Eines der größten Probleme beim Umgang mit und der Verwaltung von Datenbanken ist die Komplexität von Daten und Größe. Häufig machen sich Unternehmen Sorgen darüber, wie sie mit Wachstum umgehen und die Auswirkungen des Wachstums verwalten sollen, weil das Datenbankmanagement versagt. Komplexität bringt Bedenken mit sich, die ursprünglich nicht angesprochen und nicht gesehen wurden oder übersehen werden konnten, da die derzeit verwendete Technologie in der Lage sein sollte, sich selbst zu bewältigen. Die Verwaltung einer komplexen und großen Datenbank muss entsprechend geplant werden, insbesondere wenn erwartet wird, dass die Art der Daten, die Sie verwalten oder handhaben, entweder erwartet oder auf unvorhersehbare Weise massiv wachsen wird. Das Hauptziel der Planung ist es, ungewollte Katastrophen zu vermeiden, oder sagen wir besser, nicht in Rauch aufgehen! In diesem Blog behandeln wir die effiziente Verwaltung großer Datenbanken.
Datengröße spielt eine Rolle
Die Größe der Datenbank spielt eine Rolle, da sie sich auf die Leistung und ihre Verwaltungsmethodik auswirkt. Wie die Daten verarbeitet und gespeichert werden, trägt dazu bei, wie die Datenbank verwaltet wird, was sowohl für übertragene als auch für gespeicherte Daten gilt. Für viele große Organisationen sind Daten Gold, und das Datenwachstum könnte den Prozess drastisch verändern. Daher ist es wichtig, im Voraus Pläne zu haben, wie die wachsenden Datenmengen in einer Datenbank verarbeitet werden können.
In meiner Erfahrung mit Datenbanken habe ich erlebt, wie Kunden Probleme mit Leistungseinbußen und der Bewältigung eines extremen Datenwachstums hatten. Es stellen sich Fragen, ob die Tabellen normalisiert oder die Tabellen denormalisiert werden sollen.
Tabellen normalisieren
Das Normalisieren von Tabellen erhält die Datenintegrität, reduziert Redundanzen und vereinfacht die Organisation der Daten für eine effizientere Verwaltung, Analyse und Extraktion. Die Arbeit mit normalisierten Tabellen führt zu Effizienz, insbesondere bei der Analyse des Datenflusses und dem Abrufen von Daten entweder durch SQL-Anweisungen oder bei der Arbeit mit Programmiersprachen wie C/C++, Java, Go, Ruby, PHP oder Python-Schnittstellen mit den MySQL-Konnektoren.
Obwohl Bedenken mit normalisierten Tabellen zu Leistungseinbußen führen und die Abfragen aufgrund einer Reihe von Verknüpfungen beim Abrufen der Daten verlangsamen können. Während bei denormalisierten Tabellen alles, was Sie für die Optimierung berücksichtigen müssen, auf den Index oder den Primärschlüssel angewiesen ist, um Daten für einen schnelleren Abruf im Puffer zu speichern, als die Suche auf mehreren Festplatten durchzuführen. Denormalisierte Tabellen erfordern keine Verknüpfungen, opfern jedoch die Datenintegrität und die Datenbankgröße wird tendenziell immer größer.
Wenn Ihre Datenbank groß ist, erwägen Sie eine DDL (Data Definition Language) für Ihre Datenbanktabelle in MySQL/MariaDB. Das Hinzufügen eines Primärschlüssels oder eindeutigen Schlüssels für Ihre Tabelle erfordert eine Neuerstellung der Tabelle. Das Ändern eines Spaltendatentyps erfordert auch einen Tabellenneuaufbau, da der anzuwendende Algorithmus nur ALGORITHM=COPY ist.
Wenn Sie dies in Ihrer Produktionsumgebung tun, kann es eine Herausforderung sein. Verdoppeln Sie die Herausforderung, wenn Ihr Tisch riesig ist. Stellen Sie sich eine Million oder eine Milliarde Zeilen vor. Sie können eine ALTER TABLE-Anweisung nicht direkt auf Ihre Tabelle anwenden. Dadurch kann der gesamte eingehende Datenverkehr blockiert werden, der auf die Tabelle zugreifen muss, in der Sie derzeit die DDL anwenden. Dies kann jedoch durch die Verwendung von pt-online-schema-change oder Great gh-ost abgemildert werden. Trotzdem erfordert es Überwachung und Wartung während des DDL-Prozesses.
