Wenn Sie ClusterControl installieren, hat es eine Standardkonfiguration, die möglicherweise nicht Ihren Anforderungen entspricht, sodass Sie diese Installation wahrscheinlich anpassen müssen. Dazu können Sie die Konfigurationsdateien ändern, aber Sie können auch die ClusterControl-Einstellungen zur Laufzeit überprüfen oder ändern. In diesem Blog zeigen wir Ihnen, wo Sie diese Konfiguration sehen können und welche Optionen Sie hier verwenden können.
Wo können Sie die ClusterControl-Laufzeitkonfiguration sehen?
Es gibt zwei verschiedene Möglichkeiten, dies zu überprüfen. Zuerst können Sie zu ClusterControl -> Globale Einstellungen -> Laufzeitkonfigurationen gehen und dann Ihren Cluster auswählen.
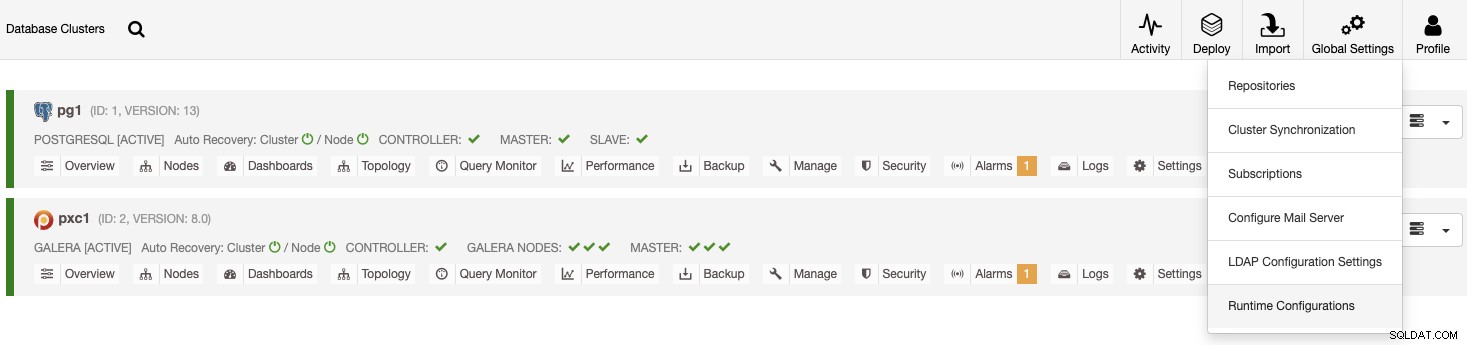
Eine andere Möglichkeit ist ClusterControl -> Cluster auswählen -> Einstellungen -> Laufzeitkonfigurationen .
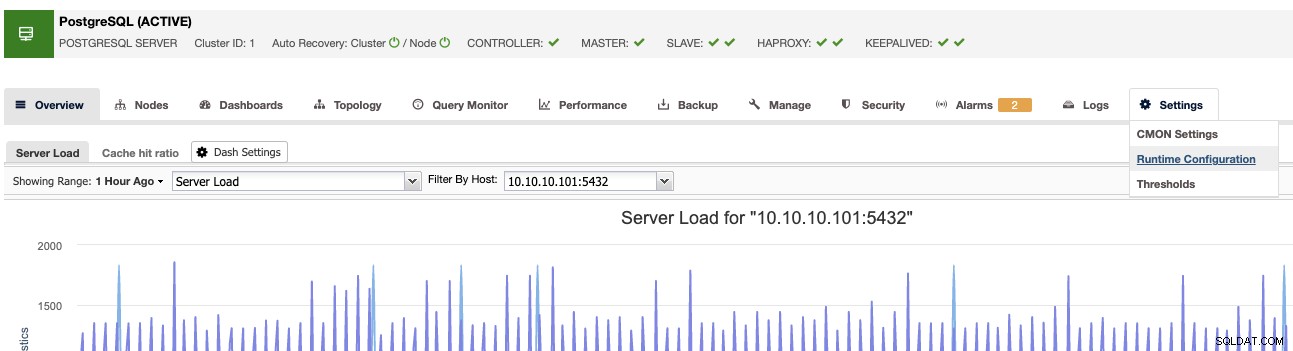
In beiden Fällen gelangen Sie zum selben Ort, der Laufzeitkonfiguration Abschnitt.
