Analysieren Sie gerne Strings? In diesem Fall ist SQL SUBSTRING eine der unverzichtbaren Zeichenfolgenfunktionen. Es ist eine dieser Fähigkeiten, die ein Entwickler für jede Sprache haben sollte.
Also, wie machst du das?
Wichtige Punkte beim String-Parsing
Angenommen, Sie sind neu im Parsing. Welche wichtigen Punkte müssen Sie beachten?
- Wissen Sie, welche Informationen in die Zeichenfolge eingebettet sind.
- Erhalten Sie die genauen Positionen der einzelnen Informationen in einer Zeichenfolge. Möglicherweise müssen Sie alle Zeichen innerhalb der Zeichenfolge zählen.
- Kennen Sie die Größe oder Länge jedes Informationsstücks in einer Zeichenfolge.
- Verwenden Sie die richtige Zeichenfolgenfunktion, die jede Information in der Zeichenfolge einfach extrahieren kann.
Wenn Sie all diese Faktoren kennen, werden Sie sich auf die Verwendung von SQL SUBSTRING() und die Übergabe von Argumenten vorbereiten.
SQL-SUBSTRING-Syntax

Die Syntax von SQL SUBSTRING lautet wie folgt:
SUBSTRING(String-Ausdruck, Start, Länge)
- String-Ausdruck – a Literal-String oder ein SQL-Ausdruck, der einen String zurückgibt.
- beginnen – eine Nummer, bei der die Extraktion beginnt. Es ist auch 1-basiert – das erste Zeichen im Argument des Zeichenfolgenausdrucks muss mit 1 beginnen, nicht mit 0. In SQL Server ist es immer eine positive Zahl. In MySQL oder Oracle kann es jedoch positiv oder negativ sein. Wenn nein, beginnt das Scannen am Ende der Zeichenfolge.
- Länge – die Länge der zu extrahierenden Zeichen. SQL Server erfordert es. In MySQL oder Oracle ist es optional.
4 SQL-SUBSTRING-Beispiele
1. Verwenden von SQL SUBSTRING zum Extrahieren aus einem Literal-String
Beginnen wir mit einem einfachen Beispiel mit einer Literalzeichenfolge. Wir verwenden den Namen einer berühmten koreanischen Mädchengruppe, BlackPink, und Abbildung 1 zeigt, wie SUBSTRING funktionieren wird:

Der folgende Code zeigt, wie wir ihn extrahieren:
-- extract 'black' from BlackPink (English)
SELECT SUBSTRING('BlackPink',1,5) AS result
Sehen wir uns nun auch die Ergebnismenge in Abbildung 2 an:
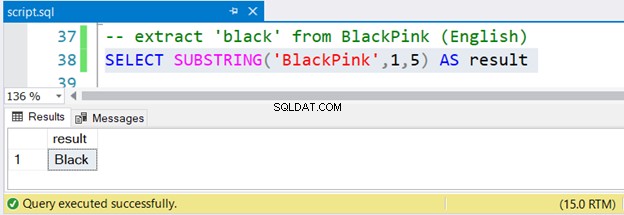
Ist das nicht einfach?
Um Schwarz zu extrahieren von BlackPink , beginnen Sie bei Position 1 und enden bei Position 5. Seit BlackPink koreanisch ist, lassen Sie uns herausfinden, ob SUBSTRING mit koreanischen Unicode-Zeichen funktioniert.
(HAFTUNGSAUSSCHLUSS :Ich kann kein Koreanisch sprechen, lesen oder schreiben, also habe ich die koreanische Übersetzung von Wikipedia. Ich habe auch Google Translate verwendet, um zu sehen, welche Zeichen Schwarz entsprechen und Rosa . Bitte verzeihen Sie mir, wenn es falsch ist. Trotzdem hoffe ich, dass der Punkt, den ich zu klären versuche, kommt quer)
Lassen Sie uns die Zeichenfolge auf Koreanisch haben (siehe Abbildung 3). Die verwendeten koreanischen Zeichen werden in BlackPink übersetzt:

Sehen Sie sich nun den folgenden Code an. Wir werden zwei Zeichen extrahieren, die Schwarz entsprechen .
