Hässlich. So sehen unsortierte Daten aus. Wir machen Daten für die Augen einfach, indem wir sie sortieren. Und dafür ist SQL ORDER BY da. Verwenden Sie eine oder mehrere Spalten oder Ausdrücke als Grundlage zum Sortieren von Daten. Fügen Sie dann ASC oder DESC hinzu, um aufsteigend oder absteigend zu sortieren.
Die SQL ORDER BY-Syntax:
ORDER BY <order_by_expression> [ASC | DESC]
Der ORDER BY-Ausdruck kann so einfach wie eine Liste von Spalten oder Ausdrücken sein. Es kann auch mit einem CASE WHEN-Block bedingt sein.
Es ist sehr flexibel.
Sie können auch Paging durch OFFSET und FETCH verwenden. Geben Sie die Anzahl der zu überspringenden Zeilen und die anzuzeigenden Zeilen an.
Aber hier sind die schlechten Nachrichten.
Das Hinzufügen von ORDER BY zu Ihren Abfragen kann sie verlangsamen. Und einige andere Vorbehalte können dazu führen, dass ORDER BY „nicht funktioniert“. Sie können sie nicht einfach verwenden, wann immer Sie wollen, da es Strafen geben kann. Also, was machen wir?
In diesem Artikel werden wir die Gebote und Verbote bei der Verwendung von ORDER BY untersuchen. Jeder Punkt behandelt ein Problem und es folgt eine Lösung.
Bereit?
Do’s in SQL ORDER BY
1. Indizieren Sie die SQL ORDER BY-Spalte(n)
Bei Indizes dreht sich alles um schnelle Suchen. Und eine in den Spalten zu haben, die Sie in der ORDER BY-Klausel verwenden, kann Ihre Abfrage beschleunigen.
Beginnen wir mit der Verwendung von ORDER BY in einer Spalte ohne Index. Wir werden AdventureWorks verwenden Musterdatenbank. Bevor Sie die folgende Abfrage ausführen, deaktivieren Sie die IX_SalesOrderDetail_ProductID Index im SalesOrderDetail Tisch. Drücken Sie dann Strg-M und führen Sie es aus.
-- Get order details by product and sort them by ProductID
USE AdventureWorks
GO
SET STATISTICS IO ON
GO
SELECT
ProductID
,OrderQty
,UnitPrice
,LineTotal
FROM Sales.SalesOrderDetail
ORDER BY ProductID
SET STATISTICS IO OFF
GO
ANALYSE
Der obige Code gibt die E/A-Statistiken auf der Registerkarte „Meldungen“ von SQL Server Management Studio aus. Sie sehen den Ausführungsplan auf einer anderen Registerkarte.
OHNE INDEX
Lassen Sie uns zuerst die logischen Lesevorgänge von STATISTICS IO abrufen. Sehen Sie sich Abbildung 1 an.
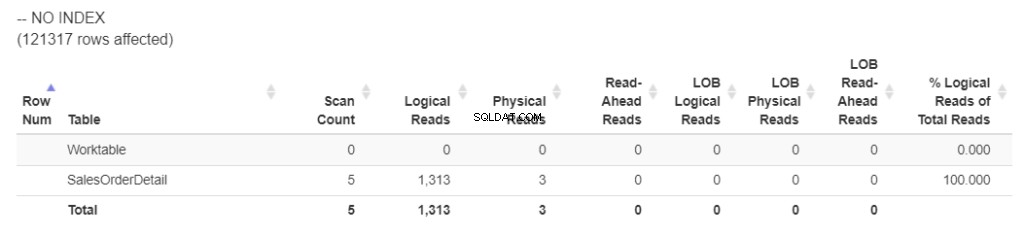
Abbildung 1 . Logische Lesevorgänge mit ORDER BY einer nicht indizierten Spalte. (Formatiert mit statisticsparser.com )
Ohne den Index verwendete die Abfrage 1.313 logische Lesevorgänge. Und dieser Arbeitstisch ? Das bedeutet, dass SQL Server TempDB verwendet hat um die Sortierung zu verarbeiten.
Aber was geschah hinter den Kulissen? Sehen wir uns den Ausführungsplan in Abbildung 2 an.
