Mit der Version 1.7 unseres Flaggschiffprodukts ClusterControl haben wir unsere neue agentenbasierte Überwachungsinfrastruktur eingeführt:SCUMM – die in diesem Blog ausführlicher besprochen wird.
Als Kernelement unseres Produkts bietet ClusterControl ein vollständiges Überwachungssystem mit Echtzeitdaten, um zu wissen, was gerade passiert, mit hochauflösenden Metriken für eine bessere Genauigkeit, vorkonfigurierten Dashboards und einer breiten Palette von Benachrichtigungsdiensten von Drittanbietern für Warnungen .
Lokale und Cloud-Systeme können von einem einzigen Punkt aus überwacht und verwaltet werden.
Intelligente Integritätsprüfungen werden für verteilte Topologien implementiert, zum Beispiel Erkennung von Netzwerkpartitionierung durch Nutzung der Ansicht des Load Balancers auf die Datenbankknoten.
Und ... die Überwachung kann ohne Agenten über SSH oder auf Agentenbasis erfolgen ... und hier kommt SCUMM ins Spiel!
Das neue SCUMM-System von ClusterControl ist agentenbasiert, wobei ein Server Metriken von Agenten abruft, die auf denselben Hosts wie die überwachten Datenbanken ausgeführt werden, und Prometheus-Agenten für größere Genauigkeit und Anpassungsoptionen bei der Überwachung Ihrer Datenbank-Cluster verwendet.
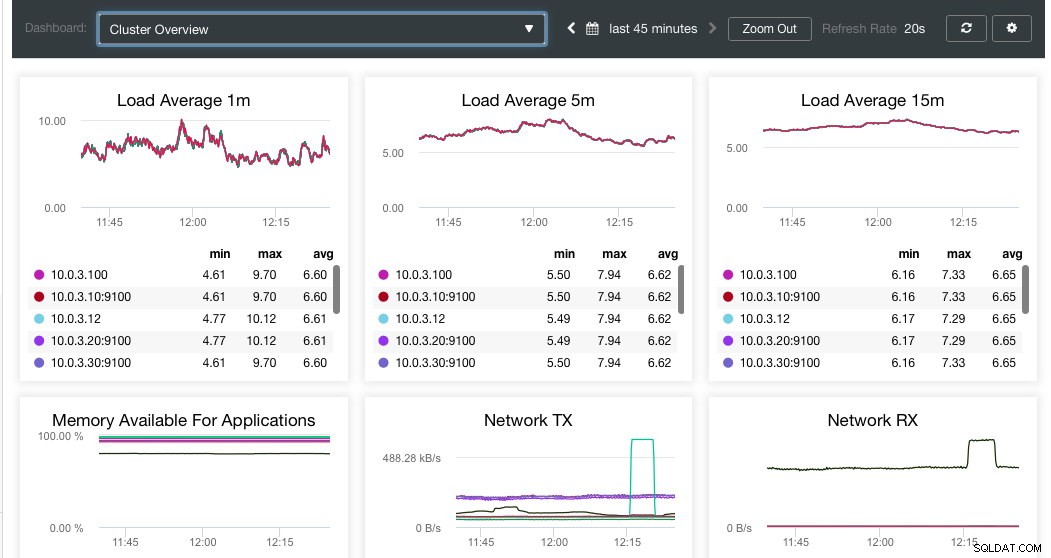
Aber warum SCUMM und was hat es damit auf sich?
Einführung in SCUMM
SCUMM - Multiplenines CMON Unified Monitoring and Management - ist unsere neue agentenbasierte Überwachungsinfrastruktur.
Diese Überwachungsinfrastruktur besteht aus zwei Hauptkomponenten:
Die erste Komponente ist der Prometheus-Server, der als Zeitreihendatenbank fungiert und die gesammelten Metriken speichert.
Die zweite Komponente ist der Exporteur. Es kann einen oder mehrere Exporter geben, die für das Sammeln von Metriken von einem Knoten oder einem Dienst verantwortlich sind. Der Prometheus-Server sammelt diese Metriken (dies wird als Scraping bezeichnet) von den Exporteuren über HTTP. Darüber hinaus haben wir eine Reihe von Dashboards erstellt, um die gesammelten Metriken zu visualisieren.
Die Hauptvorteile sind:
- Erfassen Sie Metriken mit von der Community unterstützten Prometheus-Exporteuren
- Zum Beispiel Daten aus MySQL Performance Schema oder ProxySQL
- Eine Reihe spezialisierter Dashboards, die die wichtigsten Metriken und historischen Trends für jeden überwachten Dienst anzeigen
- Hochfrequenzüberwachung macht es möglich, die Ziele in einem Sekundenintervall abzukratzen
- Eine Architektur, die mit der Anzahl der Datenbankserver und Cluster skaliert. Eine einzelne Prometheus-Instanz kann Tausende von Samples pro Sekunde aufnehmen.
