Im vorherigen Blogpost haben wir die Grundlagen der Skalierung behandelt – was es ist, welche Typen es gibt, was ein Muss ist, wenn wir skalieren wollen. Dieser Blogbeitrag konzentriert sich auf die Herausforderungen und die Möglichkeiten, wie wir skalieren können.
Herausforderung von Scaling-Out
Das Skalieren von Datenbanken ist aus mehreren Gründen nicht die einfachste Aufgabe. Konzentrieren wir uns ein wenig auf die Herausforderungen im Zusammenhang mit der horizontalen Skalierung Ihrer Datenbankinfrastruktur.
Zustandsbehafteter Dienst
Wir können zwei verschiedene Arten von Diensten unterscheiden:zustandslos und zustandsbehaftet. Zustandslose Dienste sind diejenigen, die sich nicht auf vorhandene Daten verlassen. Sie können einfach loslegen, einen solchen Dienst starten und es wird glücklicherweise einfach funktionieren. Sie müssen sich weder um den Zustand der Daten noch um den Dienst kümmern. Wenn es funktioniert, funktioniert es ordnungsgemäß und Sie können den Datenverkehr problemlos auf mehrere Dienstinstanzen verteilen, indem Sie einfach weitere Klone oder Kopien vorhandener VMs, Container oder ähnliches hinzufügen. Ein Beispiel für einen solchen Dienst kann eine Webanwendung sein – die aus dem Repo bereitgestellt wird und über einen ordnungsgemäß konfigurierten Webserver verfügt. Ein solcher Dienst wird einfach gestartet und funktioniert ordnungsgemäß.
Das Problem mit Datenbanken ist, dass die Datenbank alles andere als zustandslos ist. Daten müssen in die Datenbank eingefügt, verarbeitet und persistiert werden. Das Image der Datenbank ist nichts weiter als ein paar Pakete, die über dem Betriebssystem-Image installiert werden, und ohne Daten und ordnungsgemäße Konfiguration ist es ziemlich nutzlos. Dies erhöht die Komplexität der Datenbankskalierung. Bei zustandslosen Diensten müssen Sie sie nur bereitstellen und einige Loadbalancer konfigurieren, um neue Instanzen in die Arbeitslast aufzunehmen. Für Datenbanken, die die Datenbank bereitstellen, ist die Instanz nur der Ausgangspunkt. Weiter unten ist die Datenverwaltung – Sie müssen die Daten von Ihrer bestehenden Datenbankinstanz in die neue übertragen. Dies kann ein erheblicher Teil des Problems und der Zeit sein, die die neuen Instanzen benötigen, um mit der Verarbeitung des Datenverkehrs zu beginnen. Erst nachdem die Daten übertragen wurden, können wir die neuen Knoten so einrichten, dass sie Teil der bestehenden Replikationstopologie werden – die Daten müssen auf ihnen in Echtzeit aktualisiert werden, basierend auf dem Datenverkehr, der andere Knoten erreicht.
Zum Hochskalieren benötigte Zeit
Die Tatsache, dass Datenbanken zustandsbehaftete Dienste sind, ist ein direkter Grund für die zweite Herausforderung, der wir gegenüberstehen, wenn wir die Datenbankinfrastruktur skalieren wollen. Zustandslose Dienste - Sie starten sie einfach und das war's. Es ist ein ziemlich schneller Prozess. Bei Datenbanken müssen Sie die Daten übertragen. Wie lange es dauern wird, hängt von mehreren Faktoren ab. Wie groß ist der Datensatz? Wie schnell ist die Speicherung? Wie schnell ist das Netzwerk? Welche weiteren Schritte sind erforderlich, um den neuen Knoten mit den neuen Daten bereitzustellen? Werden dabei Daten komprimiert/dekomprimiert oder verschlüsselt/entschlüsselt? In der realen Welt kann es Minuten bis mehrere Stunden dauern, die Daten auf einem neuen Knoten bereitzustellen. Dies schränkt die Fälle, in denen Sie Ihre Datenbankumgebung skalieren können, erheblich ein. Plötzliche, vorübergehende Lastspitzen? Nicht wirklich, sie sind möglicherweise schon lange weg, bevor Sie weitere Datenbankknoten starten können. Plötzlicher und stetiger Lastanstieg? Ja, es wird möglich sein, damit umzugehen, indem man weitere Knoten hinzufügt, aber es kann sogar Stunden dauern, sie hochzufahren und sie den Datenverkehr von bestehenden Datenbankknoten übernehmen zu lassen.