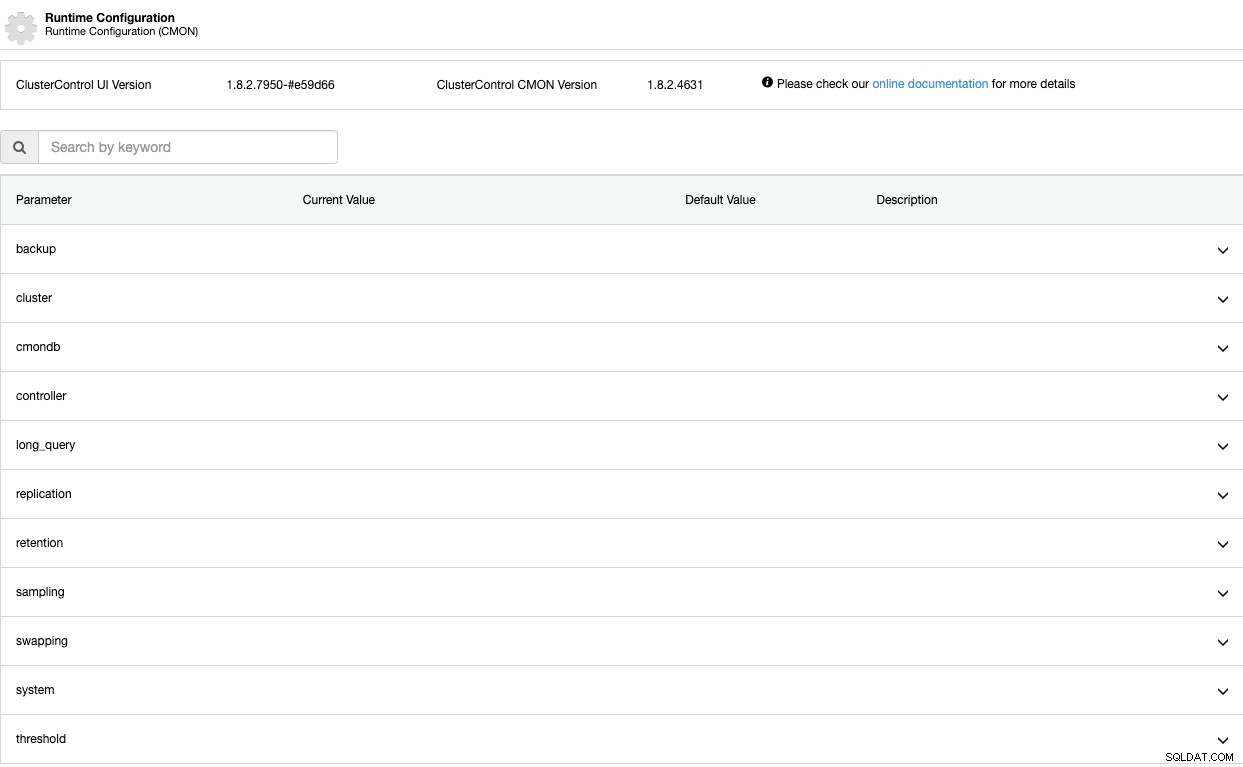
Laufzeit-Konfigurationsparameter
Sehen wir uns nun diese Parameter einen nach dem anderen an. Denken Sie daran, dass diese Parameter von der von Ihnen verwendeten Datenbanktechnologie abhängen, sodass Sie höchstwahrscheinlich nicht alle gleichzeitig im selben Cluster sehen werden.
