Alle Softwareanwendungen interagieren mit Daten , am häufigsten über ein Datenbankverwaltungssystem (DBMS). Einige Programmiersprachen enthalten Module, die Sie verwenden können, um mit einem DBMS zu interagieren, während andere die Verwendung von Paketen von Drittanbietern erfordern. In diesem Tutorial lernen Sie die verschiedenen Python SQL-Bibliotheken kennen die Sie verwenden können. Sie entwickeln eine unkomplizierte Anwendung zur Interaktion mit SQLite-, MySQL- und PostgreSQL-Datenbanken.
In diesem Tutorial erfahren Sie, wie Sie:
- Verbinden an verschiedene Datenbankverwaltungssysteme mit Python-SQL-Bibliotheken
- Interagieren mit SQLite-, MySQL- und PostgreSQL-Datenbanken
- Aufführen allgemeine Datenbankabfragen mit einer Python-Anwendung
- Entwickeln Anwendungen über verschiedene Datenbanken hinweg mit einem Python-Skript
Um dieses Lernprogramm optimal nutzen zu können, sollten Sie über grundlegende Kenntnisse in Python, SQL und der Arbeit mit Datenbankverwaltungssystemen verfügen. Sie sollten auch in der Lage sein, Pakete in Python herunterzuladen und zu importieren, und wissen, wie Sie verschiedene Datenbankserver lokal oder remote installieren und ausführen.
Kostenloser PDF-Download: Python 3-Spickzettel
Das Datenbankschema verstehen
In diesem Lernprogramm entwickeln Sie eine sehr kleine Datenbank für eine Social-Media-Anwendung. Die Datenbank wird aus vier Tabellen bestehen:
userspostscommentslikes
Ein allgemeines Diagramm des Datenbankschemas ist unten dargestellt:
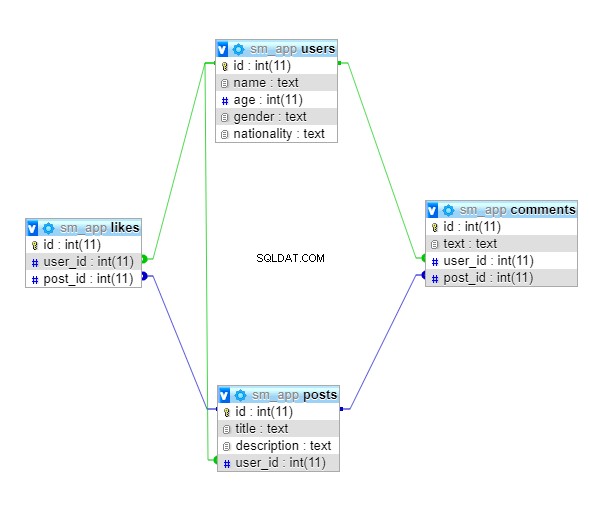
Beide users und posts wird eine Eins-zu-Viele-Beziehung haben, da ein Benutzer viele Beiträge mögen kann. Ebenso kann ein Benutzer viele Kommentare posten, und ein Beitrag kann auch mehrere Kommentare enthalten. Also beide users und posts wird auch Eins-zu-Viele-Beziehungen mit den comments haben Tisch. Dies gilt auch für die likes Tabelle, also beide users und posts wird eine Eins-zu-Viele-Beziehung mit den likes haben Tabelle.
Verwendung von Python SQL-Bibliotheken zur Verbindung mit einer Datenbank
Bevor Sie mit einer Datenbank über eine Python-SQL-Bibliothek interagieren, müssen Sie eine Verbindung herstellen zu dieser Datenbank. In diesem Abschnitt erfahren Sie, wie Sie von einer Python-Anwendung aus eine Verbindung zu SQLite-, MySQL- und PostgreSQL-Datenbanken herstellen.
Hinweis: Sie müssen MySQL- und PostgreSQL-Server betriebsbereit haben, bevor Sie die Skripts in den MySQL- und PostgreSQL-Datenbankabschnitten ausführen. Eine kurze Einführung zum Starten eines MySQL-Servers finden Sie im MySQL-Abschnitt von Starten eines Django-Projekts. Um zu erfahren, wie Sie eine Datenbank in PostgreSQL erstellen, sehen Sie sich den Abschnitt Einrichten einer Datenbank von SQL-Injection-Angriffe mit Python verhindern an.
Es wird empfohlen, dass Sie drei verschiedene Python-Dateien erstellen, sodass Sie für jede der drei Datenbanken eine haben. Sie führen das Skript für jede Datenbank in der entsprechenden Datei aus.
SQLite
SQLite ist wahrscheinlich die einfachste Datenbank, mit der Sie sich mit einer Python-Anwendung verbinden können, da Sie dafür keine externen Python-SQL-Module installieren müssen. Standardmäßig enthält Ihre Python-Installation eine Python-SQL-Bibliothek mit dem Namen sqlite3 die Sie verwenden können, um mit einer SQLite-Datenbank zu interagieren.
Darüber hinaus sind SQLite-Datenbanken serverlos und eigenständig , da sie Daten in eine Datei lesen und schreiben. Das bedeutet, dass Sie im Gegensatz zu MySQL und PostgreSQL nicht einmal einen SQLite-Server installieren und ausführen müssen, um Datenbankoperationen durchzuführen!
