In den beiden vorherigen Blogbeiträgen haben wir sowohl die Bereitstellung der vier Arten von Clustering/Replikation (MySQL/Galera, MySQL-Replikation, MongoDB &PostgreSQL) als auch die Verwaltung/Überwachung Ihrer vorhandenen Datenbanken und Cluster behandelt. Nachdem Sie also diese beiden ersten Blogbeiträge gelesen hatten, konnten Sie Ihre 20 bestehenden Replikations-Setups zu ClusterControl hinzufügen, erweitern und zusätzlich zwei neue Galera-Cluster bereitstellen, während Sie eine Menge anderer Dinge tun. Oder vielleicht haben Sie MongoDB- und/oder PostgreSQL-Systeme bereitgestellt. Also, wie halten Sie sie jetzt gesund?
Genau darum geht es in diesem Blog-Beitrag:Wie Sie die Leistungsüberwachungs- und Advisor-Funktionen von ClusterControl nutzen können, um Ihre MySQL-, MongoDB- und/oder PostgreSQL-Datenbanken und -Cluster gesund zu halten. Wie wird das in ClusterControl gemacht?
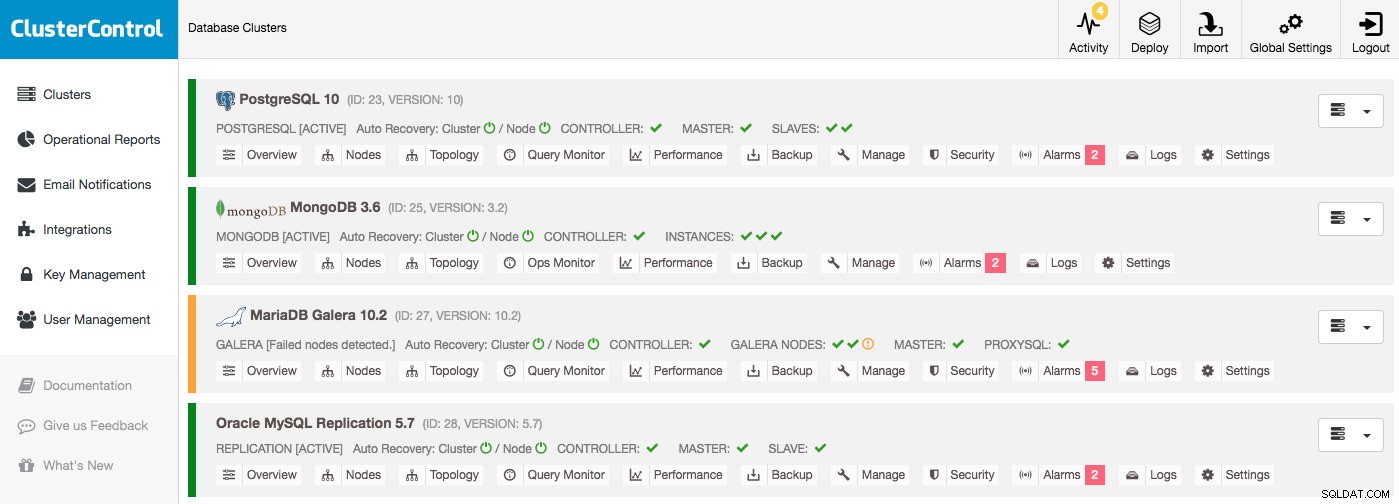
Datenbank-Cluster-Liste
Die wichtigsten Informationen sind bereits in der Clusterliste zu finden:Solange keine Alarme vorliegen und keine Hosts als down angezeigt werden, funktioniert alles einwandfrei. Ein Alarm wird ausgelöst, wenn eine bestimmte Bedingung erfüllt ist, z. Host tauscht aus und macht Sie auf das Problem aufmerksam, das Sie untersuchen sollten. Das bedeutet, dass bei einem Ausfall nicht nur Alarme ausgelöst werden, sondern Sie auch Ihre Datenbanken proaktiv verwalten können.
Angenommen, Sie würden sich bei ClusterControl anmelden und eine Cluster-Auflistung wie diese sehen, dann müssten Sie definitiv etwas untersuchen:Ein Knoten ist zum Beispiel im Galera-Cluster ausgefallen und jeder Cluster hat verschiedene Alarme:
Sobald Sie auf einen der Alarme klicken, gelangen Sie auf eine Detailseite zu allen Alarmen des Clusters. Die Alarmdetails erläutern das Problem und empfehlen in den meisten Fällen auch Maßnahmen zur Behebung des Problems.
