Dieser Artikel ist der fünfte Teil einer Reihe über T-SQL-Bugs, Fallstricke und Best Practices. Zuvor habe ich Determinismus, Unterabfragen, Joins und Windowing behandelt. Diesen Monat behandle ich Pivotierung und Unpivoting. Vielen Dank an Erland Sommarskog, Aaron Bertrand, Alejandro Mesa, Umachandar Jayachandran (UC), Fabiano Neves Amorim, Milos Radivojevic, Simon Sabin, Adam Machanic, Thomas Grohser, Chan Ming Man und Paul White für das Teilen Ihrer Vorschläge!
In meinen Beispielen verwende ich eine Beispieldatenbank namens TSQLV5. Das Skript, das diese Datenbank erstellt und füllt, finden Sie hier und ihr ER-Diagramm hier.
Implizite Gruppierung mit PIVOT
Wenn Benutzer Daten mithilfe von T-SQL pivotieren möchten, verwenden sie entweder eine Standardlösung mit einer gruppierten Abfrage und CASE-Ausdrücken oder den proprietären PIVOT-Tabellenoperator. Der Hauptvorteil des PIVOT-Operators besteht darin, dass er tendenziell zu kürzerem Code führt. Dieser Operator hat jedoch einige Mängel, darunter eine inhärente Entwurfsfalle, die zu Fehlern in Ihrem Code führen kann. Hier beschreibe ich die Falle, den potenziellen Fehler und eine Best Practice, die den Fehler verhindert. Ich werde auch einen Vorschlag beschreiben, um die Syntax des PIVOT-Operators so zu verbessern, dass der Fehler vermieden wird.
Beim Pivotieren von Daten umfasst die Lösung drei Schritte mit drei zugehörigen Elementen:
- Gruppierung basierend auf einem Gruppierungs-/Zeilenelement
- Spread basiert auf einem Spreading/on cols-Element
- Aggregat basierend auf einem Aggregat/Datenelement
Es folgt die Syntax des PIVOT-Operators:
SELECTFROM PIVOT( ( ) FOR IN( ) ) AS ;
Das Design des PIVOT-Operators erfordert, dass Sie die Aggregations- und Spreading-Elemente explizit angeben, lässt aber SQL Server das Gruppierungselement implizit durch Eliminierung ermitteln. Welche Spalten auch immer in der Quelltabelle erscheinen, die als Eingabe für den PIVOT-Operator bereitgestellt wird, sie werden implizit zum Gruppierungselement.
Angenommen, Sie möchten die Sales.Orders-Tabelle in der TSQLV5-Beispieldatenbank abfragen. Sie möchten Versender-IDs in Zeilen, Versandjahre in Spalten und die Anzahl der Bestellungen pro Versender und Jahr als Summe zurückgeben.
Vielen Menschen fällt es schwer, die Syntax des PIVOT-Operators herauszufinden, und dies führt oft dazu, dass die Daten nach unerwünschten Elementen gruppiert werden. Als Beispiel für unsere Aufgabe nehmen wir an, Sie wissen nicht, dass das Gruppierungselement implizit bestimmt wird, und Sie erhalten die folgende Abfrage:
SELECT shipperid, [2017], [2018], [2019]FROM Sales.Orders CROSS APPLY( VALUES(YEAR(shippeddate)) ) AS D(shippedyear) PIVOT( COUNT(shippeddate) FOR shippingyear IN([2017] , [2018], [2019]) ) ASP;
In den Daten sind nur drei Versender mit den Versender-IDs 1, 2 und 3 vorhanden. Sie erwarten also nur drei Zeilen im Ergebnis. Die tatsächliche Abfrageausgabe zeigt jedoch viel mehr Zeilen:
Lieferzeit 2017 2018 2019 ----------- ----------- ----------- ---------- -3 1 0 01 1 0 02 1 0 01 1 0 02 1 0 02 1 0 02 1 0 03 1 0 02 1 0 03 1 0 0...3 0 1 03 0 1 03 0 1 01 0 1 03 0 1 01 0 1 03 0 1 03 0 1 03 0 1 01 0 1 0...3 0 0 11 0 0 12 0 0 11 0 0 12 0 0 11 0 0 13 0 0 13 0 0 12 0 1 0...(830 Zeilen betroffen)
Was ist passiert?