So verwenden Sie sqlite3 um eine Verbindung zu einer SQLite-Datenbank in Python herzustellen:
1import sqlite3
2from sqlite3 import Error
3
4def create_connection(path):
5 connection = None
6 try:
7 connection = sqlite3.connect(path)
8 print("Connection to SQLite DB successful")
9 except Error as e:
10 print(f"The error '{e}' occurred")
11
12 return connection
So funktioniert dieser Code:
- Zeile 1 und 2 importiere
sqlite3und denErrordes Moduls Klasse. - Zeile 4 definiert eine Funktion
.create_connection()die den Pfad zur SQLite-Datenbank akzeptiert. - Zeile 7 verwendet
.connect()aussqlite3-Modul und nimmt den SQLite-Datenbankpfad als Parameter. Wenn die Datenbank am angegebenen Ort vorhanden ist, wird eine Verbindung zur Datenbank hergestellt. Andernfalls wird am angegebenen Ort eine neue Datenbank erstellt und eine Verbindung hergestellt. - Zeile 8 gibt den Status der erfolgreichen Datenbankverbindung aus.
- Zeile 9 fängt jede Ausnahme ab, die ausgelöst werden könnte, wenn
.connect()kann keine Verbindung herstellen. - Zeile 10 zeigt die Fehlermeldung in der Konsole an.
sqlite3.connect(path) gibt eine connection zurück Objekt, das wiederum von create_connection() zurückgegeben wird . Diese connection -Objekt kann verwendet werden, um Abfragen in einer SQLite-Datenbank auszuführen. Das folgende Skript stellt eine Verbindung zur SQLite-Datenbank her:
connection = create_connection("E:\\sm_app.sqlite")
Sobald Sie das obige Skript ausführen, sehen Sie, dass eine Datenbankdatei sm_app.sqlite wird im Stammverzeichnis erstellt. Beachten Sie, dass Sie den Speicherort ändern können, um ihn an Ihre Einrichtung anzupassen.
MySQL
Im Gegensatz zu SQLite gibt es kein Standard-Python-SQL-Modul, mit dem Sie eine Verbindung zu einer MySQL-Datenbank herstellen können. Stattdessen müssen Sie einen Python SQL-Treiber installieren für MySQL, um aus einer Python-Anwendung heraus mit einer MySQL-Datenbank zu interagieren. Einer dieser Treiber ist mysql-connector-python . Sie können dieses Python-SQL-Modul mit pip herunterladen :
$ pip install mysql-connector-python
Beachten Sie, dass MySQL serverbasiert ist Datenbankverwaltungssystem. Ein MySQL-Server kann mehrere Datenbanken haben. Im Gegensatz zu SQLite, wo das Erstellen einer Verbindung gleichbedeutend mit dem Erstellen einer Datenbank ist, hat eine MySQL-Datenbank einen zweistufigen Prozess für die Datenbankerstellung:
- Stellen Sie eine Verbindung her zu einem MySQL-Server.
- Führen Sie eine separate Abfrage aus um die Datenbank zu erstellen.
Definieren Sie eine Funktion, die eine Verbindung zum MySQL-Datenbankserver herstellt und das Verbindungsobjekt zurückgibt:
1import mysql.connector
2from mysql.connector import Error
3
4def create_connection(host_name, user_name, user_password):
5 connection = None
6 try:
7 connection = mysql.connector.connect(
8 host=host_name,
9 user=user_name,
10 passwd=user_password
11 )
12 print("Connection to MySQL DB successful")
13 except Error as e:
14 print(f"The error '{e}' occurred")
15
16 return connection
17
18connection = create_connection("localhost", "root", "")
Im obigen Skript definieren Sie eine Funktion create_connection() die drei Parameter akzeptiert:
- Hostname
- Benutzername
- Benutzerpasswort
Der mysql.connector Das Python-SQL-Modul enthält eine Methode .connect() die Sie in Zeile 7 verwenden, um sich mit einem MySQL-Datenbankserver zu verbinden. Sobald die Verbindung hergestellt ist, wird die connection Objekt wird an die aufrufende Funktion zurückgegeben. Schließlich rufen Sie in Zeile 18 create_connection() auf mit dem Hostnamen, Benutzernamen und Passwort.
Bisher haben Sie nur die Verbindung hergestellt. Die Datenbank ist noch nicht erstellt. Dazu definieren Sie eine weitere Funktion create_database() die zwei Parameter akzeptiert:
connectionist dieconnectionObjekt an den Datenbankserver, mit dem Sie interagieren möchten.queryist die Abfrage, die die Datenbank erstellt.
So sieht diese Funktion aus:
def create_database(connection, query):
cursor = connection.cursor()
try:
cursor.execute(query)
print("Database created successfully")
except Error as e:
print(f"The error '{e}' occurred")
Um Abfragen auszuführen, verwenden Sie den cursor Objekt. Die query ausgeführt werden soll, wird an cursor.execute() übergeben im String-Format.
