Einführung
Das Speichern von Daten ist eine Sache; Speichern sinnvoll, nützlich, richtig Daten ist etwas ganz anderes. Während Sinn und Nützlichkeit selbst subjektive Eigenschaften sind, lässt sich Korrektheit zumindest logisch definieren und durchsetzen. Typen stellen bereits sicher, dass Zahlen Zahlen und Datumsangaben Datumsangaben sind, können aber nicht garantieren, dass Gewichtung oder Entfernung positive Zahlen sind, oder verhindern, dass sich Datumsbereiche überschneiden. Tupel-, Tabellen- und Datenbankbeschränkungen wenden Regeln auf gespeicherte Daten an und lehnen Werte oder Kombinationen von Werten ab, die die Musterung nicht bestehen.
Einschränkungen machen andere Eingabevalidierungstechniken keineswegs nutzlos, selbst wenn sie dieselben Behauptungen testen. Zeit, die mit dem Versuch verbracht wird, ungültige Daten zu speichern, ist verschwendete Zeit. Meldung von Verstößen wie assert in Systemen und Anwendungsprogrammiersprachen, enthüllt nur das erste Problem mit dem ersten Kandidatendatensatz viel detaillierter als jeder, der nicht unmittelbar mit der Datenbank zu tun hat. Aber was die Korrektheit von Daten anbelangt, sind Einschränkungen gesetzlich vorgeschrieben, im Guten wie im Bösen; alles andere sind Ratschläge.
On Tuples:Not Null, Default und Check
Nicht-Null-Einschränkungen sind die einfachste Kategorie. Ein Tupel muss einen Wert für das eingeschränkte Attribut haben, oder anders ausgedrückt, die Menge zulässiger Werte für die Spalte enthält die leere Menge nicht mehr. Kein Wert bedeutet kein Tupel:Das Einfügen oder Aktualisieren wird abgelehnt.
Der Schutz vor Nullwerten ist so einfach wie das Deklarieren von column_name COLUMN_TYPE NOT NULL in CREATE TABLE oder ADD COLUMN . Nullwerte verursachen ganze Kategorien von Problemen zwischen der Datenbank und den Endbenutzern, daher ist es eine gute Angewohnheit, reflexartig Nicht-Null-Einschränkungen für jede Spalte ohne guten Grund zu definieren, um Nullen zuzulassen.
Die Bereitstellung eines Standardwerts, wenn nichts angegeben ist (durch Weglassen oder explizites NULL ) in einer Einfügung oder Aktualisierung wird nicht immer als Einschränkung angesehen, da Kandidatendatensätze geändert und gespeichert werden, anstatt abgelehnt zu werden. In vielen DBMS können Standardwerte von einer Funktion generiert werden, obwohl MySQL keine benutzerdefinierten Funktionen für diesen Zweck zulässt.
Jede andere Validierungsregel, die nur von den Werten innerhalb eines einzelnen Tupels abhängt, kann als CHECK implementiert werden Zwang. In gewissem Sinne NOT NULL selbst ist eine Abkürzung für CHECK (column_name IS NOT NULL); die bei Verletzung empfangene Fehlermeldung macht den größten Unterschied. CHECK , kann jedoch die Wahrheit jedes booleschen Prädikats auf ein einzelnes Tupel anwenden und erzwingen. Eine Tabelle, in der geografische Standorte gespeichert sind, sollte beispielsweise CHECK (latitude >= -90 AND latitude < 90) sein , und ähnlich für Längengrade zwischen -180 und 180 – oder, falls verfügbar, verwenden und validieren Sie einen GEOGRAPHY Datentyp.
Auf Tabellen:Eindeutig und Ausschluss
Einschränkungen auf Tabellenebene testen Tupel gegeneinander. Bei einer eindeutigen Einschränkung darf nur ein Datensatz einen bestimmten Satz von Werten für die eingeschränkten Spalten haben. Nullzulässigkeit kann hier Probleme bereiten, da NULL niemals gleich etwas anderem, bis einschließlich NULL selbst. Eine eindeutige Einschränkung für (batman, robin) ermöglicht daher unbegrenzte Kopien von jedem Robinless Batman.