Sicherung
| Name | Standardwert | Beschreibung |
|---|---|---|
| disable_backup_email | falsch | Diese Einstellung steuert, ob E-Mails gesendet werden oder nicht, wenn eine Sicherung abgeschlossen oder fehlgeschlagen ist. |
| backup_user | Sicherungsbenutzer | Der Benutzername des Datenbankkontos, das zum Verwalten von Sicherungen verwendet wird. |
| backup_create_hash | wahr | Konfiguriert ClusterControl, wenn es md5hash auf den erstellten Backup-Dateien berechnen und verifizieren muss. |
| pitr_retention_hours | 0 | Aufbewahrungszeit (um alte WAL-Archivprotokolle zu löschen) für PITR. |
| netcat_port | 9999,9990-9998 | Liste der Netcat-Ports und -Portbereiche, die zum Streamen von Backups verwendet werden. Standardmäßig '9999,9990-9998' und Port 9999 wird bevorzugt, falls verfügbar. |
| Sicherungsverzeichnis | /home/user/backups | Das Standard-Sicherungsverzeichnis, das im Frontend vorab ausgefüllt werden muss. |
| backup_subdir | BACKUP-%I | Legen Sie den Namen des Backup-Unterverzeichnisses fest. Diese Zeichenfolge kann standardmäßige „%X“-Feldtrennzeichen enthalten, das „%06I“ zum Beispiel wird durch die numerische ID der Sicherung im 6-Felder-weiten Format ersetzt, das „0“ als führende Füllzeichen verwendet. Hier ist die Liste der Felder, die das Backend derzeit unterstützt:- B Datum und Uhrzeit des Beginns der Backup-Erstellung. - H Der Name des Sicherungshosts, der Host, der die Sicherung erstellt hat. - i Die numerische ID des Clusters. - I Die numerische ID der Sicherung. - J Die numerische ID des Jobs, der die Sicherung erstellt hat. - M Die Sicherungsmethode (z. B. "mysqldump"). - O Der Name des Benutzers, der den Sicherungsjob initiiert hat. - S Der Name des Speicherhosts, des Hosts, der die Sicherungsdateien speichert. - % Das Prozentzeichen selbst. Verwenden Sie zwei Prozentzeichen, "%%" genauso wie die Standardfunktion printf() es als ein Prozentzeichen interpretiert. |
| backup_retention | 31 | Die Einstellung, wie viele Tage die Backups aufbewahrt werden sollen. Sicherungen, die der Aufbewahrungsfrist entsprechen, werden entfernt. |
| backup_cloud_retention | 180 | Die Einstellung, wie viele Tage die in eine Cloud hochgeladenen Backups aufbewahrt werden sollen. Sicherungen, die der Aufbewahrungsfrist entsprechen, werden entfernt. |
| backup_n_safety_copies | 1 | Die Einstellung, wie viele abgeschlossene vollständige Sicherungen unabhängig von ihrem Aufbewahrungsstatus aufbewahrt werden. |
Cluster
| Name | Standardwert | Beschreibung |
|---|---|---|
| Clustername | Der Name des Clusters zur einfachen Identifizierung. | |
| enable_node_autorecovery | wahr | Einstellung für automatische Knotenwiederherstellung. |
| enable_cluster_autorecovery | wahr | Wenn wahr, führt ClusterControl eine automatische Cluster-Wiederherstellung durch, wenn falsch, wird keine Cluster-Wiederherstellung automatisch durchgeführt. |
| configdir | /etc/ | Das Konfigurationsverzeichnis des Datenbankservers. |
| erstellt_durch_Job | Die ID des Jobs, der diesen Cluster erstellt hat. | |
| ssh_keypath | /home/user/.ssh/id_rsa | Die SSH-Schlüsseldatei, die für die Verbindung zu Knoten verwendet wird. |