Erstellen Sie eine Datenbank namens sm_app für Ihre Social-Media-App im MySQL-Datenbankserver:
create_database_query = "CREATE DATABASE sm_app"
create_database(connection, create_database_query)
Jetzt haben Sie eine Datenbank sm_app erstellt auf dem Datenbankserver. Allerdings ist die connection Objekt, das von create_connection() zurückgegeben wird ist mit dem MySQL-Datenbankserver verbunden. Sie müssen sich mit der sm_app verbinden Datenbank. Dazu können Sie create_connection() ändern wie folgt:
1def create_connection(host_name, user_name, user_password, db_name):
2 connection = None
3 try:
4 connection = mysql.connector.connect(
5 host=host_name,
6 user=user_name,
7 passwd=user_password,
8 database=db_name
9 )
10 print("Connection to MySQL DB successful")
11 except Error as e:
12 print(f"The error '{e}' occurred")
13
14 return connection
Sie können in Zeile 8 sehen, dass create_connection() akzeptiert jetzt einen zusätzlichen Parameter namens db_name . Dieser Parameter gibt den Namen der Datenbank an, zu der Sie eine Verbindung herstellen möchten. Sie können den Namen der Datenbank übergeben, mit der Sie sich verbinden möchten, wenn Sie diese Funktion aufrufen:
connection = create_connection("localhost", "root", "", "sm_app")
Das obige Skript ruft erfolgreich create_connection() auf und verbindet sich mit der sm_app Datenbank.
PostgreSQL
Wie bei MySQL gibt es keine Standard-Python-SQL-Bibliothek, die Sie verwenden können, um mit einer PostgreSQL-Datenbank zu interagieren. Stattdessen müssen Sie einen Python SQL-Treiber eines Drittanbieters installieren um mit PostgreSQL zu interagieren. Ein solcher Python-SQL-Treiber für PostgreSQL ist psycopg2 . Führen Sie den folgenden Befehl auf Ihrem Terminal aus, um psycopg2 zu installieren Python-SQL-Modul:
$ pip install psycopg2
Wie bei den SQLite- und MySQL-Datenbanken definieren Sie create_connection() um eine Verbindung mit Ihrer PostgreSQL-Datenbank herzustellen:
import psycopg2
from psycopg2 import OperationalError
def create_connection(db_name, db_user, db_password, db_host, db_port):
connection = None
try:
connection = psycopg2.connect(
database=db_name,
user=db_user,
password=db_password,
host=db_host,
port=db_port,
)
print("Connection to PostgreSQL DB successful")
except OperationalError as e:
print(f"The error '{e}' occurred")
return connection
Sie verwenden psycopg2.connect() um von Ihrer Python-Anwendung aus eine Verbindung zu einem PostgreSQL-Server herzustellen.
Sie können dann create_connection() verwenden um eine Verbindung zu einer PostgreSQL-Datenbank herzustellen. Zuerst stellen Sie eine Verbindung mit der Standarddatenbank postgres her indem Sie die folgende Zeichenfolge verwenden:
connection = create_connection(
"postgres", "postgres", "abc123", "127.0.0.1", "5432"
)
Als nächstes müssen Sie die Datenbank sm_app erstellen innerhalb des standardmäßigen postgres Datenbank. Sie können eine Funktion definieren, um eine beliebige SQL-Abfrage in PostgreSQL auszuführen. Unten definieren Sie create_database() So erstellen Sie eine neue Datenbank auf dem PostgreSQL-Datenbankserver:
def create_database(connection, query):
connection.autocommit = True
cursor = connection.cursor()
try:
cursor.execute(query)
print("Query executed successfully")
except OperationalError as e:
print(f"The error '{e}' occurred")
create_database_query = "CREATE DATABASE sm_app"
create_database(connection, create_database_query)
Sobald Sie das obige Skript ausgeführt haben, sehen Sie die sm_app Datenbank auf Ihrem PostgreSQL-Datenbankserver.
Bevor Sie Abfragen auf der sm_app ausführen Datenbank, müssen Sie sich mit ihr verbinden:
connection = create_connection(
"sm_app", "postgres", "abc123", "127.0.0.1", "5432"
)
Sobald Sie das obige Skript ausführen, wird eine Verbindung mit der sm_app hergestellt Datenbank, die sich im postgres befindet Datenbankserver. Hier 127.0.0.1 bezieht sich auf die Host-IP-Adresse des Datenbankservers und 5432 bezieht sich auf die Portnummer des Datenbankservers.
Tabellen erstellen
Im vorherigen Abschnitt haben Sie gesehen, wie Sie mithilfe verschiedener Python-SQL-Bibliotheken eine Verbindung zu SQLite-, MySQL- und PostgreSQL-Datenbankservern herstellen. Sie haben die sm_app erstellt Datenbank auf allen drei Datenbankservern. In diesem Abschnitt erfahren Sie, wie Sie Tabellen erstellen innerhalb dieser drei Datenbanken.
Wie bereits erwähnt, erstellen Sie vier Tabellen:
userspostscommentslikes
Sie beginnen mit SQLite.
SQLite
Um Abfragen in SQLite auszuführen, verwenden Sie cursor.execute() . In diesem Abschnitt definieren Sie eine Funktion execute_query() die diese Methode verwendet. Ihre Funktion akzeptiert die connection -Objekt und eine Abfragezeichenfolge, die Sie an cursor.execute() übergeben .
