In diesem Artikel werde ich erklären, wie Sie eine Tabelle aus der primären Dateigruppe in die sekundäre Dateigruppe verschieben. Lassen Sie uns zunächst verstehen, was Datendatei, Dateigruppe und Dateigruppentyp sind.
Datenbankdateien und Dateigruppen
Wenn SQL Server auf einem beliebigen Server installiert wird, erstellt es eine primäre Datendatei und eine Protokolldatei zum Speichern von Daten. Die primäre Datendatei speichert Daten und Datenbankobjekte wie Tabellen, Indizes, gespeicherte Prozeduren usw. Protokolldateien speichern Informationen, die zum Wiederherstellen von Transaktionen erforderlich sind. Datendateien können in Dateigruppen zusammengefasst werden.
SQL Server hat drei Arten von Dateien
- Primäre Datei :Es wird bei der Installation von SQL Server erstellt und enthält die Metadaten und Informationen der Datenbank. Benutzerdaten, Objekte können in den Primärdatendateien gespeichert werden. Die Primärdatei hat die Erweiterung .mdf.
- Sekundäre Datei :Sekundärdateien sind benutzerdefiniert. Sie speichern Benutzerdaten, von einem Benutzer erstellte Objekte. Sie haben die Erweiterung .ndf.
- Transaktionsprotokolldatei s:Die T-Logs-Dateien protokollieren alle zur Wiederherstellung der Datenbank durchgeführten Transaktionen. Die Protokolldateierweiterung in .ldf.
Wie oben erwähnt, können Datendateien in einer Dateigruppe gruppiert werden. Während der Installation von SQL Server wird die primäre Dateigruppe mit einer primären Datendatei erstellt. Sekundäre Dateigruppen sind benutzerdefiniert. Sie haben sekundäre Datendateien. Wenn wir eine neue Datenbank erstellen, können wir sekundäre Datendateien und Dateigruppen erstellen. Das Hinzufügen sekundärer Datendateien hilft, die Leistung zu verbessern. Es kann auf verschiedenen Festplattenlaufwerken oder separaten Festplattenpartitionen erstellt werden, wodurch die IO-Wartezeit und die Lese-Schreib-Latenz verringert werden.
Es wird empfohlen, Tabellen und Indizes in separaten Dateigruppen aufzubewahren. Außerdem verbessert das Aufbewahren großer Tabellen in separaten Dateien die Leistung.
Es gibt drei Arten von Dateigruppen:
- Zeilendateigruppe :Zeilendateigruppe, auch bekannt als primäre Dateigruppe, enthält eine primäre Datendatei. SQL-Objekt, Daten, Systemtabellen werden der primären Dateigruppe zugeordnet.
- Speicheroptimierte Dateigruppe :Speicheroptimierte Dateigruppe enthält speicheroptimierte Tabellen und Daten. Um In-Memory-OLTP zu aktivieren, müssen wir eine speicheroptimierte Dateigruppe erstellen.
- FileStream :File-Stream-Dateigruppe enthält File-Stream-Daten wie Bilder, Dokumente, ausführbare Dateien usw. Die primäre Dateigruppe kann keine File-Stream-Daten enthalten, wir müssen eine FileStream-Dateigruppe erstellen. Es enthält die FileStream-Daten.
Demo-Setup
In dieser Demo habe ich „DemoDatabase“ auf der SQL Server 2017-Instanz erstellt. Auf der Datenbank wurden die Registerkarten „Records“ und „PatientData“ angelegt. Der Primärschlüssel „PK_CIDX_Records_ID“ wurde in der Tabelle „Records“ und der gruppierte Index „CIDX_PatientData_ID“ in der Tabelle „PatientData“ erstellt. In dieser Demo werde ich die Tabellen „Records“ und „PatientData“ von der primären Dateigruppe in die sekundäre Dateigruppe verschieben.
Dazu müssen wir Folgendes tun:
- Erstellen Sie eine sekundäre Dateigruppe.
- Datendateien zur sekundären Dateigruppe hinzufügen.
- Verschieben Sie die Tabelle in die sekundäre Dateigruppe, indem Sie den gruppierten Index mit der Primärschlüsseleinschränkung verschieben.
- Verschieben Sie die Tabellen in die sekundäre Dateigruppe, indem Sie den gruppierten Index ohne den Primärschlüssel verschieben.
