Einführung
Es gibt zwei Denkrichtungen über die Durchführung von Berechnungen in Ihrer Datenbank:Leute, die es großartig finden, und Leute, die falsch liegen. Das soll nicht heißen, dass die Welt der Funktionen, gespeicherten Prozeduren, generierten oder berechneten Spalten und Trigger nur Sonnenschein ist! Diese Tools sind alles andere als narrensicher, und unüberlegte Implementierungen können schlecht funktionieren, ihre Betreuer traumatisieren und vieles mehr, was zum Teil die Existenz von Kontroversen erklärt.
Aber Datenbanken sind per Definition sehr gut darin, Informationen zu verarbeiten und zu manipulieren, und die meisten von ihnen stellen ihren Benutzern dieselbe Kontrolle und Macht zur Verfügung (SQLite und MS Access in geringerem Maße). Externe Datenverarbeitungsprogramme beginnen auf der Rückseite, indem sie Informationen aus der Datenbank ziehen müssen, oft über ein Netzwerk, bevor sie etwas tun können. Und wo Datenbankprogramme native Mengenoperationen, Indexierung, temporäre Tabellen und andere Früchte eines halben Jahrhunderts Datenbankentwicklung voll ausnutzen können, erfordern externe Programme jeglicher Komplexität in der Regel ein gewisses Maß an Neuerfindung des Rades. Warum also nicht die Datenbank zum Laufen bringen?
Hier ist der Grund, warum Sie es vielleicht nicht tun sollten Ihre Datenbank programmieren möchten!
- Datenbankfunktionen neigen dazu, unsichtbar zu werden – besonders Trigger. Diese Schwäche skaliert ungefähr mit der Größe der Teams und/oder Anwendungen, die mit der Datenbank interagieren, da sich weniger Menschen an die datenbankinterne Programmierung erinnern oder sich dessen bewusst sind. Dokumentation hilft, aber nur so viel.
- SQL ist eine Sprache, die speziell für die Bearbeitung von Datensätzen entwickelt wurde. Es ist nicht besonders gut in Dingen, die keine Datensätze manipulieren, und es ist weniger gut, je komplizierter diese anderen Dinge werden.
- RDBMS-Fähigkeiten und SQL-Dialekte unterscheiden sich. Einfach generierte Spalten werden weitgehend unterstützt, aber die Portierung komplexerer Datenbanklogik auf andere Stores erfordert mindestens Zeit und Mühe.
- Datenbankschema-Upgrades sind in der Regel aufwendiger als Anwendungsupgrades. Sich schnell ändernde Logik wird am besten an anderer Stelle gepflegt, obwohl es einen weiteren Blick wert sein kann, sobald sich die Dinge stabilisieren.
- Das Verwalten von Datenbankprogrammen ist nicht so einfach, wie man hoffen könnte. Viele Schema-Migrationstools tun wenig oder gar nichts für die Organisation, was zu ausgedehnten Diffs und belastenden Codeüberprüfungen führt (die Abhängigkeitsdiagramme von sqitch und die Überarbeitung einzelner Objekte machen es zu einer bemerkenswerten Ausnahme, und migra versucht, das Problem vollständig zu umgehen). Beim Testen verbessern Frameworks wie pgTAP und utPLSQL Blackbox-Integrationstests, stellen aber auch eine zusätzliche Support- und Wartungsverpflichtung dar.
- Bei einer etablierten externen Codebasis ist jede strukturelle Änderung sowohl arbeitsintensiv als auch riskant.
Andererseits bietet SQL für die Aufgaben, für die es geeignet ist, Geschwindigkeit, Prägnanz, Dauerhaftigkeit und die Möglichkeit, automatisierte Arbeitsabläufe zu „kanonisieren“. Datenmodellierung ist mehr als das Festhalten von Entitäten wie Insekten an Pappe, und die Unterscheidung zwischen Daten in Bewegung und Daten im Ruhezustand ist schwierig. Ruhe ist wirklich langsamere Bewegung in feinerem Grad; Informationen fließen immer von hier nach dort, und die Programmierbarkeit von Datenbanken ist ein leistungsstarkes Werkzeug, um diese Ströme zu verwalten und zu lenken.