.execute() kann jede ihm in Form einer Zeichenfolge übergebene Abfrage ausführen. Sie werden diese Methode verwenden, um Tabellen in diesem Abschnitt zu erstellen. In den folgenden Abschnitten verwenden Sie dieselbe Methode auch zum Ausführen von Aktualisierungs- und Löschabfragen.
Hinweis: Dieses Skript sollte in derselben Datei ausgeführt werden, in der Sie die Verbindung für Ihre SQLite-Datenbank erstellt haben.
Hier ist Ihre Funktionsdefinition:
def execute_query(connection, query):
cursor = connection.cursor()
try:
cursor.execute(query)
connection.commit()
print("Query executed successfully")
except Error as e:
print(f"The error '{e}' occurred")
Dieser Code versucht, die angegebene query auszuführen und gibt ggf. eine Fehlermeldung aus.
Als nächstes schreiben Sie Ihre Abfrage :
create_users_table = """
CREATE TABLE IF NOT EXISTS users (
id INTEGER PRIMARY KEY AUTOINCREMENT,
name TEXT NOT NULL,
age INTEGER,
gender TEXT,
nationality TEXT
);
"""
Dies besagt, dass eine Tabelle users erstellt werden soll mit den folgenden fünf Spalten:
idnameagegendernationality
Schließlich rufen Sie execute_query() auf um die Tabelle zu erstellen. Sie übergeben die connection Objekt, das Sie im vorherigen Abschnitt erstellt haben, zusammen mit der create_users_table Zeichenfolge, die die Abfrage zum Erstellen einer Tabelle enthält:
execute_query(connection, create_users_table)
Die folgende Abfrage wird verwendet, um die posts zu erstellen Tabelle:
create_posts_table = """
CREATE TABLE IF NOT EXISTS posts(
id INTEGER PRIMARY KEY AUTOINCREMENT,
title TEXT NOT NULL,
description TEXT NOT NULL,
user_id INTEGER NOT NULL,
FOREIGN KEY (user_id) REFERENCES users (id)
);
"""
Da zwischen users eine Eins-zu-Viele-Beziehung besteht und posts , sehen Sie einen Fremdschlüssel user_id in den posts Tabelle, die auf die id verweist Spalte in der users Tisch. Führen Sie das folgende Skript aus, um die posts zu erstellen Tabelle:
execute_query(connection, create_posts_table)
Schließlich können Sie die comments erstellen und likes Tabellen mit folgendem Skript:
create_comments_table = """
CREATE TABLE IF NOT EXISTS comments (
id INTEGER PRIMARY KEY AUTOINCREMENT,
text TEXT NOT NULL,
user_id INTEGER NOT NULL,
post_id INTEGER NOT NULL,
FOREIGN KEY (user_id) REFERENCES users (id) FOREIGN KEY (post_id) REFERENCES posts (id)
);
"""
create_likes_table = """
CREATE TABLE IF NOT EXISTS likes (
id INTEGER PRIMARY KEY AUTOINCREMENT,
user_id INTEGER NOT NULL,
post_id integer NOT NULL,
FOREIGN KEY (user_id) REFERENCES users (id) FOREIGN KEY (post_id) REFERENCES posts (id)
);
"""
execute_query(connection, create_comments_table)
execute_query(connection, create_likes_table)
Sie können sehen, dass Tabellen erstellt werden in SQLite ist der Verwendung von rohem SQL sehr ähnlich. Alles, was Sie tun müssen, ist die Abfrage in einer String-Variablen zu speichern und diese Variable dann an cursor.execute() zu übergeben .
MySQL
Sie verwenden den mysql-connector-python Python-SQL-Modul zum Erstellen von Tabellen in MySQL. Genau wie bei SQLite müssen Sie Ihre Abfrage an cursor.execute() übergeben , die durch den Aufruf von .cursor() zurückgegeben wird auf der connection Objekt. Sie können eine weitere Funktion execute_query() erstellen die die connection akzeptiert und query Zeichenkette:
1def execute_query(connection, query):
2 cursor = connection.cursor()
3 try:
4 cursor.execute(query)
5 connection.commit()
6 print("Query executed successfully")
7 except Error as e:
8 print(f"The error '{e}' occurred")
In Zeile 4 übergeben Sie die query zu cursor.execute() .
Jetzt können Sie Ihre users erstellen Tabelle mit dieser Funktion:
create_users_table = """
CREATE TABLE IF NOT EXISTS users (
id INT AUTO_INCREMENT,
name TEXT NOT NULL,
age INT,
gender TEXT,
nationality TEXT,
PRIMARY KEY (id)
) ENGINE = InnoDB
"""
execute_query(connection, create_users_table)
Die Abfrage zur Implementierung der Fremdschlüsselbeziehung ist in MySQL etwas anders als in SQLite. Darüber hinaus verwendet MySQL den AUTO_INCREMENT Schlüsselwort (im Vergleich zum SQLite AUTOINCREMENT Schlüsselwort), um Spalten zu erstellen, in denen die Werte automatisch inkrementiert werden wenn neue Datensätze eingefügt werden.