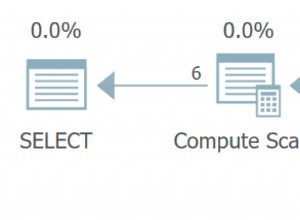
Sie können einen Hinweis finden, der Ihnen hilft, den Fehler im Code herauszufinden, indem Sie sich den in Abbildung 1 gezeigten Abfrageplan ansehen.
 Abbildung 1:Planen Sie eine Pivot-Abfrage mit impliziter Gruppierung
Abbildung 1:Planen Sie eine Pivot-Abfrage mit impliziter Gruppierung
Lassen Sie sich nicht durch die Verwendung des CROSS APPLY-Operators mit der VALUES-Klausel in der Abfrage verwirren. Dies geschieht einfach, um die Ergebnisspalte "shippedyear" basierend auf der Quelle "shippeddate" zu berechnen, und wird vom ersten "Compute Scalar"-Operator im Plan behandelt.
Die Eingabetabelle für den PIVOT-Operator enthält alle Spalten aus der Tabelle „Sales.Orders“ sowie die Ergebnisspalte „shippedyear“. Wie bereits erwähnt, bestimmt SQL Server das Gruppierungselement implizit durch Eliminierung basierend auf dem, was Sie nicht als Aggregations- (shippeddate) und Spreading-Element (shippedyear) angegeben haben. Vielleicht haben Sie intuitiv erwartet, dass die shipperid-Spalte die Gruppierungsspalte ist, weil sie in der SELECT-Liste erscheint, aber wie Sie im Plan sehen können, haben Sie in der Praxis eine viel längere Liste von Spalten, einschließlich orderid, die darin die Primärschlüsselspalte ist die Quelltabelle. Das bedeutet, dass Sie statt einer Zeile pro Versender eine Zeile pro Bestellung erhalten. Da Sie in der SELECT-Liste nur die Spalten shipperid, [2017], [2018] und [2019] angegeben haben, sehen Sie den Rest nicht, was zur Verwirrung beiträgt. Aber der Rest nahm an der impliziten Gruppierung teil.
Was großartig sein könnte, wäre, wenn die Syntax des PIVOT-Operators eine Klausel unterstützen würde, in der Sie das Gruppierungs-/in-Zeilen-Element explizit angeben können. Etwa so:
SELECTFROM PIVOT( ( ) FOR IN( ) ON ROWS ) AS ;
Basierend auf dieser Syntax würden Sie den folgenden Code verwenden, um unsere Aufgabe zu erledigen:
SELECT shipperid, [2017], [2018], [2019]FROM Sales.Orders CROSS APPLY( VALUES(YEAR(shippeddate)) ) AS D(shippedyear) PIVOT( COUNT(shippeddate) FOR shippingyear IN([2017] , [2018], [2019]) ON ROWS shipperid ) AS P;
Hier finden Sie ein Feedback-Element mit einem Vorschlag zur Verbesserung der Syntax des PIVOT-Operators. Um diese Verbesserung zu einer nicht brechenden Änderung zu machen, kann diese Klausel optional gemacht werden, wobei der Standardwert das vorhandene Verhalten ist. Es gibt weitere Vorschläge zur Verbesserung der Syntax des PIVOT-Operators, indem sie dynamischer gestaltet und mehrere Aggregate unterstützt werden.