Einige Datenbank-Engines teilen den Unterschied zwischen SQL und anderen Programmiersprachen auf, indem sie diese anderen Programmiersprachen ebenfalls berücksichtigen. SQL Server unterstützt Funktionen, die in jeder .NET Framework-Sprache geschrieben sind; Oracle verfügt über gespeicherte Java-Prozeduren; PostgreSQL ermöglicht Erweiterungen mit C und ist benutzerprogrammierbar in Python, Perl und Tcl, wobei Plugins Shell-Skripte, R, JavaScript und mehr hinzufügen. Um die üblichen Verdächtigen abzurunden, ist es SQL oder nichts für MySQL und MariaDB, MS Access ist nur programmierbar in VBA, und SQLite ist überhaupt nicht benutzerprogrammierbar.
Die Verwendung von Nicht-SQL-Sprachen ist eine Option, wenn SQL für eine Aufgabe nicht ausreicht oder wenn Sie anderen Code wiederverwenden möchten, aber es wird Sie nicht um die anderen Probleme herumbringen, die die Datenbankprogrammierung zu einem vielschneidigen Schwert machen. Wenn überhaupt, verkompliziert der Rückgriff auf diese die Bereitstellung und Interoperabilität weiter. Warnungsskriptor:Lassen Sie den Autor aufpassen.
Funktionen vs. Prozeduren
Wie bei anderen Aspekten der Implementierung des SQL-Standards variieren die genauen Details ein wenig von RDBMS zu RDBMS. Allgemein:
- Funktionen können keine Transaktionen steuern.
- Funktionen geben Werte zurück; Prozeduren können mit
OUTbezeichnete Parameter ändern oderINOUTdie dann im aufrufenden Kontext gelesen werden können, aber niemals ein Ergebnis zurückgeben (SQL Server ausgenommen). - Funktionen werden innerhalb von SQL-Anweisungen aufgerufen, um einige Arbeiten an Datensätzen auszuführen, die abgerufen oder gespeichert werden, während Prozeduren allein stehen.
Insbesondere verbietet MySQL auch Rekursion und einige zusätzliche SQL-Anweisungen in Funktionen. SQL Server verhindert, dass Funktionen Daten ändern, dynamisches SQL ausführen und Fehler behandeln. PostgreSQL hat gespeicherte Prozeduren bis 2017 mit Version 11 überhaupt nicht von Funktionen getrennt, daher können Postgres-Funktionen fast alles tun, was Prozeduren können, mit Ausnahme der Transaktionskontrolle.
Also, was wann verwenden? Funktionen eignen sich am besten für Logik, die Datensatz für Datensatz anwendet, wenn Daten gespeichert und abgerufen werden. Komplexere Workflows, die von selbst aufgerufen werden und Daten intern verschieben, sind besser als Prozeduren.
Standards und Generierung
Selbst einfache Berechnungen können Probleme bereiten, wenn sie oft genug durchgeführt werden oder wenn mehrere konkurrierende Implementierungen vorhanden sind. Operationen mit Werten in einer einzelnen Zeile – etwa das Umrechnen zwischen metrischen und imperialen Einheiten, das Multiplizieren eines Satzes mit geleisteten Arbeitsstunden für Rechnungszwischensummen, das Berechnen der Fläche eines geografischen Polygons – können in einer Tabellendefinition deklariert werden, um das eine oder andere Problem zu lösen :
CREATE TABLE pythag ( a INT NOT NULL, b INT NOT NULL, c DOUBLE PRECISION NOT NULL GENERATED ALWAYS AS (sqrt(pow(a, 2) + pow(b, 2))) STORED);
Die meisten RDBMS bieten eine Auswahl zwischen „gespeicherten“ und „virtuell“ generierten Spalten. Im ersten Fall wird der Wert berechnet und gespeichert, wenn die Zeile eingefügt oder aktualisiert wird. Dies ist die einzige Möglichkeit mit PostgreSQL ab Version 12 und MS Access. Virtuell generierte Spalten werden bei Abfragen wie in Ansichten berechnet, sodass sie keinen Speicherplatz beanspruchen, aber häufiger neu berechnet werden. Beide Arten sind streng eingeschränkt:Werte können nicht von Informationen außerhalb der Zeile abhängen, zu der sie gehören, sie können nicht aktualisiert werden, und einzelne RDBMS können noch spezifischere Einschränkungen haben. PostgreSQL beispielsweise verbietet es, eine Tabelle auf eine generierte Spalte zu partitionieren.