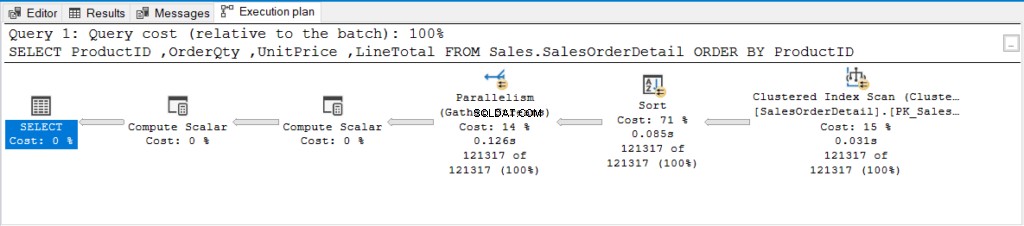
Abbildung 2 . Ausführungsplan einer Abfrage mit ORDER BY einer nicht indizierten Spalte.
Haben Sie den Parallelism (Streams sammeln)-Operator gesehen? Dies bedeutet, dass SQL Server mehr als einen Prozessor verwendet hat, um diese Abfrage zu verarbeiten. Die Abfrage war schwer genug, um mehr CPUs zu erfordern.
Was wäre also, wenn SQL Server TempDB verwenden würde und mehr Prozessoren? Es ist schlecht für eine einfache Abfrage.
MIT EINEM INDEX
Wie wird es weitergehen, wenn der Index wieder aktiviert wird? Lass es uns herausfinden. Erstellen Sie den Index IX_SalesOrderDetail_ProductID neu . Führen Sie dann die obige Abfrage erneut aus.
Überprüfen Sie die neuen logischen Lesevorgänge in Abbildung 3.
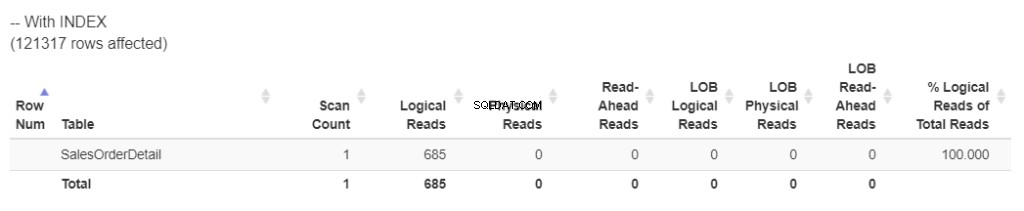
Abbildung 3 . Neue logische Lesevorgänge nach dem Neuaufbau des Index.
Das ist viel besser. Wir haben die Anzahl der logischen Lesevorgänge um fast die Hälfte reduziert. Das bedeutet, dass der Index dafür sorgt, dass weniger Ressourcen verbraucht werden. Und der Arbeitstisch ? Es ist weg! TempDB muss nicht verwendet werden .
Und der Ausführungsplan? Siehe Abbildung 4.
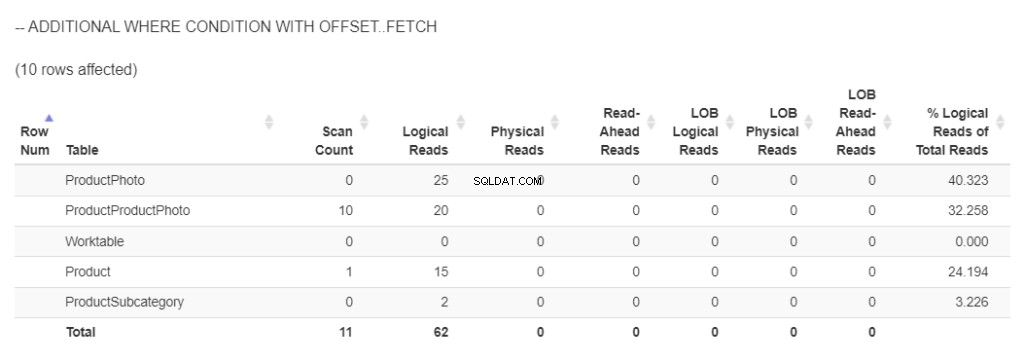
Abbildung 4 . Der neue Ausführungsplan ist einfacher, wenn der Index neu erstellt wurde.
Sehen? Der Plan ist einfacher. Es sind keine zusätzlichen CPUs erforderlich, um dieselben 121.317 Zeilen zu sortieren.
Das Fazit lautet also:Stellen Sie sicher, dass die Spalten, die Sie für ORDER BY verwenden, indexiert sind .