Ausschlussbeschränkungen werden nur in PostgreSQL und DB2 unterstützt, füllen aber eine sehr nützliche Nische:Sie können Überschneidungen verhindern. Geben Sie die eingeschränkten Felder und die Operationen an, von denen jedes ausgewertet wird, und ein neuer Datensatz wird nur akzeptiert, wenn kein vorhandener Datensatz erfolgreich mit jedem Feld und jeder Operation verglichen werden kann. Zum Beispiel ein schedules Tabelle kann so konfiguriert werden, dass Konflikte abgewiesen werden:
-- text, int, etc. comparisons in exclusion constraints require this-- Postgres extensionCREATE EXTENSION btree_gist;CREATE TABLE schedules ( schedule_id SERIAL NOT NULL PRIMARY KEY, room_number TEXT NOT NULL, -- a range of TIMESTAMP WITH TIME ZONE provides both start and end duration TSTZRANGE, -- table-level constraints imply an index, since otherwise they'd -- have to search the entire table to validate a candidate record; -- GiST (generalized search tree) indexes are usually used in -- Postgres EXCLUDE USING GIST ( room_number WITH =, duration WITH && ));INSERT INTO schedules (room_number, duration)VALUES ('32A', '[2020-08-20T10:00:00Z,2020-08-20T11:00:00Z)');-- the same time in a different room: acceptedINSERT INTO schedules (room_number, duration)VALUES ('32B', '[2020-08-20T10:00:00Z,2020-08-20T11:00:00Z)');-- a half-hour overlap for an already-scheduled room: rejectedINSERT INTO schedules (room_number, duration)VALUES ('32A', '[2020-08-20T10:30:00Z,2020-08-20T11:30:00Z)');
Upsert-Operationen wie ON CONFLICT von PostgreSQL -Klausel oder ON DUPLICATE KEY UPDATE von MySQL Verwenden Sie eine Einschränkung auf Tabellenebene, um Konflikte zu erkennen. Und ähnliche Nicht-Null-Einschränkungen können als CHECK ausgedrückt werden Beschränkungen kann eine eindeutige Beschränkung als Ausschlussbeschränkung auf Gleichheit ausgedrückt werden.
Der Primärschlüssel
Unique Constraints haben einen besonders nützlichen Sonderfall. Mit einer zusätzlichen Nicht-Null-Einschränkung für die eindeutige Spalte oder Spalten kann jeder Datensatz in der Tabelle einzeln durch seine Werte für die eingeschränkten Spalten identifiziert werden, die zusammen als Schlüssel bezeichnet werden . In einer Tabelle können mehrere Schlüsselkandidaten koexistieren, z. B. users immer noch manchmal mit unterschiedlichen eindeutigen und nicht-null email s und username s; aber das Deklarieren eines Primärschlüssels legt ein einziges Kriterium fest, nach dem Aufzeichnungen öffentlich und ausschließlich bekannt sind. Einige RDBMS organisieren Zeilen auf Seiten sogar nach dem Primärschlüssel, der zu diesem Zweck als Clustered Index bezeichnet wird , um die Suche nach Primärschlüsselwerten so schnell wie möglich zu machen.
Es gibt zwei Arten von Primärschlüsseln. Ein natürlicher Schlüssel wird für eine Spalte oder Spalten definiert, die "natürlich" in den Daten der Tabelle enthalten sind, während ein Ersatz- oder synthetischer Schlüssel nur zu dem Zweck erfunden wird, der Schlüssel zu werden. Natürliche Schlüssel erfordern Sorgfalt – mehr Dinge können sich ändern, als Datenbankdesigner oft glauben, von Namen bis hin zu Nummerierungsschemata. Eine Nachschlagetabelle mit Länder- und Regionsnamen kann ihre jeweiligen ISO-3166-Codes als sicheren natürlichen Primärschlüssel verwenden, aber einen users Tabelle mit einem natürlichen Schlüssel, der auf veränderlichen Werten wie Namen oder E-Mail-Adressen basiert, lädt zu Problemen ein. Erstellen Sie im Zweifelsfall einen Ersatzschlüssel.