Sharding und Partitionierung
Mit Sharding und Partitionierung hilft es, die Daten gemäß ihrer logischen Identität zu trennen oder zu segmentieren. Zum Beispiel durch Trennung nach Datum, alphabetischer Reihenfolge, Land, Staat oder Primärschlüssel basierend auf dem angegebenen Bereich. Dies trägt dazu bei, dass Ihre Datenbankgröße überschaubar ist. Halten Sie Ihre Datenbankgröße so weit, dass sie für Ihre Organisation und Ihr Team überschaubar ist. Bei Bedarf einfach zu skalieren oder einfach zu verwalten, insbesondere im Katastrophenfall.
Wenn wir von überschaubar sprechen, sollten Sie auch die Kapazitätsressourcen Ihres Servers und auch Ihres Engineering-Teams berücksichtigen. Sie können nicht mit wenigen Ingenieuren mit großen und großen Datenmengen arbeiten. Die Arbeit mit Big Data wie 1000 Datenbanken mit vielen Datensätzen erfordert einen enormen Zeitaufwand. Geschicklichkeit und Fachwissen sind ein Muss. Wenn die Kosten ein Problem sind, ist dies der Zeitpunkt, an dem Sie Dienste von Drittanbietern nutzen können, die Managed Services oder kostenpflichtige Beratung oder Unterstützung für solche Engineering-Arbeiten anbieten.
Zeichensätze und Sortierung
Zeichensätze und Sortierungen wirken sich auf die Datenspeicherung und -leistung aus, insbesondere auf den angegebenen Zeichensatz und die ausgewählten Sortierungen. Jeder Zeichensatz und jede Sortierung hat seinen Zweck und erfordert meist unterschiedliche Längen. Wenn Sie Tabellen haben, die aufgrund der Zeichencodierung andere Zeichensätze und Sortierungen erfordern, müssen die Daten für Ihre Datenbank und Tabellen oder sogar mit Spalten gespeichert und verarbeitet werden.
Dies wirkt sich auf die effektive Verwaltung Ihrer Datenbank aus. Wie bereits erwähnt, wirkt sich dies auf Ihren Datenspeicher und die Leistung aus. Wenn Sie verstanden haben, welche Arten von Zeichen von Ihrer Anwendung verarbeitet werden sollen, beachten Sie den zu verwendenden Zeichensatz und die zu verwendenden Sortierungen. Für die zu speichernden und zu verarbeitenden Zeichensätze der alphanumerischen Art genügen meist LATEINISCHE Zeichensätze.
Wenn es unvermeidlich ist, helfen Sharding und Partitionierung dabei, die Daten zumindest abzumildern und zu begrenzen, um zu vermeiden, dass zu viele Daten auf Ihrem Datenbankserver aufgebläht werden. Die Verwaltung sehr großer Daten auf einem einzigen Datenbankserver kann die Effizienz beeinträchtigen, insbesondere für Sicherungszwecke, Notfall und Wiederherstellung oder Datenwiederherstellung sowie im Falle von Datenbeschädigung oder Datenverlust.