| server_selection_try_once | wahr | MongoDB-Verbindungs-URI-Option. Definiert, ob die Serverauswahl bei einem Fehler wiederholt werden soll, bis ein Timeout für die Serverauswahl abläuft, oder ob sie bei einem Fehler sofort zurückkehren soll. |
| server_selection_timeout_ms | 30000 | MongoDB-Verbindungs-URI-Option. Definiert den Zeitüberschreitungswert, bis Mongodriver versuchen sollte, eine erfolgreiche Serverauswahl durchzuführen. |
| Eigentümer | Die ClusterControl-Benutzer-ID des Eigentümers des Cluster-Objekts. | |
| Gruppenbesitzer | Die ClusterControl-Gruppen-ID der Gruppe, die das Cluster-Objekt besitzt. | |
| cdt_Pfad | Der Speicherort des Cluster-Objekts im ClusterControl-Verzeichnisbaum. | |
| Tags | / | Eine Reihe von Zeichenfolgen, die der Benutzer angeben kann. |
| acl | Die Access Control List als String, der den Zugriff auf das Cluster-Objekt steuert. | |
| mongodb_user | admindb | Der MongoDB-Benutzername. |
| mongodb_basedir | /usr/ | Das basedir für die MongoDB-Installation. |
| mysql_basedir | /usr/ | Das basedir für die MySQL-Installation. |
| Skriptverzeichnis | /usr/bin/ | Das Skriptverzeichnis der MySQL-Installation. |
| staging_dir | /home/user/s9s_tmp | Ein Bereitstellungspfad für temporäre Dateien. |
| bindir | /usr/bin | Das /bin-Verzeichnis der MySQL-Installation. |
| monitored_mysql_port | 3306 | Die Portnummer des überwachten MySQL-Servers. |
| ndb_connectstring | 127.0.0.1:1186 | Die Einstellung der NDB-Verbindungszeichenfolge für MySQL Cluster. |
| ndbd_datadir | Das Datenverzeichnis der NDBD-Knoten. | |
| mgmd_datadir | Das Datenverzeichnis der NDB-MGMD-Knoten. | |
| os_user | Der SSH-Benutzername, der für den Zugriff auf Knoten verwendet wird. | |
| repl_user | cmon_replication | Der Replikationsbenutzername. |
| Verkäufer | Der Name des Datenbankanbieters, der für Bereitstellungen verwendet wird. | |
| galera_version | Die verwendete Galera-Versionsnummer. | |
| Serverversion | Die verwendete Datenbankserverversion für Bereitstellungen. | |
| postgresql_user | admindb | Der PostgreSQL-Benutzername. |
| galera_port | 4567 | Der zu verwendende Galera-Port, wenn nodes/garbd hinzugefügt und wsrep_cluster_address erstellt wird. Zur Laufzeit nicht ändern. |
| auto_manage_readonly | wahr | ClusterControl erlauben, das Nur-Lesen-Flag der verwalteten MySQL-Server zu verwalten. |
| node_recovery_lock_file | Geben Sie eine Sperrdatei an und wenn sie auf einem Knoten vorhanden ist, wird der Knoten nicht wiederhergestellt. Es liegt in der Verantwortung des Administrators, die Datei zu erstellen/zu entfernen. |
Cmondb
| Name | Standardwert | Beschreibung |
|---|---|---|
| cmon_db | cmon | Der Name der lokalen ClusterControl-Datenbank. |
| cmondb_hostname | 127.0.0.1 | Der Hostname des MySQL-Servers der lokalen ClusterControl-Datenbank. |
| mysql_port | 3306 | Der MySQL-Serverport der lokalen ClusterControl-Datenbank. |
| cmon_user | cmon | Der Kontoname für den Zugriff auf die lokale ClusterControl-Datenbank. |
Verantwortlicher
| Name | Standardwert | Beschreibung |
|---|---|---|
| controller_id | 5a3a993d-xxxx | Ein beliebiger Identifikator-String dieser Controller-Instanz. |
| cmon_hostname | 192.168.xx.xx | Der Controller-Hostname. |