Wenn sich ein natürlicher Schlüssel über mehrere Spalten erstreckt, sollte immer zumindest ein Ersatzschlüssel in Betracht gezogen werden, da mehrspaltige Schlüssel mehr Aufwand in der Verwaltung erfordern. Wenn der natürliche Schlüssel passt, sollten die Spalten jedoch in aufsteigender Genauigkeit geordnet werden, genau wie in Indizes:Ländercode dann Regionscode und nicht umgekehrt.
Der Ersatzschlüssel war in der Vergangenheit eine einzelne ganzzahlige Spalte oder BIGINT wo schließlich Milliarden zugeteilt werden. Relationale Datenbanken können Ersatzschlüssel automatisch mit der nächsten Ganzzahl in einer Reihe füllen, eine Funktion, die normalerweise als SERIAL bezeichnet wird oder IDENTITY .
Ein automatisch inkrementierender numerischer Zähler ist nicht ohne Nachteile:Das Hinzufügen von Datensätzen mit vorgenerierten Schlüsseln kann zu Konflikten führen, und wenn den Benutzern sequenzielle Werte angezeigt werden, können sie leicht erraten, welche anderen gültigen Schlüssel es sein könnten. Universally Unique Identifiers oder UUIDs vermeiden diese Schwächen und sind zu einer gängigen Wahl für Ersatzschlüssel geworden, obwohl sie auch viel größer auf der Seite sind als eine einfache Zahl. Die UUID-Typen v1 (auf MAC-Adresse basierend) und v4 (pseudozufällig) werden am häufigsten verwendet.
Auf der Datenbank:Fremdschlüssel
Relationale Datenbanken implementieren nur eine Klasse von Einschränkungen für mehrere Tabellen, die
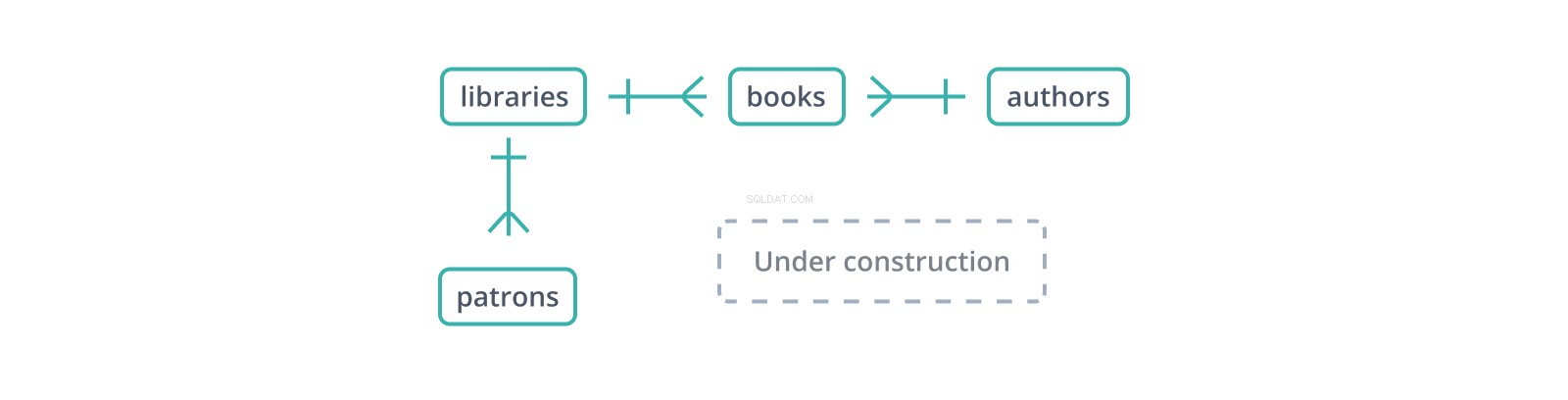
Dieses informelle "Entity-Relationship-Diagramm" oder ERD zeigt die Anfänge eines Schemas für eine Datenbank von Bibliotheken und ihren Sammlungen und Benutzern. Jede Kante stellt eine Beziehung zwischen den Tabellen dar, die sie verbindet. Die | Die Glyphe zeigt einen einzelnen Datensatz auf seiner Seite an, während die Glyphe "Krähenfuß" mehrere darstellt:Eine Bibliothek enthält viele Bücher und hat viele Benutzer.