Datenbankkomplexität wirkt sich auf die Leistung aus
Eine große und komplexe Datenbank hat tendenziell einen Faktor, wenn es um Leistungseinbußen geht. Komplex bedeutet in diesem Fall, dass der Inhalt Ihrer Datenbank aus mathematischen Gleichungen, Koordinaten oder numerischen und finanziellen Aufzeichnungen besteht. Jetzt werden diese Datensätze mit Abfragen gemischt, die die mathematischen Funktionen der Datenbank aggressiv verwenden. Sehen Sie sich die Beispiel-SQL-Abfrage (kompatibel mit MySQL/MariaDB) unten an,
SELECT
ATAN2( PI(),
SQRT(
pow(`a`.`col1`-`a`.`col2`,`a`.`powcol`) +
pow(`b`.`col1`-`b`.`col2`,`b`.`powcol`) +
pow(`c`.`col1`-`c`.`col2`,`c`.`powcol`)
)
) a,
ATAN2( PI(),
SQRT(
pow(`b`.`col1`-`b`.`col2`,`b`.`powcol`) -
pow(`c`.`col1`-`c`.`col2`,`c`.`powcol`) -
pow(`a`.`col1`-`a`.`col2`,`a`.`powcol`)
)
) b,
ATAN2( PI(),
SQRT(
pow(`c`.`col1`-`c`.`col2`,`c`.`powcol`) *
pow(`b`.`col1`-`b`.`col2`,`b`.`powcol`) /
pow(`a`.`col1`-`a`.`col2`,`a`.`powcol`)
)
) c
FROM
a
LEFT JOIN `a`.`pk`=`b`.`pk`
LEFT JOIN `a`.`pk`=`c`.`pk`
WHERE
((`a`.`col1` * `c`.`col1` + `a`.`col1` * `b`.`col1`)/ (`a`.`col2`))
between 0 and 100
AND
SQRT(((
(0 + (
(((`a`.`col3` * `a`.`col4` + `b`.`col3` * `b`.`col4` + `c`.`col3` + `c`.`col4`)-(PI()))/(`a`.`col2`)) *
`b`.`col2`)) -
`c`.`col2) *
((0 + (
((( `a`.`col5`* `b`.`col3`+ `b`.`col4` * `b`.`col5` + `c`.`col2` `c`.`col3`)-(0))/( `c`.`col5`)) *
`b`.`col3`)) -
`a`.`col5`)) +
((
(0 + (((( `a`.`col5`* `b`.`col3` + `b`.`col5` * PI() + `c`.`col2` / `c`.`col3`)-(0))/( `c`.`col5`)) * `b`.`col5`)) -
`b`.`col5` ) *
((0 + (((( `a`.`col5`* `b`.`col3` + `b`.`col5` * `c`.`col2` + `b`.`col2` / `c`.`col3`)-(0))/( `c`.`col5`)) * -20.90625)) - `b`.`col5`)) +
(((0 + (((( `a`.`col5`* `b`.`col3` + `b`.`col5` * `b`.`col2` +`a`.`col2` / `c`.`col3`)-(0))/( `c`.`col5`)) * `c`.`col3`)) - `b`.`col5`) *
((0 + (((( `a`.`col5`* `b`.`col3` + `b`.`col5` * `b`.`col2`5 + `c`.`col3` / `c`.`col2`)-(0))/( `c`.`col5`)) * `c`.`col3`)) - `b`.`col5`
))) <=600
ORDER BY
ATAN2( PI(),
SQRT(
pow(`a`.`col1`-`a`.`col2`,`a`.`powcol`) +
pow(`b`.`col1`-`b`.`col2`,`b`.`powcol`) +
pow(`c`.`col1`-`c`.`col2`,`c`.`powcol`)
)
) DESC
Bedenken Sie, dass diese Abfrage auf eine Tabelle mit einer Million Zeilen angewendet wird. Es besteht die große Möglichkeit, dass dies den Server zum Stillstand bringen kann, und es könnte ressourcenintensiv sein und die Stabilität Ihres Produktionsdatenbankclusters gefährden. Beteiligte Spalten werden in der Regel indiziert, um diese Abfrage zu optimieren und leistungsfähig zu machen. Das Hinzufügen von Indizes zu den referenzierten Spalten für eine optimale Leistung garantiert jedoch nicht die Effizienz der Verwaltung Ihrer großen Datenbanken.
Bei der Handhabung von Komplexität ist es am effizientesten, die rigorose Verwendung komplexer mathematischer Gleichungen und die aggressive Nutzung dieser integrierten komplexen Rechenfähigkeit zu vermeiden. Dies kann durch komplexe Berechnungen mit Backend-Programmiersprachen betrieben und transportiert werden, anstatt die Datenbank zu verwenden. Wenn Sie komplexe Berechnungen haben, warum speichern Sie diese Gleichungen dann nicht in der Datenbank, rufen die Abfragen ab, organisieren sie in einer einfacher zu analysierenden oder bei Bedarf zu debuggenden Form.