| error_report_dir | /home/user/s9s_tmp | Speicherort von Fehlermeldungen. |
Lange_Abfrage
| Name | Standardwert | Beschreibung |
|---|---|---|
| lange_Abfragezeit | 0,5 | Schwellenwert für langsame Abfrageprüfung. |
| query_monitor_alert_long_running_query | wahr | Löst einen Alarm aus, wenn eine Abfrage länger als query_monitor_long_running_query_ms ausgeführt wird. |
| query_monitor_kill_long_running_query | falsch | Beenden Sie die Abfrage, wenn die Abfrage länger als query_monitor_long_running_query_ms ausgeführt wurde. |
| query_monitor_long_running_query_time_ms | 30000 | Löst einen Alarm aus, wenn eine Abfrage länger als query_monitor_long_running_query_ms ausgeführt wird. Der Mindestwert ist 1000. |
| query_monitor_long_running_query_matching_info | Passen Sie nur Abfragen mit einer 'Info' an, die nur mit dieser POSIX-Regex übereinstimmt. Kein Standardwert, Übereinstimmung mit allen Informationen. | |
| query_monitor_long_running_query_matching_info_negate | falsch | Negiere das Ergebnis von query_monitor_long_running_query_matching_info. |
| query_monitor_long_running_query_matching_host | Passen Sie nur Abfragen mit einem 'Host' an, der nur mit dieser POSIX-Regex übereinstimmt. Kein Standardwert, passt zu jedem Host. | |
| query_monitor_long_running_query_matching_db | Passen Sie nur Abfragen mit einer 'Db' an, die nur mit dieser POSIX-Regex übereinstimmt. Kein Standardwert, stimmt mit jeder Datenbank überein. | |
| query_monitor_long_running_query_matching_user | Passen Sie nur Abfragen mit einem 'Benutzer' an, der nur mit dieser POSIX-Regex übereinstimmt. Kein Standardwert, passt zu jedem Benutzer. | |
| query_monitor_long_running_query_matching_user_negate | falsch | Negiere das Ergebnis von query_monitor_long_running_query_matching_user. |
| query_monitor_long_running_query_matching_command | Abfrage | Passen Sie nur Abfragen mit einem 'Befehl' an, der nur mit dieser POSIX-Regex übereinstimmt. Standardmäßig 'Abfrage'. |
Replikation
| Name | Standardwert | Beschreibung |
|---|---|---|
| max_replication_lag | 10 | Maximal erlaubte Replikationsverzögerung in Sekunden, bevor ein Alarm gesendet wird. |
| replication_stop_on_error | wahr | Steuert, ob die Failover-/Switchover-Prozeduren fehlschlagen sollen, wenn Fehler auftreten, die zu Datenverlust führen können. |
| replication_auto_rebuild_slave | falsch | Wenn der SQL-THREAD gestoppt wird und der Fehlercode nicht Null ist, wird der Slave automatisch neu erstellt. |
| replication_failover_blacklist | Komma-getrennte Liste von Hostnamen:Port-Paaren. Server auf der schwarzen Liste werden während des Failovers nicht als Kandidat berücksichtigt. replication_failover_blacklist wird ignoriert, wenn replication_failover_whitelist gesetzt ist. | |
| replication_failover_whitelist | Komma-getrennte Liste von Hostnamen:Port-Paaren. Beim Failover werden nur Server auf der Whitelist als Kandidat berücksichtigt. Wenn kein Server auf der Whitelist verfügbar (aktiv/verbunden) ist, schlägt das Failover fehl. replication_failover_blacklist wird ignoriert, wenn replication_failover_whitelist gesetzt ist. | |
