgänge nicht direkt auf diesem Knoten ausführen, was Sie dazu zwingt, zu planen, wie Sie die Abfragen erneut ausführen, da der einfachste Ansatz, nur darauf zu antworten, nicht funktioniert. Andererseits werden alle Schreibvorgänge schließlich über den SQL-Thread ausgeführt, sodass Sie nur den Umgang mit SELECT-Abfragen planen müssen.
Abhängig von der genauen Änderung möchten Sie vielleicht den Schemaänderungsprozess testen. Schemaänderungen werden häufig durchgeführt und können sogar schwerwiegende Auswirkungen auf die Leistung der Datenbank haben. Daher ist es wichtig, sie zu verifizieren, bevor sie in der Produktion eingesetzt werden. Wir wollen uns die Zeit ansehen, die zum Ausführen der Änderung benötigt wird, und überprüfen, ob die Änderung separat auf Knoten angewendet werden kann oder erforderlich ist, um die Änderung gleichzeitig an der gesamten Topologie durchzuführen. Dadurch erfahren wir, welchen Prozess wir für eine bestimmte Schemaänderung verwenden sollten.
Verwendung von ClusterControl zur Verbesserung der Automatisierung der Release-Tests
ClusterControl enthält eine Reihe von Funktionen, die Ihnen helfen können, die Release-Tests zu automatisieren. Schauen wir uns an, was es bietet. Um es deutlich zu machen, die Funktionen, die wir