Haben Sie Schwierigkeiten mit SQL UNION? Es passiert, wenn die Ergebnisse, die Sie kombiniert haben, Ihren SQL Server zum Stillstand bringen. Oder ein Bericht, der zuvor funktioniert hat, zeigt ein Kästchen mit einem roten X-Symbol an. Ein „Operand type clash“-Fehler tritt auf und zeigt auf eine Zeile mit UNION. Das „Feuer“ beginnt. Kommt Ihnen das bekannt vor?
Egal, ob Sie SQL UNION schon eine Weile verwenden oder gerade erst damit anfangen, ein Spickzettel oder ein kurzer Satz von Notizen werden nicht schaden. Das erfährst du heute in diesem Beitrag. Diese Liste bietet 10 nützliche Tipps für Anfänger und Veteranen. Außerdem wird es Beispiele und einige fortgeschrittene Diskussionen geben.

[sendpulse-form id=”11900″]
Aber bevor wir zum ersten Punkt kommen, klären wir die Begriffe.
UNION ist einer der Mengenoperatoren in SQL, der zwei oder mehr Ergebnismengen kombiniert. Es kann nützlich sein, wenn Sie Namen, monatliche Statistiken und mehr aus verschiedenen Quellen kombinieren müssen. Und ob Sie SQL Server, MySQL oder Oracle verwenden, der Zweck, das Verhalten und die Syntax sind sehr ähnlich. Aber wie funktioniert es?
1. Verwenden Sie SQL UNION, um Unique zu kombinieren Aufzeichnungen
Die Verwendung von UNION zum Kombinieren von Ergebnismengen entfernt Duplikate.
Warum ist das wichtig?
Meistens möchten Sie keine Ergebnisse mit Duplikaten. Ein Bericht mit doppelten Zeilen verschwendet Tinte und Papier in Ausdrucken. Und das wird Ihre Benutzer verärgern.
Verwendung
Sie kombinieren die Ergebnisse der SELECT-Anweisungen mit UNION dazwischen.
Bevor wir mit dem Beispiel beginnen, bereiten wir unsere Beispieldaten vor.
USE AdventureWorks
GO
IF OBJECT_ID ('dbo.Customer1', 'U') IS NOT NULL
DROP TABLE dbo.Customer1;
GO
IF OBJECT_ID ('dbo.Customer2', 'U') IS NOT NULL
DROP TABLE dbo.Customer2;
GO
IF OBJECT_ID ('dbo.Customer3', 'U') IS NOT NULL
DROP TABLE dbo.Customer3;
GO
-- Get 3 customer names with Andersen lastname
SELECT TOP 3
p.LastName
, p.FirstName
, c.AccountNumber
INTO dbo.Customer1
FROM Person.Person AS p
INNER JOIN Sales.Customer c
ON c.PersonID = p.BusinessEntityID
WHERE p.LastName = 'Andersen';
-- Make sure we have a duplicate in another table
SELECT
c.LastName
,c.FirstName
,c.AccountNumber
INTO dbo.Customer2
FROM Customer1 c
-- Seems it's not enough. Let's have a 3rd copy
SELECT
c.LastName
,c.FirstName
,c.AccountNumber
INTO dbo.Customer3
FROM Customer1 c
Wir verwenden die vom obigen Code generierten Daten bis zum dritten Tipp. Nun, da wir bereit sind, sehen Sie unten das Beispiel:
SELECT
c.LastName
,c.FirstName
,c.AccountNumber
FROM dbo.Customer1 c
UNION
SELECT
c2.LastName
,c2.FirstName
,c2.AccountNumber
FROM dbo.Customer2 c2
UNION
SELECT
c3.LastName
,c3.FirstName
,c3.AccountNumber
FROM dbo.Customer3 c3
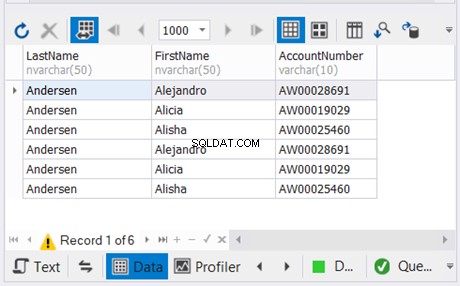
Wir haben 3 Kopien derselben Kundennamen und gehen davon aus, dass eindeutige Datensätze verschwinden werden. Sehen Sie sich die Ergebnisse an:
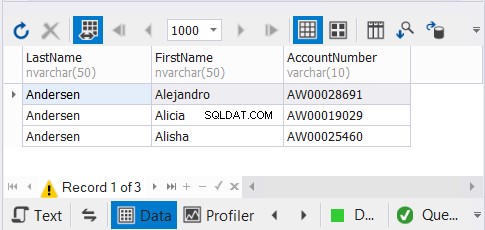
Die dbForge Studio for SQL Server-Lösung, die wir für unsere Beispiele verwenden, zeigt nur 3 Datensätze. Es hätte 9 sein können. Durch die Anwendung von UNION haben wir die Duplikate entfernt.