| replication_onfail_failover_script | Dieses Skript wird ausgeführt, sobald festgestellt wurde, dass ein Failover erforderlich ist. Wenn das Skript einen Wert ungleich Null zurückgibt oder nicht vorhanden ist, wird das Failover abgebrochen. Vier Argumente werden an das Skript geliefert und gesetzt, wenn sie bekannt sind, sonst leer:arg1='alle Server' arg2='ausgefallener Master' arg3='ausgewählter Kandidat', arg4='Slaves von Oldmaster (die Kandidaten)' und wie übergeben this:'scriptname arg1 arg2 arg3 arg4' Das Skript muss auf dem Controller zugänglich und ausführbar sein. | |
| replication_pre_failover_script | Dieses Skript wird ausgeführt, bevor das Failover stattfindet, aber nachdem ein Kandidat gewählt wurde und es möglich ist, den Failover-Prozess fortzusetzen. Wenn das Skript einen Wert ungleich Null zurückgibt oder nicht vorhanden ist, wird das Failover abgebrochen. Vier Argumente werden an das Skript geliefert und gesetzt, wenn sie bekannt sind, sonst leer:arg1='alle Server' arg2='ausgefallener Master' arg3='ausgewählter Kandidat', arg4='Slaves von Oldmaster (die Kandidaten)' und wie übergeben this:'scriptname arg1 arg2 arg3 arg4' Das Skript muss auf dem Controller zugänglich und ausführbar sein. | |
| replication_post_failover_script | Dieses Skript wird ausgeführt, nachdem das Failover stattgefunden hat (ein neuer Master wird gewählt und läuft). Wenn das Skript einen Wert ungleich Null zurückgibt oder nicht vorhanden ist, wird das Failover abgebrochen. Vier Argumente werden an das Skript geliefert und gesetzt, wenn sie bekannt sind, sonst leer.:arg1='alle Server' arg2='Master ausgefallen' arg3='ausgewählter Kandidat', arg4='Slaves von Oldmaster (die Kandidaten)' und übergeben etwa so:'scripname arg1 arg2 arg3 arg4' Das Skript muss auf dem Controller zugänglich und ausführbar sein. | |
| replication_post_unsuccessful_failover_script | Dieses Skript wird ausgeführt, wenn der Failover-Versuch fehlschlägt. Wenn das Skript einen Wert ungleich Null zurückgibt oder nicht vorhanden ist, wird das Failover abgebrochen. Vier Argumente werden an das Skript geliefert und gesetzt, wenn sie bekannt sind, sonst leer.:arg1='alle Server' arg2='Master ausgefallen' arg3='ausgewählter Kandidat', arg4='Slaves von Oldmaster (die Kandidaten)' und übergeben etwa so:'scripname arg1 arg2 arg3 arg4' Das Skript muss auf dem Controller zugänglich und ausführbar sein. |
Aufbewahrung
| Name | Standardwert | Beschreibung |
|---|---|---|
| ops_report_retention | 31 | Die Einstellung, wie viele Tage Betriebsberichte aufbewahrt werden sollen. Berichte mit übereinstimmender Aufbewahrungsfrist werden entfernt. |
Probenahme
| Name | Standardwert | Beschreibung |
|---|---|---|
| enable_icmp_ping | wahr | Schaltet um, ob ClusterControl die ICMP-Ping-Zeiten zum Host messen soll. |
| host_stats_collection_interval | 30 | Einstellung für das Erfassungsintervall des Hosts (CPU, Speicher usw.). |
| host_stats_window_size | 180 | Festlegen der Fenstergröße (in Sekunden) zum Untersuchen von Statistiken zum Auslösen/Löschen von Host-Statistik-Alarmen. |
| db_stats_collection_interval | 30 | Einstellung für das Erfassungsintervall der Datenbankstatistiken. |
| db_proc_stats_collection_interval | 5 | Einstellung für das Erfassungsintervall für Datenbankprozessstatistiken. Der zulässige Mindestwert beträgt 1 Sekunde. Erfordert einen Neustart des cmon-Dienstes. |