zeigen werden, sind auf verschiedene Arten verfügbar. Der einfachste Weg ist die Verwendung der Benutzeroberfläche, aber es ist unnötig, was Sie tun möchten, wenn Sie an Automatisierung denken. Es gibt zwei weitere Möglichkeiten, dies zu tun:Befehlszeilenschnittstelle zu ClusterControl und RPC-API. In beiden Fällen können Jobs von externen Skripten ausgelöst werden, sodass Sie sie in Ihre bestehenden CI/CD-Prozesse einbinden können. Außerdem sparen Sie viel Zeit, da das Bereitstellen des Clusters nur eine Frage der Ausführung eines Befehls sein kann, anstatt ihn manuell einzurichten.
Bereitstellen des Testclusters
In erster Linie bietet ClusterControl die Möglichkeit, einen neuen Cluster bereitzustellen und ihn mit den Daten aus der vorhandenen Datenbank zu versorgen. Allein mit dieser Funktion können Sie die Bereitstellung des Staging-Servers einfach implementieren.
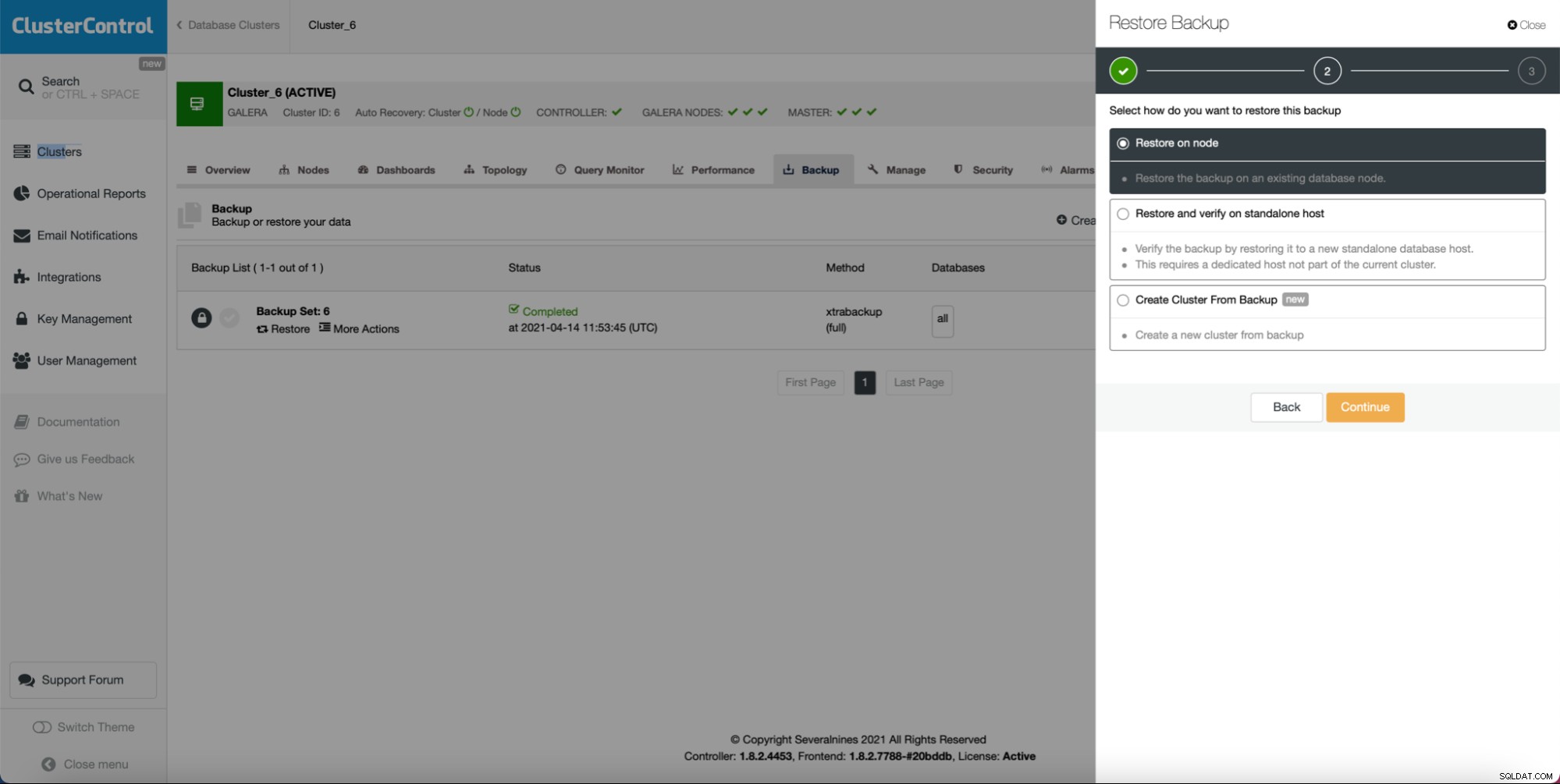
Wie Sie sehen können, solange Sie eine Sicherung erstellt haben, können Sie kann einen neuen Cluster erstellen und mit den Daten aus dem Backup bereitstellen:
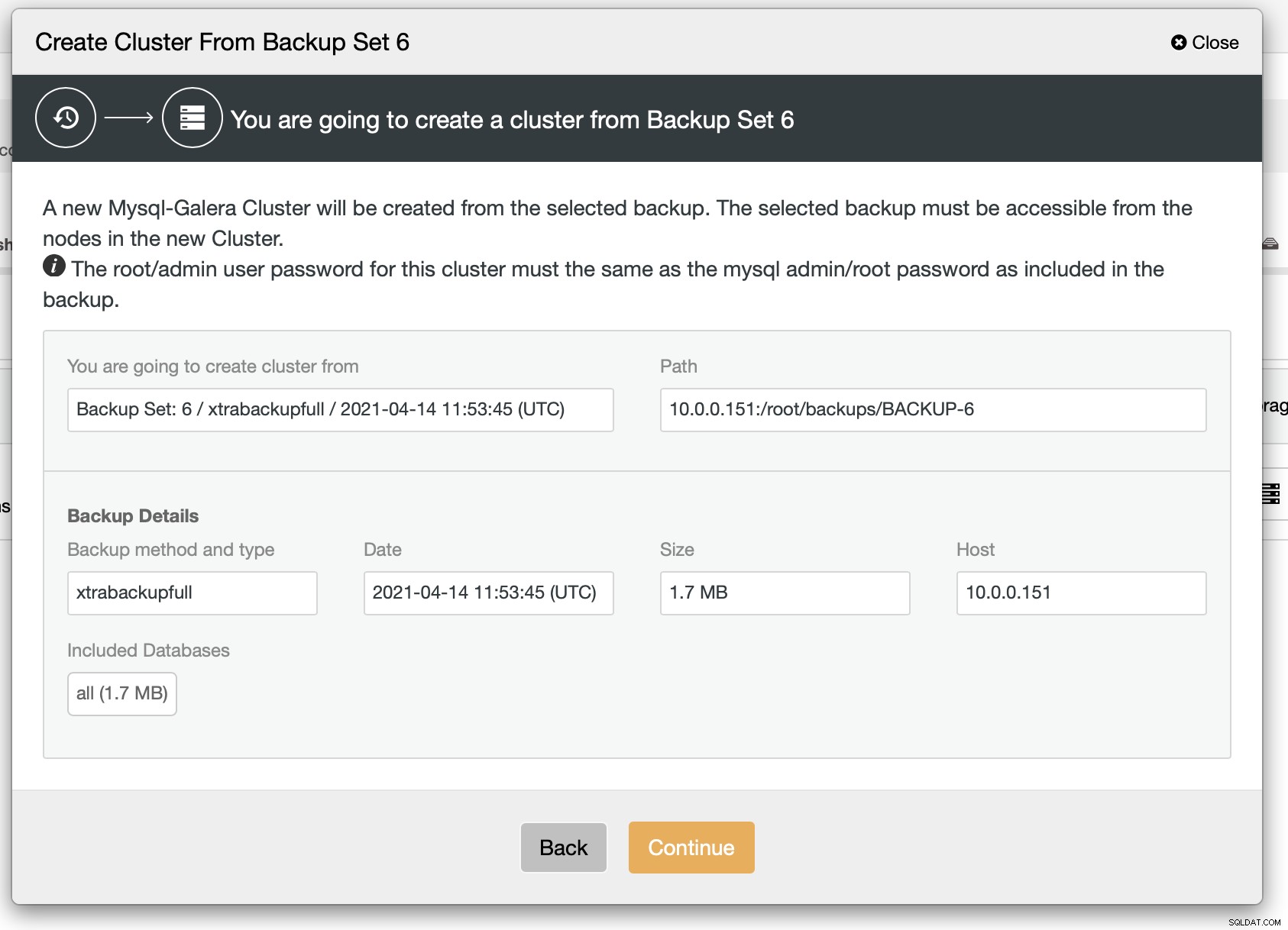
Wie wir sehen können, gibt es eine kurze Zusammenfassung dessen, was passieren wird. Wenn Sie auf Weiter klicken, werden Sie weiter fortfahren.