Sekundäre Dateigruppe erstellen
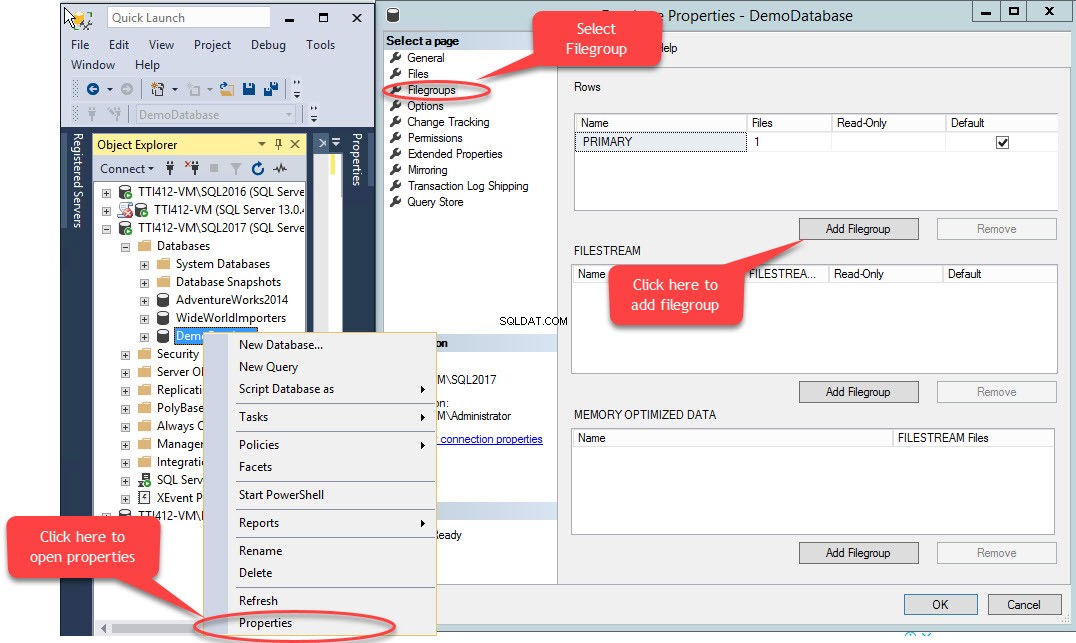
Eine sekundäre Dateigruppe kann mit T-SQL ODER mit dem Assistenten zum Hinzufügen von Dateien in SQL Server Management Studio erstellt werden. Um eine Dateigruppe mit SSMS hinzuzufügen, öffnen Sie SSMS und wählen Sie eine Datenbank aus, in der eine Dateigruppe erstellt werden muss. Klicken Sie mit der rechten Maustaste auf die Datenbank und wählen Sie „Eigenschaften“. “>> „Dateigruppen auswählen “ und klicken Sie auf „Dateigruppe hinzufügen “, wie im folgenden Bild gezeigt:
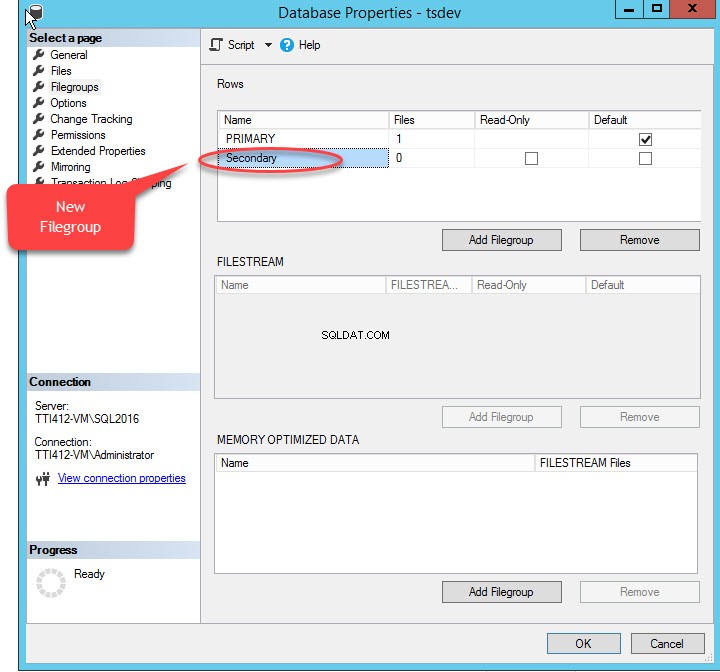
Wenn wir auf „Dateigruppe hinzufügen klicken “, wird eine Zeile in den „Zeilen hinzugefügt " Netz. In den „Zeilen Geben Sie im Raster „Name“ den entsprechenden Dateigruppennamen an " Säule. Die Dateigruppe ist weder schreibgeschützt noch standardmäßig; Behalten Sie daher den Schreibschutz bei und Standard Kontrollkästchen für neue Dateigruppe deaktiviert. Siehe folgendes Bild:
Klicken Sie auf OK, um das Dialogfeld zu schließen.