Das folgende Skript erstellt die posts Tabelle, die einen Fremdschlüssel user_id enthält die auf die id verweist Spalte der users Tabelle:
create_posts_table = """
CREATE TABLE IF NOT EXISTS posts (
id INT AUTO_INCREMENT,
title TEXT NOT NULL,
description TEXT NOT NULL,
user_id INTEGER NOT NULL,
FOREIGN KEY fk_user_id (user_id) REFERENCES users(id),
PRIMARY KEY (id)
) ENGINE = InnoDB
"""
execute_query(connection, create_posts_table)
Ähnlich, um die comments zu erstellen und likes Tabellen können Sie das entsprechende CREATE übergeben Abfragen an execute_query() .
PostgreSQL
Wie bei SQLite- und MySQL-Datenbanken ist die connection Objekt, das von psycopg2.connect() zurückgegeben wird enthält einen cursor Objekt. Sie können cursor.execute() verwenden um Python-SQL-Abfragen auf Ihrer PostgreSQL-Datenbank auszuführen.
Definieren Sie eine Funktion execute_query() :
def execute_query(connection, query):
connection.autocommit = True
cursor = connection.cursor()
try:
cursor.execute(query)
print("Query executed successfully")
except OperationalError as e:
print(f"The error '{e}' occurred")
Sie können diese Funktion verwenden, um Tabellen zu erstellen, Datensätze einzufügen, Datensätze zu ändern und Datensätze in Ihrer PostgreSQL-Datenbank zu löschen.
Erstellen Sie nun die users Tabelle innerhalb der sm_app Datenbank:
create_users_table = """
CREATE TABLE IF NOT EXISTS users (
id SERIAL PRIMARY KEY,
name TEXT NOT NULL,
age INTEGER,
gender TEXT,
nationality TEXT
)
"""
execute_query(connection, create_users_table)
Sie können sehen, dass die Abfrage zum Erstellen der users Tabelle in PostgreSQL unterscheidet sich geringfügig von SQLite und MySQL. Hier das Schlüsselwort SERIAL wird verwendet, um Spalten zu erstellen, die automatisch inkrementieren. Denken Sie daran, dass MySQL das Schlüsselwort AUTO_INCREMENT verwendet .
Darüber hinaus wird die Fremdschlüsselreferenzierung auch anders angegeben, wie im folgenden Skript gezeigt, das die posts erstellt Tabelle:
create_posts_table = """
CREATE TABLE IF NOT EXISTS posts (
id SERIAL PRIMARY KEY,
title TEXT NOT NULL,
description TEXT NOT NULL,
user_id INTEGER REFERENCES users(id)
)
"""
execute_query(connection, create_posts_table)
Um die comments zu erstellen Tabelle müssen Sie ein CREATE schreiben Abfrage für die comments Tabelle und übergeben Sie sie an execute_query() . Der Prozess zum Erstellen der likes Tisch ist der gleiche. Sie müssen nur den CREATE ändern Abfrage zum Erstellen der likes Tabelle anstelle der comments Tabelle.
Datensätze einfügen
Im vorherigen Abschnitt haben Sie gesehen, wie Sie Tabellen in Ihren SQLite-, MySQL- und PostgreSQL-Datenbanken erstellen, indem Sie verschiedene Python-SQL-Module verwenden. In diesem Abschnitt erfahren Sie, wie Sie Datensätze einfügen in Ihre Tabellen.
SQLite
Um Datensätze in Ihre SQLite-Datenbank einzufügen, können Sie denselben execute_query() verwenden Funktion, die Sie zum Erstellen von Tabellen verwendet haben. Zuerst müssen Sie Ihren INSERT INTO speichern Abfrage in einer Zeichenfolge. Dann können Sie die connection weitergeben Objekt und query Zeichenfolge zu execute_query() . Lassen Sie uns fünf Datensätze in users einfügen Tabelle:
create_users = """
INSERT INTO
users (name, age, gender, nationality)
VALUES
('James', 25, 'male', 'USA'),
('Leila', 32, 'female', 'France'),
('Brigitte', 35, 'female', 'England'),
('Mike', 40, 'male', 'Denmark'),
('Elizabeth', 21, 'female', 'Canada');
"""
execute_query(connection, create_users)
Da Sie die id gesetzt haben Spalte automatisch inkrementieren, müssen Sie den Wert der id nicht angeben Spalte für diese users . Die users Die Tabelle füllt diese fünf Datensätze automatisch mit id Werte von 1 bis 5 .
Fügen Sie nun sechs Datensätze in die posts ein Tabelle:
create_posts = """
INSERT INTO
posts (title, description, user_id)
VALUES
("Happy", "I am feeling very happy today", 1),
("Hot Weather", "The weather is very hot today", 2),
("Help", "I need some help with my work", 2),
("Great News", "I am getting married", 1),
("Interesting Game", "It was a fantastic game of tennis", 5),
("Party", "Anyone up for a late-night party today?", 3);
"""
execute_query(connection, create_posts)
Es ist wichtig zu erwähnen, dass die user_id Spalte der posts Tabelle ist ein Fremdschlüssel die auf die id verweist Spalte der users Tisch. Das bedeutet, dass die user_id Spalte muss einen Wert enthalten, der bereits existiert in der id Spalte der users Tisch. Wenn es nicht existiert, wird ein Fehler angezeigt.