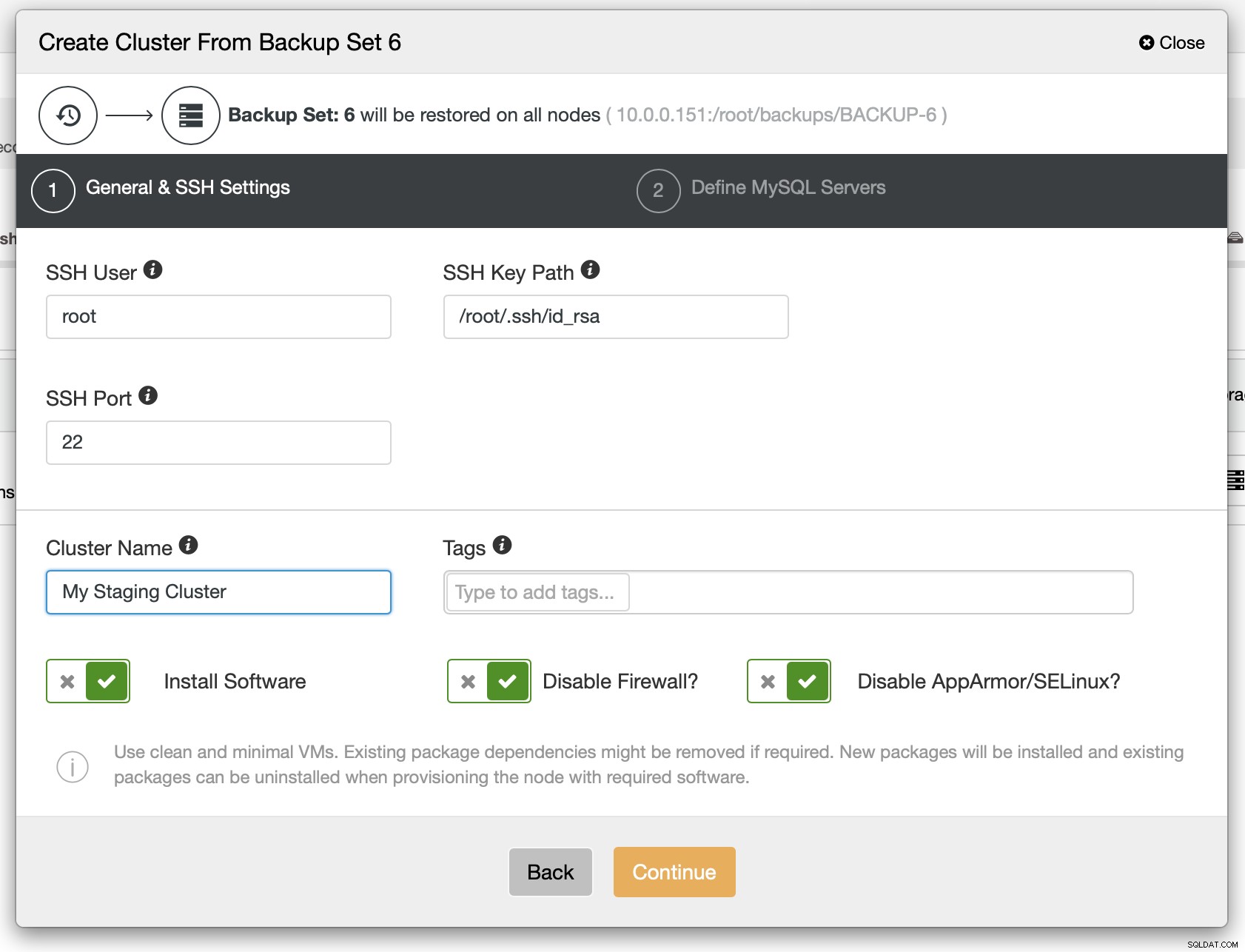
Als nächsten Schritt sollten Sie die SSH-Konnektivität definieren - sie muss vorhanden sein, bevor ClusterControl die Knoten bereitstellen kann.