-- extract 'black' from BlackPink (Korean)
SELECT SUBSTRING(N'블랙핑크',1,2) AS result
Ist Ihnen die koreanische Zeichenfolge mit vorangestelltem N aufgefallen? ? Es verwendet Unicode-Zeichen, und der SQL Server geht von NVARCHAR aus und sollte von N vorangestellt werden . Das ist der einzige Unterschied zur englischen Version. Aber wird es gut laufen? Siehe Abbildung 4:
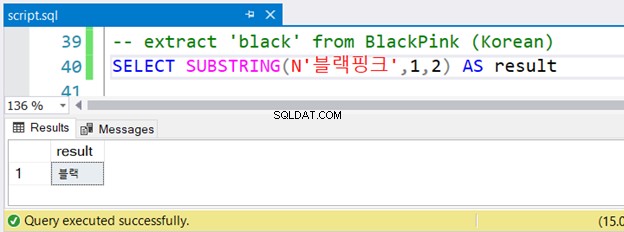
Es lief ohne Fehler.
2. Verwenden von SQL SUBSTRING in MySQL mit einem negativen Startargument
Ein negatives Startargument funktioniert in SQL Server nicht. Aber wir können ein Beispiel dafür mit MySQL haben. Lassen Sie uns dieses Mal Pink extrahieren von BlackPink . Hier ist der Code:
-- Extract 'Pink' from BlackPink using MySQL Substring (English)
select substring('BlackPink',-4,4) as result;
Sehen wir uns nun das Ergebnis in Abbildung 5 an:
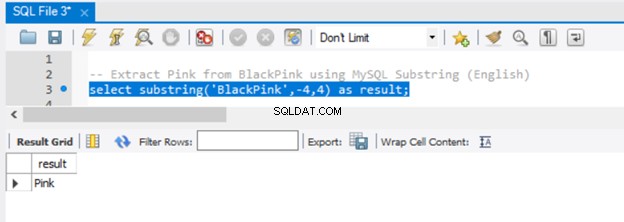
Da wir -4 an den Startparameter übergeben haben, begann die Extraktion am Ende der Zeichenfolge und ging 4 Zeichen rückwärts. Um dasselbe Ergebnis in SQL Server zu erzielen, verwenden Sie die RIGHT()-Funktion.
Unicode-Zeichen funktionieren auch mit MySQL SUBSTRING, wie Sie in Abbildung 6 sehen können:
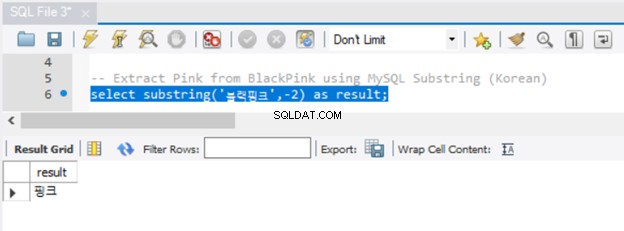
Es hat gut funktioniert. Aber ist Ihnen aufgefallen, dass wir der Zeichenfolge kein N voranstellen mussten? Beachten Sie auch, dass es mehrere Möglichkeiten gibt, einen Teilstring in MySQL zu erhalten. Sie haben SUBSTRING bereits gesehen. Die äquivalenten Funktionen in MySQL sind SUBSTR() und MID().