Auf ähnliche Weise fügt das folgende Skript Datensätze in die comments ein und likes Tabellen:
create_comments = """
INSERT INTO
comments (text, user_id, post_id)
VALUES
('Count me in', 1, 6),
('What sort of help?', 5, 3),
('Congrats buddy', 2, 4),
('I was rooting for Nadal though', 4, 5),
('Help with your thesis?', 2, 3),
('Many congratulations', 5, 4);
"""
create_likes = """
INSERT INTO
likes (user_id, post_id)
VALUES
(1, 6),
(2, 3),
(1, 5),
(5, 4),
(2, 4),
(4, 2),
(3, 6);
"""
execute_query(connection, create_comments)
execute_query(connection, create_likes)
In beiden Fällen speichern Sie Ihren INSERT INTO als String abfragen und mit execute_query() ausführen .
MySQL
Es gibt zwei Möglichkeiten, Datensätze aus einer Python-Anwendung in MySQL-Datenbanken einzufügen. Der erste Ansatz ähnelt SQLite. Sie können den INSERT INTO speichern Abfrage in einer Zeichenfolge und verwenden Sie dann cursor.execute() Datensätze einfügen.
Zuvor haben Sie eine Wrapper-Funktion execute_query() definiert die Sie zum Einfügen von Datensätzen verwendet haben. Sie können dieselbe Funktion jetzt verwenden, um Datensätze in Ihre MySQL-Tabelle einzufügen. Das folgende Skript fügt Datensätze in users ein Tabelle mit execute_query() :
create_users = """
INSERT INTO
`users` (`name`, `age`, `gender`, `nationality`)
VALUES
('James', 25, 'male', 'USA'),
('Leila', 32, 'female', 'France'),
('Brigitte', 35, 'female', 'England'),
('Mike', 40, 'male', 'Denmark'),
('Elizabeth', 21, 'female', 'Canada');
"""
execute_query(connection, create_users)
Der zweite Ansatz verwendet cursor.executemany() , die zwei Parameter akzeptiert:
- Die Abfrage Zeichenfolge, die Platzhalter für die einzufügenden Datensätze enthält
- Die Liste der Datensätze, die Sie einfügen möchten
Sehen Sie sich das folgende Beispiel an, das zwei Datensätze in die likes einfügt Tabelle:
sql = "INSERT INTO likes ( user_id, post_id ) VALUES ( %s, %s )"
val = [(4, 5), (3, 4)]
cursor = connection.cursor()
cursor.executemany(sql, val)
connection.commit()
Es liegt an Ihnen, welchen Ansatz Sie wählen, um Datensätze in Ihre MySQL-Tabelle einzufügen. Wenn Sie ein SQL-Experte sind, können Sie .execute() verwenden . Wenn Sie mit SQL nicht sehr vertraut sind, ist es möglicherweise einfacher, .executemany() zu verwenden . Mit jedem der beiden Ansätze können Sie Datensätze erfolgreich in die posts einfügen , comments , und likes Tabellen.
PostgreSQL
Im vorherigen Abschnitt haben Sie zwei Ansätze zum Einfügen von Datensätzen in SQLite-Datenbanktabellen gesehen. Die erste verwendet eine SQL-String-Abfrage und die zweite verwendet .executemany() . psycopg2 folgt diesem zweiten Ansatz, obwohl .execute() wird verwendet, um eine platzhalterbasierte Abfrage auszuführen.
Sie übergeben die SQL-Abfrage mit den Platzhaltern und der Liste der Datensätze an .execute() . Jeder Datensatz in der Liste ist ein Tupel, wobei Tupelwerte den Spaltenwerten in der Datenbanktabelle entsprechen. So können Sie Benutzerdatensätze in users einfügen Tabelle in einer PostgreSQL-Datenbank:
users = [
("James", 25, "male", "USA"),
("Leila", 32, "female", "France"),
("Brigitte", 35, "female", "England"),
("Mike", 40, "male", "Denmark"),
("Elizabeth", 21, "female", "Canada"),
]
user_records = ", ".join(["%s"] * len(users))
insert_query = (
f"INSERT INTO users (name, age, gender, nationality) VALUES {user_records}"
)
connection.autocommit = True
cursor = connection.cursor()
cursor.execute(insert_query, users)
Das obige Skript erstellt eine Liste users das fünf Benutzerdatensätze in Form von Tupeln enthält. Als Nächstes erstellen Sie eine Platzhalterzeichenfolge mit fünf Platzhalterelementen (%s ), die den fünf Benutzerdatensätzen entsprechen. Die Platzhalterzeichenfolge wird mit der Abfrage verkettet, die Datensätze in users einfügt Tisch. Schließlich werden die Abfragezeichenfolge und die Benutzerdatensätze an .execute() übergeben . Das obige Skript fügt erfolgreich fünf Datensätze in users ein Tabelle.
Sehen Sie sich ein weiteres Beispiel für das Einfügen von Datensätzen in eine PostgreSQL-Tabelle an. Das folgende Skript fügt Datensätze in die posts ein Tabelle:
posts = [
("Happy", "I am feeling very happy today", 1),
("Hot Weather", "The weather is very hot today", 2),
("Help", "I need some help with my work", 2),
("Great News", "I am getting married", 1),
("Interesting Game", "It was a fantastic game of tennis", 5),
("Party", "Anyone up for a late-night party today?", 3),
]
post_records = ", ".join(["%s"] * len(posts))
insert_query = (
f"INSERT INTO posts (title, description, user_id) VALUES {post_records}"
)
connection.autocommit = True
cursor = connection.cursor()
cursor.execute(insert_query, posts)
Sie können Datensätze in die comments einfügen und likes Tabellen mit dem gleichen Ansatz.
