MongoDB ist eine NoSQL-Datenbank, die eine Vielzahl von Quellen für Eingabedatensätze unterstützt. Es ist in der Lage, Daten in flexiblen JSON-ähnlichen Dokumenten zu speichern, was bedeutet, dass Felder oder Metadaten von Dokument zu Dokument variieren können und die Datenstruktur im Laufe der Zeit geändert werden kann. Das Dokumentenmodell erleichtert die Arbeit mit den Daten, indem es den Objekten im Anwendungscode zugeordnet wird. MongoDB ist im Kern auch als verteilte Datenbank bekannt, sodass Hochverfügbarkeit, horizontale Skalierung und geografische Verteilung integriert und einfach zu verwenden sind. Es bietet die Möglichkeit, Parameter für das Modelltraining nahtlos zu ändern. Data Scientists können die Strukturierung von Daten einfach mit dieser Modellgenerierung zusammenführen.
Was ist maschinelles Lernen?
Maschinelles Lernen ist die Wissenschaft, Computer dazu zu bringen, wie Menschen zu lernen und zu handeln und ihr Lernen im Laufe der Zeit auf autonome Weise zu verbessern. Der Lernprozess beginnt mit Beobachtungen oder Daten, wie z. B. Beispielen, direkten Erfahrungen oder Anweisungen, um nach Mustern in Daten zu suchen und anhand der von uns bereitgestellten Beispiele in Zukunft bessere Entscheidungen zu treffen. Das Hauptziel besteht darin, den Computern zu ermöglichen, automatisch ohne menschliche Intervention oder Unterstützung zu lernen und Aktionen entsprechend anzupassen.
Ein umfangreiches Programmier- und Abfragemodell
MongoDB bietet sowohl native Treiber als auch zertifizierte Konnektoren für Entwickler und Datenwissenschaftler, die maschinelle Lernmodelle mit Daten aus MongoDB erstellen. PyMongo ist eine großartige Bibliothek zum Einbetten der MongoDB-Syntax in Python-Code. Wir können alle Funktionen und Methoden von MongoDB importieren, um sie in unserem maschinellen Lerncode zu verwenden. Es ist eine großartige Technik, um mehrsprachige Funktionalität in einem einzigen Code zu erhalten. Der zusätzliche Vorteil besteht darin, dass Sie die wesentlichen Funktionen dieser Programmiersprachen verwenden können, um eine effiziente Anwendung zu erstellen.
Die MongoDB-Abfragesprache mit reichhaltigen Sekundärindizes ermöglicht es Entwicklern, Anwendungen zu erstellen, die die Daten in mehreren Dimensionen abfragen und analysieren können. Auf die Daten kann über einzelne Schlüssel, Bereiche, Textsuche, Grafiken und Geodatenabfragen durch komplexe Aggregationen und MapReduce-Jobs zugegriffen werden, die Antworten in Millisekunden zurückgeben.
Um die Datenverarbeitung über einen verteilten Datenbankcluster zu parallelisieren, stellt MongoDB die Aggregationspipeline und MapReduce bereit. Die MongoDB-Aggregationspipeline ist nach dem Konzept der Datenverarbeitungspipelines modelliert. Dokumente gelangen in eine mehrstufige Pipeline, die die Dokumente mithilfe nativer Operationen, die in MongoDB ausgeführt werden, in ein aggregiertes Ergebnis umwandelt. Die grundlegendsten Pipeline-Stufen bieten Filter, die wie Abfragen funktionieren, und Dokumenttransformationen, die die Form des Ausgabedokuments ändern. Andere Pipeline-Operationen bieten Tools zum Gruppieren und Sortieren von Dokumenten nach bestimmten Feldern sowie Tools zum Aggregieren des Inhalts von Arrays, einschließlich Arrays von Dokumenten. Darüber hinaus können Pipeline-Stufen Operatoren für Aufgaben wie das Berechnen des Durchschnitts oder der Standardabweichungen über Sammlungen von Dokumenten hinweg und das Bearbeiten von Zeichenfolgen verwenden. MongoDB bietet auch native MapReduce-Operationen innerhalb der Datenbank, wobei benutzerdefinierte JavaScript-Funktionen verwendet werden, um die Karte auszuführen und Stufen zu reduzieren.
