Egal auf welcher Seite der Gleichung Sie stehen, manchmal ist es schwierig, eine qualifizierte Person für einen bestimmten Job zu finden. In diesem Beitrag betrachten wir ein Datenmodell, das Personalvermittlern und Personalabteilungen dabei helfen soll, während des Einstellungsprozesses organisiert zu bleiben.
Die meisten von uns waren am Einstellungsprozess beteiligt – meistens als Bewerber. Wir können uns aber auch auf der Einstellungsseite wiederfinden, vielleicht indem wir das technische Wissen des Bewerbers testen. Der Rekrutierungsprozess nimmt eine gewisse Zeit in Anspruch und der Kreis der Bewerber wird immer kleiner, je näher die endgültige Entscheidung rückt. Das Ergebnis sollte die Auswahl der besten Person für den Job sein.
Die Rekrutierung an sich ist ziemlich kompliziert, daher besprechen wir ein ziemlich umfassendes Datenmodell, um alle Aspekte des Prozesses abzudecken. Lehnen Sie sich in Ihrem Stuhl zurück und genießen Sie den heutigen Artikel!
Wie der Rekrutierungsprozess funktioniert
Die meisten Teile des Rekrutierungsprozesses sind allgemein bekannt, aber wir besprechen genau, wie er funktioniert, bevor wir zum Datenmodell übergehen.
-
Bedarf erkennen
Dies ist ein absolutes Muss im Einstellungsprozess; Es findet kein Verfahren statt, wenn die Geschäftsleitung nicht weiß, dass ein neuer Mitarbeiter eingestellt werden muss. Dieser Bedarf kann das Ergebnis der Gründung eines neuen Unternehmens, des Wachstums in einem bestehenden Unternehmen oder des Ausscheidens eines derzeitigen Mitarbeiters sein.
Sofern ein Unternehmen keine fest definierten Positionen hat (z. B. Banken), ist es nicht immer einfach zu bestimmen, wann ein neuer Mitarbeiter eingestellt werden sollte. Gespräche mit Mitarbeitern und viele Überstunden können einen neuen Mitarbeiter anspornen. Interne oder externe Vorschriften können auch vorschreiben, dass bestimmte Positionen nur an Personen mit bestimmten Fähigkeiten und relevanter Berufserfahrung vergeben werden (z. B. interner Revisor).
-
Beschreibung der Position und der erforderlichen Fähigkeiten
Um sich ein Bild von diesem Schritt zu machen, denken Sie an eine wirklich gut geschriebene Stellenbeschreibung. Es enthält:
- Eine Liste aller Aufgaben im Zusammenhang mit dem Job
- Mindestqualifikationen für Bildung und Berufserfahrung
- Spezifische Fähigkeiten, die für berufliche Funktionen unerlässlich sind
- Zusätzliche oder bevorzugte Fähigkeiten
- Eine Zusammenfassung dessen, was der Arbeitgeber vom Bewerber erwartet und was der Bewerber von dieser Stelle erwarten kann
- Eine Gehaltsspanne und vielleicht ein Leistungspaket
Diese Informationen sind für Personalvermittler und Bewerber gleichermaßen wichtig. Es macht keinen Sinn, zehn Bewerber zum Auswahlverfahren einzuladen, wenn keiner von ihnen mit dem finanziellen Angebot zufrieden ist. Und je detaillierter die Stellenbeschreibung, desto einfacher ist es, qualifizierte Bewerber zu gewinnen.
-
Definieren, wer den Prozess verwaltet und wann jede Aufgabe ausgeführt werden soll
Der nächste Schritt besteht darin, bestimmte Daten zu definieren, an denen jeder Teil des Prozesses stattfinden wird. Außerdem können Unternehmen jedem Schritt Mitarbeiter zuweisen. Wenn das Unternehmen über eine Personalabteilung verfügt, wird diese wahrscheinlich jeden Teil des Rekrutierungsprozesses verwalten, obwohl andere Mitarbeiter bei Bedarf ihr spezifisches Wissen einbringen können (z. B. wenn wir einen IT-Spezialisten einstellen, sollte der Leiter der IT-Abteilung die Kandidaten bewerten ' technische Fähigkeiten).
Wenn es keine Personalabteilung gibt, können wir damit rechnen, dass Führungskräfte den Prozess leiten. In kleinen und mittelständischen Unternehmen ist dies nicht nur notwendig, sondern erwünscht.
