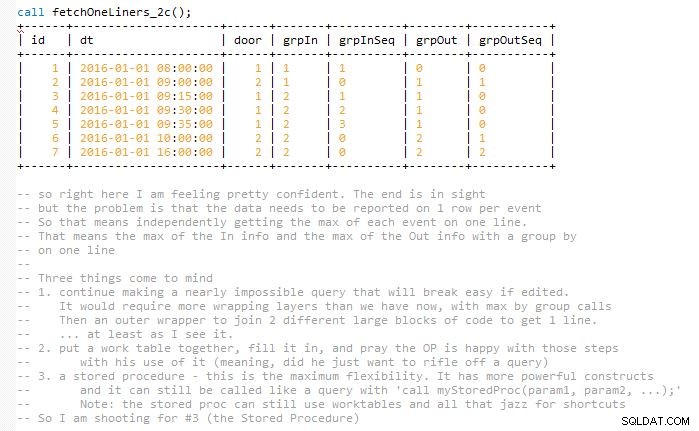
Dadurch soll die Lösung leicht wartbar bleiben, ohne die letzte Abfrage auf einen Schlag zu beenden, was ihre Größe (meiner Meinung nach) fast verdoppelt hätte. Dies liegt daran, dass die Ergebnisse übereinstimmen und in einer Zeile mit übereinstimmenden In- und Out-Ereignissen dargestellt werden müssen. Am Ende verwende ich also ein paar Arbeitstische. Es ist in einer gespeicherten Prozedur implementiert.
Die gespeicherte Prozedur verwendet mehrere Variablen, die mit einem cross join eingebracht werden . Stellen Sie sich den Cross Join nur als einen Mechanismus zum Initialisieren von Variablen vor. Die Variablen werden sicher gepflegt, so glaube ich, im Geiste dieses Dokument
oft in Variablenabfragen referenziert. Die wichtigen Teile der Referenz sind der sichere Umgang mit Variablen in einer Zeile, die erzwingen, dass sie vor anderen Spalten gesetzt werden, die sie verwenden. Dies wird durch greatest() erreicht und least() Funktionen, die eine höhere Priorität als Variablen haben, werden ohne die Verwendung dieser Funktionen festgelegt. Beachten Sie auch, dass coalesce() wird oft für den gleichen Zweck verwendet. Wenn ihre Verwendung seltsam erscheint, wie z. B. das Nehmen der größten Zahl, von der bekannt ist, dass sie größer als 0 oder 0 ist, nun, das ist Absicht. Bewusstes Erzwingen der Rangfolge der gesetzten Variablen.
Die Spalten in der Abfrage haben Dinge wie dummy2 genannt usw. sind Spalten, deren Ausgabe nicht verwendet wurde, aber sie wurden verwendet, um Variablen innerhalb von beispielsweise greatest() zu setzen oder ein anderes. Dies wurde oben erwähnt. Ausgabe wie 7777 war ein Platzhalter im 3. Platz, da ein Wert für if() benötigt wurde das wurde verwendet. Also ignoriere das alles.
Ich habe mehrere Screenshots des Codes eingefügt, während er Schicht für Schicht fortschritt, um Ihnen zu helfen, die Ausgabe zu visualisieren. Und wie diese Iterationen der Entwicklung langsam in die nächste Phase gefaltet werden, um die vorherige zu erweitern.
Ich bin sicher, dass meine Kollegen dies in einer Abfrage verbessern könnten. Ich hätte es so beenden können. Aber ich glaube, es hätte zu einem verwirrenden Durcheinander geführt, das bei Berührung zerbrechen würde.
