Für den T-SQL-Dienstag dieses Monats bat uns Steve Jones (@way0utwest), über unsere besten oder schlechtesten Trigger-Erfahrungen zu sprechen. Es stimmt zwar, dass Trigger oft verpönt und sogar gefürchtet sind, aber sie haben mehrere gültige Anwendungsfälle, darunter:
- Prüfung (vor 2016 SP1, als diese Funktion in allen Editionen kostenlos wurde)
- Durchsetzung von Geschäftsregeln und Datenintegrität, wenn sie nicht einfach in Einschränkungen implementiert werden können und Sie nicht möchten, dass sie vom Anwendungscode oder den DML-Abfragen selbst abhängig sind
- Pflegen historischer Datenversionen (vor Change Data Capture, Change Tracking und Temporal Tables)
- Einreihen von Warnungen oder asynchrone Verarbeitung als Reaktion auf eine bestimmte Änderung
- Zulassen von Änderungen an Ansichten (über INSTEAD OF-Trigger)
Das ist keine vollständige Liste, sondern nur eine kurze Zusammenfassung einiger Szenarien, die ich erlebt habe, wo Trigger damals die richtige Antwort waren.
Wenn Trigger notwendig sind, erkunde ich immer gerne die Verwendung von INSTEAD OF-Triggern anstelle von AFTER-Triggern. Ja, sie sind ein bisschen mehr Vorausarbeit*, aber sie haben einige ziemlich wichtige Vorteile. Zumindest theoretisch scheint die Aussicht, das Eintreten einer Aktion (und ihrer protokollierten Konsequenzen) zu verhindern, viel effizienter zu sein, als alles geschehen zu lassen und es dann rückgängig zu machen.
*Ich sage das, weil Sie die DML-Anweisung innerhalb des Triggers erneut codieren müssen; Aus diesem Grund werden sie nicht als BEFORE-Trigger bezeichnet. Die Unterscheidung ist hier wichtig, da einige Systeme echte BEFORE-Trigger implementieren, die einfach zuerst ausgeführt werden. In SQL Server bricht ein INSTEAD OF-Trigger effektiv die Anweisung ab, die ihn ausgelöst hat.
Nehmen wir an, wir hätten eine einfache Tabelle zum Speichern von Kontonamen. In diesem Beispiel erstellen wir zwei Tabellen, damit wir zwei verschiedene Auslöser und ihre Auswirkungen auf die Abfragedauer und die Protokollnutzung vergleichen können. Das Konzept ist, dass wir eine Geschäftsregel haben:Der Kontoname ist nicht in einer anderen Tabelle vorhanden, die „schlechte“ Namen darstellt, und der Auslöser wird verwendet, um diese Regel durchzusetzen. Hier ist die Datenbank:
USE [master];
GO
CREATE DATABASE [tr] ON (name = N'tr_dat', filename = N'C:\temp\tr.mdf', size = 4096MB)
LOG ON (name = N'tr_log', filename = N'C:\temp\tr.ldf', size = 2048MB);
GO
ALTER DATABASE [tr] SET RECOVERY FULL;
GO Und die Tabellen:
USE [tr]; GO CREATE TABLE dbo.Accounts_After ( AccountID int PRIMARY KEY, name sysname UNIQUE, filler char(255) NOT NULL DEFAULT '' ); CREATE TABLE dbo.Accounts_Instead ( AccountID int PRIMARY KEY, name sysname UNIQUE, filler char(255) NOT NULL DEFAULT '' ); CREATE TABLE dbo.InvalidNames ( name sysname PRIMARY KEY ); INSERT dbo.InvalidNames(name) VALUES (N'poop'),(N'hitler'),(N'boobies'),(N'cocaine');
Und schließlich die Auslöser. Der Einfachheit halber beschäftigen wir uns nur mit Einfügungen, und sowohl im Nachher- als auch im Statt-Fall brechen wir einfach den gesamten Stapel ab, wenn ein einzelner Name gegen unsere Regel verstößt:
CREATE TRIGGER dbo.tr_Accounts_After
ON dbo.Accounts_After
AFTER INSERT
AS
BEGIN
IF EXISTS
(
SELECT 1 FROM inserted AS i
INNER JOIN dbo.InvalidNames AS n
ON i.name = n.name
)
BEGIN
RAISERROR(N'Tsk tsk.', 11, 1);
ROLLBACK TRANSACTION;
RETURN;
END
END
GO
CREATE TRIGGER dbo.tr_Accounts_Instead
ON dbo.Accounts_After
INSTEAD OF INSERT
AS
BEGIN
IF EXISTS
(
SELECT 1 FROM inserted AS i
INNER JOIN dbo.InvalidNames AS n
ON i.name = n.name
)
BEGIN
RAISERROR(N'Tsk tsk.', 11, 1);
RETURN;
END
ELSE
BEGIN
INSERT dbo.Accounts_Instead(AccountID, name, filler)
SELECT AccountID, name, filler FROM inserted;
END
END
GO Um die Leistung zu testen, versuchen wir jetzt einfach, 100.000 Namen in jede Tabelle einzufügen, mit einer vorhersehbaren Fehlerrate von 10 %. Mit anderen Worten, 90.000 Namen sind in Ordnung, die anderen 10.000 bestehen den Test nicht und führen dazu, dass der Trigger je nach Stapel entweder zurückgesetzt oder nicht eingefügt wird.