-
Veröffentlichen des Jobs
Jetzt sind wir bereit, eine Stellenbeschreibung auf unserer Website, auf Jobbörsen oder Aggregatoren oder in einer Zeitung zu veröffentlichen. Die Stellenausschreibung sollte die in Schritt 2 aufgeführten Aufzählungspunkte enthalten. Dies hilft potenziellen Kandidaten bei der Entscheidung, ob sie sich auf die Stelle bewerben möchten. Es ist wichtig, dass die Stellenbeschreibung genau ist; Wir alle haben unsere Zeit damit verschwendet, ein Vorstellungsgespräch für einen Job zu führen, der nicht seiner Beschreibung oder unseren Erwartungen entsprach.
-
Kandidaten auswählen, testen und interviewen
Nach Ablauf der Bewerbungsfrist werden die Bewerber mit den relevantesten Fähigkeiten und Erfahrungen zu einer ersten Bewertungsphase (in der Regel ein Vorstellungsgespräch oder Test) eingeladen. Die anderen Bewerber werden darüber informiert, dass sie nicht für die Stelle ausgewählt wurden. Ein großes Unternehmen sollte eine vordefinierte Mindestanzahl an Kandidaten zur Erstbewertung einladen. Das spart sowohl den Bewerbern als auch dem Unternehmen Zeit.
Kleine und mittlere Unternehmen könnten sich dafür entscheiden, den Prozess fortzusetzen, bis sie die beste Lösung gefunden haben. In solchen Fällen bleibt der Bewerbungszeitraum offen, bis der richtige Kandidat gefunden ist, und alle anderen Termine werden im Laufe der Zeit festgelegt.
Der Interview- und Testprozess variiert je nach Unternehmensgröße und Organisation. In großen Unternehmen mit Personalabteilungen wird es wahrscheinlich eine Reihe von Tests geben, um die beruflichen Fähigkeiten der Bewerber zu überprüfen. Andere Tests können psychologische und Persönlichkeitsmerkmale messen, um die Übereinstimmung zwischen Bewerber und Job, Bewerber und Unternehmen oder sogar die geistige Gesundheit des Bewerbers zu bestimmen. ☺
Diese Tests werden normalerweise in mehrere Schritte unterteilt, und jeder Schritt verringert die Anzahl der Bewerber.
-
Das letzte Interview
Dieser Schritt wird wahrscheinlich ein Interview mit den wenigen Top-Bewerbern sein. Es ist der wichtigste Schritt im Prozess, denn die Bewerber können für sich sprechen, ihre Kompetenz und Persönlichkeit unter Beweis stellen und feststellen, ob das Unternehmen und die Stelle zu ihnen passen. Nach diesem Schritt erhält der beste Bewerber ein Angebot. Wenn sie zustimmen, ist das Einstellungsverfahren für diese Position beendet. Lehnt der Bewerber das Stellenangebot ab, unterbreitet das Unternehmen seiner nächsten Wahl ein Angebot.
-
Gibt es Unterschiede im Rekrutierungsprozess für kleine, mittlere und große Unternehmen? Wie werden wir sie in unserem Modell lösen?
Es wird gewisse Unterschiede in den Rekrutierungsprozessen von kleinen, mittleren und großen Unternehmen geben. Außerdem variiert der Prozess je nach zu besetzender Stelle. Überlegen Sie, wie unterschiedlich die erforderlichen Fähigkeiten und Erfahrungen für einen Content Manager, einen Ornithologen und einen Kreuzfahrtkapitän sind. Bei einigen Jobs gibt es mehr Tests und Vorstellungsgespräche, bei anderen nur wenige. Aber am Ende kommt es darauf an, die richtigen Antworten zu bekommen und die Bewerber einzuordnen.
In diesem Modell behandle ich alle Tests und Interviews gleich. Wir speichern die Antworten jedes Bewerbers, verknüpfen sie mit der relevanten Frage und speichern die Punktzahl des Bewerbers für jeden Schritt des Prozesses.
-
Wer kann dieses Datenmodell verwenden?
Dieses Modell ist sehr spezifisch und sollte nur für den Einstellungsprozess verwendet werden. Aber es ist nicht auf Personalabteilungen beschränkt; Sie könnten dieses Modell auch verwenden, um einen professionellen Personalvermittlungsdienst zu betreiben.