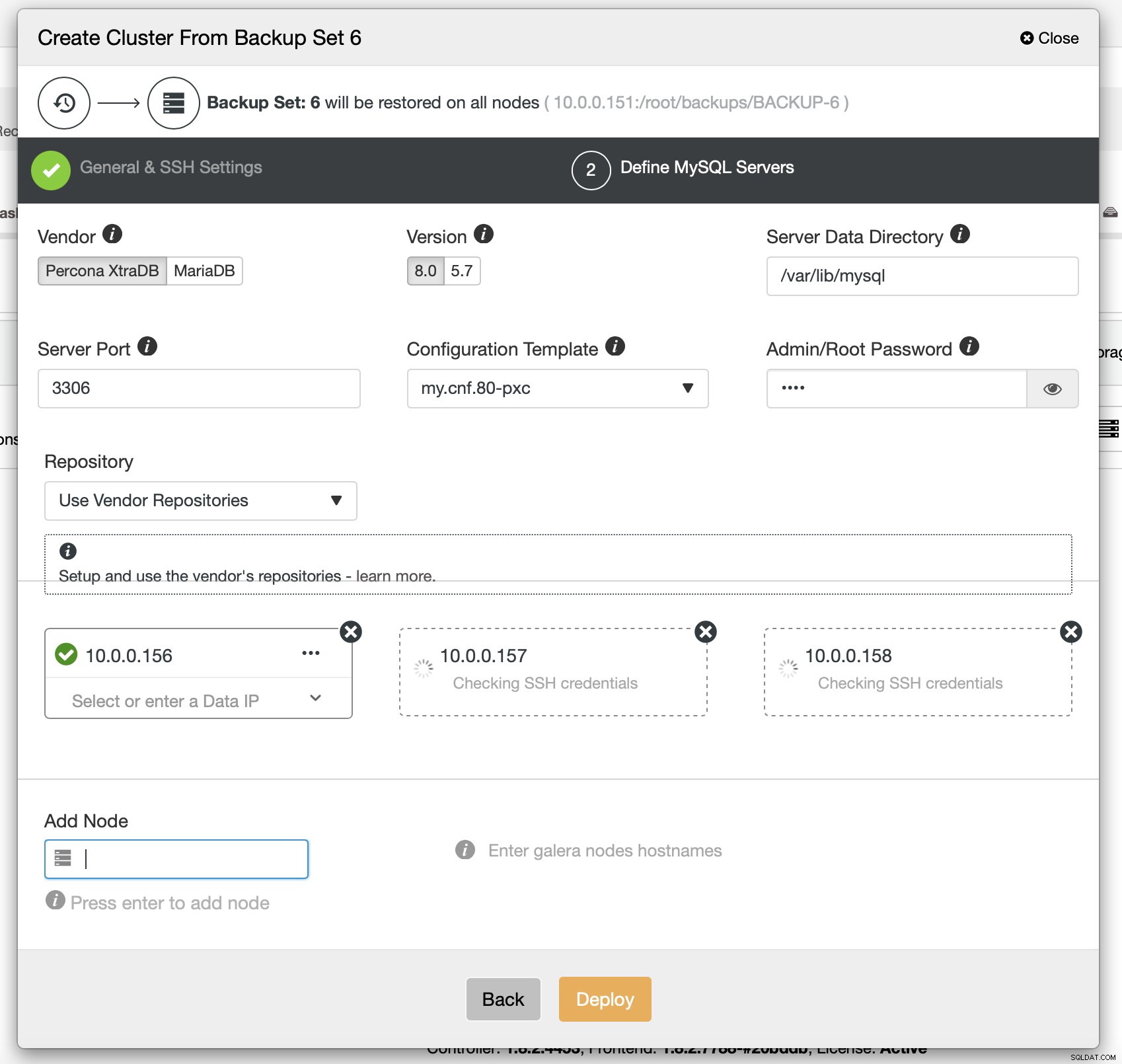
Schließlich müssen Sie (unter anderem) Hersteller, Version und Hostnamen der Knoten auswählen, die Sie im Cluster verwenden möchten. Genau das ist es.
Der CLI-Befehl, der dasselbe bewirken würde, sieht folgendermaßen aus:
s9s cluster --create --cluster-type=galera --nodes="10.0.0.156;10.0.0.157;10.0.0.158" --vendor=percona --cluster-name=PXC --provider-version=8.0 --os-user=root --os-key-file=/root/.ssh/id_rsa --backup-id=6Konfigurieren von ProxySQL zum Spiegeln des Datenverkehrs
Wenn wir einen Cluster bereitgestellt haben, möchten wir möglicherweise den Produktionsdatenverkehr an ihn senden, um zu überprüfen, wie das neue Schema den vorhandenen Datenverkehr handhabt. Eine Möglichkeit hierfür ist die Verwendung von ProxySQL.