Zusätzlich zu seinem nativen Abfrage-Framework bietet MongoDB auch einen Hochleistungs-Connector für Apache Spark. Der Konnektor stellt alle Bibliotheken von Spark bereit, einschließlich Python, R, Scala und Java. MongoDB-Daten werden als DataFrames und Datasets zur Analyse mit maschinellem Lernen, Diagrammen, Streaming und SQL-APIs materialisiert.
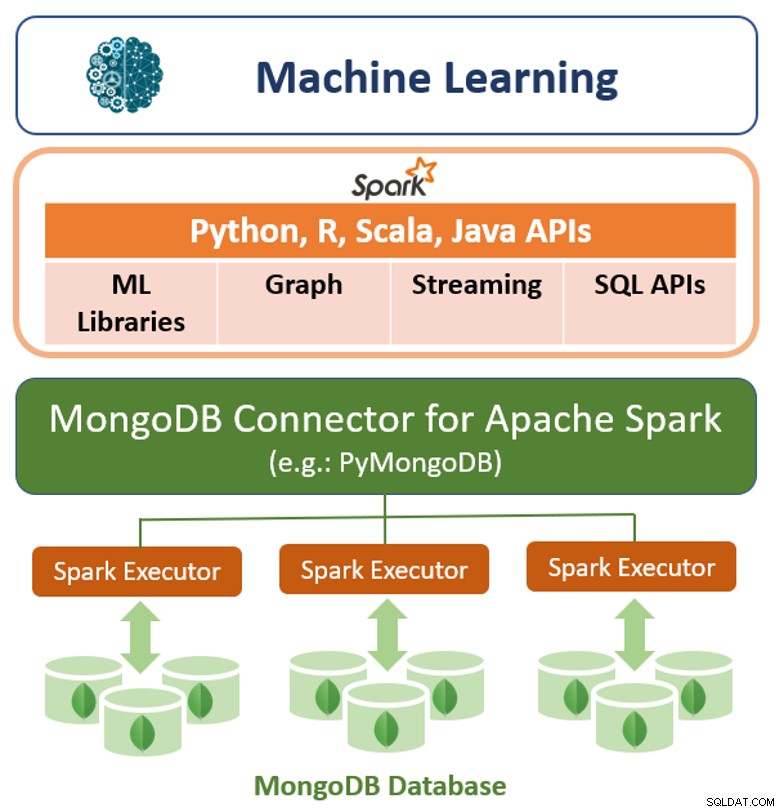
Der MongoDB-Connector für Apache Spark kann die Vorteile der Aggregationspipeline von MongoDB und der sekundären Pipeline nutzen Indizes, um nur den benötigten Datenbereich zu extrahieren, zu filtern und zu verarbeiten - zum Beispiel die Analyse aller Kunden in einer bestimmten Region. Dies unterscheidet sich stark von einfachen NoSQL-Datenspeichern, die weder sekundäre Indizes noch datenbankinterne Aggregationen unterstützen. In diesen Fällen müsste Spark alle Daten basierend auf einem einfachen Primärschlüssel extrahieren, selbst wenn nur eine Teilmenge dieser Daten für den Spark-Prozess benötigt wird. Dies bedeutet mehr Verarbeitungsaufwand, mehr Hardware und eine längere Zeit bis zur Erkenntnis für Data Scientists und Ingenieure. Um die Leistung über große, verteilte Datensätze hinweg zu maximieren, kann der MongoDB Connector für Apache Spark Resilient Distributed Datasets (RDDs) mit dem MongoDB-Quellknoten zusammenlegen, wodurch die Datenbewegung im Cluster minimiert und die Latenz reduziert wird.
Leistung, Skalierbarkeit und Redundanz
Die Modelltrainingszeit kann reduziert werden, indem die maschinelle Lernplattform auf einer leistungsfähigen und skalierbaren Datenbankschicht aufgebaut wird. MongoDB bietet eine Reihe von Innovationen, um den Durchsatz zu maximieren und die Latenz von Arbeitslasten für maschinelles Lernen zu minimieren:
- WiredTiger ist bekannt als die Standardspeicher-Engine für MongoDB, entwickelt von den Architekten von Berkeley DB, der weltweit am häufigsten eingesetzten eingebetteten Datenverwaltungssoftware. WiredTiger skaliert auf modernen Multicore-Architekturen. WiredTiger nutzt eine Vielzahl von Programmiertechniken wie Hazard-Pointer, Lock-Free-Algorithmen, Fast-Latch und Message-Passing und maximiert die Rechenarbeit pro CPU-Kern und Taktzyklus. Um den Overhead und die E/A auf der Festplatte zu minimieren, verwendet WiredTiger kompakte Dateiformate und Speicherkomprimierung.