Generierte Spalten sind ein spezialisiertes Werkzeug. Häufiger ist lediglich ein Standardwert erforderlich, falls beim Einfügen kein Wert angegeben wird. Funktionen wie now() werden häufig als Standardwerte für Spalten angezeigt, aber die meisten Datenbanken erlauben sowohl benutzerdefinierte als auch integrierte Funktionen (außer MySQL, wo nur current_timestamp kann ein Standardwert sein).
Nehmen wir das eher trockene, aber einfache Beispiel einer Chargennummer im Format YYYYXXX, wobei die ersten vier Ziffern das aktuelle Jahr darstellen und die letzten drei Ziffern einen aufsteigenden Zähler:Die erste in diesem Jahr produzierte Charge ist 2020001, die zweite 2020002 und so weiter . Es gibt keinen Standardtyp oder keine eingebaute Funktion, die einen solchen Wert generiert, aber eine benutzerdefinierte Funktion kann jedes Los
CREATE SEQUENCE lot_counter;CREATE OR REPLACE FUNCTION next_lot_number () RETURNS TEXT AS $$BEGIN RETURN date_part('year', now())::TEXT || lpad(nextval('lot_counter'::REGCLASS)::TEXT, 2, '0');END;$$LANGUAGE plpgsql;CREATE TABLE lots ( lot_number TEXT NOT NULL DEFAULT next_lot_number () PRIMARY KEY, current_quantity INT NOT NULL DEFAULT 0, target_quantity INT NOT NULL, created_at TIMESTAMPTZ NOT NULL DEFAULT now(), completed_at TIMESTAMPTZ, CHECK (target_quantity > 0));
Daten in Funktionen referenzieren
Der obige Sequenzansatz hat eine wichtige Schwäche (und lot_counter wird immer noch den gleichen Wert wie am 31. Dezember haben. Es gibt jedoch mehr als eine Möglichkeit zu verfolgen, wie viele Lose in einem Jahr erstellt wurden, und zwar durch Abfragen von lots selbst die next_lot_number Funktion kann einen korrekten Wert garantieren, nachdem das Jahr übergelaufen ist.
CREATE OR REPLACE FUNCTION next_lot_number () RETURNS TEXT AS $$BEGIN RETURN ( SELECT date_part('year', now())::TEXT || lpad((count(*) + 1)::TEXT, 2, '0') FROM lots WHERE date_part('year', created_at) = date_part('year', now()) );END;$$LANGUAGE plpgsql;ALTER TABLE lots ALTER COLUMN lot_number SET DEFAULT next_lot_number();
Workflows
Selbst eine Einzelanweisungsfunktion hat einen entscheidenden Vorteil gegenüber externem Code:Die Ausführung verlässt niemals die Sicherheit der ACID-Garantien der Datenbank. Vergleichen Sie next_lot_number oben zu den Möglichkeiten einer Client-Anwendung oder sogar eines manuellen Prozesses, der
Gespeicherte Programme mit mehreren Anweisungen eröffnen einen immensen Raum an Möglichkeiten, da SQL alle Tools enthält, die Sie zum Schreiben von prozeduralem Code benötigen, von der Ausnahmebehandlung bis zu Sicherungspunkten (es ist sogar Turing komplett mit Fensterfunktionen und allgemeinen Tabellenausdrücken!). Vollständige Datenverarbeitungs-Workflows können in der Datenbank ausgeführt werden, wodurch die Exposition gegenüber anderen Bereichen des Systems minimiert und zeitaufwändige Roundtrips zwischen der Datenbank und anderen Domänen vermieden werden.