| lb_stats_collection_interval | 15 | Einstellung für das Erfassungsintervall der Load-Balancer-Statistiken. |
| db_schema_stats_collection_interval | 108000 | Einstellung für Schema-Statistik-Überwachungsintervall. |
| db_deadlock_check_interval | 0 | Wie oft auf Deadlocks geprüft werden soll. Angabe in Sekunden. Deadlock-Erkennung wirkt sich auf die CPU-Auslastung auf Datenbankknoten aus. |
| log_collection_interval | 600 | Steuert das Intervall zwischen den Protokolldateisammlungen. |
| db_hourly_stats_collection_interval | 5 | Steuert, wie viele Sekunden zwischen jedem einzelnen Sample in der stündlichen Bereichsstatistik liegen. |
| monitored_mountpoints | Die Liste der zu überwachenden Einhängepunkte. | |
| monitor_cpu_temperature | falsch | CPU-Temperatur überwachen. |
| log_queries_not_using_indexes | falsch | Stellen Sie den Abfragemonitor so ein, dass er Abfragen erkennt, die keine Indizes verwenden. |
| query_sample_interval | 1 | Steuert das Abfrageüberwachungsintervall in Sekunden, -1 bedeutet keine Abfrageüberwachung. |
| query_monitor_auto_purge_ps | falsch | Wenn aktiviert, wird die P_S-Tabelle events_statements_summary_by_digest jede Stunde automatisch gelöscht (TRUNCATE TABLE). |
| schema_change_detection_address | Überprüfungen werden ausgeführt (mithilfe von SHOW TABLES/SHOW CREATE TABLE), um festzustellen, ob sich das Schema geändert hat. Die Prüfungen werden auf der angegebenen Adresse ausgeführt und haben das Format HOSTNAME:PORT. Die schema_change_detection_databases müssen ebenfalls festgelegt werden. Ein Diff einer geänderten Tabelle wird erstellt. | |
| schema_change_detection_databases | Komma-separierte Liste von Datenbanken, die auf Schemaänderungen überwacht werden sollen. Wenn leer, werden keine Prüfungen durchgeführt. | |
| schema_change_detection_pause_time_ms | 0 | Pausenzeit in ms zwischen jedem SHOW CREATE TABLE. Die Pausenzeit wirkt sich auf die Dauer des Erkennungsprozesses aus. |
| enable_is_queries | wahr | Gibt an, ob Abfragen an das information_schema ausgeführt werden oder nicht. Abfragen an das information_schema sind möglicherweise nicht geeignet, wenn viele Schemaobjekte vorhanden sind (Hunderte von Datenbanken, Hunderte von Tabellen in jeder Datenbank, Trigger, Benutzer, Ereignisse, Sprocs). Wenn deaktiviert, wird die ausgeführte Abfrage protokolliert, sodass festgestellt werden kann, ob die Abfrage für Ihre Umgebung geeignet ist. |
Austauschen
| Name | Standardwert | Beschreibung |
|---|---|---|
| swap_warning | 20 | Warnungsalarmschwelle für Swap-Nutzung. |
| swap_critical | 90 | Kritische Alarmschwelle für Swap-Nutzung. |
| swap_inout_period | 0 | Das Intervall für Swap-E/A-Alarme (<=0 deaktiviert). |
| swap_inout_warning | 10240 | Die Anzahl der Seiten, die I/O im angegebenen Intervall (swap_inout_period, standardmäßig 10 Minuten) für die Warnung ausgetauscht haben. |
| swap_inout_critical | 102400 | Die Anzahl der Seiten, die E/A im angegebenen Intervall (swap_inout_period, standardmäßig 10 Minuten) für kritisch ausgetauscht haben. |
System
| Name | Standardwert | Beschreibung |
|---|---|---|
