ClusterControl ist mit einer Reihe von Wiederherstellungsalgorithmen programmiert, um automatisch auf verschiedene Arten von häufigen Fehlern zu reagieren, die Ihre Datenbanksysteme betreffen. Es versteht verschiedene Arten von Datenbanktopologien und datenbankbezogenes Prozessmanagement, um Ihnen dabei zu helfen, den besten Weg zur Wiederherstellung des Clusters zu bestimmen. In gewisser Weise verbessert ClusterControl Ihre Datenbankverfügbarkeit.
Einige Topologie-Manager decken nur die Cluster-Wiederherstellung ab, wie MHA, Orchestrator und mysqlfailover, aber Sie müssen sich selbst um die Wiederherstellung der Knoten kümmern. ClusterControl unterstützt die Wiederherstellung sowohl auf Cluster- als auch auf Knotenebene.
Konfigurationsoptionen
ClusterControl unterstützt zwei Wiederherstellungskomponenten, nämlich:
- Cluster – Versuch, einen Cluster in einen Betriebszustand zurückzuversetzen
- Knoten – Versuch, einen Knoten wieder in einen Betriebszustand zu versetzen
Diese beiden Komponenten sind die wichtigsten Dinge, um eine möglichst hohe Serviceverfügbarkeit sicherzustellen. Wenn Sie bereits einen Topologie-Manager auf ClusterControl haben, können Sie die automatische Wiederherstellungsfunktion deaktivieren und andere Topologie-Manager dies für Sie erledigen lassen. Mit ClusterControl haben Sie alle Möglichkeiten.
Die automatische Wiederherstellungsfunktion kann durch einfaches Umschalten auf EIN/AUS aktiviert und deaktiviert werden und funktioniert für die Wiederherstellung von Clustern oder Knoten. Die grünen Symbole bedeuten aktiviert und die roten Symbole bedeuten deaktiviert. Der folgende Screenshot zeigt, wo Sie es in der Datenbank-Cluster-Liste finden können:
Es gibt 3 ClusterControl-Parameter, die zur Steuerung des Wiederherstellungsverhaltens verwendet werden können. Alle Parameter sind standardmäßig auf wahr (mit boolescher Ganzzahl 0 oder 1 gesetzt):
- enable_autorecovery – Aktiviert die Cluster- und Knotenwiederherstellung. Dieser Parameter ist die Obermenge von enable_cluster_recovery und enable_node_recovery. Wenn es auf 0 gesetzt ist, werden die Subset-Parameter ausgeschaltet.
- enable_cluster_recovery - ClusterControl führt eine Cluster-Wiederherstellung durch, falls aktiviert.
- enable_node_recovery – ClusterControl führt eine Knotenwiederherstellung durch, falls aktiviert.
Cluster-Wiederherstellung umfasst den Wiederherstellungsversuch, die gesamte Cluster-Topologie hochzufahren. Beispielsweise muss bei einer Master-Slave-Replikation immer mindestens ein Master aktiv sein, unabhängig von der Anzahl verfügbarer Slaves. ClusterControl versucht, die Topologie mindestens einmal für Replikations-Cluster zu korrigieren, aber unendlich für Multi-Master-Replikation wie NDB-Cluster und Galera-Cluster.
Knotenwiederherstellung deckt Knotenwiederherstellungsprobleme ab, wie wenn ein Knoten ohne ClusterControl-Wissen gestoppt wurde, z. B. über einen Systemstoppbefehl von der SSH-Konsole oder durch einen OOM-Prozess beendet wurde.
Knotenwiederherstellung
ClusterControl ist in der Lage, einen Datenbankknoten im Falle eines zeitweiligen Ausfalls wiederherzustellen, indem es den Prozess und die Verbindung zu den Datenbankknoten überwacht. Für den Prozess funktioniert es ähnlich wie systemd, wo es sicherstellt, dass der MySQL-Dienst gestartet und ausgeführt wird, es sei denn, Sie haben ihn absichtlich über die ClusterControl-Benutzeroberfläche gestoppt.