ABER WAS IST, WENN DAS HINZUFÜGEN EINES INDEX DIE SCHREIBLEISTUNG AUSWIRKT?
Gute Frage.
Wenn das das Problem ist, können Sie einen Teil der Quelltabelle in eine temporäre Tabelle oder eine speicheroptimierte Tabelle ausgeben . Indizieren Sie dann diese Tabelle. Verwenden Sie dasselbe, wenn mehr Tabellen beteiligt sind. Bewerten Sie dann die Abfrageleistung der ausgewählten Option. Die schnellere Option gewinnt.
2. Begrenzen Sie die Ergebnisse mit WHERE und OFFSET/FETCH
Lassen Sie uns eine andere Abfrage verwenden. Angenommen, Sie müssen Produktinformationen mit Bildern in einer App anzeigen. Bilder können Abfragen noch schwerer machen. Wir prüfen also nicht nur logische Lesevorgänge, sondern loben auch logische Lesevorgänge.
Hier ist der Code.
SET STATISTICS IO ON
GO
SELECT
a.ProductID
,a.Name AS ProductName
,a.ListPrice
,a.Color
,b.Name AS ProductSubcategory
,d.ThumbNailPhoto
,d.LargePhoto
FROM Production.Product a
INNER JOIN Production.ProductSubcategory b ON a.ProductSubcategoryID = b.ProductSubcategoryID
INNER JOIN Production.ProductProductPhoto c ON a.ProductID = c.ProductID
INNER JOIN Production.ProductPhoto d ON c.ProductPhotoID = d.ProductPhotoID
WHERE b.ProductCategoryID = 1 -- Bikes
ORDER BY ProductSubcategory, ProductName, a.Color
SET STATISTICS IO OFF
GO
Dadurch werden 97 Fahrräder mit Bildern ausgegeben. Sie sind auf einem mobilen Gerät sehr schwer zu durchsuchen.
ANALYSE
VERWENDUNG DER MINIMAL-WHERE-BEDINGUNG OHNE OFFSET/FETCH
So viele logische Lesevorgänge sind erforderlich, um 97 Produkte mit Bildern abzurufen. Siehe Abbildung 5.
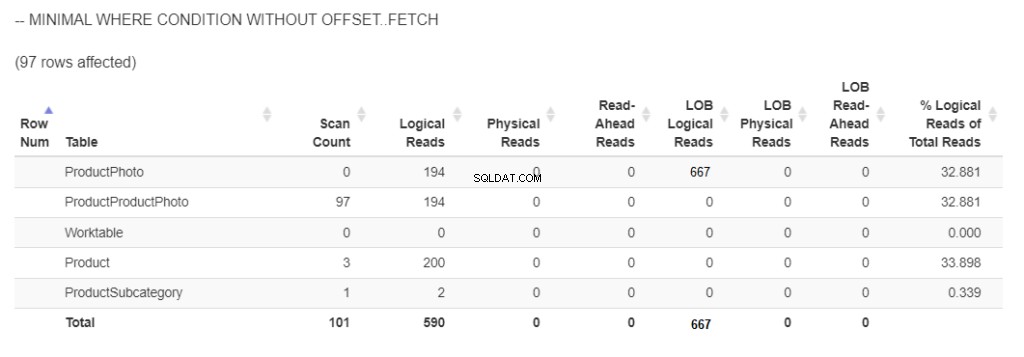
Abbildung 5 . Die logischen Lesevorgänge und logischen Lob-Lesevorgänge bei Verwendung von ORDER BY ohne OFFSET/FETCH und mit minimaler WHERE-Bedingung . (Hinweis:statisticsparser.com hat die logischen Lob-Lesevorgänge nicht angezeigt. Der Screenshot wird basierend auf dem Ergebnis in SSMS) bearbeitet
667 logische Lob-Lesevorgänge wurden angezeigt, weil Bilder in 2 Spalten abgerufen wurden. Für den Rest wurden 590 logische Lesevorgänge verwendet.
Hier ist der Ausführungsplan in Abbildung 6, damit wir ihn später mit dem besseren Plan vergleichen können.