Schema:
create table attendance2(Id int, DateTime datetime, Door char(20), Active_door char(20));
INSERT INTO attendance2 VALUES
( 1, '2016-01-01 08:00:00', 'In', ''),
( 2, '2016-01-01 09:00:00', 'Out', ''),
( 3, '2016-01-01 09:15:00', 'In', ''),
( 4, '2016-01-01 09:30:00', 'In', ''),
( 5, '2016-01-01 09:35:00', '', 'On'),
( 6, '2016-01-01 10:00:00', 'Out', ''),
( 7, '2016-01-01 16:00:00', '', 'Off');
drop table if exists oneLinersDetail;
create table oneLinersDetail
( -- architect this depending on multi-user concurrency
id int not null,
dt datetime not null,
door int not null,
grpIn int not null,
grpInSeq int not null,
grpOut int not null,
grpOutSeq int not null
);
drop table if exists oneLinersSummary;
create table oneLinersSummary
( -- architect this depending on multi-user concurrency
id int not null,
grpInSeq int null,
grpOutSeq int null,
checkIn datetime null, -- we are hoping in the end it is not null
checkOut datetime null -- ditto
);
Gespeicherte Prozedur:
DROP PROCEDURE IF EXISTS fetchOneLiners;
DELIMITER $$
CREATE PROCEDURE fetchOneLiners()
BEGIN
truncate table oneLinersDetail; -- architect this depending on multi-user concurrency
insert oneLinersDetail(id,dt,door,grpIn,grpInSeq,grpOut,grpOutSeq)
select id,dt,door,grpIn,grpInSeq,grpOut,grpOutSeq
from
( select id,dt,door,
if(@lastEvt!=door and door=1,
greatest(@grpIn:example@sqldat.com+1,0),
7777) as dummy2, -- this output column we don't care about (we care about the variable being set)
if(@lastEvt!=door and door=2,
greatest(@grpOut:example@sqldat.com+1,0),
7777) as dummy3, -- this output column we don't care about (we care about the variable being set)
if (@lastEvt!=door,greatest(@flip:=1,0),least(@flip:=0,1)) as flip,
if (door=1 and @flip=1,least(@grpOutSeq:=0,1),7777) as dummy4,
if (door=1 and @flip=1,greatest(@grpInSeq:=1,0),7777) as dummy5,
if (door=1 and @flip!=1,greatest(@grpInSeq:example@sqldat.comnSeq+1,0),7777) as dummy6,
if (door=2 and @flip=1,least(@grpInSeq:=0,1),7777) as dummy7,
if (door=2 and @flip=1,greatest(@grpOutSeq:=1,0),7777) as dummy8,
if (door=2 and @flip!=1,greatest(@grpOutSeq:example@sqldat.com+1,0),7777) as dummy9,
@grpIn as grpIn,
@grpInSeq as grpInSeq,
@grpOut as grpOut,
@grpOutSeq as grpOutSeq,
@lastEvt:=door as lastEvt
from
( select id,`datetime` as dt,
CASE
WHEN Door='in' or Active_door='on' THEN 1
ELSE 2
END as door
from attendance2
order by id
) xD1 -- derived table #1
cross join (select @grpIn:=0,@grpInSeq:=0,@grpOut:=0,@grpOutSeq:=0,@lastEvt:=-1,@flip:=0) xParams
order by id
) xD2 -- derived table #2
order by id;
-- select * from oneLinersDetail;
truncate table oneLinersSummary; -- architect this depending on multi-user concurrency
insert oneLinersSummary (id,grpInSeq,grpOutSeq,checkIn,checkOut)
select distinct grpIn,null,null,null,null
from oneLinersDetail
order by grpIn;
-- select * from oneLinersSummary;
update oneLinersSummary ols
join
( select grpIn,max(grpInSeq) m
from oneLinersDetail
where door=1
group by grpIn
) d1
on d1.grpIn=ols.id
set ols.grpInSeq=d1.m;
-- select * from oneLinersSummary;
update oneLinersSummary ols
join
( select grpOut,max(grpOutSeq) m
from oneLinersDetail
where door=2
group by grpOut
) d1
on d1.grpOut=ols.id
set ols.grpOutSeq=d1.m;
-- select * from oneLinersSummary;
update oneLinersSummary ols
join oneLinersDetail old
on old.door=1 and old.grpIn=ols.id and old.grpInSeq=ols.grpInSeq
set ols.checkIn=old.dt;
-- select * from oneLinersSummary;
update oneLinersSummary ols
join oneLinersDetail old
on old.door=2 and old.grpOut=ols.id and old.grpOutSeq=ols.grpOutSeq
set ols.checkOut=old.dt;
-- select * from oneLinersSummary;
-- dump out the results
select id,checkIn,checkOut
from oneLinersSummary
order by id;
-- rows are left in those two tables (oneLinersDetail,oneLinersSummary)
END$$
DELIMITER ;
Test:
call fetchOneLiners();
+----+---------------------+---------------------+
| id | checkIn | checkOut |
+----+---------------------+---------------------+
| 1 | 2016-01-01 08:00:00 | 2016-01-01 09:00:00 |
| 2 | 2016-01-01 09:35:00 | 2016-01-01 16:00:00 |
+----+---------------------+---------------------+
Dies ist das Ende der Antwort. Das Folgende dient zur Visualisierung der Schritte, die zum Abschluss der gespeicherten Prozedur geführt haben, durch einen Entwickler.
