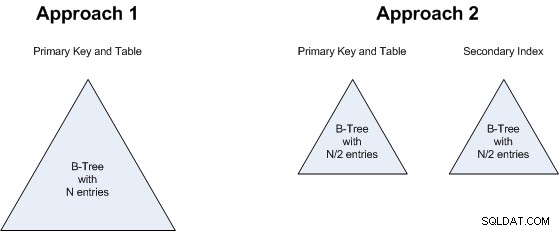
So werden diese beiden Ansätze physisch in der Datenbank dargestellt:
Lassen Sie uns beide Ansätze analysieren...
Approach 1 (beide Richtungen in der Tabelle hinterlegt):
- PRO:Einfachere Abfragen.
- CONT:Daten können nur durch Einfügen/Aktualisieren/Löschen beschädigt werden eine Richtung.
- MINOR PRO:Erfordert keine zusätzlichen Einschränkungen, um sicherzustellen, dass eine Freundschaft nicht dupliziert werden kann.
- Weitere Analyse erforderlich:
- TIE:Ein Index deckt ab beide Richtungen, sodass Sie keinen sekundären Index benötigen.
- TIE:Speicheranforderungen.
- TIE:Leistung.
Approach 2 (nur eine Richtung in der Tabelle gespeichert):
- CONT:Kompliziertere Abfragen.
- PRO:Die Daten können nicht beschädigt werden, indem vergessen wird, die entgegengesetzte Richtung zu behandeln, da es keine entgegengesetzte Richtung gibt .
- MINOR CON:Benötigt
CHECK(UID < FriendID), sodass dieselbe Freundschaft niemals auf zwei verschiedene Arten dargestellt werden kann, und der Schlüssel auf(UID, FriendID)kann seinen Job machen. - Weitere Analyse erforderlich:
- TIE:Zwei Indizes sind notwendig, um abzudecken
beide Abfragerichtungen (zusammengesetzter Index auf
{UID, FriendID}und zusammengesetzter Index auf{FriendID, UID}). - TIE:Speicheranforderungen.
- TIE:Leistung.
- TIE:Zwei Indizes sind notwendig, um abzudecken
beide Abfragerichtungen (zusammengesetzter Index auf
Der Punkt 1 ist von besonderem Interesse. MySQL/InnoDB immer Cluster Daten und Sekundärindizes können in geclusterten Tabellen teuer sein (siehe „Nachteile des Clustering“ in dieser Artikel ), so dass es den Anschein haben könnte, als würde der sekundäre Index in Ansatz 2 alle Vorteile von weniger Zeilen auffressen. Allerdings enthält der sekundäre Index genau die gleichen Felder wie der primäre (nur in umgekehrter Reihenfolge), sodass in diesem speziellen Fall kein Speicheraufwand entsteht. Es gibt auch keinen Zeiger auf den Tabellen-Heap (da es keinen Tabellen-Heap gibt), also ist es wahrscheinlich noch billiger in Bezug auf die Speicherung als ein normaler Heap-basierter Index. Und vorausgesetzt, die Abfrage ist mit dem Index abgedeckt, gibt es auch keine doppelte Suche, die normalerweise mit einem sekundären Index in einer gruppierten Tabelle verbunden ist. Dies ist also im Grunde ein Unentschieden (weder Ansatz 1 noch Ansatz 2 haben einen signifikanten Vorteil).
Der Punkt 2 hängt mit dem Punkt 1 zusammen:Es spielt keine Rolle, ob wir einen B-Baum mit N Werten haben oder zwei B-Bäume mit jeweils N/2 Werten. Das ist also auch ein Unentschieden:Beide Ansätze verbrauchen ungefähr die gleiche Menge an Speicherplatz.
Die gleiche Begründung gilt für Punkt 3 :Ob wir einen größeren B-Baum oder 2 kleinere suchen, macht keinen großen Unterschied, also ist dies auch ein Unentschieden.
Also, für die Robustheit, und trotz etwas hässlicher Abfragen und einem Bedarf an zusätzlichem CHECK , ich würde den Ansatz 2 wählen.