Ein Großteil der Softwarearchitektur im Allgemeinen dreht sich darum, Komplexität zu verwalten und zu isolieren und zu verhindern, dass sie über die Grenzen zwischen Subsystemen hinausschwappt. Wenn ein mehr oder weniger komplizierter Arbeitsablauf darin besteht, Daten in ein Anwendungs-Backend, ein Skript oder einen Cron-Job zu ziehen, sie zu verdauen und hinzuzufügen und das Ergebnis zu speichern, ist es an der Zeit zu fragen, warum es wirklich erforderlich ist, sich außerhalb der Datenbank zu wagen.
Wie oben erwähnt, ist dies ein Bereich, in dem Unterschiede zwischen RDBMS-Varianten und SQL-Dialekten in den Vordergrund treten. Eine Funktion oder Prozedur, die für eine Datenbank entwickelt wurde, wird wahrscheinlich nicht ohne Änderungen auf einer anderen ausgeführt, unabhängig davon, ob diese das TOP von SQL Server ersetzt für ein Standard-LIMIT -Klausel oder eine vollständige Überarbeitung der Art und Weise, wie der temporäre Zustand bei einer Unternehmensmigration von Oracle zu PostgreSQL gespeichert wird. Die Kanonisierung Ihrer Arbeitsabläufe in SQL verpflichtet Sie auch gründlicher zu Ihrer aktuellen Plattform und Ihrem Dialekt als fast jede andere Wahl, die Sie treffen können.
Berechnungen in Abfragen
Bisher haben wir uns mit der Verwendung von Funktionen zum Speichern und Ändern von Daten befasst, unabhängig davon, ob sie an Tabellendefinitionen gebunden sind oder Workflows mit mehreren Tabellen verwalten. In gewisser Weise ist das der mächtigere Nutzen, für den sie eingesetzt werden können, aber Funktionen haben auch einen Platz beim Datenabruf. Viele Tools, die Sie möglicherweise bereits in Ihren Abfragen verwenden, sind als Funktionen aus integrierten Standardfunktionen wie count implementiert zu Erweiterungen wie jsonb_build_object von Postgres , ST_SnapToGrid von PostGIS , und mehr. Da diese natürlich enger mit der Datenbank selbst integriert sind, sind sie meistens in anderen Sprachen als SQL geschrieben (z. B. C im Fall von PostgreSQL und PostGIS).
Wenn Sie häufig feststellen (oder glauben, dass Sie sich finden könnten), dass Sie Daten abrufen und dann einige Vorgänge für jeden Datensatz ausführen müssen, bevor es wirklich ist bereit, erwägen Sie stattdessen, sie auf dem Weg aus der Datenbank zu transformieren! Projizieren Sie eine Anzahl von Werktagen von einem Datum aus? Generieren eines Unterschieds zwischen zwei JSONB Felder? Praktisch jede Berechnung, die nur von den abgefragten Informationen abhängt, kann in SQL durchgeführt werden. Und was in der Datenbank gemacht wird – solange konsistent darauf zugegriffen wird – ist kanonisch, soweit es um alles geht, was auf der Datenbank aufgebaut ist.
Es muss gesagt werden:Wenn Sie mit einem Anwendungs-Backend arbeiten, kann sein Datenzugriffs-Toolkit den Umfang einschränken, den Sie aus der Erweiterung von Abfrageergebnissen mit Funktionen ziehen. Die meisten dieser Bibliotheken können beliebiges SQL ausführen, aber diejenigen, die allgemeine SQL-Anweisungen auf der Grundlage von Modellklassen generieren, können die Anpassung der Abfrage SELECT zulassen oder nicht Listen. Generierte Spalten oder Ansichten können hier eine Antwort sein.
Triggers and Consequences
Funktionen und Prozeduren sind unter Datenbankdesignern und -benutzern umstritten genug, aber Dinge wirklich mit Triggern abheben. Ein Trigger definiert eine automatische Aktion, normalerweise eine Prozedur (SQLite erlaubt nur eine einzelne Anweisung), die vor, nach oder anstelle einer anderen Aktion ausgeführt wird.