Ein Fremdschlüssel ist eine Kopie des Primärschlüssels einer anderen Tabelle, Spalte für Spalte (ein Punkt zugunsten von Ersatzschlüsseln:nur eine Spalte zum Kopieren und Referenzieren), mit Werten, die Datensätze in dieser Tabelle mit "übergeordneten" Datensätzen darin verknüpfen. Im obigen Schema die books Tabelle verwaltet eine library_id Fremdschlüssel zu libraries , die Bücher enthalten, und eine author_id an authors , die sie schreiben. Aber was passiert, wenn ein Buch mit einer author_id eingefügt wird das existiert nicht in authors ?
Wenn der Fremdschlüssel nicht eingeschränkt ist – d. h. es ist nur eine weitere Spalte oder Spalten – kann ein Buch einen Autor haben, der nicht existiert. Dies ist ein Problem:wenn jemand versucht, dem Link zwischen books zu folgen und authors , sie landen nirgendwo. Wenn authors.author_id eine serielle Ganzzahl ist, besteht auch die Möglichkeit, dass niemand es bemerkt, bis die falsche author_id wird schließlich zugewiesen, und Sie landen mit einem bestimmten Exemplar von Don Quixote zuerst niemand bekannt und dann Pierre Menard zugeschrieben, wobei Miguel Cervantes nirgendwo zu finden ist.
Das Einschränken des Fremdschlüssels kann nicht verhindern, dass ein Buch falsch zugeordnet wird, wenn author_id falsch ist auf einen bestehenden Datensatz in authors verweisen , daher bleiben andere Überprüfungen und Tests wichtig. Der Satz vorhandener Fremdschlüsselwerte ist jedoch fast immer nur ein winziger Teil des Möglichen Fremdschlüsselwerte, sodass Fremdschlüsseleinschränkungen die meisten falschen Werte abfangen und verhindern. Mit einer Fremdschlüsselbeschränkung, dem Quixote mit einem nicht existierenden Autor werden abgelehnt statt aufgenommen.
Kommt das "relational" in "relationale Datenbank" von hier?
Fremdschlüssel erstellen Beziehungen zwischen Tabellen, aber Tabellen, wie wir sie kennen, sind mathematisch Beziehungen unter den Sätzen möglicher Werte für jedes Attribut. Ein einzelnes Tupel verknüpft einen Wert für Spalte A mit einem Wert für Spalte B und so weiter. E. F. Codds Originalarbeit verwendet „relational“ in diesem Sinne.
Dies hat zu endloser Verwirrung geführt und wird dies wahrscheinlich auf ewig tun.
Für bestimmte richtige Werte
Es gibt viele weitere Möglichkeiten, wie Daten falsch sein können, als hier angesprochen werden. Beschränkungen helfen, aber selbst sie sind nur begrenzt flexibel; viele gängige tabelleninterne Spezifikationen, wie z. B. ein Limit von zwei oder mehr, wie oft ein Wert in einer Spalte erscheinen darf, können nur mit Triggern erzwungen werden.
Aber es gibt auch Möglichkeiten, wie die Struktur einer Tabelle zu Inkonsistenzen führen kann. Um dies zu verhindern, müssen wir Primär- und Fremdschlüssel nicht nur zum Definieren und Validieren, sondern auch zum Normalisieren marshallen die Beziehungen zwischen Tabellen. Zunächst haben wir jedoch kaum an der Oberfläche gekratzt, wie die Beziehungen zwischen Tabellen die Struktur der Datenbank selbst definieren.