3. Parsing von Teilstrings mit variablen Start- und Längenargumenten
Leider verwenden nicht alle Zeichenfolgenextraktionen feste Start- und Längenargumente. In einem solchen Fall benötigen Sie CHARINDEX, um die Position einer Zeichenfolge zu ermitteln, auf die Sie abzielen. Nehmen wir ein Beispiel:
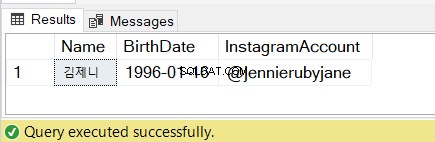
DECLARE @lineString NVARCHAR(30) = N'김제니 01/16/example@sqldat.com'
DECLARE @name NVARCHAR(5)
DECLARE @bday DATE
DECLARE @instagram VARCHAR(20)
SET @name = SUBSTRING(@lineString,1,CHARINDEX('@',@lineString)-11)
SET @bday = SUBSTRING(@lineString,CHARINDEX('@',@lineString)-10,10)
SET @instagram = SUBSTRING(@lineString,CHARINDEX('@',@lineString),30)
SELECT @name AS [Name], @bday AS [BirthDate], @instagram AS [InstagramAccount]
Im obigen Code müssen Sie einen Namen auf Koreanisch, das Geburtsdatum und das Instagram-Konto extrahieren.
Wir beginnen mit der Definition von drei Variablen, um diese Informationen zu speichern. Danach können wir den String parsen und die Ergebnisse jeder Variablen zuweisen.
Sie denken vielleicht, dass es einfacher ist, feste Starts und Längen zu haben. Außerdem können wir es lokalisieren, indem wir die Zeichen manuell zählen. Aber was ist, wenn Sie viele davon auf einem Tisch haben?
Hier ist unsere Analyse:
- Das einzige feste Element in der Zeichenfolge ist das @ Charakter im Instagram-Konto. Wir können seine Position in der Zeichenfolge mit CHARINDEX erhalten. Dann verwenden wir diese Position, um den Start und die Länge des Rests zu erhalten.
- Das Geburtsdatum hat ein festes Format mit MM/TT/JJJJ mit 10 Zeichen.
- Um den Namen zu extrahieren, beginnen wir bei 1. Da das Geburtsdatum 10 Zeichen plus das @ hat Zeichen können Sie zum Endzeichen des Namens in der Zeichenfolge gelangen. Aus der Position des @ Zeichen gehen wir 11 Zeichen zurück. Der SUBSTRING(@lineString,1,CHARINDEX(‘@’,@lineString)-11) ist der richtige Weg.
- Um das Geburtsdatum zu erhalten, wenden wir die gleiche Logik an. Holen Sie sich die Position des @ Zeichen und gehen Sie 10 Zeichen zurück, um den Startwert für das Geburtsdatum zu erhalten. 10 ist eine feste Länge. SUBSTRING(@lineString,CHARINDEX(‘@’,@lineString)-10,10) So erhalten Sie das Geburtsdatum.
- Schließlich ist es einfach, ein Instagram-Konto zu eröffnen. Beginnen Sie an der Position des @ Zeichen mit CHARINDEX. Hinweis:30 ist das Limit für Instagram-Benutzernamen.
Sehen Sie sich die Ergebnisse in Abbildung 7 an:
4. Verwenden von SQL SUBSTRING in einer SELECT-Anweisung
Sie können auch SUBSTRING in der SELECT-Anweisung verwenden, aber zuerst benötigen wir Arbeitsdaten. Hier ist der Code:
SELECT
CAST(P.LastName AS CHAR(50))
+ CAST(P.FirstName AS CHAR(50))
+ CAST(ISNULL(P.MiddleName,'') AS CHAR(50))
+ CAST(ea.EmailAddress AS CHAR(50))
+ CAST(a.City AS CHAR(30))
+ CAST(a.PostalCode AS CHAR(15)) AS line
INTO PersonContacts
FROM Person.Person p
INNER JOIN Person.EmailAddress ea
ON P.BusinessEntityID = ea.BusinessEntityID
INNER JOIN Person.BusinessEntityAddress bea
ON P.BusinessEntityID = bea.BusinessEntityID
INNER JOIN Person.Address a
ON bea.AddressID = a.AddressID
Der obige Code erstellt eine lange Zeichenfolge, die den Namen, die E-Mail-Adresse, die Stadt und die Postleitzahl enthält. Wir wollen es auch in den Personenkontakten speichern Tabelle.