Die auslösende Aktion ist im Allgemeinen ein Einfügen, Aktualisieren oder Löschen einer Tabelle, und die Auslöseprozedur kann normalerweise so eingestellt werden, dass sie entweder für jeden Datensatz oder für die Anweisung als Ganzes ausgeführt wird. SQL Server lässt auch Trigger für aktualisierbare Ansichten zu, hauptsächlich um detailliertere Sicherheitsmaßnahmen durchzusetzen; und it, PostgreSQL und Oracle bieten alle irgendeine Art von Ereignis oder
Eine übliche risikoarme Verwendung für Trigger ist eine besonders starke Einschränkung, die verhindert, dass ungültige Daten gespeichert werden. In allen großen relationalen Datenbanken nur Primär- und Fremdschlüssel und UNIQUE Einschränkungen können Informationen außerhalb des Kandidatendatensatzes auswerten. Es ist nicht möglich, in einer Tabellendefinition zu deklarieren, dass beispielsweise nur zwei Lose in einem Monat erstellt werden dürfen – und die einfachste Datenbank-und-Code-Lösung ist anfällig für eine ähnliche Race-Condition wie der Count-then-Set-Ansatz lot_number Oben. Um eine andere Einschränkung zu erzwingen, die die gesamte Tabelle oder andere Tabellen betrifft, benötigen Sie einen
CREATE FUNCTION enforce_monthly_lot_limit () RETURNS TRIGGERAS $$DECLARE current_count BIGINT;BEGIN SELECT count(*) INTO current_count FROM lots WHERE date_trunc('month', created_at) = date_trunc('month', NEW.created_at); IF current_count >= 2 THEN RAISE EXCEPTION 'Two lots already created this month'; END IF; RETURN NEW;END;$$LANGUAGE plpgsql;CREATE TRIGGER monthly_lot_limitBEFORE INSERT ON lotsFOR EACH ROWEXECUTE PROCEDURE enforce_monthly_lot_limit();
Sobald Sie mit der Ausführung von lots selbst kann die letzte Operation eines Triggers sein, der durch eine Einfügung in orders initiiert wird , ohne dass ein menschlicher Benutzer oder ein Anwendungs-Backend berechtigt ist, in lots zu schreiben direkt. Oder als items zu vielen hinzugefügt werden, könnte ein Trigger dort die Aktualisierung von current_quantity handhaben , und starten Sie einen anderen Prozess, wenn er die target_quantity erreicht .
Trigger und Funktionen können auf der Zugriffsebene ihres Definierers ausgeführt werden (in PostgreSQL ein SECURITY DEFINER -Deklaration neben der LANGUAGE einer Funktion ), was ansonsten eingeschränkten Benutzern die Möglichkeit gibt, weitreichendere Prozesse zu initiieren – und das Validieren und Testen dieser Prozesse umso wichtiger macht.