-
Das Datenmodell
Das Datenmodell besteht aus fünf Hauptthemenbereichen:
JobsApplicants, Recruiters and DocumentsApplicationsTest detailsApplication tests
Ich beschreibe jeden Themenbereich separat in der gleichen Reihenfolge, in der sie aufgelistet sind.
Abschnitt 1:Jobs
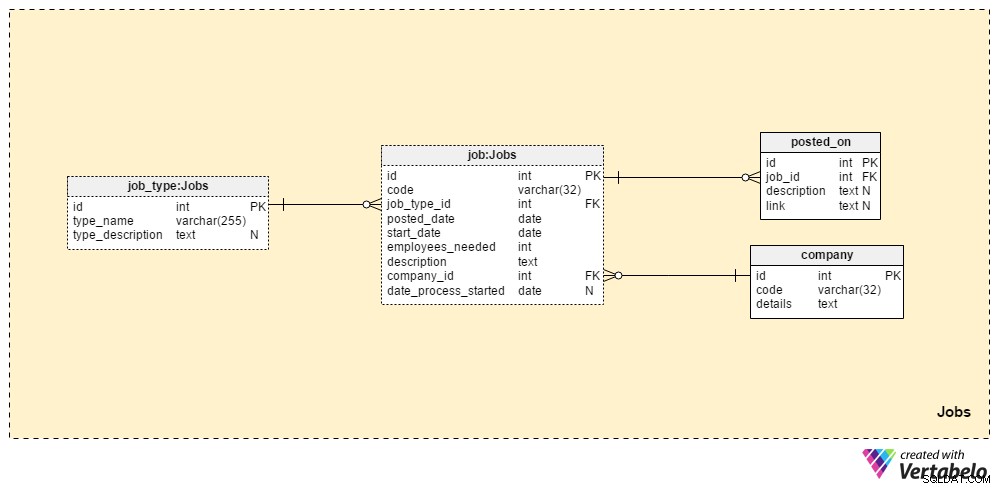
Die Jobs Abschnitt speichert alle Details für alle Positionen, die wir jemals veröffentlicht haben. Die beiden Wörterbuchtabellen, die company Tabelle und den job_type Tabelle, sind Teil der Ersteinrichtung. Die verbleibenden zwei Tabellen, job und posted_on , enthalten „echte“ Daten im Zusammenhang mit Stellenausschreibungen.
Der job_type Das Wörterbuch enthält eine Liste verschiedener und EINZIGARTIGER Auftragstypen. Wir können Werte wie „leitender Datenbankadministrator“ erwarten oder „IT-Journalist“ im type_name gespeichert werden Attribut. Die type_description -Attribut kann eine detailliertere Beschreibung des Jobs speichern.
Das company Wörterbuch enthält eine Liste aller Unternehmen, mit denen wir zusammenarbeiten. Wenn wir Mitarbeiter nur für unser Unternehmen einstellen, enthält dieses Wörterbuch nur unseren Firmennamen. Wenn wir eine Personalagentur sind, werden die Namen aller Unternehmen gespeichert, die uns eingestellt haben.
Eine Liste aller Stellenangebote, die wir jemals ausgeschrieben haben, ist in der Tabelle „Job“ gespeichert. Die Attribute in dieser Tabelle sind:
code– Unsere interne EINZIGARTIGE ID, die verwendet wird, um einen Job zu kennzeichnen.job_type_id– Verweist auf den zugehörigen Jobtyp.posted_date– Das Datum, an dem diese Stellenausschreibung veröffentlicht wurde.start_date– Das voraussichtliche Startdatum (erster Arbeitstag) für diesen Job.employees_needed– Die Anzahl der Mitarbeiter, die wir während dieses Rekrutierungsprozesses einstellen möchten. Meistens wird dieser den Wert „1“ haben, aber in manchen Fällen – z.B. bei der Gründung eines neuen Unternehmens oder dem Aufbau einer neuen Abteilung – wir können mit größeren Werten rechnen.description– Eine detaillierte Beschreibung dieser Position. Hier listen wir alle erforderlichen, bevorzugten und gewünschten beruflichen Fähigkeiten auf.company_id– Verweist auf die ID des Unternehmens, das uns beauftragt hat. Wenn wir eine Personalvermittlung sind, bezieht sich dies auf einen Unternehmensnamen, der imcompanyTisch. Andernfalls handelt es sich um unsere eigene Firmen-ID.date_process_started– Das Startdatum des Rekrutierungsprozesses. Dies könnte NULL sein, wenn wir zukünftige Schritte und Aktionen in Bezug auf diesen Job definieren müssen.