- Keine Abhängigkeit von SSH-Konnektivität zum Erfassen von Host- und Prozessmetriken, was ein skalierbareres System im Vergleich zu einer agentenlosen Überwachungslösung bedeutet
- Die Möglichkeit, benutzerdefinierte Dashboards mit benutzerdefinierten Regeln zu erstellen (achten Sie auf unsere kommenden Versionen)
Die auf den überwachten Knoten installierten SCUMM-Agenten/Exporter werden als Prometheus-Exporter bezeichnet. Die Exporter sammeln Metriken vom Knoten (z. B. CPU, RAM, Festplatte und Netzwerk) und von Diensten wie MySQL- oder PostgreSQL-Servern. Der Prometheus-Server wird auf einem Server installiert und scraped (sampelt) die Exporter mit einem benutzerdefinierten Intervall.
Warum Prometheus?
Prometheus ist eine sehr beliebte Zeitreihendatenbank, die mit einem aktiven Ökosystem eine große Akzeptanz gefunden hat. Es bietet ein reichhaltiges Datenmodell und eine Abfragesprache mit einem http-basierten Abfragesystem. Es ist auch im HA-Setup einfach zu installieren, zu warten und zu konfigurieren.
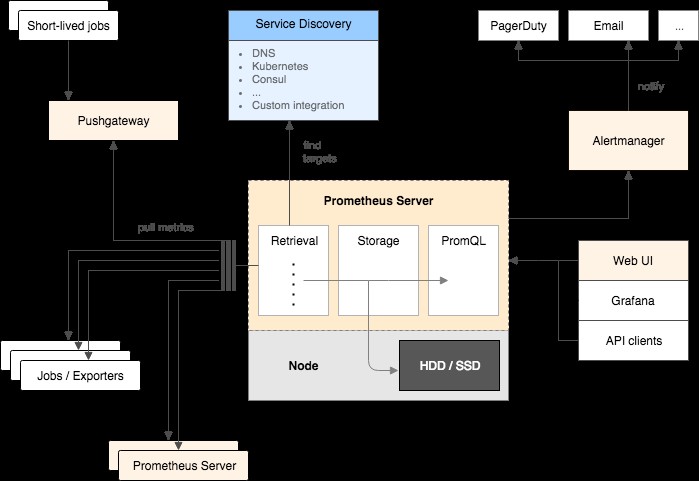
Prometheus kratzt Metriken aus instrumentierten Jobs, entweder direkt oder über ein zwischengeschaltetes Push-Gateway für kurzlebige Jobs. Es speichert alle abgekratzten Proben lokal und führt Regeln über diese Daten aus, um entweder neue Zeitreihen aus vorhandenen Daten zu aggregieren und aufzuzeichnen oder Warnungen zu generieren.
Prometheus eignet sich gut für die Aufzeichnung rein numerischer Zeitreihen. Es passt sowohl zur maschinenzentrierten Überwachung als auch zur Überwachung hochdynamischer, serviceorientierter Architekturen. In einer Welt der Microservices ist seine Unterstützung für mehrdimensionale Datenerfassung und -abfrage eine besondere Stärke.
Prometheus ist auf Zuverlässigkeit ausgelegt, um das System zu sein, zu dem Sie während eines Ausfalls gehen, damit Sie Probleme schnell diagnostizieren können. Jeder Prometheus-Server ist eigenständig und unabhängig von Netzwerkspeicher oder anderen Remote-Diensten. Sie können sich darauf verlassen, wenn andere Teile Ihrer Infrastruktur ausfallen, und Sie müssen keine umfangreiche Infrastruktur einrichten, um sie zu nutzen. Daher ist es für Hochverfügbarkeit möglich, einfach einen zweiten Prometheus-Server zu installieren, der die gleichen Daten wie der erste Prometheus-Server kratzt.
Darüber hinaus ist Prometheus eine sehr beliebte Zeitreihendatenbank und ihre Akzeptanz hat sehr schnell zugenommen. Es ist möglich, dass ein anderer Prometheus-Server, der sich weiter oben in der Organisation befindet, die Prometheus-Server näher an der Datenbankebene abkratzt. Dies ermöglicht eine skalierbare Überwachungsinfrastruktur, bei der die Datenauflösung auf der Datenbankebene höher ist als weiter oben in einer Organisation.