Wenn der Knoten wieder online geht, stellt ClusterControl eine Verbindung zurück zum Datenbankknoten her und führt die erforderlichen Aktionen durch. Folgendes würde ClusterControl tun, um einen Knoten wiederherzustellen:
- Es wartet 30 Sekunden lang darauf, dass systemd/chkconfig/init die überwachten Dienste/Prozesse startet
- Wenn die überwachten Dienste/Prozesse immer noch nicht erreichbar sind, wird ClusterControl versuchen, den Datenbankdienst automatisch zu starten.
- Wenn ClusterControl die überwachten Dienste/Prozesse nicht wiederherstellen kann, wird ein Alarm ausgelöst.
Beachten Sie, dass ClusterControl nicht versucht, den bestimmten Knoten wiederherzustellen, wenn ein Datenbank-Shutdown vom Benutzer initiiert wird. Es erwartet, dass der Benutzer es über die ClusterControl-Benutzeroberfläche neu startet, indem er zu Node -> Node Actions -> Start Node geht oder explizit den OS-Befehl verwendet.
Die Wiederherstellung umfasst alle datenbankbezogenen Dienste wie ProxySQL, HAProxy, MaxScale, Keepalived, Prometheus-Exporter und garbd. Besonderes Augenmerk auf Prometheus-Exporter, bei denen ClusterControl ein Programm namens "Daemon" verwendet, um den Exporter-Prozess zu dämonisieren. ClusterControl wird versuchen, eine Verbindung mit dem Überwachungsport des Exporters zur Zustandsprüfung und Verifizierung herzustellen. Daher wird empfohlen, die Exporter-Ports von ClusterControl und Prometheus-Server zu öffnen, um sicherzustellen, dass während der Wiederherstellung kein Fehlalarm ausgelöst wird.
Cluster-Wiederherstellung
ClusterControl versteht die Datenbanktopologie und befolgt Best Practices bei der Durchführung der Wiederherstellung. Bei einem Datenbankcluster mit integrierter Fehlertoleranz wie Galera Cluster, NDB Cluster und MongoDB Replicaset wird der Failover-Prozess automatisch vom Datenbankserver über Quorumberechnung, Heartbeat und Rollenwechsel (falls vorhanden) durchgeführt. ClusterControl überwacht den Prozess und nimmt die erforderlichen Anpassungen an der Visualisierung vor, wie z. B. das Wiedergeben der Änderungen in der Topologieansicht und das Anpassen der Überwachungs- und Verwaltungskomponente für die neue Rolle, z. B. neuer primärer Knoten in einem Replikatsatz.
Für Datenbanktechnologien, die keine eingebaute Fehlertoleranz mit automatischer Wiederherstellung haben, wie MySQL/MariaDB-Replikation und PostgreSQL/TimescaleDB-Streaming-Replikation, führt ClusterControl die Wiederherstellungsverfahren durch, indem es die Best Practices befolgt, die von bereitgestellt werden Datenbankanbieter. Wenn die Wiederherstellung fehlschlägt, ist ein Benutzereingriff erforderlich, und natürlich erhalten Sie diesbezüglich eine Alarmbenachrichtigung.
In einer gemischten/hybriden Topologie, zum Beispiel ein asynchroner Slave, der an ein Galera-Cluster oder NDB-Cluster angeschlossen ist, wird der Knoten von ClusterControl wiederhergestellt, wenn die Cluster-Wiederherstellung aktiviert ist.
Cluster-Wiederherstellung gilt nicht für eigenständige MySQL-Server. Es wird jedoch empfohlen, sowohl die Knoten- als auch die Clusterwiederherstellung für diesen Clustertyp in der ClusterControl-Benutzeroberfläche zu aktivieren.
MySQL/MariaDB-Replikation
ClusterControl unterstützt die Wiederherstellung der folgenden MySQL/MariaDB-Replikationskonfiguration:
- Master-Slave mit MySQL-GTID
- Master-Slave mit MariaDB GTID
- Master-Slave mit ohne GTID (sowohl MySQL als auch MariaDB)
- Master-master mit MySQL GTID
- Master-Master mit MariaDB GTID
- Asynchroner Slave, der an ein Galera-Cluster angeschlossen ist
ClusterControl berücksichtigt die folgenden Parameter bei der Clusterwiederherstellung:
- enable_cluster_autorecovery
- auto_manage_readonly
- repl_password
- repl_user
- replication_auto_rebuild_slave
- replication_check_binlog_filtration_bf_failover
- replication_check_external_bf_failover
- replication_failed_reslave_failover_script
- replication_failover_blacklist
- replication_failover_events
- replication_failover_wait_to_apply_timeout
- replication_failover_whitelist
- replication_onfail_failover_script
- replication_post_failover_script
- replication_post_switchover_script
- replication_post_unsuccessful_failover_script
- replication_pre_failover_script
- replication_pre_switchover_script
- replication_skip_apply_missing_txs
- replication_stop_on_error
Weitere Details zu jedem Parameter finden Sie auf der Dokumentationsseite.