Führen Sie das folgende Skript aus, um eine Dateigruppe mit einem T-SQL-Skript zu erstellen.
USE [master] GO ALTER DATABASE [DemoDatabase] ADD FILEGROUP [Secondary ] GO
Hinzufügen von Dateien zur Dateigruppe
Um Dateien in einer Dateigruppe hinzuzufügen, öffnen Sie die Datenbankeigenschaften, wählen Sie „Dateien“ und klicken Sie auf „Hinzufügen“. Wie im folgenden Bild gezeigt:
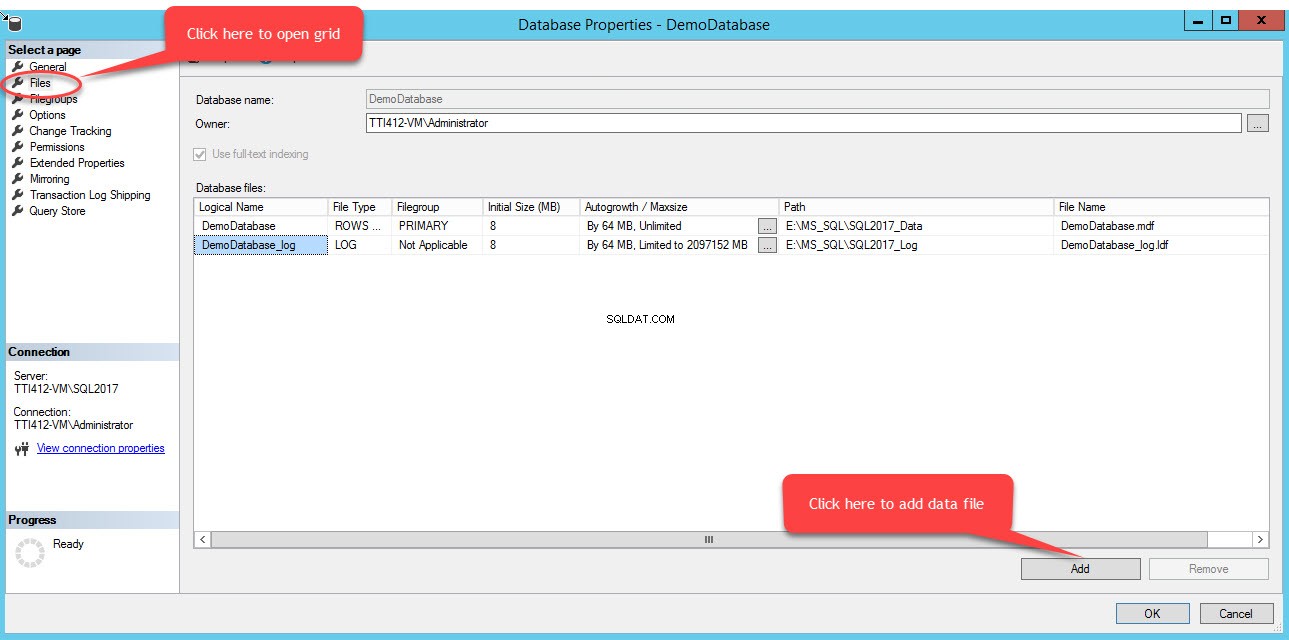
In den Datenbankdateien wird eine leere Zeile hinzugefügt Rasteransicht. Geben Sie in der Rasteransicht unter Logischer Name den entsprechenden logischen Namen an Spalte, wählen Sie Zeilendaten aus aus dem Dateityp Wählen Sie im Dropdown-Feld sekundär aus aus der Dateigruppe Drop-down-Feld legen Sie die Anfangsgröße der Datei in Anfangsgröße fest Spalten, legen Sie die Parameter für automatisches Wachstum und maximale Größe in Autogrowth/Maxsize fest Geben Sie in der Spalte Pfad den physischen Speicherort der sekundären Datendatei an Spalte und geben Sie den entsprechenden Dateinamen in Dateiname ein Säule. Siehe folgendes Bild:
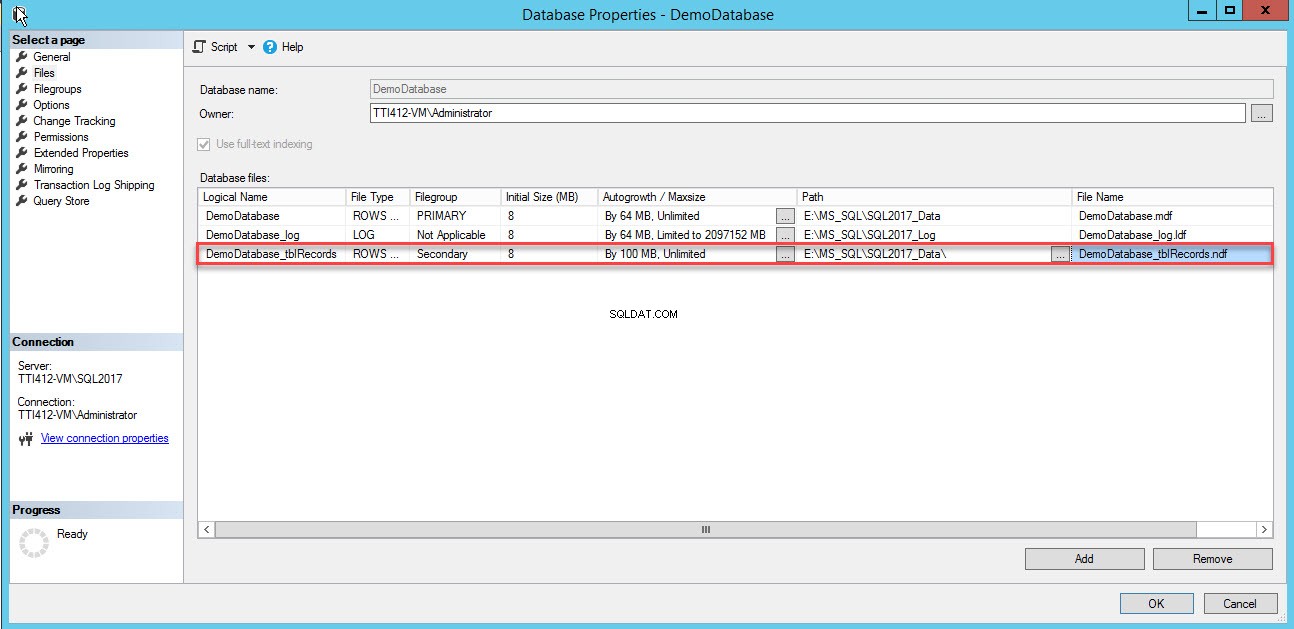
Verwenden Sie das folgende T-SQL-Skript, um eine sekundäre Datendatei zu erstellen.
USE [master] GO ALTER DATABASE [DemoDatabase] ADD FILE ( NAME = N'DemoDatabase_tblRecords', FILENAME = N'E:\MS_SQL\SQL2017_Data\DemoDatabase_tblRecords.ndf' , SIZE = 8192KB , FILEGROWTH = 102400KB ) TO FILEGROUP [Secondary] GO
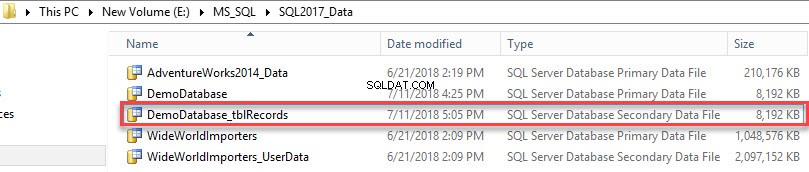
Die sekundäre Datendatei wurde erstellt. Siehe folgendes Bild:
Führen Sie die folgende Abfrage aus, um eine Liste der in der Datenbank erstellten Dateigruppen anzuzeigen.
use DemoDatabase go select a.Name as 'File group Name', type_desc as 'Filegroup Type', case when is_default=1 then 'Yes' else 'No' end as 'Is filegroup default?', b.filename as 'File Location', b.name 'Logical Name', Convert(numeric(10,3),Convert(numeric(10,3),(size/128))/1024) as 'File Size in MB' from sys.filegroups a inner join sys.sysfiles b on a.data_space_id=b.groupid
Unten ist eine Ausgabe der Abfrage.