Lassen Sie uns nun den Code zum Reverse Engineering mit SUBSTRING:
habenSELECT
TRIM(SUBSTRING(line,1,50)) AS [LastName]
,TRIM(SUBSTRING(line,51,50)) AS [FirstName]
,TRIM(SUBSTRING(line,101,50)) AS [MiddleName]
,TRIM(SUBSTRING(line,151,50)) AS [EmailAddress]
,TRIM(SUBSTRING(line,201,30)) AS [City]
,TRIM(SUBSTRING(line,231,15)) AS [PostalCode]
FROM PersonContacts pc
ORDER BY LastName, FirstName
Da wir Spalten mit fester Größe verwendet haben, ist die Verwendung von CHARINDEX nicht erforderlich.
Die Verwendung von SQL SUBSTRING in einer WHERE-Klausel – eine Performance-Falle?
Es ist wahr. Niemand kann Sie daran hindern, SUBSTRING in einer WHERE-Klausel zu verwenden. Es ist eine gültige Syntax. Aber was ist, wenn es Leistungsprobleme verursacht?
Deshalb beweisen wir es mit einem Beispiel und diskutieren dann, wie dieses Problem behoben werden kann. Aber zuerst bereiten wir unsere Daten vor:
USE AdventureWorks
GO
SELECT * INTO SalesOrders FROM Sales.SalesOrderHeader soh
Ich kann den SalesOrderHeader nicht vermasseln Tisch, also habe ich es auf einen anderen Tisch geworfen. Dann habe ich die SalesOrderID erstellt in den neuen SalesOrders Tabelle einen Primärschlüssel.
Jetzt sind wir bereit für die Abfrage. Ich verwende dbForge Studio für SQL Server mit Anfrage-Profilerstellungsmodus EIN um die Abfragen zu analysieren.
SELECT
so.SalesOrderID
,so.OrderDate
,so.CustomerID
,so.AccountNumber
FROM SalesOrders so
WHERE SUBSTRING(so.AccountNumber,4,4) = '4030'
Wie Sie sehen, läuft die obige Abfrage einwandfrei. Sehen Sie sich nun das Plandiagramm des Abfrageprofils in Abbildung 8 an:
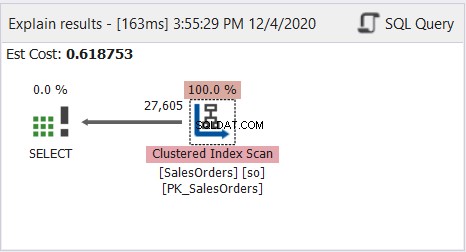
Das Plandiagramm sieht einfach aus, aber lassen Sie uns die Eigenschaften des Clustered Index Scan-Knotens untersuchen. Insbesondere benötigen wir die Laufzeitinformationen:
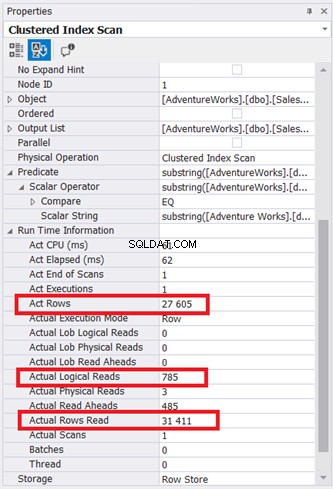
Abbildung 9 zeigt 785 * 8-KB-Seiten, die von der Datenbank-Engine gelesen wurden. Beachten Sie auch, dass die tatsächlich gelesenen Zeilen 31.411 betragen. Es ist die Gesamtzahl der Zeilen in der Tabelle. Die Abfrage hat jedoch nur 27.605 tatsächliche Zeilen zurückgegeben.
Die gesamte Tabelle wurde mit dem Clustered-Index als Referenz gelesen.
Warum?
Die Sache ist die, dass der SQL Server wissen muss, ob 4030 ist eine Teilzeichenfolge einer Kontonummer. Es muss jeden Datensatz lesen und auswerten. Verwerfen Sie die Zeilen, die nicht gleich sind, und geben Sie die Zeilen zurück, die wir benötigen. Es erledigt die Arbeit, aber nicht schnell genug.