| cmon_config_path | /etc/cmon.d/cmon_x.cnf | Der Pfad der Konfigurationsdatei. Dieser Konfigurationswert ist schreibgeschützt. |
| os | debian/redhat | Der Betriebssystemtyp. Mögliche Werte sind „debian“ oder „redhat“. |
| libssh_timeout | 30 | Der Netzwerkzeitüberschreitungswert für SSH-Verbindungen. |
| sudo | sudo -n 2>/dev/null | Der Befehl, der verwendet wird, um Superuser-Privilegien zu erhalten. |
| ssh_port | 22 | Der Port für SSH-Verbindungen zu den Knoten. |
| lokaler_repo_name | Die verwendeten lokalen Repository-Namen für die Clusterbereitstellung. | |
| frontend_url | Die in den E-Mails gesendete URL, um den Empfänger zur ClusterControl-Weboberfläche zu leiten. | |
| löschen | 7 | Wie lange ClusterControl Daten aufbewahren soll. Gemessen in Tagen werden Jobs, Jobmeldungen, Alarme, gesammelte Protokolle, Betriebsberichte, Datenbankwachstumsinformationen, die älter sind, gelöscht. |
| os_user_home | /home/user | Das HOME-Verzeichnis des Benutzers, der auf Knoten verwendet wird. |
| cmon_mail_sender | Der verwendete E-Mail-Absender für gesendete E-Mails. | |
| plugin_dir | Der Pfad des Plugin-Verzeichnisses. | |
| use_internal_repos | falsch | Einstellung, die das Einrichten des Drittanbieter-Repositorys verhindert. |
| cmon_use_mail | falsch | Einstellung zur Verwendung des 'mail'-Befehls für den E-Mail-Versand. |
| enable_html_emails | wahr | Aktiviert das Versenden von HTML-E-Mails. |
| send_clear_alarm | wahr | Schaltet den E-Mail-Versand um, wenn Cluster-Alarme gelöscht werden. |
| software_packagedir | Dies ist der Speicherort von Softwarepaketen, d.h. alle notwendigen Dateien, um einen Knoten erfolgreich zu installieren, wenn kein yum/apt-Repository verfügbar ist, müssen hier abgelegt werden. Gilt hauptsächlich für MySQL Cluster oder ältere Codership/Galera-Installationen. |
Schwellenwert
| Name | Standardwert | Beschreibung |
|---|---|---|
| ram_warning | 80 | Warnungsalarmschwelle für RAM-Nutzung. |
| ram_kritisch | 90 | Kritische Alarmschwelle für RAM-Nutzung. |
| diskspace_warning | 80 | Warnungsalarmschwelle für Festplattennutzung. |
| diskspace_critical | 90 | Kritischer Alarmschwellenwert für Festplattennutzung. |
| cpu_warning | 80 | Warnungsalarmschwelle für CPU-Auslastung. |
| cpu_kritisch | 90 | Kritischer Alarmschwellenwert für CPU-Auslastung. |
| cpu_steal_warning | 10 | Warnungsalarmschwelle für CPU-Diebstahl. |
| cpu_steal_critical | 20 | Kritische Alarmschwelle für CPU-Diebstahl. |
| cpu_iowait_warning | 50 | Warnungsalarmschwelle für CPU IO Wait. |
| cpu_iowait_critical | 60 | Kritischer Alarmschwellenwert für CPU IO Wait. |
| slow_ssh_warning | 6 | Ein Warnalarm wird ausgelöst, wenn der Aufbau einer SSH-Verbindung länger als die angegebene Zeit (Sek.) dauert. |
| slow_ssh_critical | 12 | Ein kritischer Alarm wird ausgelöst, wenn der Aufbau einer SSH-Verbindung länger als die angegebene Zeit (Sek.) dauert. |
Fazit
Wie Sie sehen, müssen viele Parameter geändert werden, wenn Sie ClusterControl an Ihre Arbeitslast oder Ihr Unternehmen anpassen müssen. Es kann eine zeitaufwändige Aufgabe sein, alle Werte zu überprüfen und entsprechend zu ändern, aber am Ende des Tages spart es Zeit, da Sie alle ClusterControl-Funktionen optimal nutzen können.