Übertragen einer vorhandenen Tabelle von der primären Dateigruppe in die sekundäre Dateigruppe
Wir können eine vorhandene Tabelle in eine andere Dateigruppe verschieben, indem wir den gruppierten Index in eine andere Dateigruppe verschieben. Wie wir wissen, enthält ein Blattknoten des Clustered-Index tatsächliche Daten; Daher kann das Verschieben von gruppierten Indizes die gesamte Tabelle in eine andere Dateigruppe verschieben. Das Verschieben von Indizes hat eine Einschränkung:Wenn es sich bei dem Index um einen Primärschlüssel oder eine Unique-Einschränkung handelt, können Sie den Index nicht mit SQL Server Management Studio verschieben. Um diese Indizes zu verschieben, müssen wir den Index erstellen verwenden -Anweisung und mit DROP_Existing=ON Option.
Moving Clustered Index with Primary Key Constraint.
Der Primärschlüssel erzwingt eindeutige Werte, erstellen Sie daher den eindeutigen gruppierten Index. Die Schlüsselspalte ist PRN. Um es in der sekundären Dateigruppe zu erstellen, setzen Sie DROP_EXISTING=ON Option und die Dateigruppe sollte sekundär sein. Führen Sie das folgende Skript aus.
USE [DemoDatabas] GO Create Unique Clustered index [PK_CIDX_Records_ID] ON [Records] (ID asc) WITH (DROP_EXISTING=ON) ON [Secondary]