Datensätze auswählen
In diesem Abschnitt erfahren Sie, wie Sie mit den verschiedenen Python-SQL-Modulen Datensätze aus Datenbanktabellen auswählen. Insbesondere sehen Sie, wie Sie SELECT ausführen Abfragen auf Ihren SQLite-, MySQL- und PostgreSQL-Datenbanken.
SQLite
Um Datensätze mit SQLite auszuwählen, können Sie wieder cursor.execute() verwenden . Nachdem Sie dies getan haben, müssen Sie jedoch .fetchall() aufrufen . Diese Methode gibt eine Liste von Tupeln zurück, wobei jedes Tupel der entsprechenden Zeile in den abgerufenen Datensätzen zugeordnet ist.
Um den Vorgang zu vereinfachen, können Sie eine Funktion execute_read_query() erstellen :
def execute_read_query(connection, query):
cursor = connection.cursor()
result = None
try:
cursor.execute(query)
result = cursor.fetchall()
return result
except Error as e:
print(f"The error '{e}' occurred")
Diese Funktion akzeptiert die connection Objekt und das SELECT Abfrage und gibt den ausgewählten Datensatz zurück.
SELECT
Wählen wir nun alle Datensätze der users aus Tabelle:
select_users = "SELECT * from users"
users = execute_read_query(connection, select_users)
for user in users:
print(user)
Im obigen Skript ist die SELECT Abfrage wählt alle Benutzer aus den users aus Tisch. Dies wird an execute_read_query() übergeben , die alle Datensätze von den users zurückgibt Tisch. Die Aufzeichnungen werden dann durchlaufen und auf der Konsole ausgegeben.
Hinweis: Es wird nicht empfohlen, SELECT * zu verwenden auf großen Tabellen, da dies zu einer großen Anzahl von E/A-Vorgängen führen kann, die den Netzwerkverkehr erhöhen.
Die Ausgabe der obigen Abfrage sieht folgendermaßen aus:
(1, 'James', 25, 'male', 'USA')
(2, 'Leila', 32, 'female', 'France')
(3, 'Brigitte', 35, 'female', 'England')
(4, 'Mike', 40, 'male', 'Denmark')
(5, 'Elizabeth', 21, 'female', 'Canada')
Auf die gleiche Weise können Sie alle Datensätze aus den posts abrufen Tabelle mit dem folgenden Skript:
select_posts = "SELECT * FROM posts"
posts = execute_read_query(connection, select_posts)
for post in posts:
print(post)
Die Ausgabe sieht so aus:
(1, 'Happy', 'I am feeling very happy today', 1)
(2, 'Hot Weather', 'The weather is very hot today', 2)
(3, 'Help', 'I need some help with my work', 2)
(4, 'Great News', 'I am getting married', 1)
(5, 'Interesting Game', 'It was a fantastic game of tennis', 5)
(6, 'Party', 'Anyone up for a late-night party today?', 3)
Das Ergebnis zeigt alle Datensätze in den posts Tabelle.
JOIN
You can also execute complex queries involving JOIN operations to retrieve data from two related tables. For instance, the following script returns the user ids and names, along with the description of the posts that these users posted:
select_users_posts = """
SELECT
users.id,
users.name,
posts.description
FROM
posts
INNER JOIN users ON users.id = posts.user_id
"""
users_posts = execute_read_query(connection, select_users_posts)
for users_post in users_posts:
print(users_post)
Here’s the output:
(1, 'James', 'I am feeling very happy today')
(2, 'Leila', 'The weather is very hot today')
(2, 'Leila', 'I need some help with my work')
(1, 'James', 'I am getting married')
(5, 'Elizabeth', 'It was a fantastic game of tennis')
(3, 'Brigitte', 'Anyone up for a late night party today?')
You can also select data from three related tables by implementing multiple JOIN operators . The following script returns all posts, along with the comments on the posts and the names of the users who posted the comments:
select_posts_comments_users = """
SELECT
posts.description as post,
text as comment,
name
FROM
posts
INNER JOIN comments ON posts.id = comments.post_id
INNER JOIN users ON users.id = comments.user_id
"""
posts_comments_users = execute_read_query(
connection, select_posts_comments_users
)
for posts_comments_user in posts_comments_users:
print(posts_comments_user)
The output looks like this:
('Anyone up for a late night party today?', 'Count me in', 'James')
('I need some help with my work', 'What sort of help?', 'Elizabeth')
('I am getting married', 'Congrats buddy', 'Leila')
('It was a fantastic game of tennis', 'I was rooting for Nadal though', 'Mike')
('I need some help with my work', 'Help with your thesis?', 'Leila')
('I am getting married', 'Many congratulations', 'Elizabeth')
You can see from the output that the column names are not being returned by .fetchall() . To return column names, you can use the .description attribute of the cursor object. For instance, the following list returns all the column names for the above query:
cursor = connection.cursor()
cursor.execute(select_posts_comments_users)
cursor.fetchall()
column_names = [description[0] for description in cursor.description]
print(column_names)
The output looks like this:
['post', 'comment', 'name']
You can see the names of the columns for the given query.