Die letzte Tabelle in diesem Themenbereich ist der posted_on Tisch. Für jede job_id speichern wir einen link zur Stellenausschreibung und der dazugehörigen description . Wir könnten diese Daten verwenden, um zu erfahren, wo die Bewerber unsere Stellenausschreibungen finden.
Abschnitt 2:Bewerber, Anwerber und Dokumente
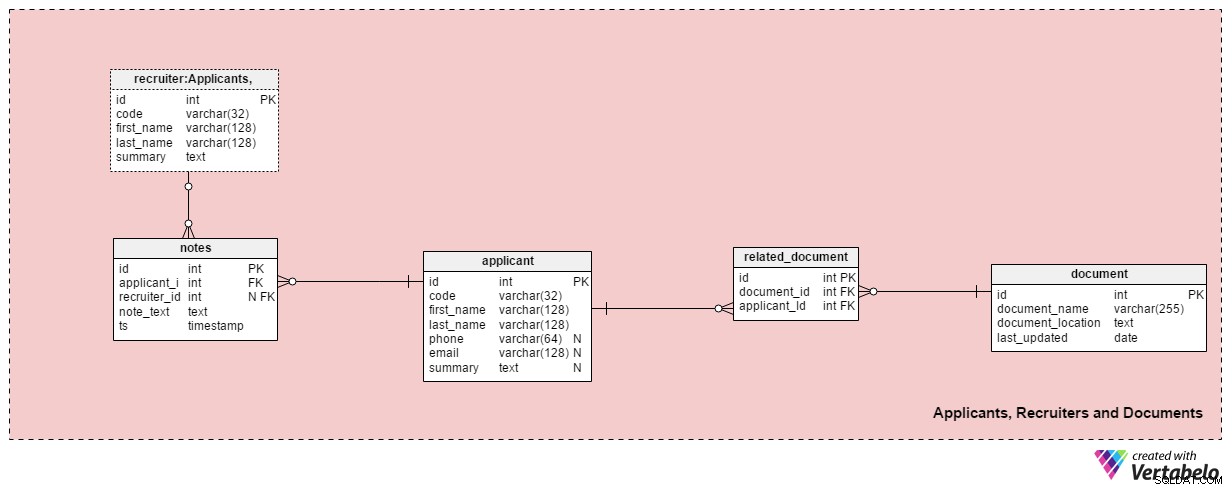
Dieser Themenbereich enthält alle Tabellen, die zum Speichern von Informationen über Personalvermittler, Bewerber und die zugehörigen Dokumente erforderlich sind.
Der applicant Tabelle listet alle Bewerber auf, mit denen wir jemals Kontakt hatten. Jeder Bewerber ist in unserem System EINZIGARTIG mit einem „Code“ definiert. Außerdem speichern wir von jedem Bewerber den Vor- und Nachnamen, phone Nummer, email Adresse und deren summary . Dieser Tisch kann an spezifische Bedürfnisse angepasst werden, z. Hinzufügen zusätzlicher Telefonnummern, E-Mail-Adressen oder physischer Adressen.
Wir werden Bewerber mit verfügbaren Dokumenten in Verbindung bringen. Im document Tisch. Für jedes Dokument speichern wir seinen Namen im System, seinen Speicherort und den Zeitpunkt der letzten Aktualisierung.
Wir verknüpfen Bewerber mit Dokumenten unter Verwendung des related_document Tisch. Es enthält nur zwei Fremdschlüssel, die die document_id bilden – applicant_id EINZIGARTIGES Paar.
Der recruiter Tabelle listet die Mitarbeiter auf, die einer Bewerbung zugeordnet werden konnten oder die Notizen zu einem Bewerber erfassen. Jeder Anwerber wird EINZIGARTIG durch seinen oder seinen code definiert . Wir speichern nur grundlegende Details wie first_name , last_name und die summary des Anwerbers .