In der Zwischenzeit gibt es eine Best Practice, die Ihnen helfen kann, den Fehler zu vermeiden. Verwenden Sie einen Tabellenausdruck wie einen CTE oder eine abgeleitete Tabelle, in der Sie nur die drei Elemente projizieren, die Sie in die Pivot-Operation einbeziehen müssen, und verwenden Sie dann den Tabellenausdruck als Eingabe für den PIVOT-Operator. Auf diese Weise haben Sie die volle Kontrolle über das Gruppierungselement. Hier ist die allgemeine Syntax nach dieser Best Practice:
WITHAS( SELECT , , FROM )SELECT FROM PIVOT( ( ) FOR IN( ) ) AS ;
Angewendet auf unsere Aufgabe verwenden Sie folgenden Code:
WITH C AS( SELECT shipperid, YEAR(shippeddate) AS shippingyear, shippingdate FROM Sales.Orders)SELECT shipperid, [2017], [2018], [2019]FROM C PIVOT( COUNT(shippeddate) FOR shippingyear IN([ 2017], [2018], [2019]) ) ASP;
Dieses Mal erhalten Sie wie erwartet nur drei Ergebniszeilen:
Lieferzeit 2017 2018 2019 ----------- ----------- ----------- ---------- -3 51 125 731 36 130 792 56 143 116
Eine weitere Option ist die Verwendung der alten und klassischen Standardlösung für das Pivotieren mit einer gruppierten Abfrage und CASE-Ausdrücken, etwa so:
Versandzeitraum auswählen, COUNT(CASE WHEN Auslieferungsjahr =2017 DANN 1 ENDE) AS [2017], COUNT(CASE WHEN Versandjahr =2018 THEN 1 ENDE) AS [2018], COUNT(CASE WHEN Versandjahr =2019 THEN 1 ENDE) AS [2019]FROM Sales.Orders CROSS APPLY( VALUES(YEAR(shippeddate)) ) AS D(shippedyear)WHERE shippingdate IS NOT NULLGROUP BY shipperid;
Bei dieser Syntax müssen alle drei Pivot-Schritte und die zugehörigen Elemente explizit im Code enthalten sein. Wenn Sie jedoch über eine große Anzahl von Spreading-Werten verfügen, neigt diese Syntax dazu, ausführlich zu sein. In solchen Fällen wird häufig der PIVOT-Operator bevorzugt.
Implizites Entfernen von NULLen mit UNPIVOT
Der nächste Punkt in diesem Artikel ist eher eine Falle als ein Fehler. Dies hat mit dem proprietären T-SQL-Operator UNPIVOT zu tun, mit dem Sie Daten von einem Spaltenstatus in einen Zeilenstatus entpivotieren können.
Ich verwende eine Tabelle namens CustOrders als meine Beispieldaten. Verwenden Sie den folgenden Code, um diese Tabelle zu erstellen, zu füllen und abzufragen, um ihren Inhalt anzuzeigen:
DROP TABLE IF EXISTS dbo.CustOrders;GO WITH C AS( SELECT custid, YEAR(orderdate) AS orderyearyear, val FROM Sales.OrderValues)SELECT custid, [2017], [2018], [2019]INTO dbo.CustOrdersFROM C PIVOT( SUM(val) FOR orderyearyear IN([2017], [2018], [2019]) ) AS P; SELECT * FROM dbo.CustOrders;
Dieser Code generiert die folgende Ausgabe:
custid 2017 2018 2019------- ---------- ---------- ----------1 NULL 2022,50 2250,502 88,80 799,75 514.403 403.20 5960.78 660.004 1379.00 6406.90 5604.755 4324.40 13849.02 6754.166 NULL 1079.80 2160.007 9986.20 7817.88 730.008 982.00 3026.85 224.009 4074.28 11208.36 6680.6110 1832.80 7630.25 11338.5611 479.40 3179.50 2431.0012 NULL 238.00 1576.8013 100.80 NULL NULL14 1674.22 6516.40 4158.2615 2169.00 1128.00 513.7516 NULL 787.60 931.5017 533.60 420.00 2809.6118 268.80 487.00 860.1019 950.00 4514.35 9296.6920 15568.07 48096.27 41210.65...
Diese Tabelle enthält die Gesamtbestellwerte pro Kunde und Jahr. NULLen stellen Fälle dar, in denen ein Kunde im Zieljahr keine Bestellaktivität hatte.