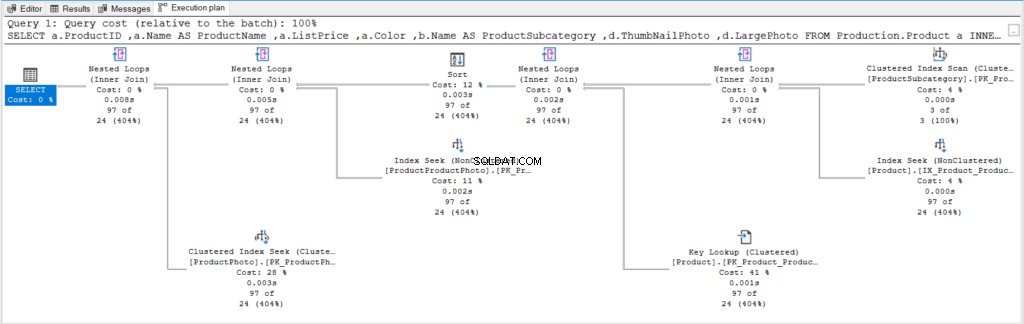
Abbildung 6 . Ausführungsplan mit ORDER BY ohne OFFSET/FETCH und mit minimaler WHERE-Bedingung.
Es gibt nicht viel mehr zu sagen, bis wir den anderen Ausführungsplan sehen.
VERWENDUNG ZUSÄTZLICHER WHERE-BEDINGUNGEN UND OFFSET/FETCH IN ORDER BY
Passen wir nun die Abfrage an, um sicherzustellen, dass nur minimale Daten zurückgegeben werden. Folgendes werden wir tun:
- Fügen Sie eine Bedingung für die Produktunterkategorie hinzu. In der aufrufenden App können wir uns vorstellen, den Nutzer auch die Unterkategorie wählen zu lassen.
- Entfernen Sie dann die Produktunterkategorie in der SELECT-Spaltenliste und der ORDER BY-Spaltenliste.
- Fügen Sie schließlich OFFSET/FETCH in ORDER BY hinzu. Nur 10 Produkte werden retourniert und in der aufrufenden App angezeigt.
Hier ist der bearbeitete Code.
DECLARE @pageNumber TINYINT = 1
DECLARE @noOfRows TINYINT = 10 -- each page will display 10 products at a time
SELECT
a.ProductID
,a.Name AS ProductName
,a.ListPrice
,a.Color
,d.ThumbNailPhoto
FROM Production.Product a
INNER JOIN Production.ProductSubcategory b ON a.ProductSubcategoryID = b.ProductSubcategoryID
INNER JOIN Production.ProductProductPhoto c ON a.ProductID = c.ProductID
INNER JOIN Production.ProductPhoto d ON c.ProductPhotoID = d.ProductPhotoID
WHERE b.ProductCategoryID = 1 -- Bikes
AND a.ProductSubcategoryID = 2 -- Road Bikes
ORDER BY ProductName, a.Color
OFFSET (@pageNumber-1)*@noOfRows ROWS FETCH NEXT @noOfRows ROWS ONLY
Dieser Code wird weiter verbessert, wenn Sie ihn in eine gespeicherte Prozedur umwandeln. Es wird auch Parameter wie Seitenzahl und Anzahl der Zeilen haben. Die Seitennummer gibt an, welche Seite der Benutzer gerade betrachtet. Verbessern Sie dies weiter, indem Sie die Anzahl der Zeilen je nach Bildschirmauflösung flexibel gestalten. Aber das ist eine andere Geschichte.
Sehen wir uns nun die logischen Lesevorgänge in Abbildung 7 an.
Abbildung 7 . Weniger logische Lesevorgänge nach der Vereinfachung der Abfrage. OFFSET/FETCH wird auch in ORDER BY verwendet.
Vergleichen Sie dann Abbildung 7 mit Abbildung 5. Die logischen Lob-Lesevorgänge sind weg. Darüber hinaus sind die logischen Lesevorgänge deutlich zurückgegangen, da die Ergebnismenge ebenfalls von 97 auf 10 verringert wurde.
Aber was hat SQL Server hinter den Kulissen getan? Sehen Sie sich den Ausführungsplan in Abbildung 8 an.