Die letzte Tabelle in diesem Themenbereich sind die notes Tisch. Hier speichern wir alle Notizen zu einem Bewerber. Wir könnten Notizen wie „Bewerber hat Termin verpasst“ hinterlegen oder "Bewerber hat beim ersten Vorstellungsgespräch super abgeschnitten" . Für jede Notiz speichern wir die ID des Personalvermittlers, der diese Notiz gemacht hat, die ID des zugehörigen Bewerbers, den note_text , und den Zeitstempel, wann die Notiz erstellt wurde.
Abschnitt 3:Testdetails
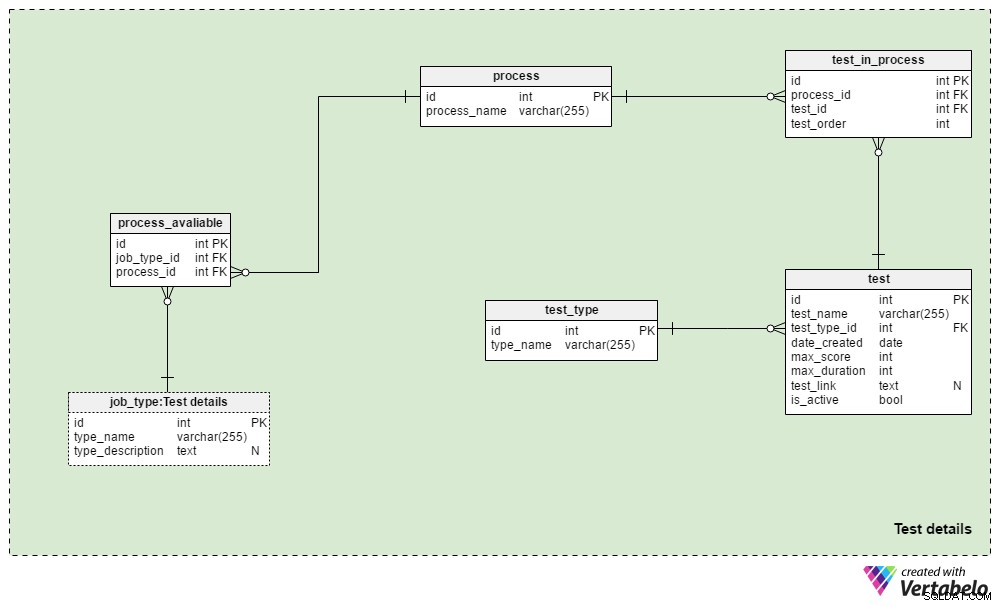
Die Test details Themenbereich enthält die Tabellen, die verwendet werden, um Rekrutierungsprozesse und die Tests zu definieren, die während dieser Prozesse verwendet werden. Grundsätzlich verwenden wir immer den gleichen Auswahlprozess für den gleichen Stellentyp:Änderungen werden nur dann vorgenommen, wenn die geschäftlichen Umstände dies erfordern. Wir könnten für jeden Jobtyp ein paar verschiedene Prozesse verwenden, und wir werden mit ziemlicher Sicherheit denselben Prozess für verschiedene Jobtypen verwenden.
Der process table ist ein einfaches Wörterbuch, das nur einen EINZIGARTIGEN process_name enthält Attribut. Es listet alle Rekrutierungsprozesse auf, die wir jemals verwendet haben und derzeit verwenden.
Wir werden Prozesse mit verschiedenen Jobtypen in Beziehung setzen. Wir speichern diese Beziehungen im process_available Tisch. Seine einzigen Attribute sind das UNIQUE-Paar job_type_id – process_id . Wenn für einen Stellentyp mehrere Prozesse verfügbar sind, kann der Personalbeschaffer einen auswählen.
Der test_in_process Tabelle wird verwendet, um die Reihenfolge der Tests während dieses Prozesses zu definieren. Die Attribute in dieser Tabelle sind:
process_idundtest_id– Verweist auf den zugehörigen Prozess und Test.test_order– Die Ordnungszahl dieses Tests oder Schritts im Prozess. Zusammen mitprocess_id, bildet dies den UNIQUE-Schlüssel der Tabelle. Wir können während des Prozesses nur einen Schritt nach dem anderen machen.