Zusätzliche Belastung durch Scale-up-Prozess
Es ist sehr wichtig, im Hinterkopf zu behalten, dass die für die Skalierung erforderliche Zeit nur eine Seite des Problems ist. Die andere Seite ist die Belastung durch den Skalierungsprozess. Wie bereits erwähnt, müssen Sie den gesamten Datensatz auf neu hinzugefügte Knoten übertragen. Dies können Sie nicht ignorieren, schließlich kann es ein stundenlanger Prozess sein, die Daten von der Festplatte zu lesen, sie über das Netzwerk zu senden und an einem neuen Ort zu speichern. Wenn der Donor, der Knoten, von dem Sie die Daten lesen, überlastet ist, müssen Sie überlegen, wie er sich verhalten wird, wenn er gezwungen wird, zusätzliche schwere E/A-Aktivitäten durchzuführen. Wird Ihr Cluster in der Lage sein, eine zusätzliche Arbeitslast zu übernehmen, wenn er bereits unter starkem Druck steht und dünn gesät ist? Die Antwort ist möglicherweise nicht leicht zu bekommen, da die Last auf den Knoten in unterschiedlicher Form auftreten kann. CPU-gebundene Last ist das beste Szenario, da die E/A-Aktivität niedrig sein sollte und zusätzliche Festplattenoperationen verwaltbar sein sollten. I/O-gebundene Last hingegen kann die Datenübertragung erheblich verlangsamen und die Skalierbarkeit des Clusters ernsthaft beeinträchtigen.
Skalierung schreiben
Der zuvor erwähnte Scale-out-Prozess beschränkt sich weitgehend auf das Skalieren von Lesevorgängen. Es ist von größter Bedeutung zu verstehen, dass das Skalieren von Schreibvorgängen eine ganz andere Geschichte ist. Sie können Lesevorgänge skalieren, indem Sie einfach weitere Knoten hinzufügen und die Lesevorgänge auf mehr Backend-Knoten verteilen. Schreibvorgänge sind nicht so einfach zu skalieren. Zunächst einmal können Sie Schreibvorgänge nicht einfach so skalieren. Jeder Knoten, der den gesamten Datensatz enthält, muss offensichtlich alle Schreibvorgänge verarbeiten, die irgendwo im Cluster durchgeführt werden, da er nur durch Anwenden aller Änderungen auf den Datensatz die Konsistenz aufrechterhalten kann. Also, wenn Sie darüber nachdenken, egal wie Sie Ihren Cluster entwerfen und welche Technologie Sie verwenden, jedes Mitglied des Clusters muss jeden Schreibvorgang ausführen. Unabhängig davon, ob es sich um ein Replikat handelt, das alle Schreibvorgänge von seinem Master oder Knoten in einem Multi-Master-Cluster wie Galera oder InnoDB Cluster repliziert und alle Änderungen am Datensatz ausführt, die auf allen anderen Knoten des Clusters durchgeführt werden, das Ergebnis ist dasselbe. Schreibvorgänge werden nicht skaliert, indem einfach weitere Knoten zum Cluster hinzugefügt werden.
Wie können wir die Datenbank skalieren?
Wir wissen also, vor welchen Herausforderungen wir stehen. Welche Möglichkeiten haben wir? Wie können wir die Datenbank skalieren?
Durch Hinzufügen von Repliken
In erster Linie skalieren wir einfach durch Hinzufügen weiterer Knoten. Sicher, es wird Zeit brauchen und sicher, es ist kein Prozess, von dem Sie erwarten können, dass er sofort passiert. Sicher, Sie werden solche Schreibvorgänge nicht skalieren können. Andererseits ist das typischste Problem, mit dem Sie konfrontiert werden, die CPU-Last, die durch SELECT-Abfragen verursacht wird, und wie wir besprochen haben, können Lesevorgänge einfach skaliert werden, indem Sie einfach mehr Knoten zum Cluster hinzufügen. Mehr Knoten, von denen gelesen werden kann, bedeutet, dass die Last auf jedem von ihnen reduziert wird. Wenn Sie am Anfang Ihrer Reise in den Lebenszyklus Ihrer Anwendung stehen, gehen Sie einfach davon aus, dass Sie sich damit befassen werden. CPU-Last, nicht effiziente Abfragen. Es ist sehr unwahrscheinlich, dass Sie Schreibvorgänge bis zu einem viel späteren Zeitpunkt im Lebenszyklus skalieren müssen, wenn Ihre Anwendung bereits ausgereift ist und Sie mit der Anzahl von Kunden fertig werden müssen.