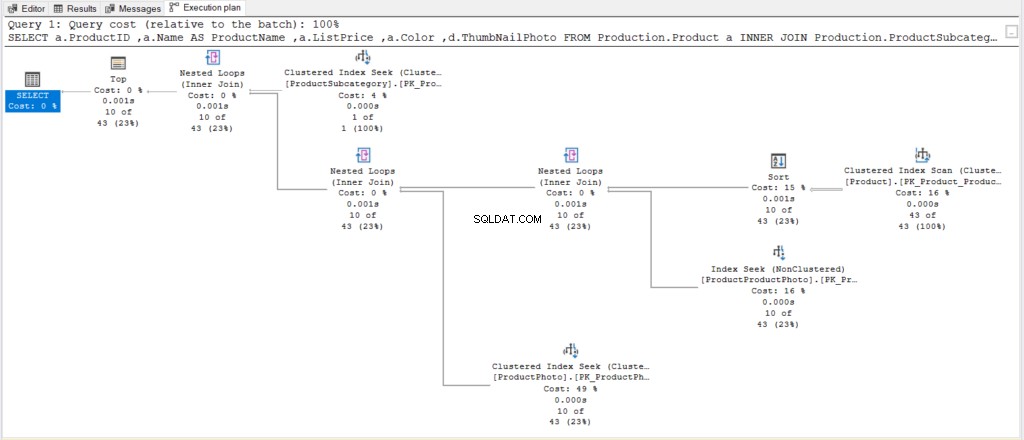
Abbildung 8 . Ein einfacherer Ausführungsplan nach der Vereinfachung der Abfrage und dem Hinzufügen von OFFSET/FETCH in ORDER BY.
Vergleichen Sie dann Abbildung 8 mit Abbildung 6. Ohne die einzelnen Operatoren zu untersuchen, können wir sehen, dass dieser neue Plan einfacher ist als der vorherige.
Der Unterricht? Vereinfachen Sie Ihre Abfrage. Verwenden Sie wann immer möglich OFFSET/FETCH.
Don’ts in SQL ORDER BY
Wir sind mit dem fertig, was wir tun müssen, wenn wir ORDER BY verwenden. Konzentrieren wir uns dieses Mal auf das, was wir vermeiden sollten.
3. Verwenden Sie ORDER BY nicht, wenn Sie nach dem Clustered-Index-Schlüssel sortieren
Weil es nutzlos ist.
Lassen Sie es uns anhand eines Beispiels zeigen.
SET STATISTICS IO ON
GO
-- Using ORDER BY with BusinessEntityID - the primary key
SELECT TOP 100 * FROM Person.Person
ORDER BY BusinessEntityID;
-- Without using ORDER BY at all
SELECT TOP 100 * FROM Person.Person;
SET STATISTICS IO OFF
GO
Lassen Sie uns dann die logischen Lesevorgänge beider SELECT-Anweisungen in Abbildung 9 überprüfen.
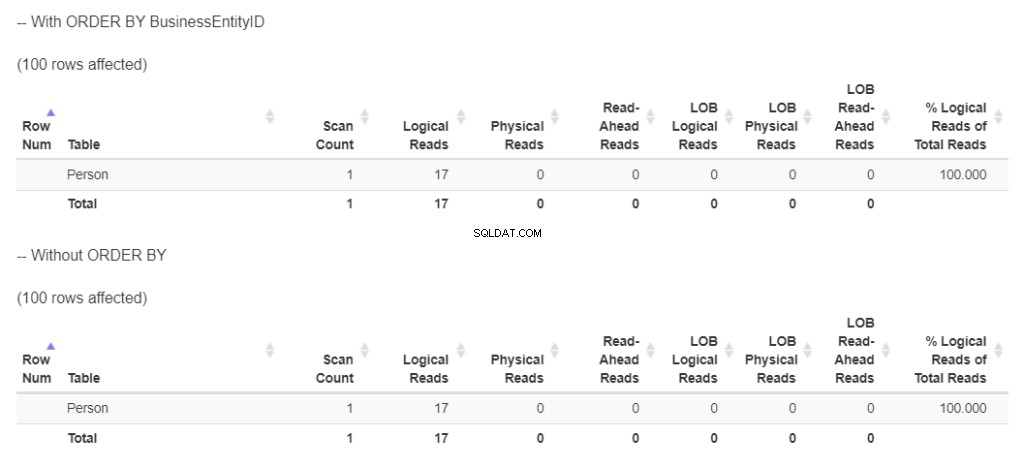
Abbildung 9 . 2 Abfragen der Person-Tabelle zeigen die gleichen logischen Lesevorgänge. Einer ist mit ORDER BY, ein anderer ohne.
Beide haben 17 logische Lesevorgänge. Dies ist logisch, da dieselben 100 Zeilen zurückgegeben werden. Aber haben sie den gleichen Plan? Sehen Sie sich Abbildung 10 an.