- Für die latenzempfindlichsten Machine-Learning-Anwendungen kann MongoDB mit der In-Memory-Speicher-Engine konfiguriert werden. Diese auf WiredTiger basierende Speicher-Engine bietet Benutzern die Vorteile von In-Memory-Computing, ohne die reichhaltige Abfrageflexibilität, Echtzeitanalyse und skalierbare Kapazität herkömmlicher festplattenbasierter Datenbanken aufzugeben.
- Um das Modelltraining zu parallelisieren und Eingabedatensätze über einen einzelnen Knoten hinaus zu skalieren, verwendet MongoDB eine Technik namens Sharding, die Verarbeitung und Daten über Cluster von handelsüblicher Hardware verteilt. Das MongoDB-Sharding ist vollständig elastisch und gleicht Daten im gesamten Cluster automatisch neu aus, wenn das Eingabe-Dataset wächst oder Knoten hinzugefügt und entfernt werden.
- Innerhalb eines MongoDB-Clusters werden Daten von jedem Shard automatisch auf mehrere Replikate verteilt, die auf separaten Knoten gehostet werden. MongoDB-Replikatsätze bieten Redundanz, um Trainingsdaten im Falle eines Fehlers wiederherzustellen, wodurch der Aufwand für Checkpointing reduziert wird.
Einstellbare Konsistenz von MongoDB
MongoDB ist standardmäßig stark konsistent, sodass Anwendungen für maschinelles Lernen sofort lesen können, was in die Datenbank geschrieben wurde, wodurch die Entwicklerkomplexität vermieden wird, die durch letztendlich konsistente Systeme auferlegt wird. Eine starke Konsistenz liefert die genauesten Ergebnisse für maschinelle Lernalgorithmen; In einigen Szenarien ist es jedoch akzeptabel, die Konsistenz gegen bestimmte Leistungsziele einzutauschen, indem Abfragen über einen Cluster von sekundären Replikatsatzmitgliedern von MongoDB verteilt werden.
Flexibles Datenmodell in MongoDB
Das Dokumentdatenmodell von MongoDB erleichtert Entwicklern und Datenwissenschaftlern das Speichern und Aggregieren von Daten beliebiger Struktur innerhalb der Datenbank, ohne auf ausgefeilte Validierungsregeln zur Steuerung der Datenqualität verzichten zu müssen. Das Schema kann ohne eine Anwendungs- oder Datenbank-Ausfallzeit dynamisch geändert werden, die durch kostspielige Schema-Änderungen oder Umgestaltungen entsteht, die bei relationalen Datenbanksystemen anfallen.
Modelle in einer Datenbank zu speichern und sie mit Python zu laden, ist ebenfalls eine einfache und oft benötigte Methode. Die Wahl von MongoDB ist auch ein Vorteil, da es sich um eine Open-Source-Dokumentendatenbank und auch um eine führende NoSQL-Datenbank handelt. MongoDB dient auch als Konnektor für das verteilte Framework Apache Spark.
Die dynamische Natur von MongoDB
Die dynamische Natur von MongoDB ermöglicht seine Verwendung bei Datenbankmanipulationsaufgaben bei der Entwicklung von Anwendungen für maschinelles Lernen. Es ist eine sehr effiziente und einfache Möglichkeit, eine Analyse von Datensätzen und Datenbanken durchzuführen. Die Ausgabe der Analyse kann zum Trainieren von Modellen für maschinelles Lernen verwendet werden. Es wurde empfohlen, dass Datenanalysten und Programmierer für maschinelles Lernen MongoDB beherrschen und in vielen verschiedenen Anwendungen anwenden. Das Aggregation-Framework von MongoDB wird für Data-Science-Workflows zur Durchführung von Datenanalysen für zahlreiche Anwendungen verwendet.
Fazit
MongoDB bietet verschiedene Funktionen wie:flexibles Datenmodell, reichhaltige Programmierung, Datenmodell, Abfragemodell und seine anpassbare Konsistenz, die das Training und die Verwendung von Algorithmen für maschinelles Lernen viel einfacher machen als mit herkömmlichen, relationalen Datenbanken. Das Ausführen von MongoDB als Back-End-Datenbank ermöglicht das Speichern und Anreichern von maschinellen Lerndaten, was Persistenz und erhöhte Effizienz ermöglicht.