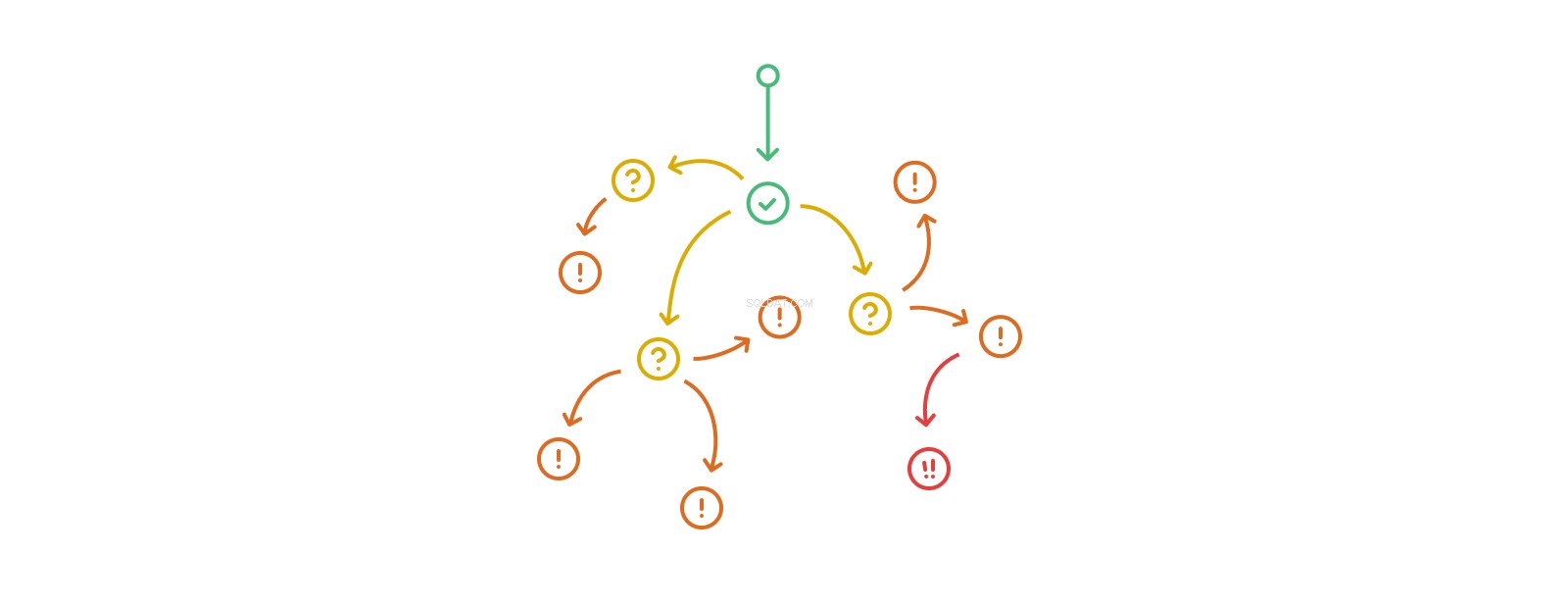
Der Trigger-Action-Trigger-Action-Aufrufstapel kann beliebig lang werden, obwohl eine echte Rekursion in Form der mehrfachen Änderung derselben Tabellen oder Datensätze in einem solchen Fluss auf einigen Plattformen illegal und im Allgemeinen unter fast allen Umständen eine schlechte Idee ist. Die Verschachtelung von Auslösern übersteigt schnell unsere Fähigkeit, ihr Ausmaß und ihre Auswirkungen zu verstehen. Datenbanken, die stark von verschachtelten Triggern Gebrauch machen, beginnen, aus dem Bereich des Komplizierten in den Bereich des Komplexen abzudriften, und es wird schwierig oder unmöglich, sie zu analysieren, zu debuggen und vorherzusagen.
Praktische Programmierbarkeit
Berechnungen in der Datenbank sind nicht nur schneller und prägnanter ausgedrückt:Sie beseitigen Mehrdeutigkeiten und setzen Maßstäbe. Die obigen Beispiele befreien Datenbankbenutzer davon, Losnummern selbst berechnen zu müssen, oder sich Sorgen zu machen, versehentlich mehr Lose zu erstellen, als sie handhaben können. Insbesondere Anwendungsentwickler wurden oft darauf trainiert, Datenbanken als "dummen Speicher" zu betrachten, der nur Struktur und Persistenz bereitstellt, und können sich daher wiederfinden - oder schlimmer noch, nicht erkennen, dass sie es tun - und ungeschickt außerhalb der Datenbank artikulieren, was sie tun könnten effektiver in SQL.
Programmierbarkeit ist ein zu Unrecht übersehenes Merkmal relationaler Datenbanken. Es gibt Gründe, es zu vermeiden, und mehr, seine Verwendung einzuschränken, aber Funktionen, Prozeduren und Trigger sind allesamt leistungsstarke Werkzeuge, um die Komplexität zu begrenzen, die Ihr Datenmodell den Systemen auferlegt, in die es eingebettet ist.