Sie können Ihre eigenen Alarme einrichten, indem Sie benutzerdefinierte Ausdrücke erstellen, aber das wurde zugunsten unseres neuen Developer Studio verworfen, das es Ihnen ermöglicht, benutzerdefinierte Javascripts zu schreiben und diese als Berater auszuführen. Wir werden später in diesem Beitrag auf dieses Thema zurückkommen.
Cluster-Übersicht – Dashboards
Beim Öffnen der Cluster-Übersicht sehen wir in den Tabs sofort die wichtigsten Performance-Metriken des Clusters. Diese Übersicht kann je nach Clustertyp unterschiedlich sein, da beispielsweise Galera andere Leistungsmetriken zu beobachten hat als traditionelles MySQL, PostgreSQL oder MongoDB.
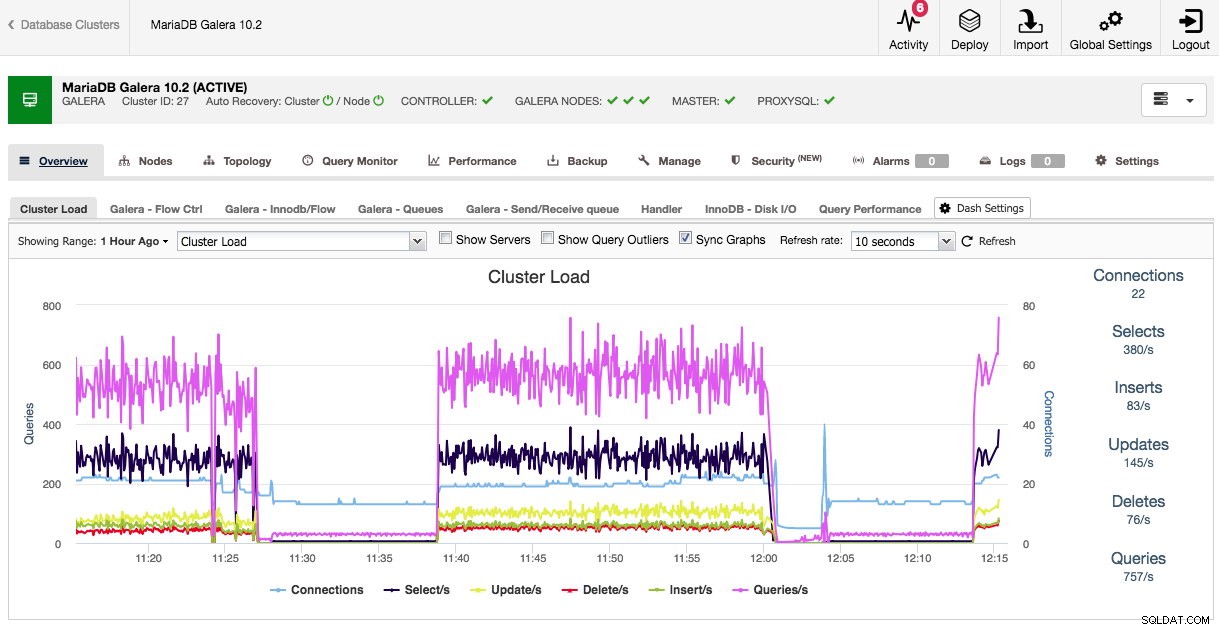