Exporteure
Ein oder mehrere Exporter werden auf dem überwachten Server installiert und sind für das Sammeln von Metriken über einen bestimmten Teil der Infrastruktur verantwortlich. Beispielsweise kann es einen Exporter geben, um hostspezifische Informationen zu erfassen, einen Exporter, um MySQL-Metriken und ProxySQL-Metriken zu erfassen.
Wir haben auch einen speziellen Prozess-Exporter erstellt, der die laufenden Prozesse des Servers überwacht. Dieser Exporter ist entscheidend für die Hochverfügbarkeitsfunktionen in ClusterControl und ermöglicht es ClusterControl, schnell auf Prozessfehler und Prozesszustände zu reagieren. Die Verwendung des Prozess-Exporters (der standardmäßig installiert wird, wenn die agentenbasierte Überwachung aktiviert ist) reduziert die Systemlast auf den überwachten Servern.
Aktivieren der agentenbasierten Überwachung in ClusterControl
Um die agentenbasierte Überwachung zu aktivieren, klicken Sie einfach auf das Dashboard und dann auf „Agentenbasierte Überwachung aktivieren“. Wählen Sie einen Host aus, auf dem der Prometheus-Server installiert wird. Dieser Prometheus-Server kann dann mit anderen Clustern geteilt werden.
Mit der Version 1.7.1 enthält ClusterControl die folgenden Dashboards:
- Systemübersicht
- Cluster-Übersicht
- MySQL Server – Allgemein
- MySQL Server - Caches
- MySQL InnoDB-Metriken
- Galera-Cluster-Übersicht
- Galera-Serverübersicht
- PostgreSQL-Übersicht
- ProxySQL-Übersicht
- HAProxy-Übersicht
- MongoDB-Cluster-Übersicht
- MongoDB-ReplicaSet
- MongoDB-Server
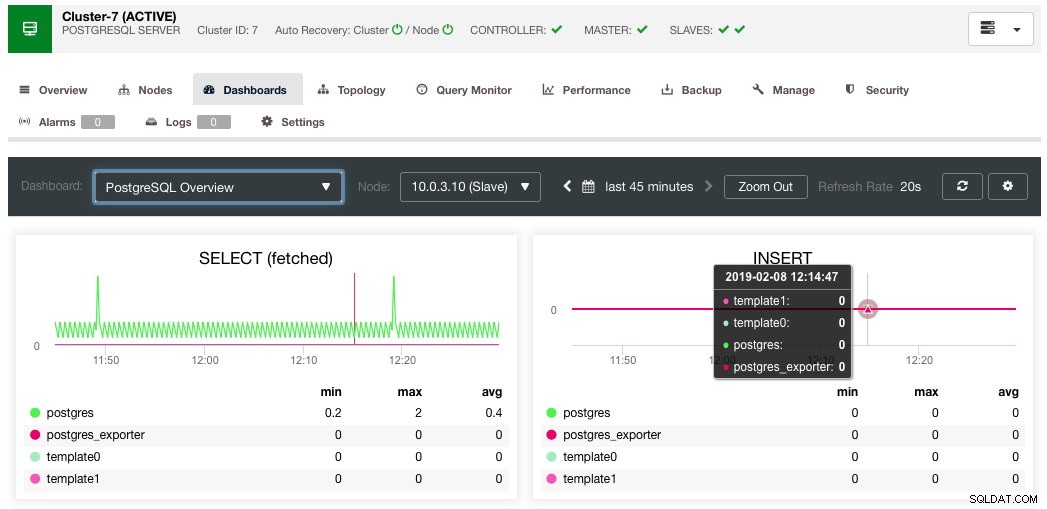
Zusammenfassend …
Ob man einen Überwachungsagenten verwenden oder den Weg ohne Agenten gehen möchte, hängt vollständig von den Richtlinienanforderungen der Organisation und den individuellen Bedürfnissen ab. Und obwohl wir die Einfachheit lieben, keine Agenten auf den überwachten Datenbankhosts installieren oder verwalten zu müssen, kann ein agentenbasierter Ansatz eine höhere Auflösung der Überwachungsdaten bieten und hat bestimmte Vorteile in Bezug auf die Sicherheit.
Das neue SCUMM-System von ClusterControl verwendet Prometheus-Agenten für größere Genauigkeit und Anpassungsoptionen bei der Überwachung Ihrer Datenbank-Cluster.
Probieren Sie es aus und überzeugen Sie sich selbst!
Installieren Sie ClusterControl noch heute (kostenlos mit unserer Community Edition) oder laden Sie unseren neuen ClusterControl-Leitfaden herunter, wenn Sie zuerst mehr über unser Produkt erfahren möchten.