Der test Die Tabelle listet alle Tests auf, die derzeit und zuvor im Einstellungsprozess verwendet wurden. Wir behandeln auch CV-Überprüfungen und Vorstellungsgespräche als Tests. Obwohl sie keine definierten Fragen und Antworten benötigen, sind sie Teil einer Bewertung. Für jeden Test speichern wir:
test_name– Eine EINDEUTIGE Bezeichnung für jeden Test.test_type_id– Referenziert dentest_typeWörterbuch.date_created– Das Datum, an dem wir diesen Test in unserem System erstellt haben.max_score– Die maximal erreichbare Punktzahl für diesen Test. Dieser Wert ist die Summe aller richtigen Antworten in diesem Test oder die höchste Note, die Personalvermittler einem Lebenslauf oder Vorstellungsgespräch geben könnten.max_duration– Wie lange (in Minuten) der Bewerber den Test absolvieren muss.test_link– Enthält einen Link zum Testort. Dieser Wert könnte NULL sein, wenn wir im Prozess keinen Test verwenden.is_active– Gibt an, ob wir diesen Test derzeit verwenden.
Wir haben bereits den test_type Wörterbuch. Es enthält alle EINZIGARTIGEN Testnamen nach Format, z. "Lebenslaufüberprüfung" , "Online-Fähigkeitstest" , "Papier-Skill-Test" und "Interview" .
Dieses Modell enthält nicht die Struktur, die zum Speichern von Testfragen und -antworten erforderlich ist. Vielmehr speichert es einen Link zu den Orten, die diese Informationen enthalten. Dasselbe Design wird in den Applications verwendet Fachbereich.
Abschnitt 4:Bewerbungen
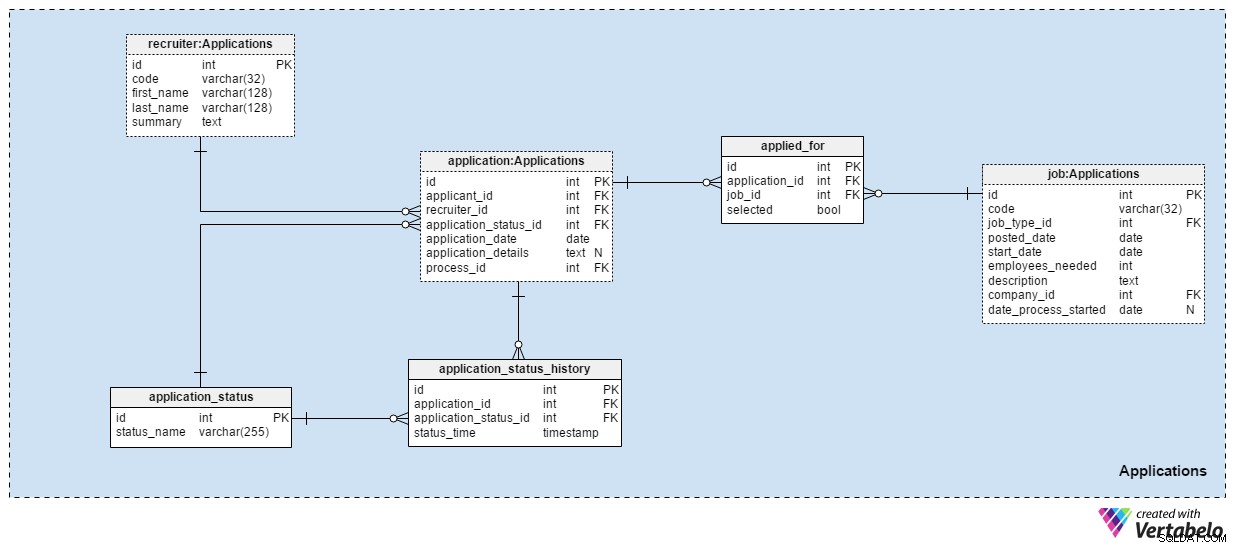
Die Applications Fachgebiet ist das wohl wichtigste in diesem Datenmodell. Alle anderen bisher genannten Fachgebiete beschrieben Anwendungen. Dieser speichert die echten Dinge.