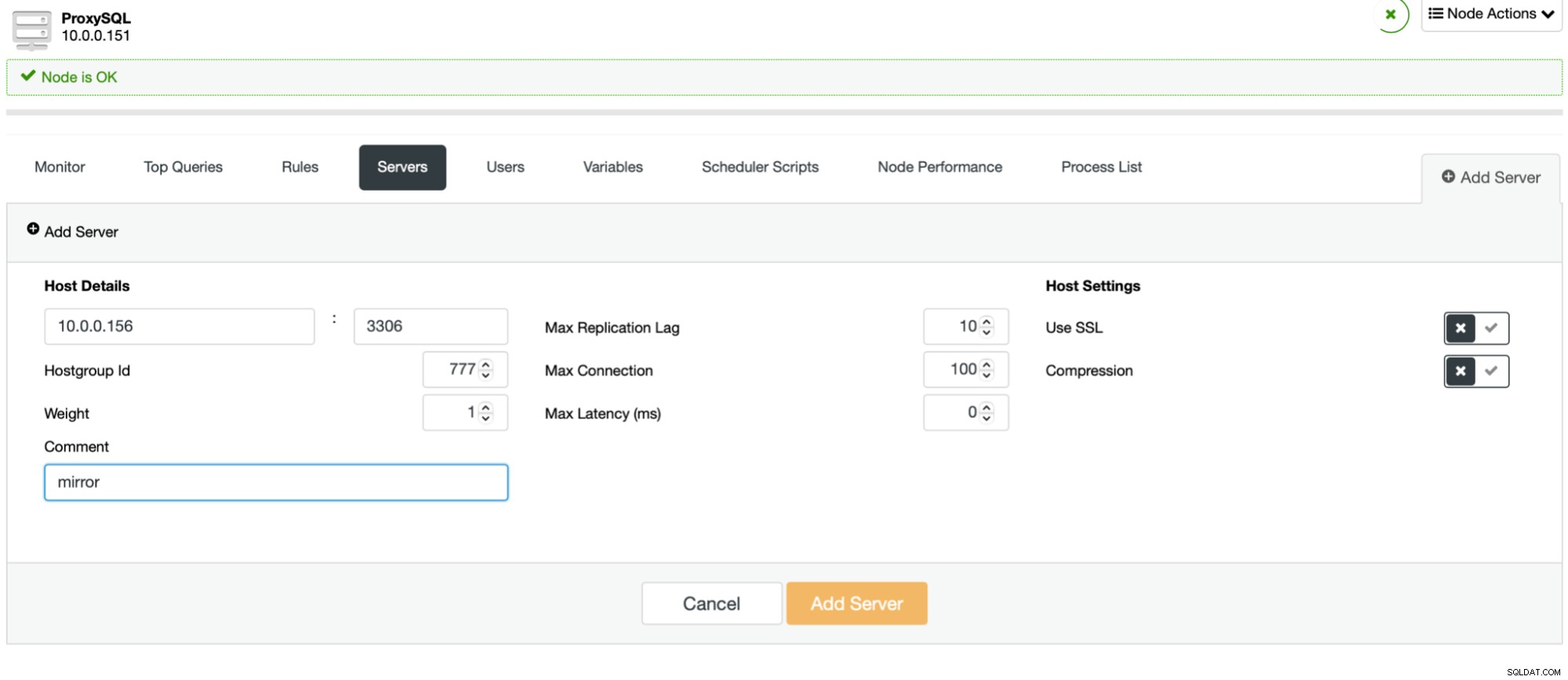
Der Prozess ist einfach. Zuerst sollten Sie die Knoten zu ProxySQL hinzufügen. Sie sollten zu einer separaten Hostgruppe gehören, die noch nicht verwendet wird. Stellen Sie sicher, dass der Benutzer des ProxySQL-Monitors darauf zugreifen kann.