Wie funktioniert es?
Das Plan-Diagramm in dbForge Studio zeigt, wie SQL Server das in Abbildung 1 gezeigte Ergebnis erzeugt. Sehen Sie sich das an:
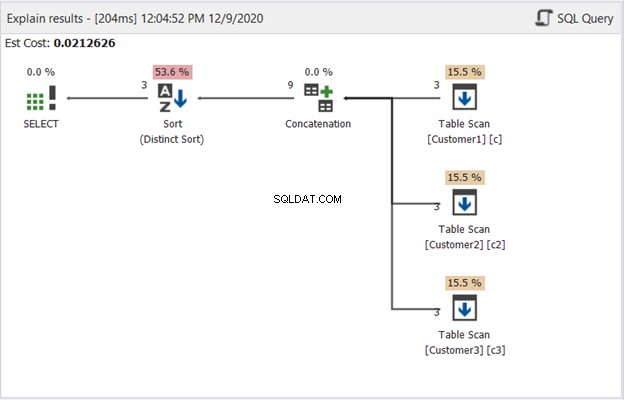
Um Abbildung 2 zu interpretieren, beginnen Sie von rechts nach links:
- Wir haben 3 Datensätze von jedem Table Scan-Operator abgerufen. Das sind die 3 SELECT-Anweisungen aus dem obigen Beispiel. Jede davon ausgehende Zeile zeigt „3“, was jeweils 3 Datensätze bedeutet.
- Der Concatenation-Operator führt das Kombinieren von Ergebnissen durch. Die davon ausgehende Zeile zeigt „9“ – eine Ausgabe von 9 Datensätzen aus der Kombination der Ergebnisse.
- Der Distinct Sort-Operator stellt sicher, dass eindeutige Datensätze die endgültige Ausgabe sind. Die davon ausgehende Linie zeigt „3“, was mit der Anzahl der Datensätze in Abbildung 1 übereinstimmt.
Das obige Diagramm zeigt, wie UNION von SQL Server verarbeitet wird. Die Anzahl und Art der verwendeten Operatoren kann je nach Abfrage und zugrunde liegender Datenquelle unterschiedlich sein. Aber zusammenfassend funktioniert eine UNION wie folgt:
- Die Ergebnisse jeder SELECT-Anweisung abrufen.
- Kombinieren Sie die Ergebnisse mit einem Verkettungsoperator.
- Wenn die kombinierten Ergebnisse nicht eindeutig sind, filtert SQL Server die Duplikate heraus.
Alle erfolgreichen Beispiele mit UNION folgen diesen grundlegenden Schritten.
2. Verwenden Sie SQL UNION ALL, um Datensätze mit Duplikaten zu kombinieren
Die Verwendung von UNION ALL kombiniert Ergebnismengen mit eingeschlossenen Duplikaten.
Warum ist das wichtig?
Möglicherweise möchten Sie Ergebnissätze kombinieren und dann die Datensätze mit Duplikaten zur späteren Verarbeitung abrufen. Diese Aufgabe ist nützlich, um Ihre Daten zu bereinigen.
Verwendung
Sie kombinieren die Ergebnisse der SELECT-Anweisungen mit UNION ALL dazwischen. Sehen Sie sich das Beispiel an:
SELECT
c.LastName
,c.FirstName
,c.AccountNumber
FROM dbo.Customer1 c
UNION ALL
SELECT
c2.LastName
,c2.FirstName
,c2.AccountNumber
FROM dbo.Customer2 c2
UNION ALL
SELECT
c3.LastName
,c3.FirstName
,c3.AccountNumber
FROM dbo.Customer3 c3
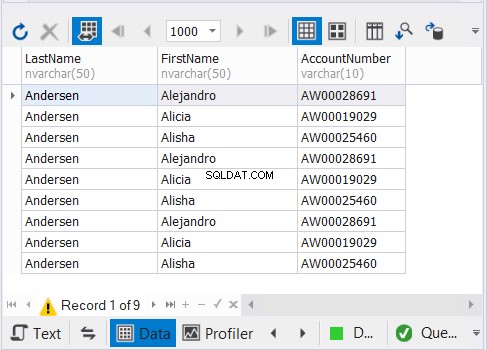
Der obige Code gibt 9 Datensätze aus, wie in Abbildung 3 gezeigt:
Wie funktioniert es?