ClusterControl befolgt die folgenden Regeln bei der Überwachung und Verwaltung einer Master-Slave-Replikation:
- Alle Knoten werden mit read_only=ON und super_read_only=ON gestartet (unabhängig von ihrer Rolle).
- Nur ein Master (read_only=OFF) darf gleichzeitig arbeiten.
- Verlassen Sie sich auf die MySQL-Variable report_host, um die Topologie abzubilden.
- Wenn zwei oder mehr Knoten gleichzeitig read_only=OFF haben, setzt ClusterControl automatisch read_only=ON auf beiden Mastern, um sie vor versehentlichem Schreiben zu schützen. Es ist ein Benutzereingriff erforderlich, um den tatsächlichen Master auszuwählen, indem der Schreibschutz deaktiviert wird. Gehen Sie zu Knoten -> Knotenaktionen -> Schreibgeschützt deaktivieren.
Falls der aktive Master ausfällt, versucht ClusterControl, das Master-Failover in der folgenden Reihenfolge durchzuführen:
- Nach 3 Sekunden der Nichterreichbarkeit des Masters wird ClusterControl einen Alarm auslösen.
- Überprüfen Sie die Slave-Verfügbarkeit, mindestens einer der Slaves muss für ClusterControl erreichbar sein.
- Wählen Sie den Sklaven als Kandidaten, um ein Meister zu werden.
- ClusterControl berechnet die Wahrscheinlichkeit fehlerhafter Transaktionen, wenn GTID aktiviert ist.
- Wenn keine fehlerhafte Transaktion erkannt wird, wird der Auserwählte zum neuen Master befördert.
- Erstellen und gewähren Sie einen Replikationsbenutzer, der von Slaves verwendet werden soll.
- Ändere den Master für alle Slaves, die auf den alten Master verweisen, auf den neu beförderten Master.
- Slave starten und nur lesen aktivieren.
- Protokolle auf allen Knoten leeren.
- Wenn die Slave-Promotion fehlschlägt, bricht ClusterControl den Wiederherstellungsjob ab. Ein Benutzereingriff oder ein Neustart des cmon-Dienstes ist erforderlich, um den Wiederherstellungsjob erneut auszulösen.
- Wenn der alte Master wieder verfügbar ist, wird er schreibgeschützt gestartet und ist nicht Teil der Replikation. Ein Benutzereingriff ist erforderlich.
Gleichzeitig werden folgende Alarme ausgelöst:
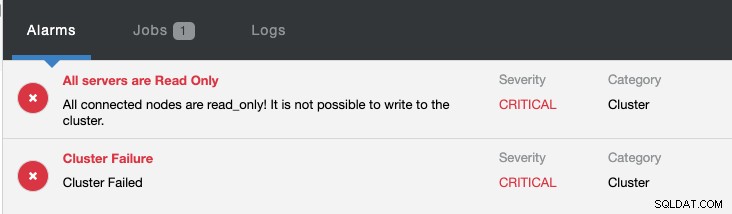
Sehen Sie sich Introduction to Failover for MySQL Replication - the 101 Blog and Automatic Failover of MySQL Replication - New in ClusterControl 1.4 an, um weitere Informationen zur Konfiguration und Verwaltung von MySQL-Replikations-Failover mit ClusterControl zu erhalten.
PostgreSQL/TimescaleDB-Streaming-Replikation
ClusterControl unterstützt die Wiederherstellung der folgenden PostgreSQL-Replikationskonfiguration:
- PostgreSQL-Streaming-Replikation
- TimescaleDB-Streaming-Replikation
ClusterControl berücksichtigt die folgenden Parameter bei der Clusterwiederherstellung:
- enable_cluster_autorecovery
- repl_password
- repl_user
- replication_auto_rebuild_slave
- replication_failover_whitelist
- replication_failover_blacklist
Weitere Details zu jedem Parameter finden Sie auf der Dokumentationsseite.