Sowohl die Standardübersicht als auch die vorausgewählten Registerkarten sind anpassbar. Durch Klicken auf Übersicht -> Dash-Einstellungen Sie erhalten einen Dialog, mit dem Sie das Dashboard definieren können:
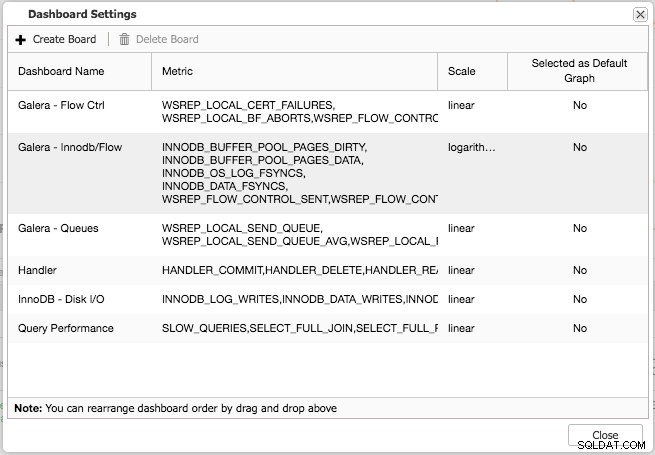
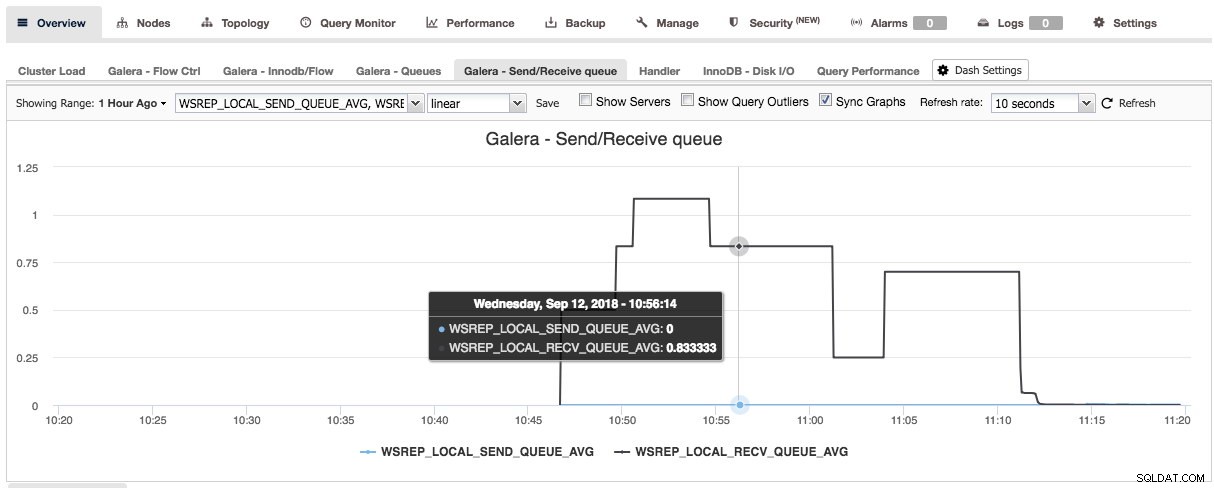
Durch Drücken des Pluszeichens können Sie Ihre eigenen Metriken hinzufügen und definieren, um das Dashboard grafisch darzustellen. In unserem Fall definieren wir ein neues Dashboard mit dem Galera-spezifischen Sende- und Empfangswarteschlangendurchschnitt:
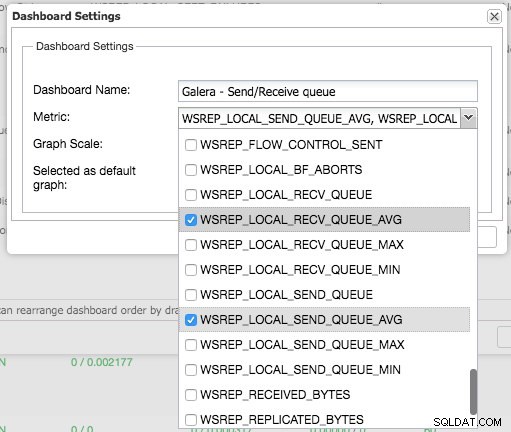
Dieses neue Dashboard sollte uns einen guten Einblick in die durchschnittliche Warteschlangenlänge unseres Galera-Clusters geben.