Wie zuvor verwenden wir das Plan-Diagramm, um zu wissen, wie das funktioniert:
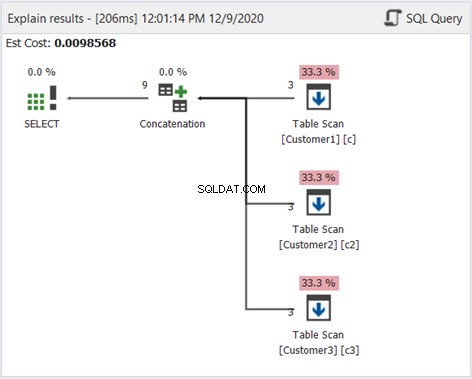
Mit Ausnahme von Sort Distinct in Abbildung 2 ist das obige Diagramm identisch. Das passt, denn wir wollen die Duplikate nicht herausfiltern.
Das obige Diagramm zeigt, wie UNION ALL funktioniert. Zusammenfassend sind dies die Schritte, denen SQL Server folgt:
- Die Ergebnisse jeder SELECT-Anweisung abrufen.
- Kombinieren Sie dann die Ergebnisse mit einem Verkettungsoperator.
Erfolgreiche Beispiele mit UNION ALL folgen diesem Muster.
3. Sie können SQL UNION und UNION ALL mischen, aber mit Klammern gruppieren
Sie können die Verwendung von UNION und UNION ALL in mindestens drei SELECT-Anweisungen mischen.
Wie benutzt man es?
Sie kombinieren die Ergebnisse der SELECT-Anweisungen entweder mit UNION oder UNION ALL dazwischen. Klammern gruppieren die zusammenkommenden Ergebnisse. Lassen Sie uns dieselben Daten für das nächste Beispiel verwenden:
SELECT
c.LastName
,c.FirstName
,c.AccountNumber
FROM dbo.Customer1 c
UNION ALL
(
SELECT
c2.LastName
,c2.FirstName
,c2.AccountNumber
FROM dbo.Customer2 c2
UNION
SELECT
c3.LastName
,c3.FirstName
,c3.AccountNumber
FROM dbo.Customer3 c3
)
Das obige Beispiel kombiniert die Ergebnisse der letzten beiden SELECT-Anweisungen ohne Duplikate. Dann kombiniert es das mit dem Ergebnis der ersten SELECT-Anweisung. Das Ergebnis ist in Abbildung 5 unten zu sehen:
4. Spalten jeder SELECT-Anweisung sollten kompatible Datentypen haben
Spalten in jeder SELECT-Anweisung, die UNION verwendet, können unterschiedliche Datentypen haben. Es ist akzeptabel, solange sie kompatibel sind und eine implizite Konvertierung über sie zulassen. Der endgültige Datentyp der kombinierten Ergebnisse verwendet den Datentyp mit der höchsten Priorität. Außerdem sind die Daten mit der größten Größe die Grundlage für die endgültige Datengröße. Im Fall von Zeichenketten werden die Daten mit der größten Anzahl von Zeichen verwendet.
Warum ist das wichtig?
Wenn Sie das Ergebnis von UNIONs in eine Tabelle einfügen müssen, bestimmen der endgültige Datentyp und die endgültige Größe, ob es in die Zieltabellenspalte passt oder nicht. Wenn nicht, tritt ein Fehler auf. Beispielsweise hat eine der Spalten in UNION den Endtyp NVARCHAR(50). Wenn die Zieltabellenspalte VARCHAR(50) ist, können Sie sie nicht in die Tabelle einfügen.
Wie funktioniert es?
Es gibt keinen besseren Weg, es zu erklären als ein Beispiel:
SELECT N'김지수' AS FullName
UNION
SELECT N'김제니' AS KoreanName
UNION
SELECT N'박채영' AS KoreanName
UNION
SELECT N'ลลิษา มโนบาล' AS ThaiName
UNION
SELECT 'Kim Ji-soo' AS EnglishName
UNION
SELECT 'Jennie Kim' AS EnglishName
UNION
SELECT 'Roseanne Park' AS EnglishName
UNION
SELECT 'Lalisa Manoban' AS EnglishName
Das obige Beispiel enthält Daten mit englischen, koreanischen und thailändischen Zeichennamen. Thai und Koreanisch sind Unicode-Zeichen. Englische Zeichen sind es nicht. Also, was glauben Sie, wird der endgültige Datentyp und die endgültige Größe sein? dbForge Studio zeigt es in der Ergebnismenge:
Haben Sie den endgültigen Datentyp in Abbildung 6 bemerkt? Wegen der Unicode-Zeichen kann es nicht VARCHAR sein. Es muss also NVARCHAR sein. In der Zwischenzeit kann die Größe nicht kleiner als 14 sein, da die Daten mit der größten Anzahl von Zeichen 14 Zeichen haben. Siehe die roten Beschriftungen in Abbildung 6. Es empfiehlt sich, den Datentyp und die Größe in die Spaltenüberschrift in dbForge Studio aufzunehmen.