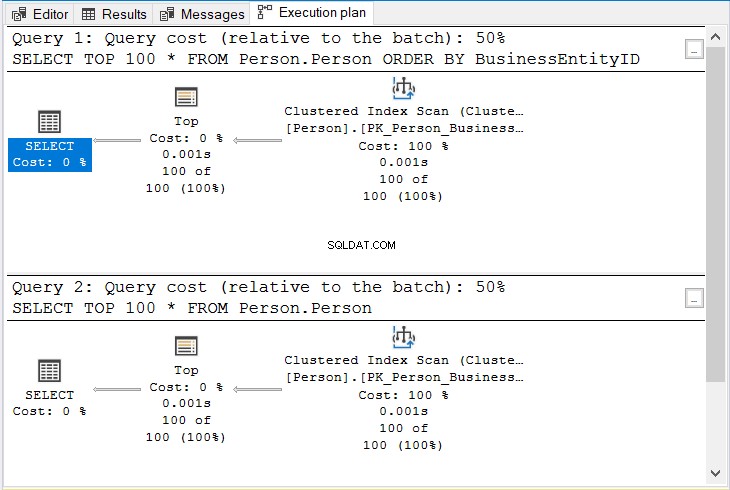
Abbildung 10 . Derselbe Plan, ob ORDER BY verwendet wird oder nicht, wenn nach dem Clustered-Index-Schlüssel sortiert wird.
Beachten Sie die gleichen Operatoren und die gleichen Abfragekosten.
Aber warum? Beim Indizieren einer oder mehrerer Spalten in einem Clustered-Index wird die Tabelle physisch sortiert durch den gruppierten Indexschlüssel. Auch wenn Sie also nicht nach diesem Schlüssel sortieren, wird das Ergebnis dennoch sortiert.
Endeffekt? Verzeihen Sie sich, indem Sie den Clustered-Index-Schlüssel in ähnlichen Fällen nicht mit ORDER BY verwenden . Sparen Sie Energie mit weniger Tastenanschlägen.
4. Verwenden Sie ORDER BY nicht, wenn eine String-Spalte Zahlen enthält
Wenn Sie nach einer Zeichenfolgenspalte sortieren, die Zahlen enthält, erwarten Sie keine Sortierreihenfolge wie bei Typen mit reellen Zahlen. Andernfalls erwartet Sie eine große Überraschung.
Hier ist ein Beispiel.
SELECT
NationalIDNumber
,JobTitle
,HireDate
FROM HumanResources.Employee
ORDER BY NationalIDNumber;
Überprüfen Sie die Ausgabe in Abbildung 11.
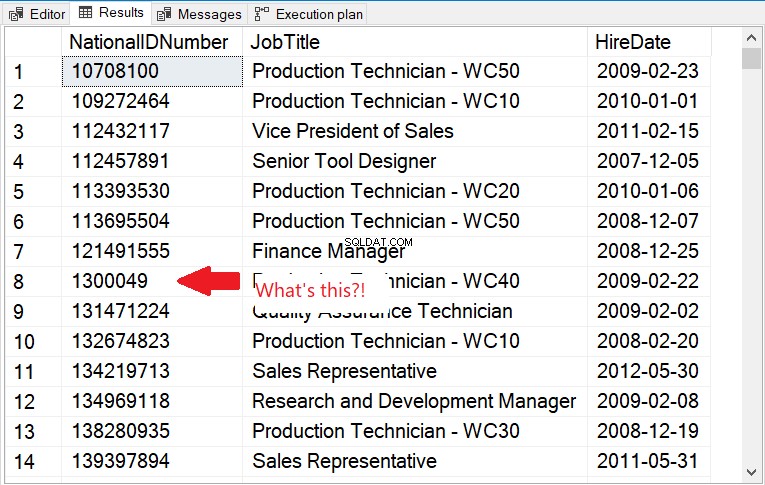
Abbildung 11 . Sortierreihenfolge einer Zeichenfolgenspalte, die Zahlen enthält. Dem Zahlenwert wird nicht gefolgt.
In Abbildung 11 wird die lexikografische Sortierreihenfolge befolgt. Um dies zu beheben, verwenden Sie also einen CAST in eine Ganzzahl.
SELECT
NationalIDNumber
,JobTitle
,HireDate
FROM HumanResources.Employee
ORDER BY CAST(NationalIDNumber AS INT)
Sehen Sie sich Abbildung 12 für die feste Ausgabe an.