WHERE
Now you’ll execute a SELECT query that returns the post, along with the total number of likes that the post received:
select_post_likes = """
SELECT
description as Post,
COUNT(likes.id) as Likes
FROM
likes,
posts
WHERE
posts.id = likes.post_id
GROUP BY
likes.post_id
"""
post_likes = execute_read_query(connection, select_post_likes)
for post_like in post_likes:
print(post_like)
The output is as follows:
('The weather is very hot today', 1)
('I need some help with my work', 1)
('I am getting married', 2)
('It was a fantastic game of tennis', 1)
('Anyone up for a late night party today?', 2)
By using a WHERE clause, you’re able to return more specific results.
MySQL
The process of selecting records in MySQL is absolutely identical to selecting records in SQLite. You can use cursor.execute() followed by .fetchall() . The following script creates a wrapper function execute_read_query() that you can use to select records:
def execute_read_query(connection, query):
cursor = connection.cursor()
result = None
try:
cursor.execute(query)
result = cursor.fetchall()
return result
except Error as e:
print(f"The error '{e}' occurred")
Now select all the records from the users table:
select_users = "SELECT * FROM users"
users = execute_read_query(connection, select_users)
for user in users:
print(user)
The output will be similar to what you saw with SQLite.
PostgreSQL
The process of selecting records from a PostgreSQL table with the psycopg2 Python SQL module is similar to what you did with SQLite and MySQL. Again, you’ll use cursor.execute() followed by .fetchall() to select records from your PostgreSQL table. The following script selects all the records from the users table and prints them to the console:
def execute_read_query(connection, query):
cursor = connection.cursor()
result = None
try:
cursor.execute(query)
result = cursor.fetchall()
return result
except OperationalError as e:
print(f"The error '{e}' occurred")
select_users = "SELECT * FROM users"
users = execute_read_query(connection, select_users)
for user in users:
print(user)
Again, the output will be similar to what you’ve seen before.
Updating Table Records
In the last section, you saw how to select records from SQLite, MySQL, and PostgreSQL databases. In this section, you’ll cover the process for updating records using the Python SQL libraries for SQLite, PostgresSQL, and MySQL.
SQLite
Updating records in SQLite is pretty straightforward. You can again make use of execute_query() . As an example, you can update the description of the post with an id of 2 . First, SELECT the description of this post:
select_post_description = "SELECT description FROM posts WHERE id = 2"
post_description = execute_read_query(connection, select_post_description)
for description in post_description:
print(description)
You should see the following output:
('The weather is very hot today',)
The following script updates the description:
update_post_description = """
UPDATE
posts
SET
description = "The weather has become pleasant now"
WHERE
id = 2
"""
execute_query(connection, update_post_description)
Now, if you execute the SELECT query again, you should see the following result:
('The weather has become pleasant now',)
The output has been updated.
MySQL
The process of updating records in MySQL with mysql-connector-python is also a carbon copy of the sqlite3 Python SQL module. You need to pass the string query to cursor.execute() . For example, the following script updates the description of the post with an id of 2 :
update_post_description = """
UPDATE
posts
SET
description = "The weather has become pleasant now"
WHERE
id = 2
"""
execute_query(connection, update_post_description)
Again, you’ve used your wrapper function execute_query() to update the post description.
PostgreSQL
The update query for PostgreSQL is similar to what you’ve seen with SQLite and MySQL. You can use the above scripts to update records in your PostgreSQL table.
Deleting Table Records
In this section, you’ll see how to delete table records using the Python SQL modules for SQLite, MySQL, and PostgreSQL databases. The process of deleting records is uniform for all three databases since the DELETE query for the three databases is the same.
SQLite
You can again use execute_query() to delete records from YOUR SQLite database. All you have to do is pass the connection object and the string query for the record you want to delete to execute_query() . Then, execute_query() will create a cursor object using the connection and pass the string query to cursor.execute() , which will delete the records.
As an example, try to delete the comment with an id of 5 :
delete_comment = "DELETE FROM comments WHERE id = 5"
execute_query(connection, delete_comment)
Now, if you select all the records from the comments table, you’ll see that the fifth comment has been deleted.
MySQL
The process for deletion in MySQL is also similar to SQLite, as shown in the following example:
delete_comment = "DELETE FROM comments WHERE id = 2"
execute_query(connection, delete_comment)
Here, you delete the second comment from the sm_app database’s comments table in your MySQL database server.
PostgreSQL
The delete query for PostgreSQL is also similar to SQLite and MySQL. You can write a delete query string by using the DELETE keyword and then passing the query and the connection object to execute_query() . This will delete the specified records from your PostgreSQL database.
Conclusion
In this tutorial, you’ve learned how to use three common Python SQL libraries. sqlite3 , mysql-connector-python , and psycopg2 allow you to connect a Python application to SQLite, MySQL, and PostgreSQL databases, respectively.
Now you can:
- Interact with SQLite, MySQL, or PostgreSQL databases
- Use three different Python SQL modules
- Execute SQL queries on various databases from within a Python application
However, this is just the tip of the iceberg! There are also Python SQL libraries for object-relational mapping , such as SQLAlchemy and Django ORM, that automate the task of database interaction in Python. You’ll learn more about these libraries in other tutorials in our Python databases section.