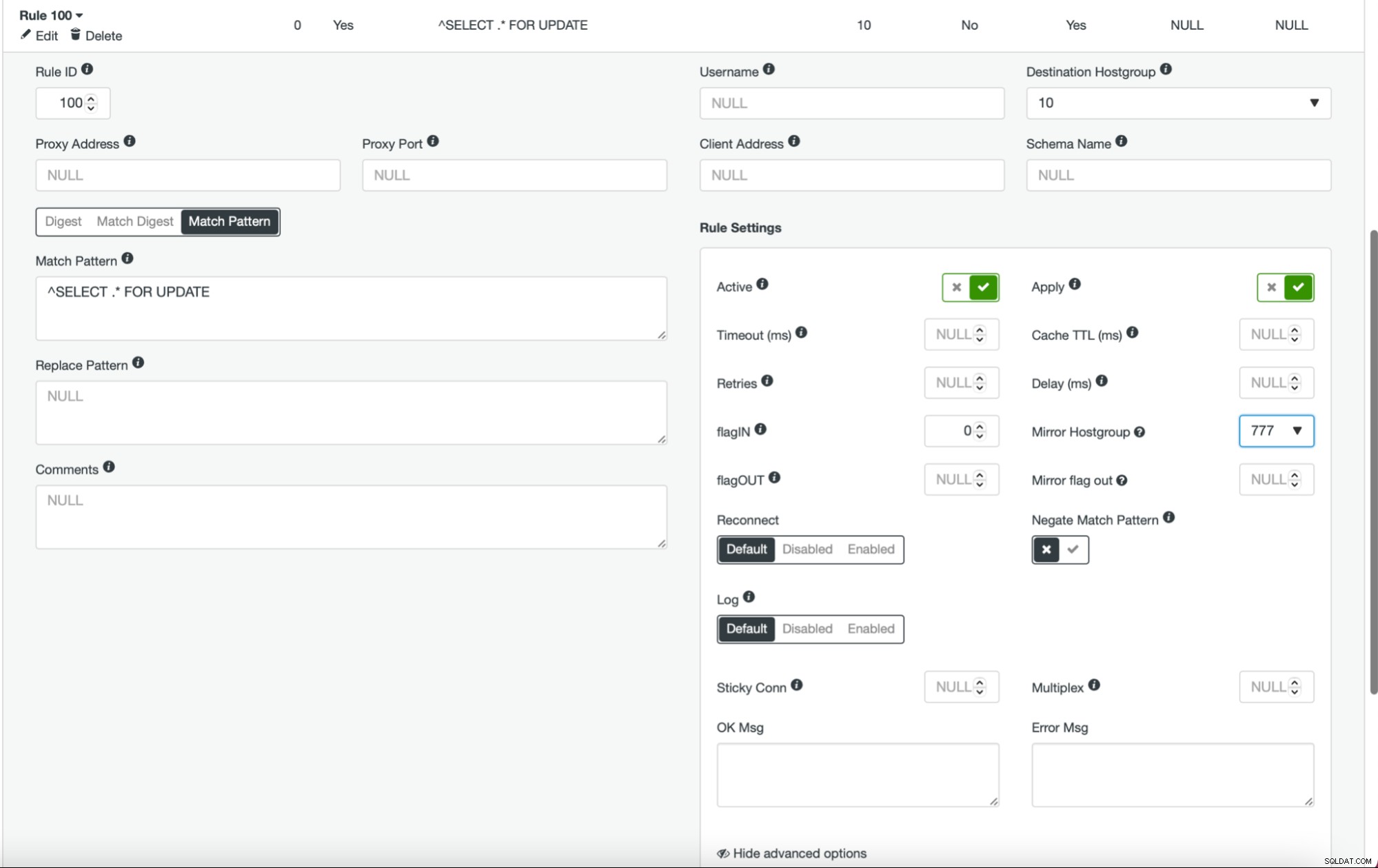
Sobald dies erledigt ist und Sie alle (oder einige) Ihrer Knoten in der Hostgruppe konfiguriert haben, können Sie die Abfrageregeln bearbeiten und die Spiegel-Hostgruppe definieren (sie ist in den erweiterten Optionen verfügbar). Wenn Sie dies für den gesamten Datenverkehr tun möchten, möchten Sie wahrscheinlich alle Ihre Abfrageregeln auf diese Weise bearbeiten. Wenn Sie nur SELECT-Abfragen spiegeln möchten, sollten Sie entsprechende Abfrageregeln bearbeiten. Danach sollte Ihr Staging-Cluster Produktionsdatenverkehr empfangen.
Cluster als Slave bereitstellen
Wie wir bereits besprochen haben, wäre eine alternative Lösung, einen neuen Cluster zu erstellen, der als Kopie des bestehenden Setups fungiert. Mit einem solchen Ansatz können wir alle Schreibvorgänge mithilfe der Replikation automatisch testen lassen. SELECTs können mit dem oben beschriebenen Ansatz getestet werden - Spiegelung durch ProxySQL.
Die Bereitstellung eines Slave-Clusters ist ziemlich einfach.
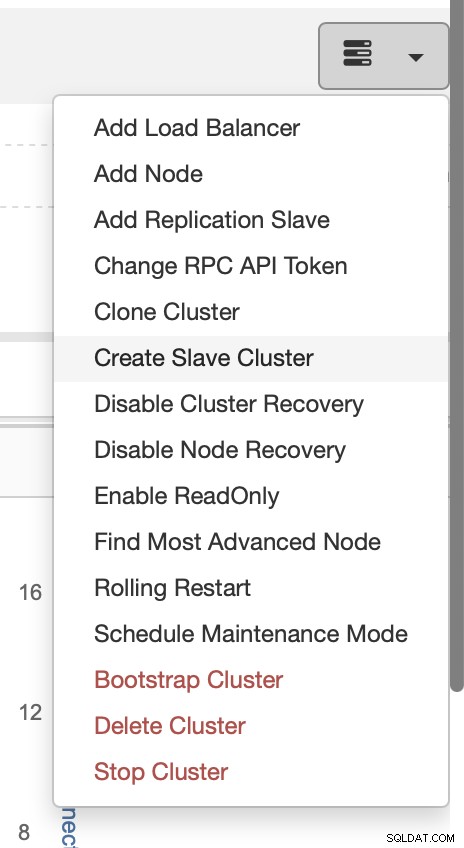
Wählen Sie den Job "Slave-Cluster erstellen".