Versionen der Entwicklung, die bis zum Ende geführt haben. Hoffentlich hilft dies bei der Visualisierung, anstatt nur einen verwirrenden Codeblock mittlerer Größe zu löschen.
Schritt A
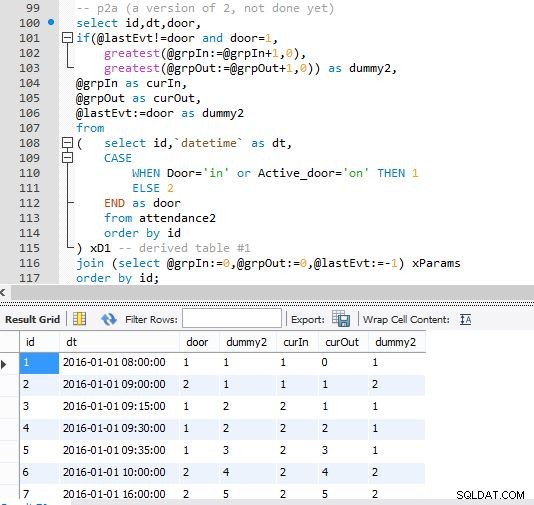
Schritt B
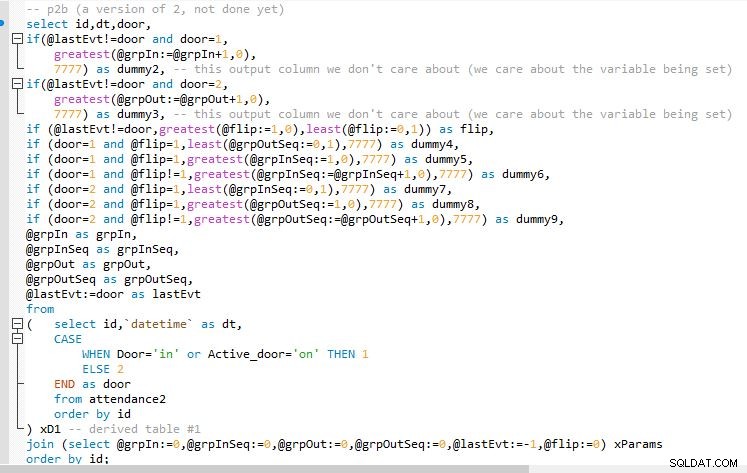
Ausgabe von Schritt B

Schritt C
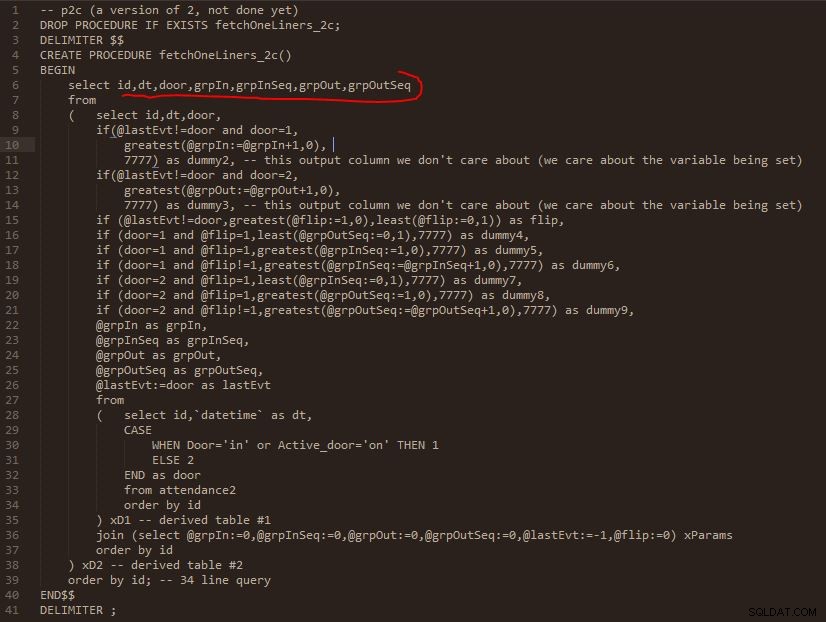
Ausgabe von Schritt C