Angenommen, Sie möchten die Daten aus der CustOrders-Tabelle entpivotieren und eine Zeile pro Kunde und Jahr zurückgeben, wobei eine Ergebnisspalte namens val den Gesamtbestellwert für den aktuellen Kunden und das aktuelle Jahr enthält. Jede unpivotierende Aufgabe umfasst im Allgemeinen drei Elemente:
- Die Namen der vorhandenen Quellspalten, die Sie entpivotieren:[2017], [2018], [2019] in unserem Fall
- Ein Name, den Sie der Zielspalte zuweisen, die die Quellspaltennamen enthält:in unserem Fall orderyear
- Ein Name, den Sie der Zielspalte zuweisen, die die Quellspaltenwerte enthält:in unserem Fall val
Wenn Sie sich entscheiden, den UNPIVOT-Operator zu verwenden, um die Unpivoting-Aufgabe zu handhaben, müssen Sie zuerst die obigen drei Elemente herausfinden und dann die folgende Syntax verwenden:
SELECT, , FROM UNPIVOT( FOR IN( ) ) AS ;
Angewendet auf unsere Aufgabe verwenden Sie die folgende Abfrage:
SELECT custid, orderyear, valFROM dbo.CustOrders UNPIVOT( val FOR orderyear IN([2017], [2018], [2019]) ) AS U;
Diese Abfrage generiert die folgende Ausgabe:
Wenn Sie sich die Quelldaten und das Abfrageergebnis ansehen, fällt Ihnen auf, was fehlt?
Das Design des UNPIVOT-Operators beinhaltet eine implizite Eliminierung von Ergebniszeilen, die eine NULL in der Wertespalte enthalten – in unserem Fall val. Wenn Sie sich den in Abbildung 2 gezeigten Ausführungsplan für diese Abfrage ansehen, können Sie sehen, wie der Filteroperator die Zeilen mit den NULL-Werten in der val-Spalte (Expr1007 im Plan) entfernt.
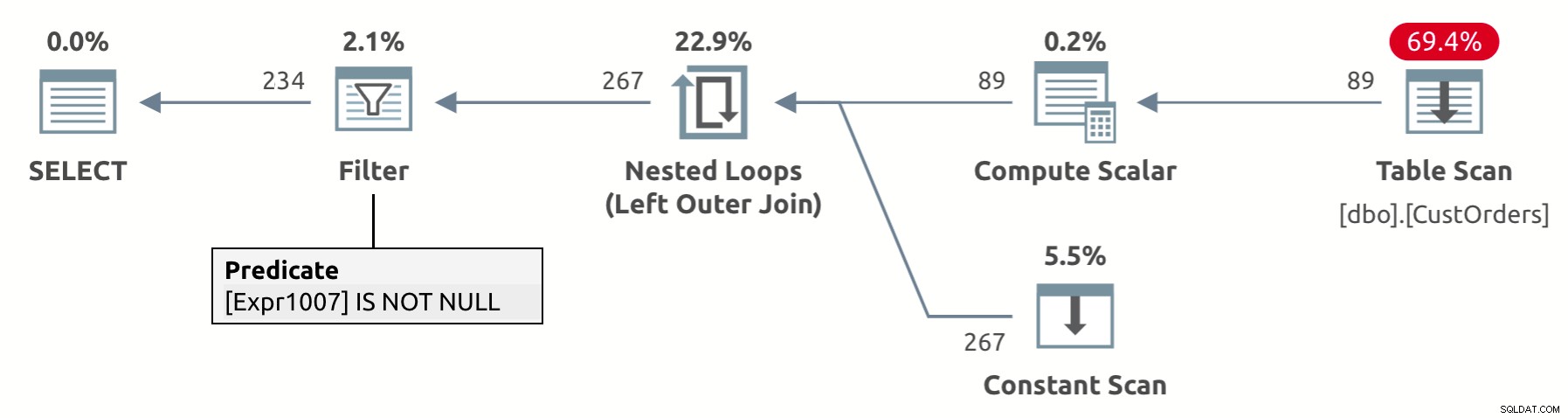 Abbildung 2:Planen Sie eine Unpivot-Abfrage mit impliziter Entfernung von NULLen
Abbildung 2:Planen Sie eine Unpivot-Abfrage mit impliziter Entfernung von NULLen
Manchmal ist dieses Verhalten erwünscht, in diesem Fall müssen Sie nichts Besonderes tun. Das Problem ist, dass Sie manchmal die Zeilen mit den NULL-Werten behalten möchten. Der Fallstrick ist, wenn Sie die NULLen behalten wollen und nicht einmal merken, dass der UNPIVOT-Operator darauf ausgelegt ist, sie zu entfernen.