Durch Sharding
Das Hinzufügen von Knoten wird das Schreibproblem nicht lösen, das haben wir festgestellt. Was Sie stattdessen tun müssen, ist Sharding – das Aufteilen des Datensatzes über den Cluster. In diesem Fall enthält jeder Knoten nur einen Teil der Daten, nicht alle. Dadurch können wir endlich mit der Skalierung von Schreibvorgängen beginnen. Nehmen wir an, wir haben vier Knoten, die jeweils die Hälfte des Datensatzes enthalten.
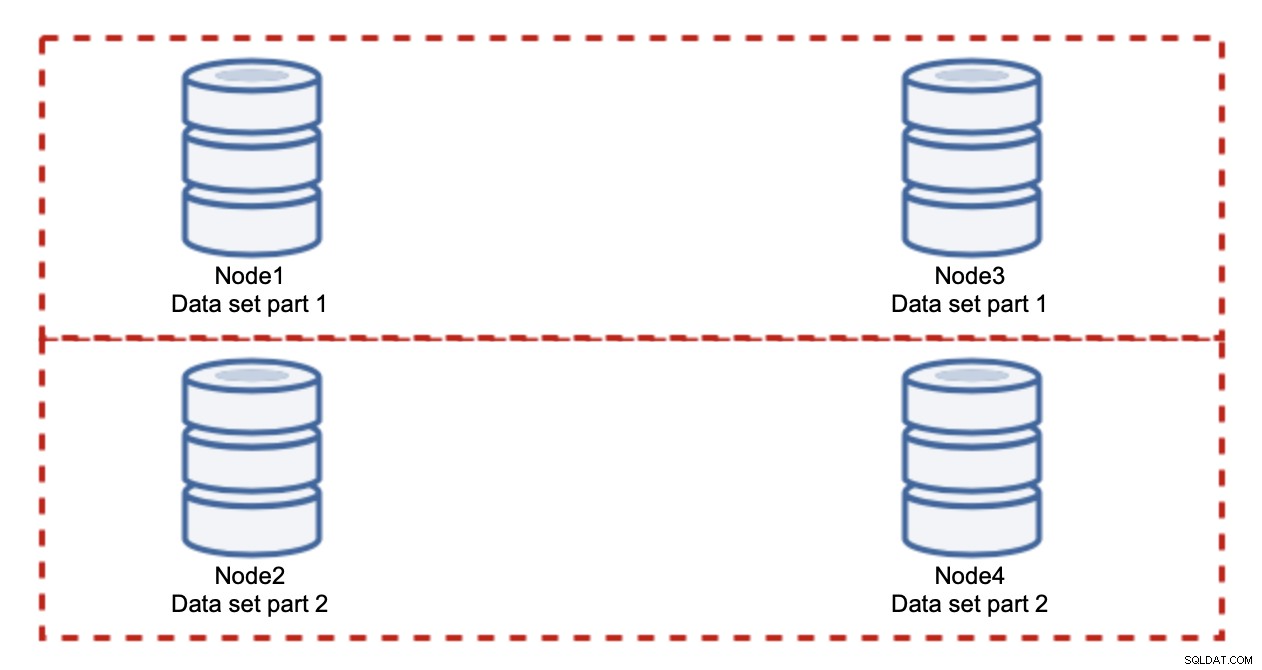
Wie Sie sehen können, ist die Idee einfach. Wenn sich der Schreibvorgang auf Teil 1 des Datensatzes bezieht, wird er auf Knoten1 und Knoten3 ausgeführt. Wenn es sich auf Teil 2 des Datensatzes bezieht, wird es auf Knoten2 und Knoten4 ausgeführt. Sie können sich die Datenbankknoten als Festplatten in einem RAID vorstellen. Hier haben wir ein Beispiel für RAID10, zwei Spiegelpaare, für Redundanz. In der realen Implementierung kann es komplexer sein, Sie haben möglicherweise mehr als eine Replik der Daten für eine verbesserte Hochverfügbarkeit. Das Wesentliche ist, dass unter der Annahme einer vollkommen fairen Aufteilung der Daten die Hälfte der Schreibvorgänge auf Knoten 1 und Knoten 3 und die andere Hälfte auf Knoten 2 und 4 trifft. Wenn Sie die Last noch weiter aufteilen möchten, können Sie das dritte Knotenpaar einführen:
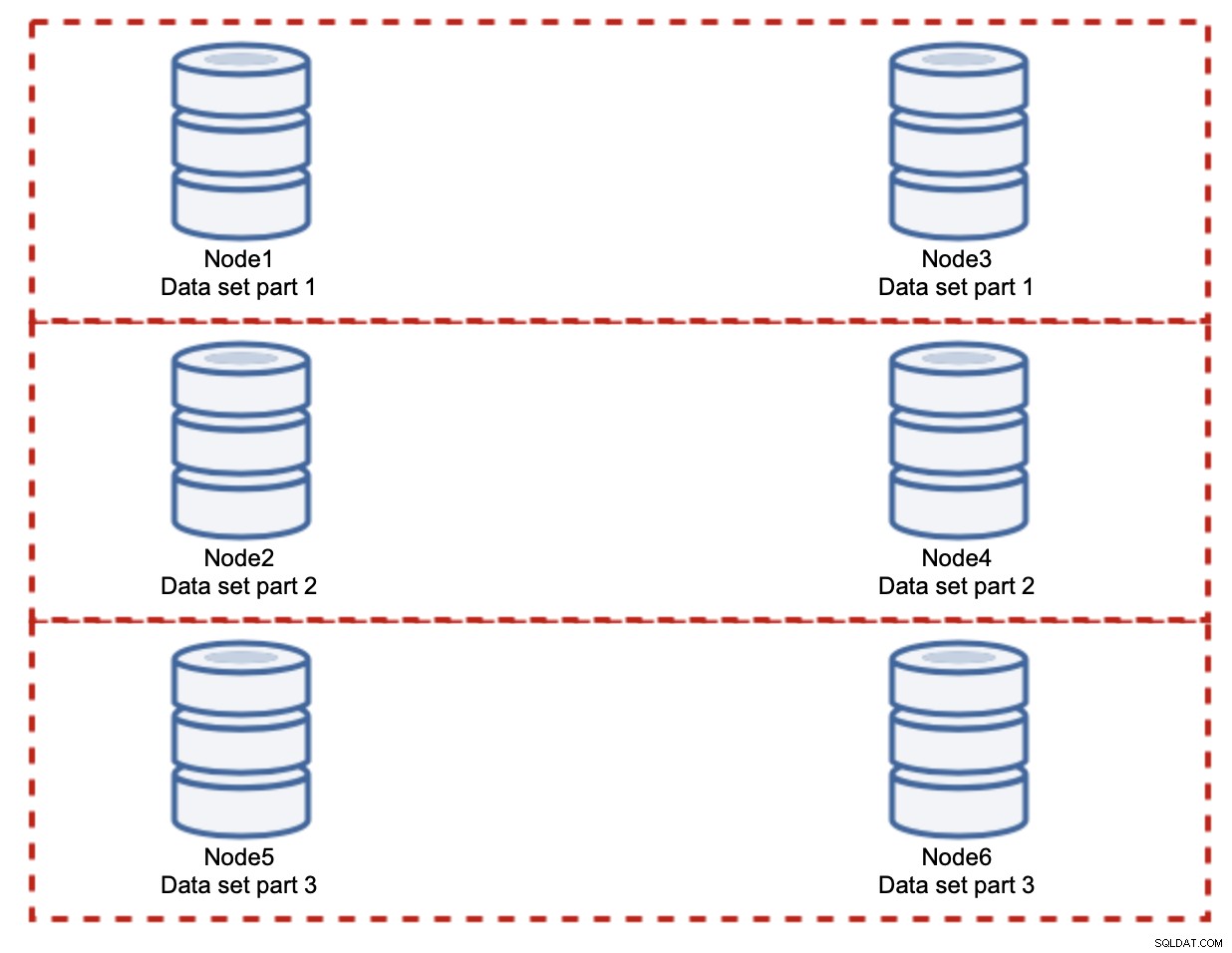
Auch in diesem Fall, unter der Annahme einer vollkommen fairen Aufteilung, wird jedes Paar dies tun für 33 % aller Schreibvorgänge im Cluster verantwortlich sein.
Das fasst die Idee des Sharding ziemlich gut zusammen. In unserem Beispiel können wir durch Hinzufügen weiterer Shards die Schreibaktivität auf den Datenbankknoten auf 33 % der ursprünglichen E/A-Last reduzieren. Wie Sie sich vorstellen können, ist dies nicht ohne Nachteile.
Wie finde ich heraus, auf welchem Shard sich meine Daten befinden? Details sind nicht Gegenstand dieses Aufrufs, aber kurz gesagt, Sie können entweder eine Art Funktion für eine bestimmte Spalte implementieren (Modulo oder Hash für die Spalte „id“) oder eine separate Metadatenbank erstellen, in der Sie die Details speichern wie die Daten verteilt werden.
Wir hoffen, dass Sie diese kurze Blog-Serie informativ fanden und dass Sie ein besseres Verständnis für die verschiedenen Herausforderungen bekommen haben, denen wir gegenüberstehen, wenn wir die Datenbankumgebung skalieren wollen. Wenn Sie Kommentare oder Vorschläge zu diesem Thema haben, können Sie diese gerne unter diesem Beitrag kommentieren und Ihre Erfahrungen teilen