Nachdem der Befehl erfolgreich ausgeführt wurde, überprüfen Sie, ob der Index in der sekundären Dateigruppe erstellt wurde. Klicken Sie dazu mit der rechten Maustaste auf den Speicher Option in den Indexeigenschaften Dialogbox. Erweitern Sie zum Öffnen von Indexeigenschaften die DemoDatabase Datenbank>> erweitern Sie Tabellen>> Erweitern Sie Indizes . Klicken Sie mit der rechten Maustaste auf PK_CIDX_Records_ID , wie im folgenden Bild gezeigt:
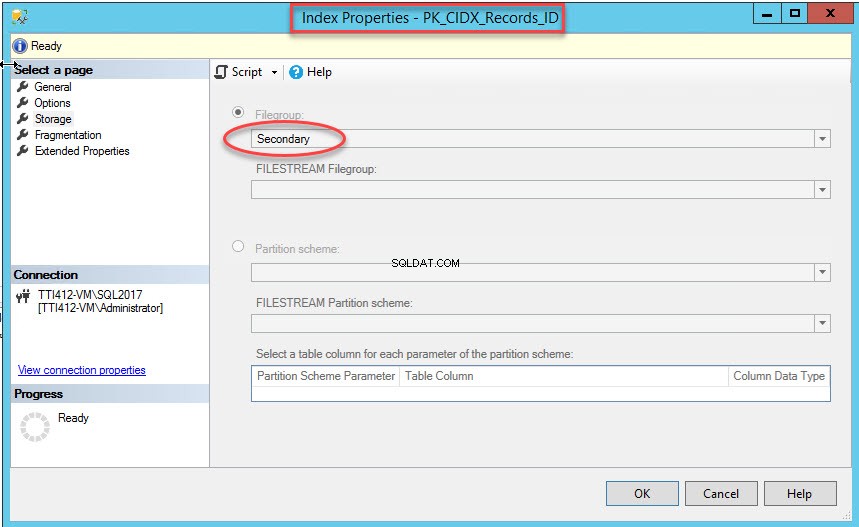
Wie bereits erwähnt, wird die Tabelle in die sekundäre Dateigruppe verschoben, sobald der gruppierte Index in eine sekundäre Dateigruppe verschoben wurde. Klicken Sie zur Überprüfung mit der rechten Maustaste auf Speicher Option in den Tabelleneigenschaften Dialogbox. Erweitern Sie zum Öffnen von Indexeigenschaften die DemoDatabase Datenbank>> erweitern Sie Tabelle s>> Klicken Sie mit der rechten Maustaste auf Datensätze und wählen Sie Speicher aus wie im folgenden Bild gezeigt:
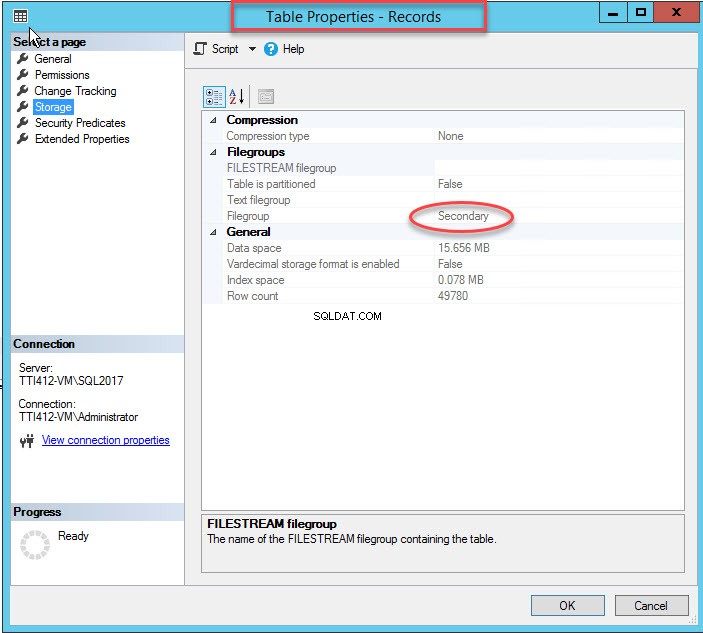
Clustered-Index ohne Primärschlüssel verschieben
Wir können gruppierten Index ohne Primärschlüssel mit SQL Server Management Studio verschieben. Erweitern Sie dazu die DemoDatabase Datenbank>> erweitern Sie Tabellen>> Erweitern Sie Index s>> Klicken Sie mit der rechten Maustaste auf die CIDX_PatientData_ID index und wählen Sie Eigenschaften aus wie im folgenden Bild gezeigt:
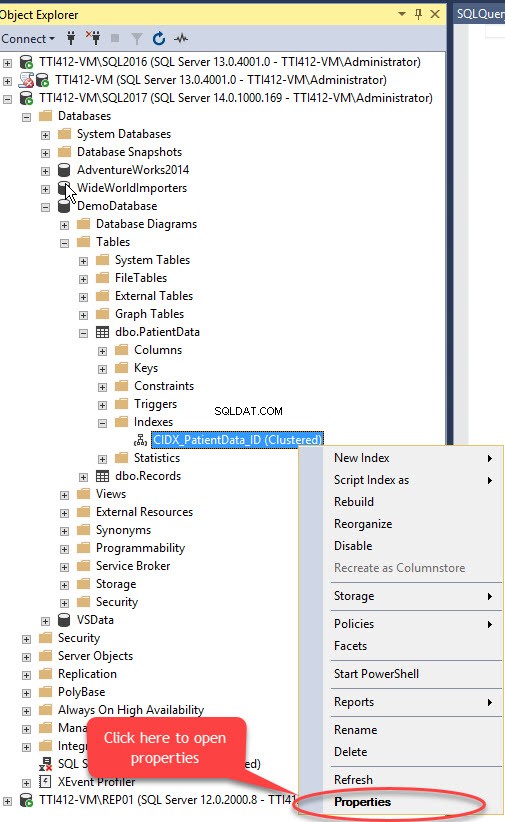
Die Indexeigenschaften Dialogfeld öffnet sich. Wählen Sie im Dialogfeld Speicher aus und klicken Sie im Speicherfenster auf die Dateigruppe Wählen Sie im Dropdown-Feld Sekundär aus Dateigruppe und klicken Sie auf OK, wie im folgenden Bild gezeigt:
