Ihre Frage zu Wie berechne ich die am engsten verwandten Städte? Zum Beispiel. Wenn ich mir Stadt 1 (Paris) ansehe, sollten die Ergebnisse lauten:London (2), New York (3) und basierend auf Ihrem bereitgestellten Datensatz gibt es nur eine Sache, die in Beziehung gesetzt werden muss, nämlich die gemeinsamen Tags zwischen den Städten, sodass die Städte, die die gemeinsamen Tags teilen, die nächsten wären, darunter die Unterabfrage, die die Städte findet (außer denen, die bereitgestellt werden). finden Sie die nächstgelegenen Städte), die die gemeinsamen Tags
teilenSELECT * FROM `cities` WHERE id IN (
SELECT city_id FROM `cities_tags` WHERE tag_id IN (
SELECT tag_id FROM `cities_tags` WHERE city_id=1) AND city_id !=1 )
Arbeiten
Ich nehme an, Sie geben eine der Stadt-IDs oder Namen ein, um die nächstgelegene zu finden. In meinem Fall hat "Paris" die ID
SELECT tag_id FROM `cities_tags` WHERE city_id=1
Es findet dann alle Tag-IDs, die Paris hat
SELECT city_id FROM `cities_tags` WHERE tag_id IN (
SELECT tag_id FROM `cities_tags` WHERE city_id=1) AND city_id !=1 )
Es werden alle Städte außer Paris abgerufen, die dieselben Tags wie Paris haben
Hier ist Ihre Fiddle
Beim Lesen über die Jaccard-Ähnlichkeit/den Index Ich habe einige Dinge gefunden, um zu verstehen, was die Begriffe eigentlich sind. Nehmen wir dieses Beispiel:Wir haben zwei Sätze A und B
Gehen Sie nun zu Ihrem Szenario
Hier ist die bisherige Abfrage, die den perfekten Jaccard-Index berechnet. Sie können das folgende Fiddle-Beispiel sehen
SELECT a.*,
( (CASE WHEN a.`intersect` =0 THEN a.`union` ELSE a.`intersect` END ) /a.`union`) AS jaccard_index
FROM (
SELECT q.* ,(q.sets + q.parisset) AS `union` ,
(q.sets - q.parisset) AS `intersect`
FROM (
SELECT cities.`id`, cities.`name` , GROUP_CONCAT(tag_id SEPARATOR ',') sets ,
(SELECT GROUP_CONCAT(tag_id SEPARATOR ',') FROM `cities_tags` WHERE city_id= 1)AS parisset
FROM `cities_tags`
LEFT JOIN `cities` ON (cities_tags.`city_id` = cities.`id`)
GROUP BY city_id ) q
) a ORDER BY jaccard_index DESC
In der obigen Abfrage habe ich die Ergebnismenge auf zwei Unterauswahlen abgeleitet, um meine benutzerdefinierten berechneten Aliase
zu erhalten
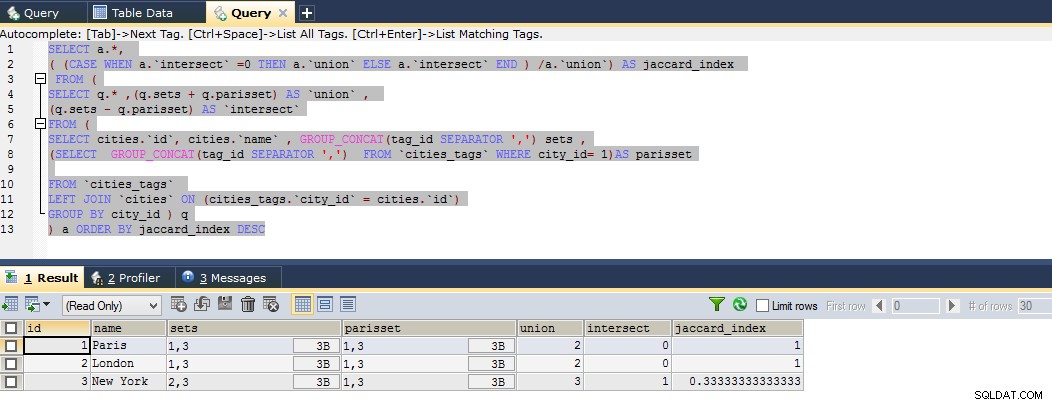
Sie können den Filter in der obigen Abfrage hinzufügen, um die Ähnlichkeit mit sich selbst nicht zu berechnen
SELECT a.*,
( (CASE WHEN a.`intersect` =0 THEN a.`union` ELSE a.`intersect` END ) /a.`union`) AS jaccard_index
FROM (
SELECT q.* ,(q.sets + q.parisset) AS `union` ,
(q.sets - q.parisset) AS `intersect`
FROM (
SELECT cities.`id`, cities.`name` , GROUP_CONCAT(tag_id SEPARATOR ',') sets ,
(SELECT GROUP_CONCAT(tag_id SEPARATOR ',') FROM `cities_tags` WHERE city_id= 1)AS parisset
FROM `cities_tags`
LEFT JOIN `cities` ON (cities_tags.`city_id` = cities.`id`) WHERE cities.`id` !=1
GROUP BY city_id ) q
) a ORDER BY jaccard_index DESC
Das Ergebnis zeigt also, dass Paris eng mit London und dann mit New York verwandt ist