Sobald Sie auf Speichern geklickt haben, wird das neue Dashboard für diesen Cluster verfügbar:
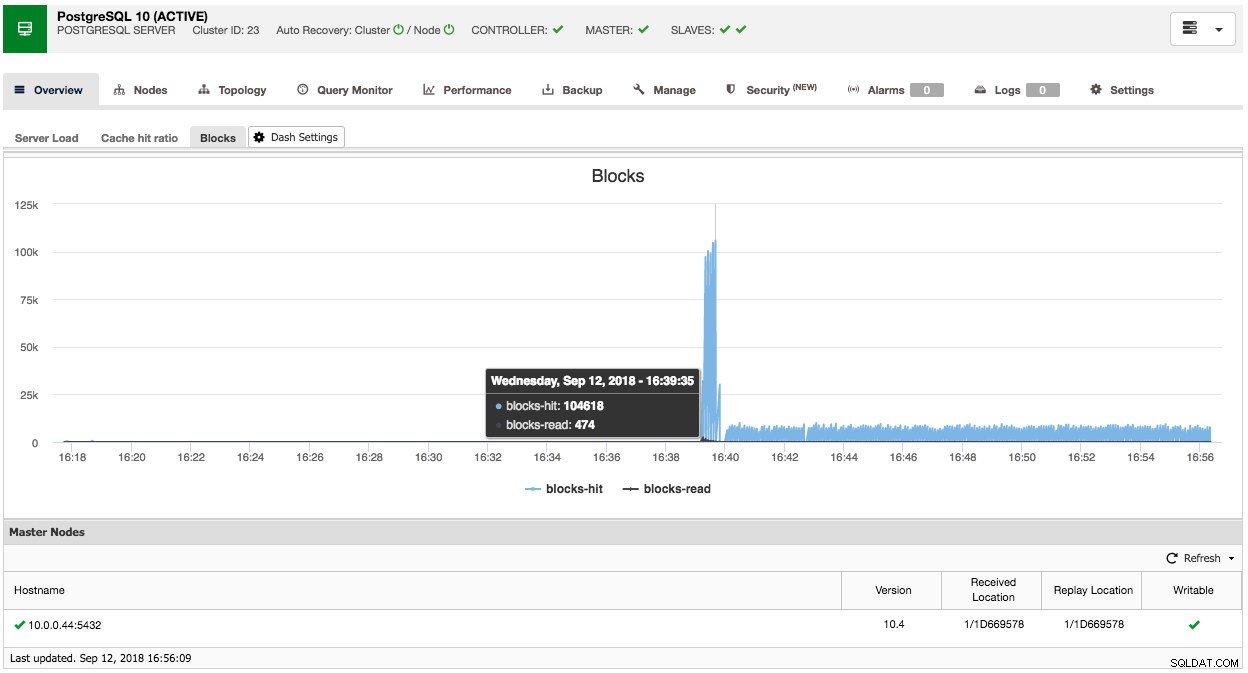
In ähnlicher Weise können Sie dies auch für PostgreSQL tun, zum Beispiel können wir die gefundenen freigegebenen Blöcke im Vergleich zu den gelesenen Blöcken überwachen:
Wie Sie sehen können, ist es relativ einfach, Ihr eigenes (Standard-)Dashboard anzupassen.
Cluster-Übersicht – Abfragemonitor
Die Registerkarte „Query Monitor“ ist sowohl für MySQL- als auch für PostgreSQL-basierte Setups verfügbar und besteht aus drei Dashboards:Top Queries, Running Queries und Query Outliers.
Im Dashboard Laufende Abfragen finden Sie alle aktuellen Abfragen, die ausgeführt werden. Dies ist im Grunde das Äquivalent der SHOW FULL PROCESSLIST-Anweisung in der MySQL-Datenbank.
Top-Abfragen und Abfrageausreißer sind beide auf die Eingabe des Protokolls für langsame Abfragen oder des Leistungsschemas angewiesen. Die Verwendung des Leistungsschemas wird immer empfohlen und wird automatisch verwendet, wenn es aktiviert ist. Andernfalls verwendet ClusterControl das langsame MySQL-Abfrageprotokoll, um die laufenden Abfragen zu erfassen. Um zu verhindern, dass ClusterControl zu aufdringlich wird und das Protokoll für langsame Abfragen zu groß wird, testet ClusterControl das Protokoll für langsame Abfragen, indem es ein- und ausgeschaltet wird. Diese Schleife ist standardmäßig auf 1 Sekunde Erfassung und die long_query_time eingestellt auf 0,5 Sekunden eingestellt. Wenn Sie diese Einstellungen für Ihren Cluster ändern möchten, können Sie dies über Einstellungen -> Abfragemonitor ändern .