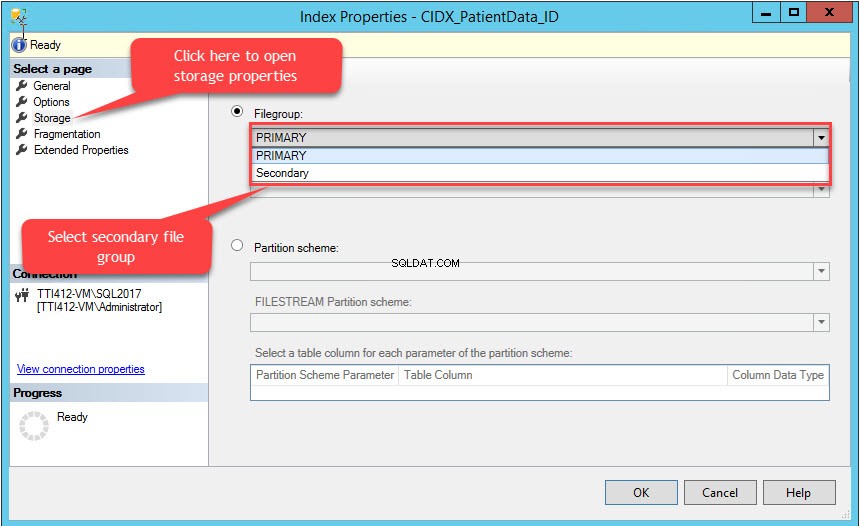
Durch das Ändern der Indexdateigruppe wird der gesamte Index neu erstellt. Sobald der Index neu erstellt wurde, öffnen Sie Tabelleneigenschaften und wählen Sie einen Speicher aus.
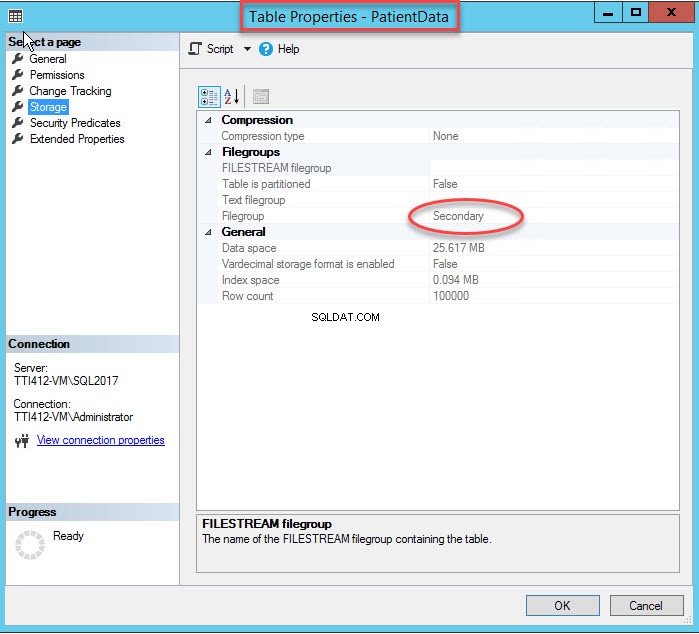
Wie Sie im obigen Bild sehen können, zusammen mit dem Verschieben der CIDX_PatientData_ID gruppierten Index zur sekundären Dateigruppe PatientData Tabelle wird auch in die Sekundäre verschoben Dateigruppe.
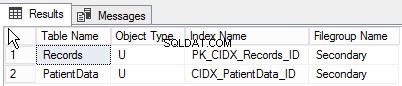
Durch Ausführen der folgenden Abfrage können Sie die Liste der Objekte finden, die in verschiedenen Dateigruppen erstellt wurden:
SELECT obj.[name] as [Table Name],
obj.[type] as [Object Type],
Indx.[name] as [Index Name],
fG.[name] as [Filegroup Name]
FROM sys.indexes INDX
INNER JOIN sys.filegroups FG
ON INDX.data_space_id = fG.data_space_id
INNER JOIN sys.all_objects Obj
ON INDX.[object_id] = obj.[object_id]
WHERE INDX.data_space_id = fG.data_space_id
And obj.type='U'
go Unten ist die Ausgabe der Abfrage:
Zusammenfassung
In diesem Artikel habe ich erklärt
-
- Grundlagen von Datendateien und Dateigruppen.
- So erstellen Sie eine sekundäre Dateigruppe und fügen ihr eine sekundäre Datendatei hinzu.
- Verschieben Sie die Tabelle in die sekundäre Dateigruppe, indem Sie Folgendes verschieben:
- Primärschlüssel.
- Cluster-Index.