Zuerst müssen wir vor jedem Batch etwas aufräumen:
TRUNCATE TABLE dbo.Accounts_Instead; TRUNCATE TABLE dbo.Accounts_After; GO CHECKPOINT; CHECKPOINT; BACKUP LOG triggers TO DISK = N'C:\temp\tr.trn' WITH INIT, COMPRESSION; GO
Bevor wir mit dem Fleisch jeder Charge beginnen, zählen wir die Zeilen im Transaktionsprotokoll und messen die Größe und den freien Speicherplatz. Dann durchlaufen wir einen Cursor, um die 100.000 Zeilen in zufälliger Reihenfolge zu verarbeiten, und versuchen, jeden Namen in die entsprechende Tabelle einzufügen. Wenn wir fertig sind, messen wir die Anzahl der Zeilen und die Größe des Protokolls erneut und prüfen die Dauer.
SET NOCOUNT ON;
DECLARE @batch varchar(10) = 'After', -- or After
@d datetime2(7) = SYSUTCDATETIME(),
@n nvarchar(129),
@i int,
@err nvarchar(512);
-- measure before and again when we're done:
SELECT COUNT(*) FROM sys.fn_dblog(NULL, NULL);
SELECT CurrentSizeMB = size/128.0,
FreeSpaceMB = (size-CONVERT(int, FILEPROPERTY(name,N'SpaceUsed')))/128.0
FROM sys.database_files
WHERE name = N'tr_log';
DECLARE c CURSOR LOCAL FAST_FORWARD
FOR
SELECT name, i = ROW_NUMBER() OVER (ORDER BY NEWID())
FROM
(
SELECT DISTINCT TOP (90000) LEFT(o.name,64) + '/' + LEFT(c.name,63)
FROM sys.all_objects AS o
CROSS JOIN sys.all_columns AS c
UNION ALL
SELECT TOP (10000) N'boobies' FROM sys.all_columns
) AS x (name)
ORDER BY i;
OPEN c;
FETCH NEXT FROM c INTO @n, @i;
WHILE @@FETCH_STATUS = 0
BEGIN
BEGIN TRY
IF @batch = 'After'
INSERT dbo.Accounts_After(AccountID,name) VALUES(@i,@n);
IF @batch = 'Instead'
INSERT dbo.Accounts_Instead(AccountID,name) VALUES(@i,@n);
END TRY
BEGIN CATCH
SET @err = ERROR_MESSAGE();
END CATCH
FETCH NEXT FROM c INTO @n, @i;
END
-- measure again when we're done:
SELECT COUNT(*) FROM sys.fn_dblog(NULL, NULL);
SELECT duration = DATEDIFF(MILLISECOND, @d, SYSUTCDATETIME()),
CurrentSizeMB = size/128.0,
FreeSpaceMB = (size-CAST(FILEPROPERTY(name,N'SpaceUsed') AS int))/128.0