Was können wir tun, damit es schneller läuft?
Vermeiden Sie SUBSTRING in der WHERE-Klausel und erzielen Sie schneller dasselbe Ergebnis
Was wir jetzt wollen, ist, dasselbe Ergebnis zu erhalten, ohne SUBSTRING in der WHERE-Klausel zu verwenden. Führen Sie die folgenden Schritte aus:
- Ändern Sie die Tabelle, indem Sie eine berechnete Spalte hinzufügen mit einem SUBSTRING(AccountNumber, 4,4) Formel. Nennen wir es AccountCategory mangels eines besseren Begriffs.
- Erstellen Sie einen nicht geclusterten Index für die neue AccountCategory Säule. Fügen Sie das Bestelldatum hinzu , Kontonummer und Kunden-ID Spalten.
Das ist es.
Wir ändern die WHERE-Klausel der Abfrage, um die neue AccountCategory anzupassen Spalte:
SET STATISTICS IO ON
SELECT
so.SalesOrderID
,so.OrderDate
,so.CustomerID
,so.AccountNumber
FROM SalesOrders so
WHERE so.AccountCategory = '4030'
SET STATISTICS IO OFF
Es gibt keinen SUBSTRING in der WHERE-Klausel. Sehen wir uns nun das Plandiagramm an:
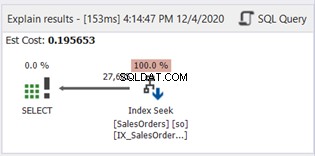
Der Index Scan wurde durch Index Seek ersetzt. Beachten Sie auch, dass der SQL Server den neuen Index für die berechnete Spalte verwendet hat. Gibt es auch Änderungen bei logischen Lesevorgängen und tatsächlich gelesenen Zeilen? Siehe Abbildung 11:
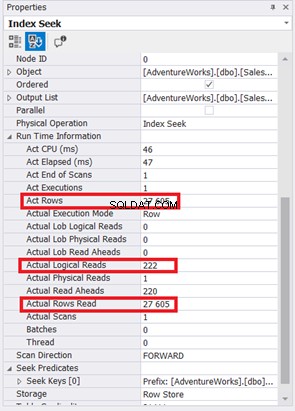
Die Reduzierung von 785 auf 222 logische Lesevorgänge ist eine große Verbesserung, mehr als dreimal weniger als die ursprünglichen logischen Lesevorgänge. Außerdem wurde Actual Rows Read auf die Zeilen minimiert, die wir benötigen.
Daher ist die Verwendung von SUBSTRING in der WHERE-Klausel nicht gut für die Leistung und gilt für jede andere skalare Funktion, die in der WHERE-Klausel verwendet wird.
Schlussfolgerung
- Entwickler kommen um das Parsen von Strings nicht herum. Ein Bedarf dafür wird sich so oder so ergeben.
- Beim Parsen von Strings ist es wichtig, die Informationen innerhalb des Strings, die Positionen der einzelnen Informationen und ihre Größe oder Länge zu kennen.
- Eine der Analysefunktionen ist SQL SUBSTRING. Es benötigt nur den zu parsenden String, die Position zum Starten der Extraktion und die Länge des zu extrahierenden Strings.
- SUBSTRING kann sich zwischen SQL-Varianten wie SQL Server, MySQL und Oracle unterschiedlich verhalten.
- Sie können SUBSTRING mit wörtlichen Zeichenfolgen und Zeichenfolgen in Tabellenspalten verwenden.
- Wir haben auch SUBSTRING mit Unicode-Zeichen verwendet.
- Die Verwendung von SUBSTRING oder einer Skalarfunktion in der WHERE-Klausel kann die Abfrageleistung verringern. Beheben Sie dies mit einer indizierten berechneten Spalte.
Wenn Sie diesen Beitrag hilfreich finden, teilen Sie ihn auf Ihren bevorzugten Social-Media-Plattformen oder teilen Sie unten Ihren Kommentar?