Verwenden Sie die richtige Datenbank-Engine?
Eine Datenstruktur beeinflusst die Leistung des Datenbankservers basierend auf der Kombination der gegebenen Abfrage und der Datensätze, die aus der Tabelle gelesen oder abgerufen werden. Die Datenbank-Engines in MySQL/MariaDB unterstützen InnoDB und MyISAM, die B-Trees verwenden, während NDB- oder Memory-Datenbank-Engines Hash-Mapping verwenden. Diese Datenstrukturen haben ihre asymptotische Notation, wobei letztere die Leistung der von diesen Datenstrukturen verwendeten Algorithmen ausdrückt. Wir nennen diese in der Informatik Big-O-Notation, die die Leistung oder Komplexität eines Algorithmus beschreibt. Da InnoDB und MyISAM B-Trees verwenden, verwendet es O(log n) für die Suche. Während Hash-Tabellen oder Hash-Maps O (n) verwenden. Beide teilen den durchschnittlichen und den schlechtesten Fall für ihre Leistung mit ihrer Notation.
Nun zurück zur spezifischen Engine, angesichts der Datenstruktur der Engine wirkt sich die Abfrage, die basierend auf den abzurufenden Zieldaten anzuwenden ist, natürlich auf die Leistung Ihres Datenbankservers aus. Hash-Tabellen können keinen Bereichsabruf durchführen, während B-Trees für diese Art von Suchen sehr effizient ist und auch große Datenmengen verarbeiten kann.
Wenn Sie die richtige Engine für die von Ihnen gespeicherten Daten verwenden, müssen Sie ermitteln, welche Art von Abfrage Sie für diese spezifischen Daten, die Sie speichern, anwenden. Welche Art von Logik sollen diese Daten formulieren, wenn sie in eine Geschäftslogik umgewandelt werden.
Der Umgang mit Tausenden oder Tausenden von Datenbanken, die Verwendung der richtigen Engine in Kombination Ihrer Abfragen und Daten, die Sie abrufen und speichern möchten, wird eine gute Leistung liefern. Vorausgesetzt, Sie haben Ihre Anforderungen für ihren Zweck an die richtige Datenbankumgebung festgelegt und analysiert.
Die richtigen Tools zum Verwalten großer Datenbanken
Es ist sehr schwer und schwierig, eine sehr große Datenbank ohne eine solide Plattform zu verwalten, auf die Sie sich verlassen können. Selbst mit guten und erfahrenen Datenbankingenieuren ist der von Ihnen verwendete Datenbankserver technisch gesehen anfällig für menschliche Fehler. Ein Fehler bei Änderungen an Ihren Konfigurationsparametern und -variablen kann zu einer drastischen Änderung führen, die die Leistung des Servers beeinträchtigt.
Das Durchführen einer Sicherung Ihrer Datenbank auf einer sehr großen Datenbank kann manchmal eine Herausforderung darstellen. Es kann vorkommen, dass die Sicherung aus seltsamen Gründen fehlschlägt. Häufig führen Abfragen, die den Server, auf dem die Sicherung ausgeführt wird, zum Stillstand bringen könnten, zu einem Fehlschlagen. Andernfalls müssen Sie der Ursache nachgehen.
Die Verwendung von Automatisierung wie Chef, Puppet, Ansible, Terraform oder SaltStack kann als IaC verwendet werden, um Aufgaben schneller auszuführen. Während Sie auch andere Tools von Drittanbietern verwenden, um Sie bei der Überwachung und Bereitstellung hochwertiger Diagrammbilder zu unterstützen. Warn- und Alarmbenachrichtigungssysteme sind ebenfalls sehr wichtig, um Sie über Probleme zu informieren, die von der Statusstufe „Warnung“ bis „Kritisch“ auftreten können. Hier ist ClusterControl in solchen Situationen sehr nützlich.