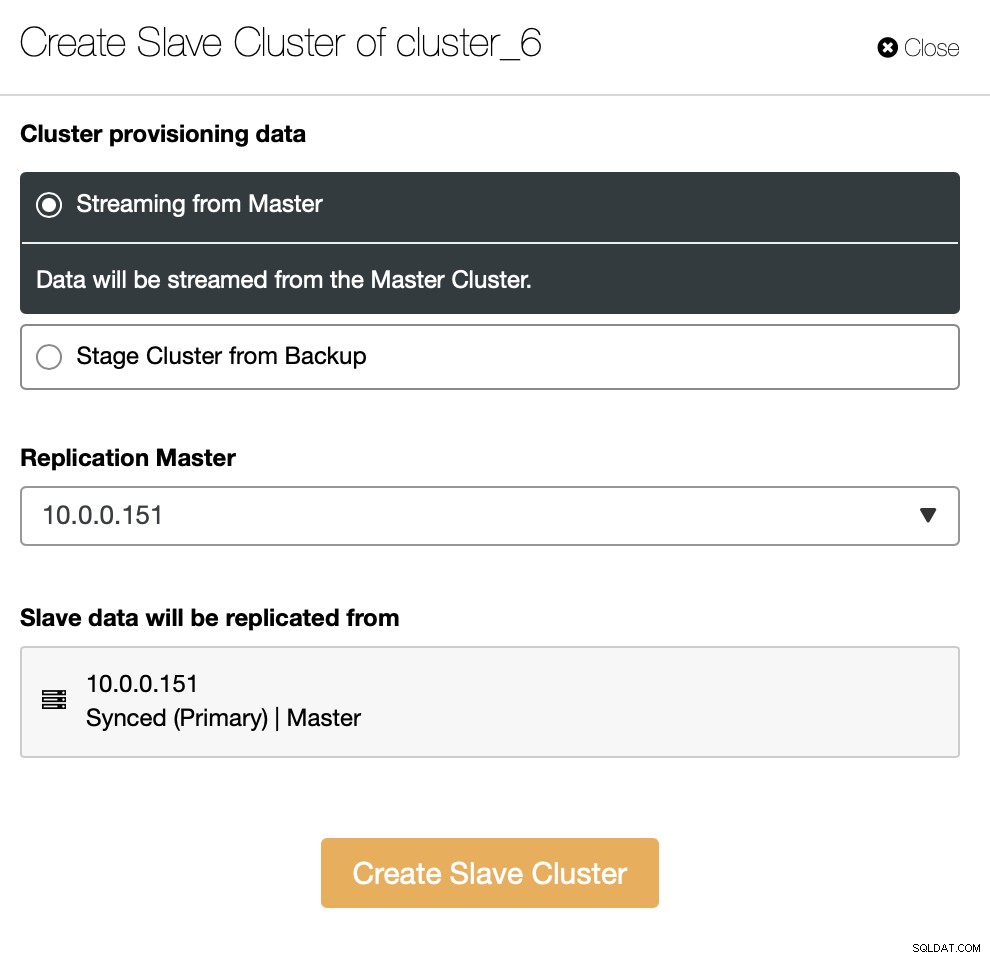
Sie müssen entscheiden, wie Sie das Replikationsset haben möchten. Sie können alle Daten vom Master auf die neuen Knoten übertragen lassen.