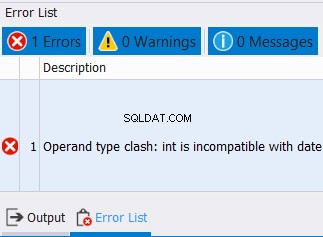
Dies gilt nicht nur für String-Datentypen. Dies gilt auch für Zahlen und Daten. Wenn Sie hingegen versuchen, Daten mit inkompatiblen Datentypen zu kombinieren, tritt ein Fehler auf. Siehe das Beispiel unten:
SELECT CAST('12/25/2020' AS DATE) AS col1
UNION
SELECT CAST('10' AS INT) AS col1
Wir können Datumsangaben und Ganzzahlen nicht in einer Spalte kombinieren. Erwarten Sie also einen Fehler wie den folgenden:
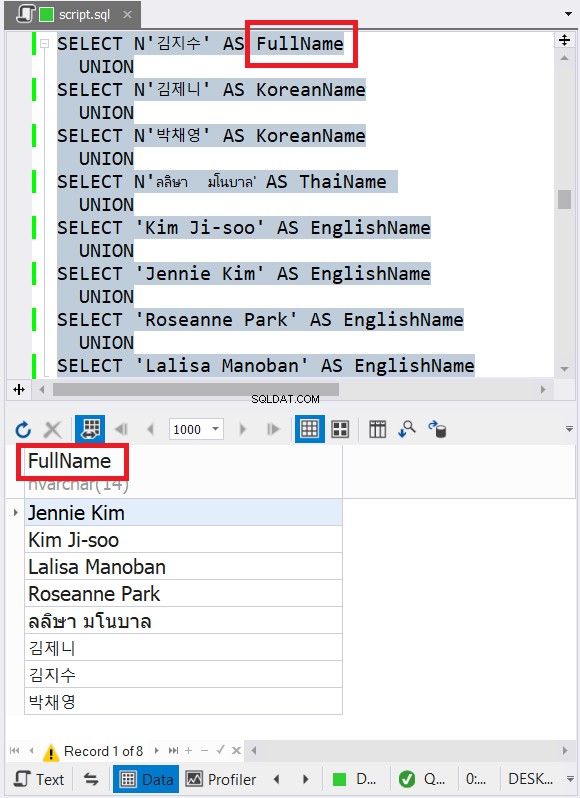
5. Die Spaltennamen der kombinierten Ergebnisse verwenden die Spaltennamen der ersten SELECT-Anweisung
Dieses Problem bezieht sich auf den vorherigen Tipp. Beachten Sie die Spaltennamen im Code in Tipp 4. In jeder SELECT-Anweisung gibt es unterschiedliche Spaltennamen. Wir haben jedoch den endgültigen Spaltennamen im kombinierten Ergebnis in Abbildung 6 zuvor gesehen. Basis ist also der Spaltenname der ersten SELECT-Anweisung.
Warum ist das wichtig?
Dies kann praktisch sein, wenn Sie das Ergebnis der UNION in einer temporären Tabelle ausgeben müssen. Wenn Sie in den nachfolgenden Anweisungen auf die Spaltennamen verweisen müssen, müssen Sie sich der Namen sicher sein. Sofern Sie keinen erweiterten Code-Editor mit IntelliSense verwenden, ist ein weiterer Fehler in Ihrem T-SQL-Code wahrscheinlich.
Wie funktioniert es?
Siehe Abbildung 8 für deutlichere Ergebnisse der Verwendung von dbForge Studio:
6. Fügen Sie ORDER BY in der letzten SELECT-Anweisung mit SQL UNION hinzu, um die Ergebnisse zu sortieren
Sie müssen die kombinierten Ergebnisse sortieren. In einer Reihe von SELECT-Anweisungen mit UNION dazwischen können Sie dies mit der ORDER BY-Klausel in der letzten SELECT-Anweisung tun.
Warum ist das wichtig?
Benutzer möchten die Daten in Apps, Webseiten, Berichten, Tabellenkalkulationen und mehr so sortieren, wie sie es bevorzugen.