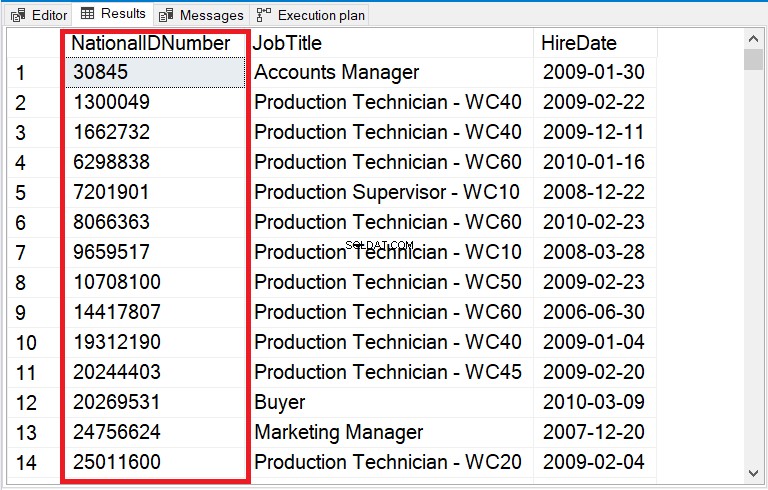
Abbildung 12 . CAST to INT hat die Sortierung einer Zeichenfolgenspalte mit Zahlen korrigiert.
Verwenden Sie also statt ORDER BY
5. Verwenden Sie SELECT INTO #TempTable nicht mit ORDER BY
Ihre gewünschte Sortierreihenfolge wird in der temporären Zieltabelle nicht garantiert. Siehe die offizielle Dokumentation .
Nehmen wir einen modifizierten Code aus dem vorherigen Beispiel.
SELECT
NationalIDNumber
,JobTitle
,HireDate
INTO #temp
FROM HumanResources.Employee
ORDER BY CAST(NationalIDNumber AS INT);
SELECT * FROM #temp;
Der einzige Unterschied zum vorherigen Beispiel ist die INTO-Klausel. Die Ausgabe ist dieselbe wie in Abbildung 11. Wir befinden uns wieder auf Feld 1, selbst wenn wir die Spalte in INT umwandeln.
Sie müssen eine temporäre Tabelle mit CREATE TABLE erstellen. Fügen Sie jedoch eine zusätzliche Identitätsspalte hinzu und machen Sie sie zu einem Primärschlüssel. Dann INSERT in die temporäre Tabelle.
Hier ist der feste Code.
CREATE TABLE #temp2
(
id INT IDENTITY(1,1) NOT NULL PRIMARY KEY,
NationalIDNumber NVARCHAR(15) NOT NULL,
JobTitle NVARCHAR(50) NOT NULL,
HireDate DATE NOT NULL
)
GO
INSERT INTO #temp2
(NationalIDNumber, JobTitle, HireDate)
SELECT
NationalIDNumber
,JobTitle
,HireDate
FROM HumanResources.Employee
ORDER BY CAST(NationalIDNumber AS INT);
SELECT
NationalIDNumber
,JobTitle
,HireDate
FROM #Temp2;
Und die Ausgabe ist dieselbe wie in Abbildung 12. Es funktioniert!
Takeaways bei der Verwendung von SQL ORDER BY
Wir haben die häufigsten Fallstricke bei der Verwendung von SQL ORDER BY behandelt. Hier ist eine Zusammenfassung:
Dos :
- Indizieren Sie die ORDER BY-Spalten
- Begrenzen Sie die Ergebnisse mit WHERE und OFFSET/FETCH,
Don’ts :
- Verwenden Sie ORDER BY nicht, wenn Sie nach dem Clustered-Index-Schlüssel sortieren,
- Verwenden Sie ORDER BY nicht, wenn eine Zeichenfolgenspalte Zahlen enthält. CAST die String-Spalte stattdessen zuerst in INT.
- Verwenden Sie SELECT INTO #TempTable nicht mit ORDER BY. Erstellen Sie stattdessen zuerst die temporäre Tabelle mit einer zusätzlichen Identitätsspalte.
Was sind Ihre Tipps und Tricks bei der Verwendung von ORDER BY? Lassen Sie es uns im Kommentarbereich unten wissen. Und wenn Ihnen dieser Beitrag gefällt, teilen Sie ihn bitte auf Ihren bevorzugten Social-Media-Plattformen.