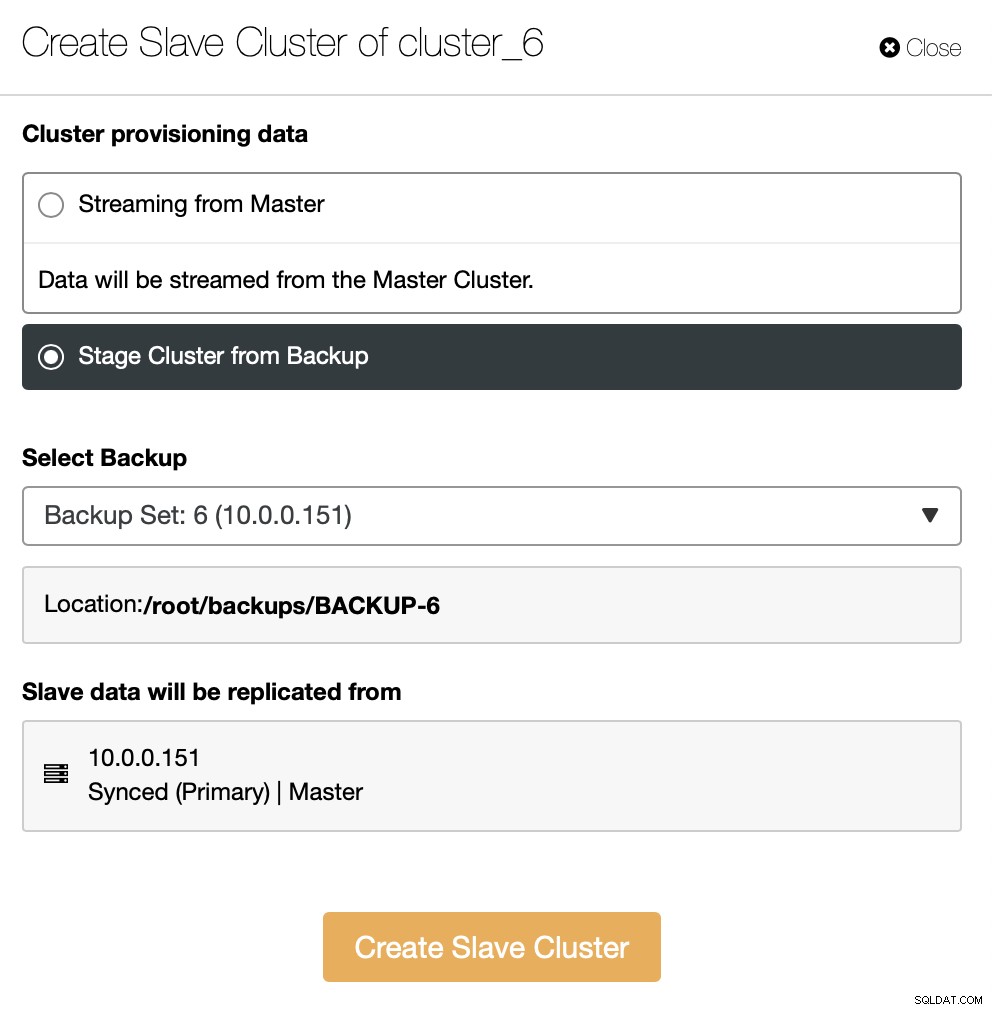
Alternativ können Sie ein vorhandenes Backup verwenden, um den neuen Cluster bereitzustellen. Dies trägt dazu bei, die Arbeitslast auf dem Master-Knoten zu reduzieren - anstatt alle Daten zu übertragen, müssen nur Transaktionen übertragen werden, die zwischen dem Zeitpunkt der Erstellung des Backups und dem Moment der Einrichtung der Replikation ausgeführt wurden.
Der Rest besteht darin, dem standardmäßigen Bereitstellungsassistenten zu folgen und SSH-Konnektivität, Version, Anbieter, Hosts usw. zu definieren. Nach der Bereitstellung sehen Sie den Cluster in der Liste.
Alternative Lösung zur Benutzeroberfläche besteht darin, dies über RPC zu erreichen.
{
"command": "create_cluster",
"job_data": {
"cluster_name": "",
"cluster_type": "galera",
"company_id": null,
"config_template": "my.cnf.80-pxc",
"data_center": 0,
"datadir": "/var/lib/mysql",
"db_password": "pass",
"db_user": "root",
"disable_firewall": true,
"disable_selinux": true,
"enable_mysql_uninstall": true,
"generate_token": true,
"install_software": true,
"port": "3306",
"remote_cluster_id": 6,
"software_package": "",
"ssh_keyfile": "/root/.ssh/id_rsa",
"ssh_port": "22",
"ssh_user": "root",
"sudo_password": "",
"type": "mysql",
"user_id": 5,
"vendor": "percona",
"version": "8.0",
"nodes": [
{
"hostname": "10.0.0.155",
"hostname_data": "10.0.0.155",
"hostname_internal": "",
"port": "3306"
},
{
"hostname": "10.0.0.159",
"hostname_data": "10.0.0.159",
"hostname_internal": "",
"port": "3306"
},
{
"hostname": "10.0.0.160",
"hostname_data": "10.0.0.160",
"hostname_internal": "",
"port": "3306"
}
],
"with_tags": []
}
}Vorwärts bewegen
Wenn Sie daran interessiert sind, mehr darüber zu erfahren, wie Sie Ihre Prozesse mit ClusterControl integrieren können, möchten wir Sie auf die Dokumentation verweisen, wo wir einen ganzen Abschnitt über die Entwicklung von Lösungen haben, bei denen ClusterControl eine Rolle spielt bedeutende Rolle:
https://docs.severalnines.com/docs/clustercontrol/developer-guide/cmon-rpc/
https://docs.severalnines.com/docs/clustercontrol/user-guide-cli/
Wir hoffen, Sie fanden diesen kurzen Blog informativ und nützlich. Wenn Sie Fragen zur Integration von ClusterControl in Ihre Umgebung haben, wenden Sie sich bitte an uns, und wir werden unser Bestes tun, um Ihnen zu helfen.