Verwendung
Verwenden Sie ORDER BY in der letzten SELECT-Anweisung. Hier ist ein Beispiel:
SELECT
e.BusinessEntityID
,p.FirstName
,p.MiddleName
,p.LastName
,'Employee' AS PersonType
FROM HumanResources.Employee e
INNER JOIN Person.Person p ON e.BusinessEntityID = p.BusinessEntityID
UNION
SELECT
c.PersonID
,p.FirstName
,p.MiddleName
,p.LastName
,'Customer' AS PersonType
FROM Sales.Customer c
INNER JOIN Person.Person p ON c.PersonID = p.BusinessEntityID
ORDER BY p.LastName, p.FirstName
Das obige Beispiel lässt es so aussehen, als ob die Sortierung nur in der letzten SELECT-Anweisung erfolgt. Aber es ist nicht. Es wird für das kombinierte Ergebnis funktionieren. Sie werden in Schwierigkeiten geraten, wenn Sie es in jede SELECT-Anweisung einfügen. Sehen Sie sich das Ergebnis an:
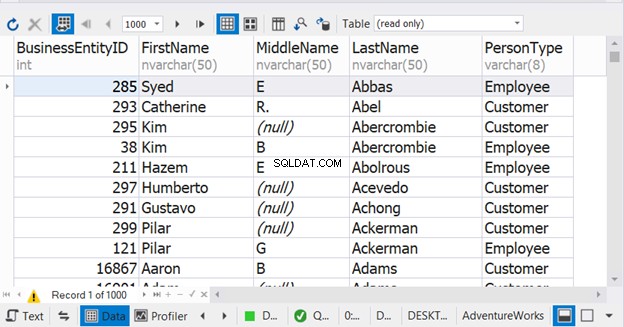
Ohne ORDER BY enthält die Ergebnismenge alle Employee PersonType zuerst gefolgt von all Customer PersonType . Abbildung 9 zeigt jedoch, dass Namen zur Sortierreihenfolge des kombinierten Ergebnisses werden.
Wenn Sie versuchen, ORDER BY in jede zu sortierende SELECT-Anweisung einzufügen, passiert Folgendes:
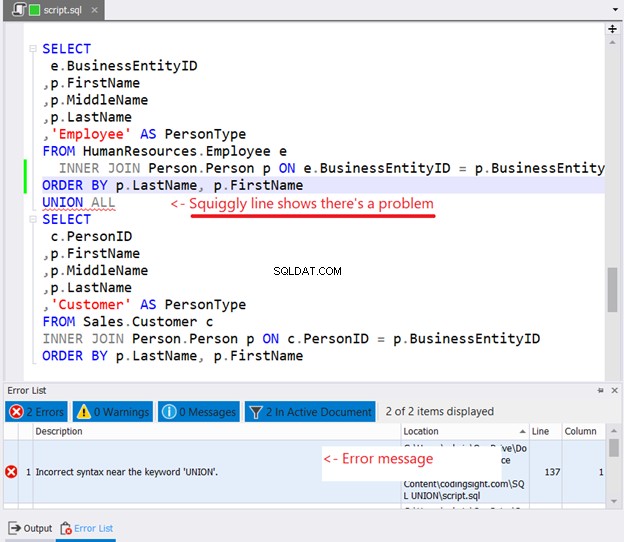
Haben Sie die verschnörkelte Linie in Abbildung 10 gesehen? Es ist eine Warnung. Wenn Sie es nicht bemerkt haben und fortgefahren sind, wird ein Fehler im Fehlerlistenfenster von dbForge Studio angezeigt.
7. WHERE- und GROUP BY-Klauseln können in jeder SELECT-Anweisung mit SQL UNION verwendet werden
Die ORDER BY-Klausel funktioniert nicht in jeder SELECT-Anweisung mit UNION dazwischen. WHERE- und GROUP BY-Klauseln funktionieren jedoch.
Warum ist das wichtig?
Möglicherweise möchten Sie die Ergebnisse verschiedener Abfragen kombinieren, die Daten filtern, zählen oder zusammenfassen. So können Sie beispielsweise die Gesamtzahl der Verkaufsaufträge für Januar 2012 abrufen und mit Januar 2013, Januar 2014 usw. vergleichen.
Verwendung
Platzieren Sie die WHERE- und/oder GROUP BY-Klauseln in jeder SELECT-Anweisung. Sehen Sie sich das folgende Beispiel an:
USE AdventureWorks
GO
-- Get the number of orders for January 2012, 2013, 2014 for comparison
SELECT
YEAR(soh.OrderDate) AS OrderYear
,COUNT(*) AS NumberOfJanuaryOrders
FROM Sales.SalesOrderHeader soh
WHERE soh.OrderDate BETWEEN '01/01/2012' AND '01/31/2012'
GROUP BY YEAR(soh.OrderDate)
UNION
SELECT
YEAR(soh.OrderDate) AS OrderYear
,COUNT(*) AS NumberOfJanuaryOrders
FROM Sales.SalesOrderHeader soh
WHERE soh.OrderDate BETWEEN '01/01/2013' AND '01/31/2013'
GROUP BY YEAR(soh.OrderDate)
UNION
SELECT
YEAR(soh.OrderDate) AS OrderYear
,COUNT(*) AS NumberOfJanuaryOrders
FROM Sales.SalesOrderHeader soh
WHERE soh.OrderDate BETWEEN '01/01/2014' AND '01/31/2014'
GROUP BY YEAR(soh.OrderDate)
Der obige Code kombiniert die Anzahl der Januar-Bestellungen für drei aufeinanderfolgende Jahre. Überprüfen Sie nun die Ausgabe:
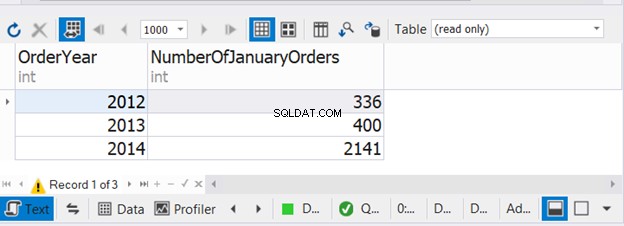
Dieses Beispiel zeigt, dass es möglich ist, WHERE und GROUP BY in jeder der drei SELECT-Anweisungen mit UNION zu verwenden.