FROM sys.database_files
WHERE name = N'tr_log';
CLOSE c; DEALLOCATE c; Ergebnisse (gemittelt über 5 Läufe jeder Charge):
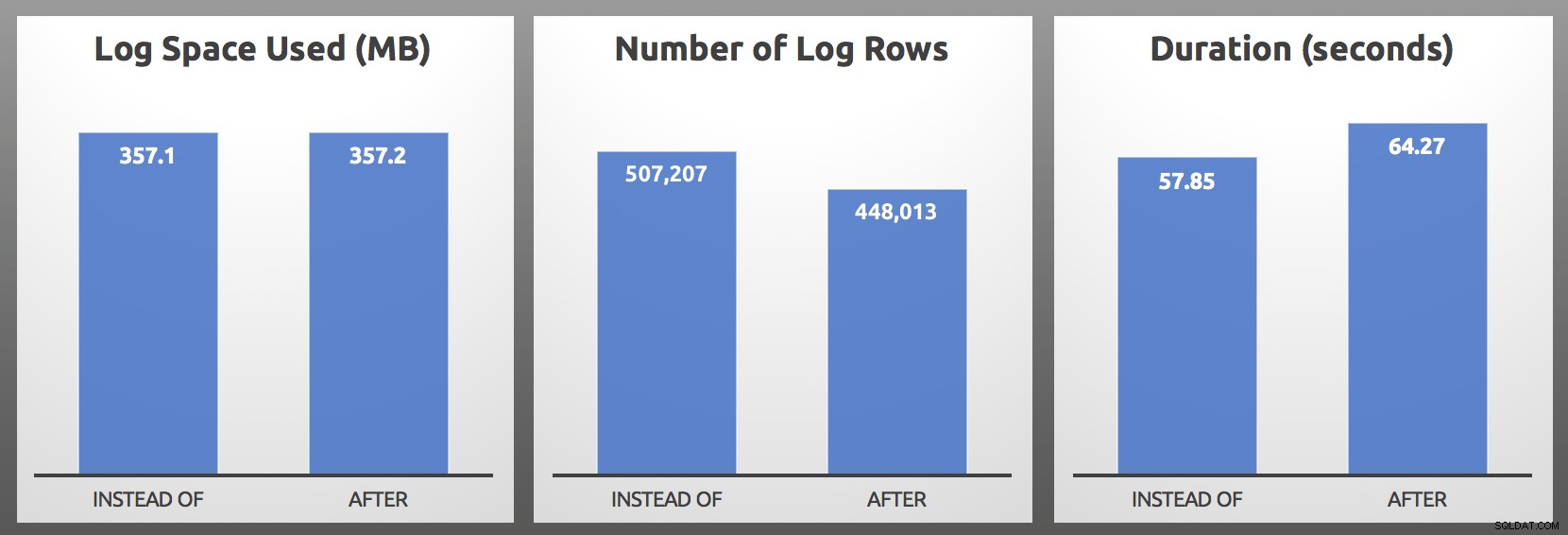 NACH vs. STATT:Ergebnisse
NACH vs. STATT:Ergebnisse
In meinen Tests war die Protokollnutzung nahezu identisch, mit über 10 % mehr Protokollzeilen, die vom INSTEAD OF-Trigger generiert wurden. Ich habe am Ende jeder Charge etwas gegraben:
SELECT [Operation], COUNT(*) FROM sys.fn_dblog(NULL, NULL) GROUP BY [Operation] ORDER BY [Operation];
Und hier war ein typisches Ergebnis (ich habe die wichtigsten Deltas hervorgehoben):
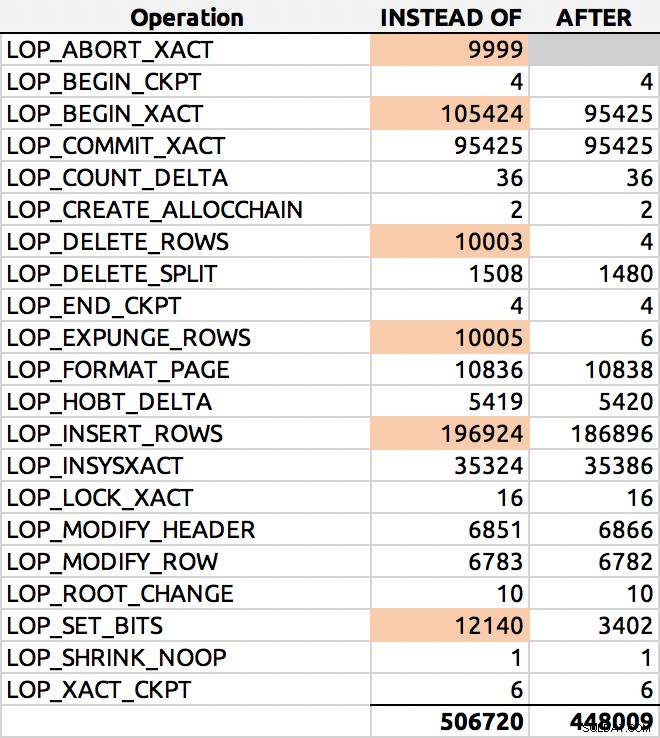 Protokollzeilenverteilung
Protokollzeilenverteilung
Darauf gehe ich ein andermal genauer ein.
Aber wenn man es genau nimmt...
… die wichtigste Metrik ist fast immer die Dauer , und in meinem Fall war der INSTEAD OF-Trigger bei jedem einzelnen Kopf-an-Kopf-Test mindestens 5 Sekunden schneller. Falls Ihnen das alles bekannt vorkommt, ja, ich habe schon einmal darüber gesprochen, aber damals habe ich nicht die gleichen Symptome bei den Protokollzeilen beobachtet.
Beachten Sie, dass dies möglicherweise nicht Ihr genaues Schema oder Ihre Arbeitslast ist, Sie möglicherweise sehr unterschiedliche Hardware haben, Ihre Parallelität möglicherweise höher ist und Ihre Fehlerrate möglicherweise viel höher (oder niedriger) ist. Meine Tests wurden auf einer isolierten Maschine mit viel Arbeitsspeicher und sehr schnellen PCIe-SSDs durchgeführt. Wenn sich Ihr Protokoll auf einem langsameren Laufwerk befindet, können die Unterschiede in der Protokollnutzung die anderen Metriken überwiegen und die Dauer erheblich ändern. All diese Faktoren (und mehr!) können Ihre Ergebnisse beeinflussen, daher sollten Sie in Ihrer Umgebung testen.
Der Punkt ist jedoch, dass INSTEAD OF-Trigger besser passen könnten. Wenn wir jetzt nur STATT DDL-Trigger bekommen könnten …