Top-Abfragen zeigt, wie der Name schon sagt, die Top-Abfragen, die abgetastet wurden. Sie können sie nach verschiedenen Spalten sortieren:zum Beispiel Häufigkeit, durchschnittliche Ausführungszeit, Gesamtausführungszeit oder Standardabweichungszeit:
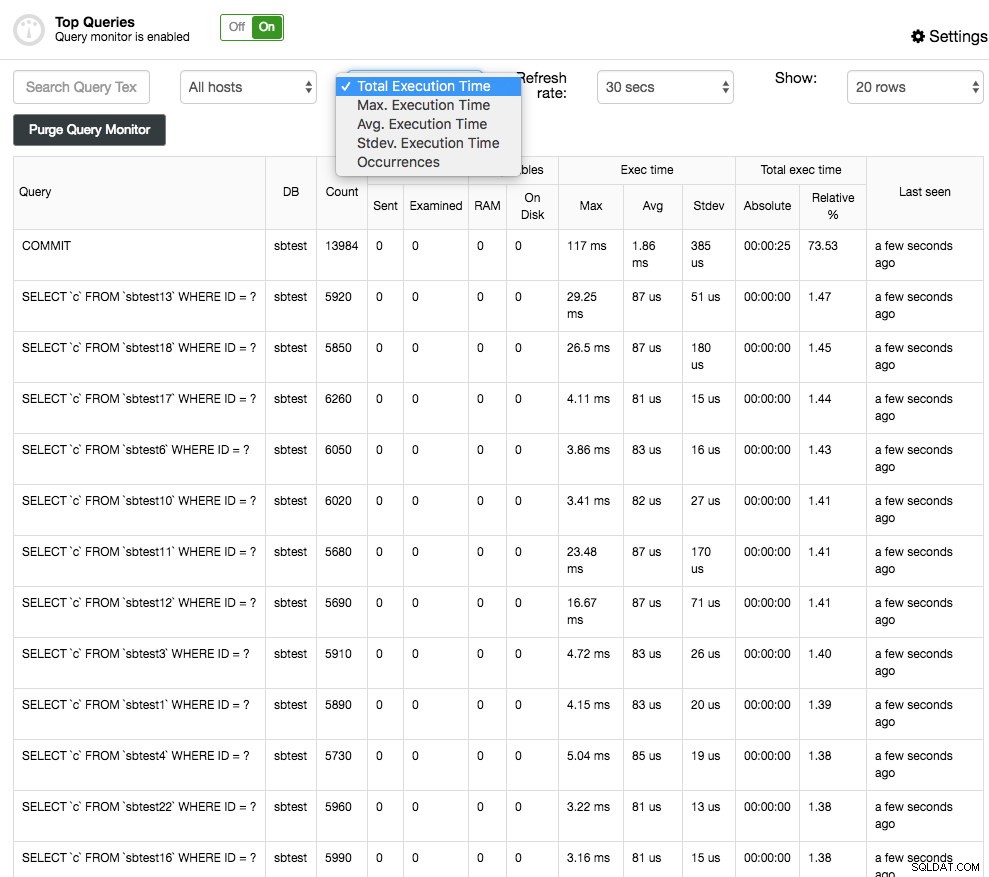
Sie können weitere Details über die Abfrage erhalten, indem Sie sie auswählen. Dadurch werden der Abfrageausführungsplan (falls verfügbar) und Optimierungshinweise/-ratschläge angezeigt. Die Abfrage-Ausreißer ähneln den Top-Abfragen, ermöglichen es Ihnen jedoch, die Abfragen pro Host zu filtern und zeitlich zu vergleichen.
Cluster-Übersicht – Betrieb
Ähnlich wie die PostgreSQL- und MySQL-Systeme haben die MongoDB-Cluster die Betriebsübersicht und ähneln den laufenden Abfragen von MySQL. Diese Übersicht ähnelt der Ausgabe des Befehls db.currentOp() in MongoDB.
Cluster-Übersicht – Leistung
MySQL/Galera
Die Registerkarte Leistung ist wahrscheinlich der beste Ort, um die Gesamtleistung und den Zustand Ihrer Cluster zu ermitteln. Für MySQL und Galera besteht es aus einer Übersichtsseite, den Advisors, Status-/Variablenübersichten, dem Schema-Analysator und dem Transaktionsprotokoll.
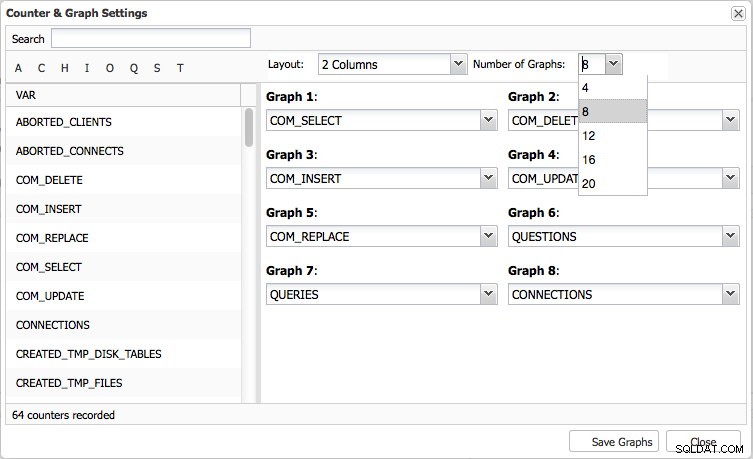