8. SELECT INTO Funktioniert mit SQL UNION
Wenn Sie die Ergebnisse einer Abfrage mit SQL UNION in eine Tabelle einfügen müssen, können Sie dies tun, indem Sie SELECT INTO.
verwendenWarum ist das wichtig?
Es wird vorkommen, dass Sie die Ergebnisse einer Abfrage mit UNION zur weiteren Verarbeitung in eine Tabelle einfügen müssen.
Verwendung
Platzieren Sie die INTO-Klausel in der ersten SELECT-Anweisung. Hier ist ein Beispiel:
SELECT
YEAR(soh.OrderDate) AS OrderYear
,COUNT(*) AS NumberOfJanuaryOrders
INTO JanuaryOrders
FROM Sales.SalesOrderHeader soh
WHERE soh.OrderDate BETWEEN '01/01/2012' AND '01/31/2012'
GROUP BY YEAR(soh.OrderDate)
UNION
SELECT
YEAR(soh.OrderDate) AS OrderYear
,COUNT(*) AS NumberOfJanuaryOrders
FROM Sales.SalesOrderHeader soh
WHERE soh.OrderDate BETWEEN '01/01/2013' AND '01/31/2013'
GROUP BY YEAR(soh.OrderDate)
UNION
SELECT
YEAR(soh.OrderDate) AS OrderYear
,COUNT(*) AS NumberOfJanuaryOrders
FROM Sales.SalesOrderHeader soh
WHERE soh.OrderDate BETWEEN '01/01/2014' AND '01/31/2014'
GROUP BY YEAR(soh.OrderDate)
Denken Sie daran, nur eine INTO-Klausel in die erste SELECT-Anweisung zu platzieren.
Wie funktioniert es?
SQL Server folgt dem Muster der Verarbeitung von UNION. Dann fügt es das Ergebnis in die Tabelle ein, die in der INTO-Klausel angegeben ist.
9. Unterscheiden Sie SQL UNION von SQL JOIN
Sowohl SQL UNION als auch SQL JOIN kombinieren die Tabellendaten, aber der Unterschied in Syntax und Ergebnissen ist wie Tag und Nacht.
Warum ist das wichtig?
Wenn Ihr Bericht oder eine Anforderung einen JOIN benötigt, Sie aber einen UNION durchgeführt haben, ist die Ausgabe falsch.
Verwendung von SQL UNION und SQL JOIN
Es ist SQL UNION vs. JOIN. Dies ist eine der verwandten Suchanfragen und Fragen, die ein Neuling in Google stellt, wenn er etwas über SQL UNION lernt. Hier ist die Tabelle der Unterschiede:
| SQL-UNION | SQL-JOIN | |
| Was kombiniert wird | Zeilen | Spalten (mit einem Schlüssel) |
| Anzahl der Spalten pro Tabelle | Dasselbe für alle Tabellen | Variable (Null für alle Spalten/Tabellen) |
In allen Projekten, an denen ich beteiligt war, kommt SQL JOIN meistens zum Einsatz. Ich hatte nur wenige Fälle, in denen SQL UNION verwendet wurde. Aber wie Sie bisher gesehen haben, ist die SQL UNION alles andere als nutzlos.
10. SQL UNION ALL ist schneller als UNION
Die Plandiagramme in Abbildung 2 und Abbildung 4 zuvor deuten darauf hin, dass UNION einen zusätzlichen Operator benötigt, um eindeutige Ergebnisse zu gewährleisten. Deshalb ist UNION ALL schneller.
Warum ist das wichtig?
Sie, Ihre Benutzer, Ihre Kunden, Ihr Chef, alle wollen schnelle Ergebnisse. Wenn Sie wissen, dass UNION ALL schneller ist als UNION, fragen Sie sich, was zu tun ist, wenn Sie einzigartige kombinierte Ergebnisse benötigen. Es gibt eine Lösung, wie Sie später sehen werden.