Jede Bewerbung, die wir jemals erhalten haben, wird im application Tisch. Für jede Bewerbung speichern wir die zugehörige Bewerber-ID, die Recruiter-ID und einen Hinweis auf den aktuellen Status dieser Bewerbung. Wir aktualisieren diesen Status gleichzeitig mit einem neuen Eintrag in application_status_history Tisch. Das application_date -Attribut wird verwendet, um das relevante Datum zu speichern, während alle zusätzlichen Details im Textformat gespeichert werden. Die process_id -Attribut speichert einen Verweis auf den für diese Anwendung ausgewählten Prozess.
Der Status der Bewerbungen ändert sich im Laufe der Zeit. Eine Liste aller Bewerbungsstatus wird im application_status Wörterbuch. Das einzige Attribut ist status_name und es kann nur EINZIGARTIGE Werte enthalten. Zu den erwarteten Werten gehören:"applied" , "Lebenslauf überprüft" , "für den Test ausgewählt" , "nach Prüfung des Lebenslaufs abgelehnt" , "Test bestanden" , "zu einem Vorstellungsgespräch eingeladen" und "vom Bewerber gekündigt" .
Wir speichern alle Bewerbungsstatus im application_status_history Tisch. Diese Tabelle enthält Verweise auf die application Tabelle und den application_status Wörterbuch. Wir speichern auch die genaue status_time wann dieser Status der Bewerbung zugewiesen wurde. Die application_id – status_time Paar bildet den UNIQUE-Schlüssel dieser Tabelle.
In den meisten Fällen bewirbt sich ein Bewerber mit einer Bewerbung nur auf eine Stelle. Es ist möglich, dass sich ein Bewerber auf mehr als eine Stelle bewirbt und wir wählen während des Auswahlverfahrens die für ihn am besten geeignete Rolle aus. Im applied_for Tabelle speichern wir das UNIQUE-Paar application_id – job_id . Wir erfassen auch, ob der mit dieser Bewerbung verbundene Bewerber selected wurde für diese Stelle. Wir können erwarten, dass alle selected Werte werden auf „False“ gesetzt zu Beginn des Auswahlverfahrens und dass wir nur einen pro Jobposition auf „Richtig“ aktualisieren .
Abschnitt 5:Bewerbungstests
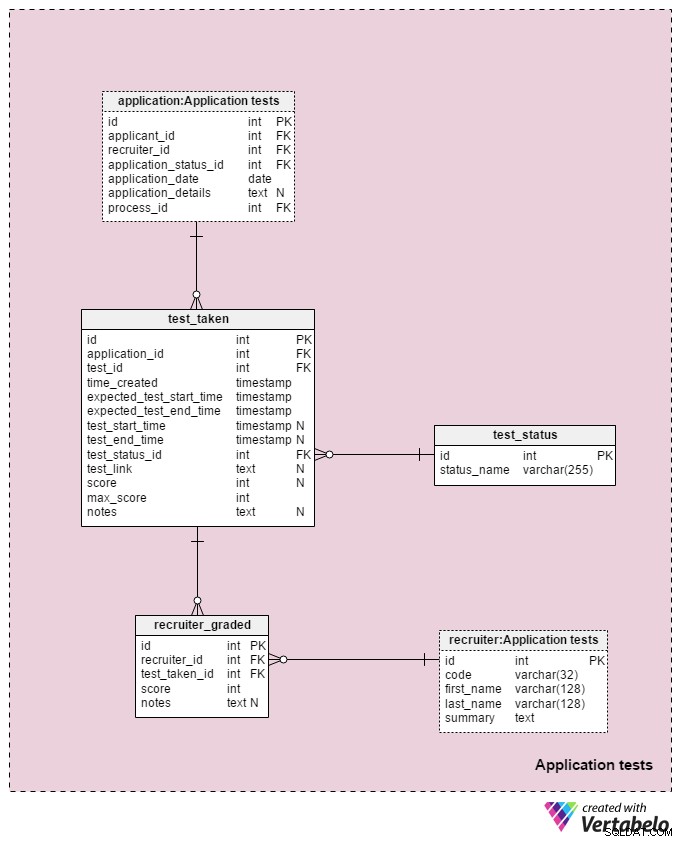
Der letzte Themenbereich in unserem Modell wird verwendet, um die Ergebnisse aller während des Auswahlverfahrens durchgeführten Tests zu speichern. Zwei in diesem Themenbereich verwendete Tabellen sind Kopien aus anderen Themenbereichen:application und recruiter . Sie werden hier verwendet, um das Modell zu vereinfachen.