Auf der Übersichtsseite erhalten Sie einen grafischen Überblick über die wichtigsten Metriken in Ihrem Cluster. Dies ist offensichtlich je nach Clustertyp unterschiedlich. Acht Metriken wurden standardmäßig festgelegt, aber Sie können ganz einfach Ihre eigenen festlegen – bei Bedarf bis zu 20 Diagramme:
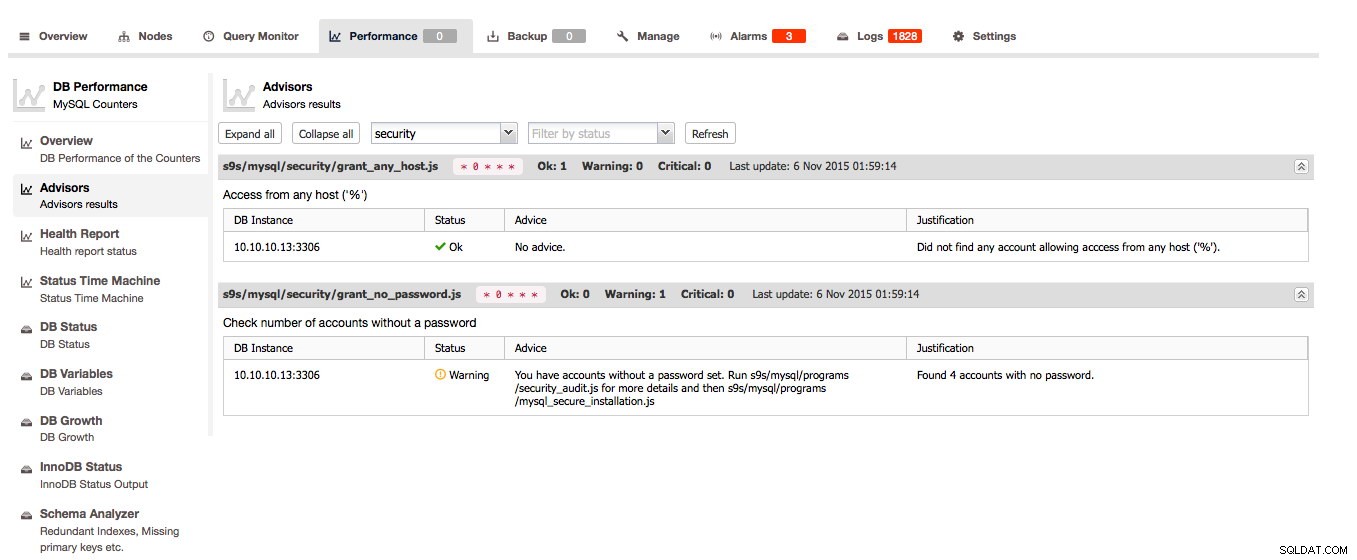
Die Advisors sind eine der Hauptfunktionen von ClusterControl:Die Advisors sind Skriptprüfungen, die bei Bedarf ausgeführt werden können. Die Berater können fast alle bekannten Fakten über den Host und/oder Cluster auswerten und ihre Meinung zum Zustand des Hosts und/oder Clusters abgeben und sogar Ratschläge geben, wie Sie Probleme lösen oder Ihre Hosts verbessern können!
Das Beste kommt aber noch:Sie können im Developer Studio (ClusterControl -> Manage -> Developer Studio) Ihre eigenen Checks erstellen ), führen Sie sie in regelmäßigen Abständen aus und verwenden Sie sie erneut im Abschnitt „Berater“. Wir haben Anfang des Jahres über diese neue Funktion gebloggt.
Wir werden die Status-/Variablenübersicht von MySQL und Galera überspringen, da dies als Referenz nützlich ist, aber nicht für diesen Blogbeitrag:Es ist gut genug, dass Sie wissen, dass es hier ist.