SQL UNION ALL vs. UNION-Leistung
Abbildung 2 und Abbildung 4 haben Ihnen bereits eine Vorstellung davon gegeben, was schneller ist. Aber die verwendeten Codebeispiele sind einfach mit einer kleinen Ergebnismenge. Lassen Sie uns weitere Vergleiche mit Millionen von Datensätzen hinzufügen, um es überzeugend zu machen.
Bereiten wir zunächst die Daten vor:
SELECT TOP (2000000)
val = ROW_NUMBER() OVER (ORDER BY sod.SalesOrderDetailID)
INTO dbo.TestNumbers
FROM AdventureWorks.Sales.SalesOrderDetail sod
CROSS JOIN AdventureWorks.Sales.SalesOrderDetail sod2
Das sind 2 Millionen Datensätze. Ich hoffe, das ist überzeugend genug. Sehen wir uns nun die nächsten beiden Abfragebeispiele unten an.
-- Using UNION ALL
SELECT
val
FROM TestNumbers tn
UNION ALL
SELECT
val
FROM TestNumbers tn
-- Using UNION
SELECT
val
FROM TestNumbers tn
UNION
SELECT
val
FROM TestNumbers tn
Untersuchen wir die an diesen Abfragen beteiligten Prozesse, beginnend mit der schnelleren.
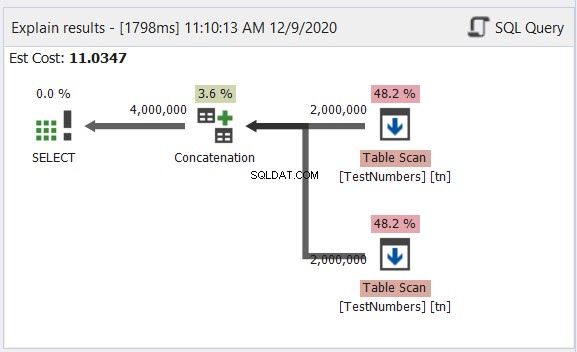
Plandiagrammanalyse
Das Diagramm in Abbildung 12 sieht typisch für einen UNION ALL-Prozess aus. Das Ergebnis sind jedoch 4 Millionen kombinierte Ergebnisse. Siehe den Pfeil, der aus dem Concatenation-Operator herausgeht. Dennoch liegt es typischerweise daran, dass es sich nicht um die Duplikate kümmert.
Sehen wir uns nun das Diagramm der UNION-Abfrage in Abbildung 13 an:
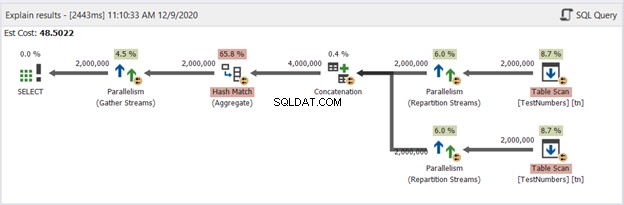
Dieser ist nicht mehr typisch. Der Plan wird zu einem parallelen Abfrageplan, um das Entfernen von Duplikaten in vier Millionen Zeilen zu bewältigen. Der parallele Abfrageplan bedeutet, dass SQL Server den Prozess durch die Anzahl der verfügbaren Prozessorkerne teilen muss.
Lassen Sie es uns interpretieren, beginnend mit den rechten Operatoren, die nach links gehen:
- Da wir eine Tabelle mit sich selbst kombinieren, muss SQL Server sie zweimal abrufen. Sehen Sie sich die beiden Tabellenscans mit jeweils zwei Millionen Datensätzen an.
- Repartition Stream-Operatoren steuern die Verteilung jeder Zeile an den nächsten verfügbaren Thread.
- Verkettung verdoppelt das Ergebnis auf vier Millionen. Dies berücksichtigt noch die Anzahl der Prozessorkerne.
- Ein Hash-Match wird angewendet, um die Duplikate zu entfernen. Dies ist ein teurer Prozess mit 65,8 % Bedienerkosten. Infolgedessen wurden zwei Millionen Datensätze verworfen.
- Gather Streams rekombinieren die in jedem Prozessorkern oder Thread erzielten Ergebnisse zu einem.
Das ist zu viel Arbeit, obwohl der Prozess in mehrere Threads unterteilt ist. Daher werden Sie daraus schließen, dass es langsamer läuft. Aber was ist, wenn es eine Lösung gibt, mit UNION ALL eindeutige Datensätze zu erhalten, aber schneller als diese?
Einzigartige Ergebnisse, aber schnellere Lösung mit UNION ALL – wie?