ClusterControl bietet eine einfache Verwaltung einer großen Anzahl von Datenbanken oder sogar von verteilten Umgebungen. Es wurde tausendfach getestet und installiert und ist in Produktionen gelaufen, um DBAs, Ingenieuren oder DevOps, die die Datenbankumgebung betreiben, Alarme und Benachrichtigungen bereitzustellen. Von Staging oder Entwicklung über QAs bis hin zur Produktionsumgebung.
ClusterControl kann auch eine Sicherung und Wiederherstellung durchführen. Selbst bei großen Datenbanken kann es effizient und einfach zu verwalten sein, da die Benutzeroberfläche eine Zeitplanung bietet und auch Optionen zum Hochladen in die Cloud (AWS, Google Cloud und Azure) bietet.
Es gibt auch eine Backup-Verifizierung und viele Optionen wie Verschlüsselung und Komprimierung. Sehen Sie sich zum Beispiel den folgenden Screenshot an (Erstellen eines Backups für MySQL mit Xtrabackup):
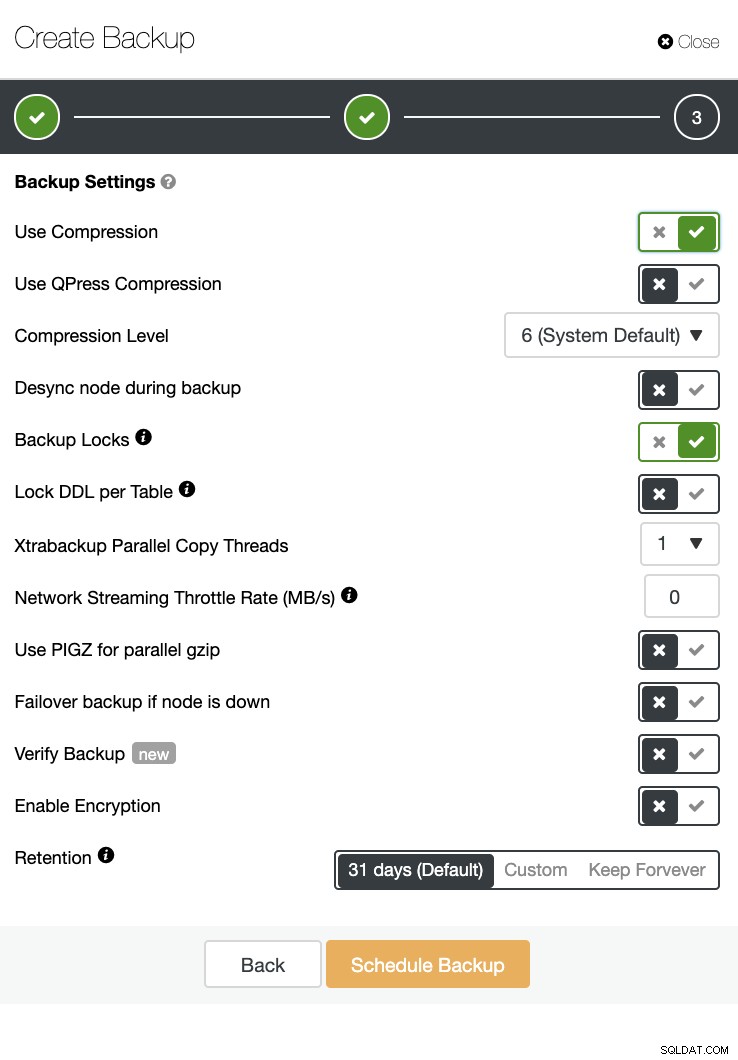
Fazit
Die Verwaltung großer Datenbanken mit tausend oder mehr kann effizient erfolgen, muss jedoch vorher festgelegt und vorbereitet werden. Die Verwendung der richtigen Tools wie Automatisierung oder sogar das Abonnieren von Managed Services hilft drastisch. Obwohl dies Kosten verursacht, können die Turnaround-Zeit für den Service und das Budget, das für die Anwerbung qualifizierter Ingenieure aufgewendet werden muss, reduziert werden, solange die richtigen Tools verfügbar sind.