Angenommen, Ihre Datenbank wächst, aber Sie möchten wissen, wie schnell sie in der letzten Woche gewachsen ist. Sie können das Wachstum sowohl der Daten- als auch der Indexgröße direkt in ClusterControl verfolgen:
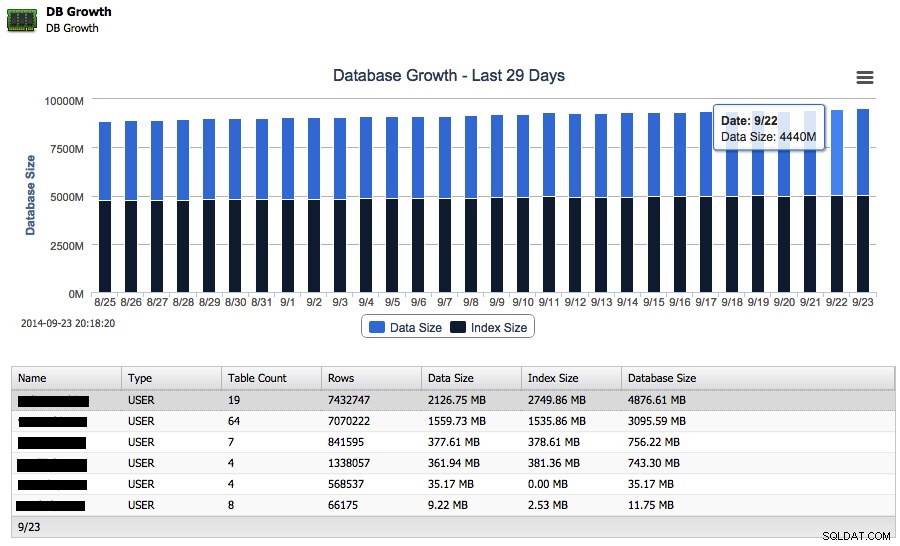
Und neben dem Gesamtwachstum auf der Festplatte kann es auch die 25 größten Schemas zurückmelden.
Ein weiteres wichtiges Feature ist der Schema Analyzer in ClusterControl:
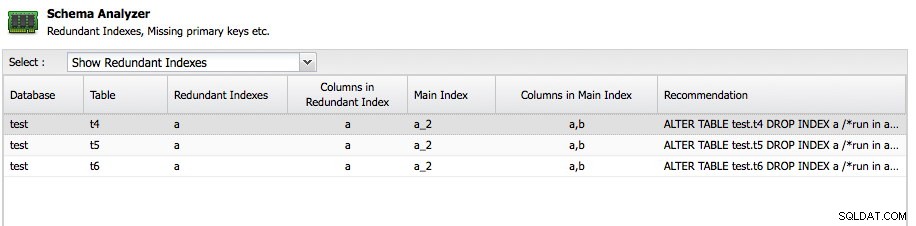
ClusterControl analysiert Ihre Schemas und sucht nach redundanten Indizes, MyISAM-Tabellen und Tabellen ohne Primärschlüssel. Natürlich liegt es ganz bei Ihnen, eine Tabelle ohne Primärschlüssel zu führen, da eine Anwendung sie möglicherweise auf diese Weise erstellt hat, aber zumindest ist es großartig, hier kostenlos Ratschläge zu erhalten. Der Schemaanalysator empfiehlt sogar die notwendige ALTER-Anweisung, um das Problem zu beheben.
PostgreSQL
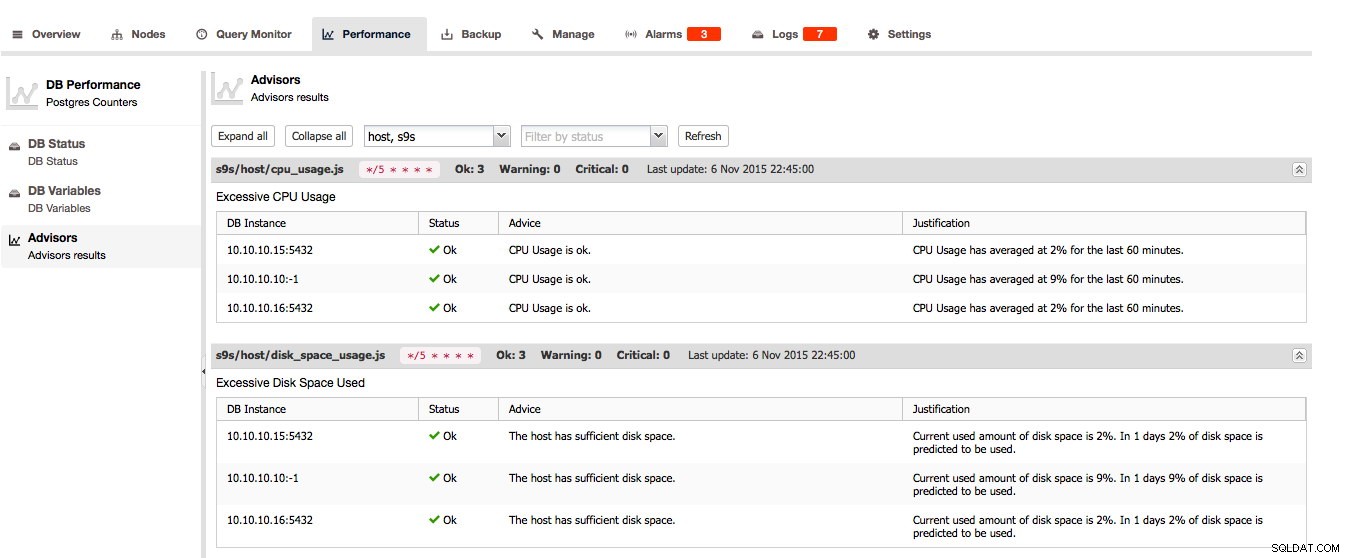
Für PostgreSQL finden Sie die Advisors, den DB-Status und die DB-Variablen hier:
MongoDB
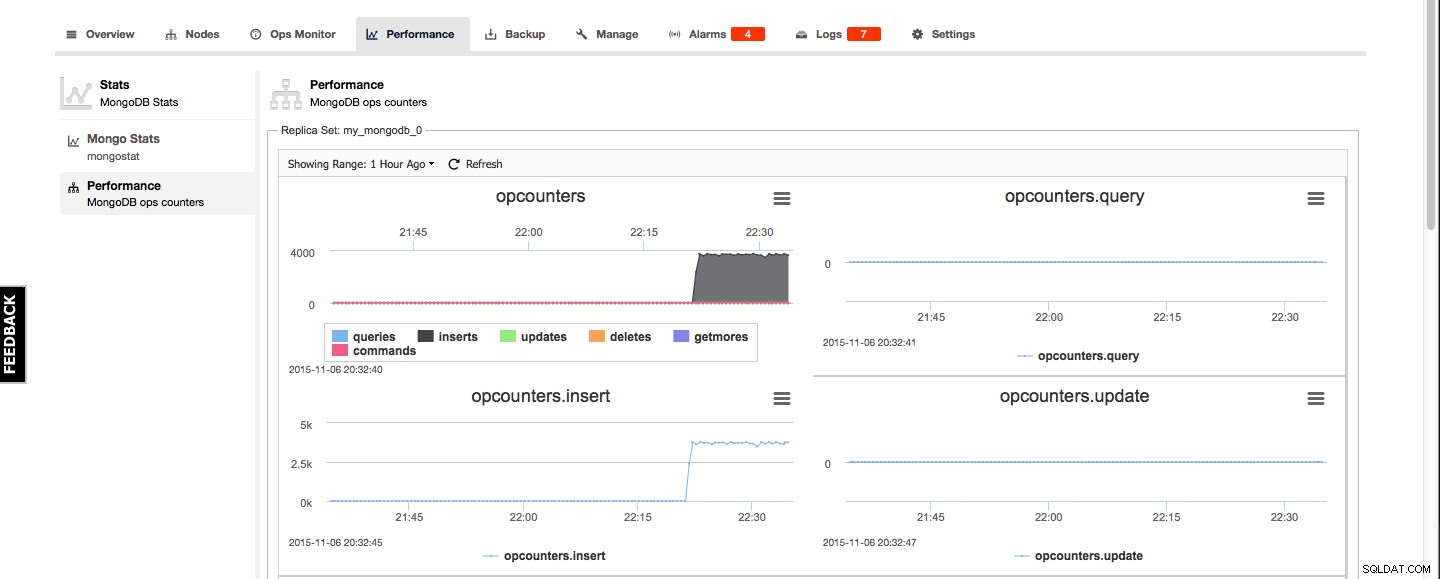