Alle Details zu jedem Test werden in test_taken Tisch. Diese Tabelle enthält auch alle anderen Schritte im Prozess, die benotet werden könnten, wie z. B. eine Überprüfung des Lebenslaufs. Die Attribute in dieser Tabelle sind:
application_id– Verweist auf dieapplicationTisch. Dies bezieht sich auf einen Test mit dem Bewerber, der diesen Test abgelegt hat.test_id– Verweist auf dentestKatalog. Wir könnten auch auftest_in_processTabelle hier, die uns weitere Informationen über den durchgeführten Test liefern würde. Ich habe mich dagegen entschieden, weil uns diese Struktur mehr Flexibilität bietet. (z. B. wenn wir Bewerbern ermöglichen möchten, einen Test zweimal oder außerhalb der üblichen Zeiten zu absolvieren).time_created– Die tatsächliche Zeit, zu der wir diesen Test in unser System eingefügt haben.expected_test_start_timeundexpected_test_end_time– Die Start- und Endzeiten, wie mit dem Antragsteller besprochen. Wir könnten diese Werte ändern, falls der Bewerber oder der Personalvermittler den Test verschieben muss.test_start_timeundtest_end_time–Die tatsächlichen Start- und Endzeiten für den Test. Diese enthalten NULL-Werte, wenn der Test erstellt wird; Die Werte werden aktualisiert, wenn der Bewerber diesen Test beginnt und beendet.test_status_id– Referenziert dentest_statusWörterbuch.test_link– Links zum Test mit den Antworten des Bewerbers. Es wird aktualisiert, wenn der Bewerber den Test einreicht.score– Das Ergebnis des Bewerbers in diesem Test. Diese wird entweder manuell von einem Personalbeschaffer (z. B. für eine CV-Überprüfung) oder automatisch (die Summe aller Testitem-Bewertungen) ermittelt. Es könnte auch einen NULL-Wert für Tests enthalten, die nicht auf einer vordefinierten Skala bewertet oder benotet werden. Außerdem kann ein geplanter, aber noch nicht abgeschlossener Test einen NULL-Wert haben.max_score– Die maximal erreichbare Punktzahl des Tests. Dies ist derselbe wie der intestgespeicherte Wert .“max_scoreAttribut. Ich möchte diesen Wert beibehalten, da der Personalvermittler den Test während der Durchführung ändern und somit die maximal erreichbare Punktzahl ändern könnte.notes– Alle zusätzlichen Notizen oder Bemerkungen, die von Personalvermittlern zu diesem bestimmten Test eingegeben wurden.
Die Kombination aus test_id – application_id – expected_test_start_time Attribute bildet den UNIQUE-Schlüssel dieser Tabelle. Bevor wir eine neue Testsitzung hinzufügen, sollten wir dennoch prüfen, ob sich die Testintervalle für den zugehörigen Bewerber und alle zugehörigen Recruiter überschneiden.
Der test_status Das Wörterbuch enthält eine Liste aller EINZIGARTIGEN status_name die einem Test zugeordnet werden könnten. Einige erwartete Werte sind:"nicht gestartet" , "in Bearbeitung" , "erfolgreich abgeschlossen" , "nicht erfolgreich abgeschlossen" , "verschoben" , "storniert" und "Bewerber abgebrochen" .
Die letzte Tabelle in unserem Modell ist recruiter_graded Tabelle, in der alle Noten gespeichert sind, die Personalvermittler bei der Benotung jedes Tests vergeben haben. Daher speichern wir Verweise auf den recruiter und test_taken Tische. Wir speichern auch die score erreicht sowie alle notes . Diese Informationen sind sehr wichtig, insbesondere wenn wir Tests manuell benoten (z. B. für Lebenslaufüberprüfungen und Vorstellungsgespräche).
Heute haben wir ein Datenmodell besprochen, das nahezu jede Situation im Auswahl- und Rekrutierungsprozess abdecken kann – einschließlich ungewöhnlicher Ausnahmen.
Die meisten von uns haben einige Erfahrung mit diesem Thema. Bitte teilen Sie Ihre Erfahrungen, während Sie in der Rolle des Personalvermittlers oder auf der anderen Seite des Schreibtisches waren. Deckt dieses Modell die Situationen ab, mit denen Sie konfrontiert waren? Falls nein, welche Änderungen würden Sie vorschlagen?