ClusterControl befolgt die folgenden Regeln zum Verwalten und Überwachen einer PostgreSQL-Streaming-Replikationseinrichtung:
- wal_level ist auf "replica" (oder "hot_standby" je nach PostgreSQL-Version) gesetzt.
- Variable archive_mode ist auf dem Master auf ON gesetzt.
- Legen Sie die Datei recovery.conf auf den Slave-Knoten fest, die den Knoten in einen Hot-Standby mit aktiviertem Nur-Lesen verwandelt.
Falls der aktive Master ausfällt, versucht ClusterControl, die Cluster-Wiederherstellung in der folgenden Reihenfolge durchzuführen:
- Nach 10 Sekunden der Nichterreichbarkeit des Masters wird ClusterControl einen Alarm auslösen.
- Nach 10 Sekunden ordnungsgemäßer Wartezeit initiiert ClusterControl den Master-Failover-Job.
- Stichproben von replayLocation und ReceiveLocation auf allen verfügbaren Knoten, um den am weitesten fortgeschrittenen Knoten zu bestimmen.
- Befördern Sie den fortschrittlichsten Knoten zum neuen Master.
- Sklaven stoppen.
- Überprüfen Sie den Synchronisationsstatus mit pg_rewind.
- Neustart von Slaves mit dem neuen Master.
- Wenn die Slave-Promotion fehlschlägt, bricht ClusterControl den Wiederherstellungsjob ab. Ein Benutzereingriff oder ein Neustart des cmon-Dienstes ist erforderlich, um den Wiederherstellungsjob erneut auszulösen.
- Wenn der alte Master wieder verfügbar ist, wird er zum Herunterfahren gezwungen und wird nicht Teil der Replikation sein. Ein Benutzereingriff ist erforderlich. Siehe weiter unten.
Wenn der alte Master wieder online geht und der PostgreSQL-Dienst läuft, erzwingt ClusterControl das Herunterfahren des PostgreSQL-Dienstes. Dies soll den Server vor unbeabsichtigten Schreibvorgängen schützen, da er ohne Recovery-Datei (recovery.conf) gestartet und somit beschreibbar wäre. Sie sollten damit rechnen, dass die folgenden Zeilen in postgresql-{day}.log erscheinen:
2019-11-27 05:06:10.091 UTC [2392] LOG: database system is ready to accept connections
2019-11-27 05:06:27.696 UTC [2392] LOG: received fast shutdown request
2019-11-27 05:06:27.700 UTC [2392] LOG: aborting any active transactions
2019-11-27 05:06:27.703 UTC [2766] FATAL: terminating connection due to administrator command
2019-11-27 05:06:27.704 UTC [2758] FATAL: terminating connection due to administrator command
2019-11-27 05:06:27.709 UTC [2392] LOG: background worker "logical replication launcher" (PID 2419) exited with exit code 1
2019-11-27 05:06:27.709 UTC [2414] LOG: shutting down
2019-11-27 05:06:27.735 UTC [2392] LOG: database system is shut downDas PostgreSQL wurde gestartet, nachdem der Server gegen 05:06:10 wieder online war, aber ClusterControl führt 17 Sekunden danach einen schnellen Shutdown durch, um 05:06:27. Wenn Sie dies nicht möchten, können Sie die Knotenwiederherstellung für diesen Cluster vorübergehend deaktivieren.
Sehen Sie sich Automatisches Failover der Postgres-Replikation und Failover für PostgreSQL-Replikation 101 an, um weitere Informationen zum Konfigurieren und Verwalten von PostgreSQL-Replikations-Failover mit ClusterControl zu erhalten.
Fazit
Die automatische Wiederherstellung von ClusterControl versteht die Datenbank-Cluster-Topologie und ist in der Lage, einen ausgefallenen oder herabgesetzten Cluster zu einem voll funktionsfähigen Cluster wiederherzustellen, was die Betriebszeit des Datenbankdienstes enorm verbessert. Testen Sie ClusterControl jetzt und erreichen Sie Ihre Neunen in SLA- und Datenbankverfügbarkeit. Sie kennen Ihre Neunen nicht? Sehen Sie sich diesen coolen Neuner-Rechner an.