Für MongoDB finden Sie die Mongo-Statistiken und die Leistungsübersicht auf der Registerkarte Leistung. Die Mongo-Statistik ist eine Übersicht über die Ausgabe von mongostat und die Leistungsübersicht gibt einen guten grafischen Überblick über die MongoDB-Opcounter:
Abschließende Gedanken
Wir haben Ihnen gezeigt, wie Sie die wichtigsten Überwachungs- und Zustandsprüfungsfunktionen von ClusterControl im Auge behalten. Offensichtlich ist dies nur der Anfang der Reise, da wir bald eine weitere Blog-Serie über die Funktionen von Developer Studio und darüber, wie Sie das Beste aus Ihren eigenen Überprüfungen machen können, starten werden. Denken Sie auch daran, dass unsere Unterstützung für MongoDB und PostgreSQL nicht so umfangreich ist wie unser MySQL-Toolset, aber wir verbessern dies kontinuierlich.
Sie fragen sich vielleicht, warum wir die Leistungsüberwachung und Zustandsprüfungen von HAProxy, ProxySQL und MaxScale übersprungen haben. Das haben wir bewusst so gemacht, da sich die Blogserie bisher nur mit dem Deployment von Clustern und nicht mit dem Deployment von HA-Komponenten befasste. Das ist also das Thema, das wir beim nächsten Mal behandeln werden.