Ich werde dich nicht warten lassen. Hier ist der Code:
SELECT DISTINCT
val
FROM
(
SELECT
val
FROM TestNumbers tn
UNION ALL
SELECT
val
FROM TestNumbers tn
) AS uniqtn
Dies kann eine lahme Lösung sein. Aber sehen Sie sich das Plandiagramm in Abbildung 14 an:
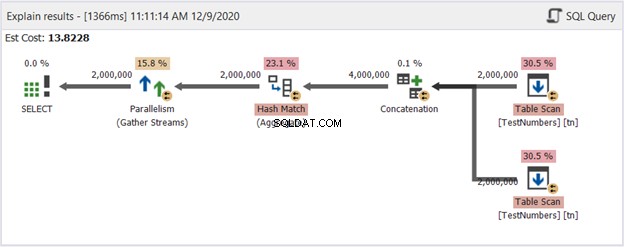
Also, was hat es besser gemacht? Wenn Sie es mit Abbildung 13 vergleichen, sehen Sie, dass die Repartition Stream-Operatoren verschwunden sind. Es verwendet jedoch immer noch mehrere Threads, um die Arbeit zu erledigen. Andererseits bedeutet dies, dass der Abfrageoptimierer diesen Prozess für einfacher hält als die Abfrage mit UNION.
Können wir sicher schlussfolgern, dass wir die Verwendung von UNION vermeiden und stattdessen diesen Ansatz verwenden sollten? Gar nicht! Überprüfen Sie immer das Ausführungsplandiagramm! Es hängt immer davon ab, was SQL Server Ihnen geben soll. Dieser zeigt nur, dass Sie Ihren Abfrageansatz ändern müssen, wenn Sie auf eine Leistungsbarriere stoßen.
Wie sieht es mit E/A-Statistiken aus?
Wir können nicht ignorieren, wie viele Ressourcen SQL Server benötigt, um unsere Abfragebeispiele zu verarbeiten. Deshalb müssen wir auch ihre STATISTIK IO untersuchen. Wenn wir die drei obigen Abfragen vergleichen, erhalten wir die folgenden logischen Lesevorgänge:
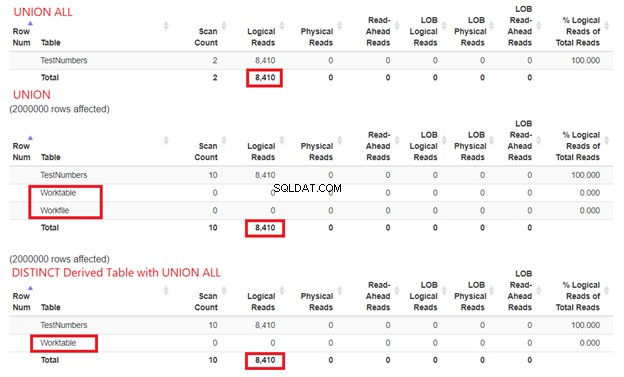
Aus Abbildung 15 können wir immer noch schließen, dass UNION ALL schneller ist als UNION, obwohl die logischen Lesevorgänge dieselben sind. Das Vorhandensein von Worktable und Arbeitsdatei zeigt mit tempdb um die Arbeit zu erledigen. Wenn wir hingegen SELECT DISTINCT aus einer abgeleiteten Tabelle mit UNION ALL verwenden, wird die tempdb Die Nutzung ist im Vergleich zu UNION geringer. Dies bestätigt erneut, dass unsere Analyse aus den früheren Plandiagrammen korrekt ist.
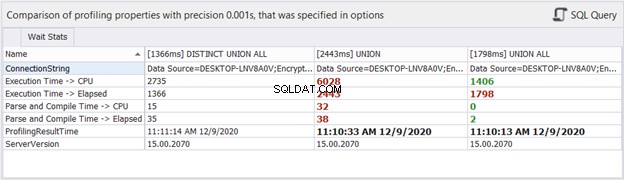
Wie wäre es mit Zeitstatistiken?
Obwohl sich die verstrichene Zeit bei jeder Ausführung derselben Abfragen ändern kann, kann sie uns eine Vorstellung geben und unserer Analyse weitere Beweise hinzufügen. dbForge Studio zeigt die Zeitunterschiede der drei obigen Abfragen an. Dieser Vergleich stimmt mit der vorherigen Analyse überein, die wir durchgeführt haben.
Schlussfolgerung
Wir haben viele Hintergrundinformationen behandelt, um Ihnen das zu vermitteln, was Sie für die Verwendung von SQL UNION und UNION ALL benötigen. Möglicherweise erinnern Sie sich nach dem Lesen dieses Beitrags nicht mehr an alles, also setzen Sie ein Lesezeichen für diese Seite.
Wenn Ihnen der Beitrag gefällt, können Sie ihn gerne in den sozialen Medien teilen.