Was großartig wäre, wäre, wenn der UNPIVOT-Operator eine optionale Klausel hätte, mit der Sie angeben könnten, ob Sie NULL-Werte entfernen oder beibehalten möchten, wobei erstere die Standardeinstellung für die Abwärtskompatibilität ist. Hier ist ein Beispiel dafür, wie diese Syntax aussehen könnte:
SELECT, , FROM UNPIVOT( FOR IN( ) [REMOVE NULLS | KEEP NULLS] ) AS ;
Wenn Sie NULLen behalten wollten, würden Sie basierend auf dieser Syntax die folgende Abfrage verwenden:
SELECT custid, orderyear, valFROM dbo.CustOrders UNPIVOT( val FOR orderyear IN([2017], [2018], [2019]) KEEP NULLS ) AS U;
Hier finden Sie ein Feedback-Element mit einem Vorschlag, die Syntax des UNPIVOT-Operators auf diese Weise zu verbessern.
Wenn Sie in der Zwischenzeit die Zeilen mit den NULL-Werten behalten möchten, müssen Sie sich eine Problemumgehung einfallen lassen. Wenn Sie darauf bestehen, den UNPIVOT-Operator zu verwenden, müssen Sie zwei Schritte ausführen. Im ersten Schritt definieren Sie einen Tabellenausdruck basierend auf einer Abfrage, die die Funktion ISNULL oder COALESCE verwendet, um NULLen in allen nichtpivotierten Spalten durch einen Wert zu ersetzen, der normalerweise nicht in den Daten erscheinen kann, z. B. in unserem Fall -1. Im zweiten Schritt verwenden Sie die NULLIF-Funktion in der äußeren Abfrage gegen die Wertespalte, um die -1 wieder durch eine NULL zu ersetzen. Hier ist der vollständige Lösungscode:
MIT C AS( CUSTID AUSWÄHLEN, ISNULL([2017], -1.0) AS [2017], ISNULL([2018], -1.0) AS [2018], ISNULL([2019], -1.0) AS [2019 ] FROM dbo.CustOrders)SELECT custid, orderyear, NULLIF(val, -1.0) AS valFROM C UNPIVOT( val FOR orderyear IN([2017], [2018], [2019]) ) AS U;
Hier ist die Ausgabe dieser Abfrage, die zeigt, dass Zeilen mit NULL-Werten in der Val-Spalte erhalten bleiben:
custid orderyear val------- ---------- ----------1 2017 NULL1 2018 2022.501 2019 2250.502 2017 88.802 2018 799.752 2019 514.403 2017 403.203 2018 5960.783 2019 660.004 2017 1379.004 2018 6406.904 2019 5604.755 2017 4324.405 2018 13849.025 2019 6754.166 2017 NULL6 2018 1079.806 2019 2160.007 2017 9986.207 2018 7817.87 2019 730.007 9986.207 2018 7817.887 2019 730.007 2017-/PREEDieser Ansatz ist umständlich, besonders wenn Sie eine große Anzahl von Spalten zum Entpivotieren haben.
Eine alternative Lösung verwendet eine Kombination aus dem APPLY-Operator und der VALUES-Klausel. Sie erstellen eine Zeile für jede nichtpivotierte Spalte, wobei eine Spalte die Zielnamensspalte (in unserem Fall orderyear) und eine andere die Zielwertspalte (in unserem Fall val) darstellt. Sie geben das konstante Jahr für die Namensspalte und die relevante korrelierte Quellenspalte für die Wertespalte an. Hier ist der vollständige Lösungscode:
SELECT custid, orderyear, valFROM dbo.CustOrders CROSS APPLY ( VALUES(2017, [2017]), (2018, [2018]), (2019, [2019]) ) AS A(orderyear, val);
Das Schöne hier ist, dass Sie nichts Besonderes tun müssen, es sei denn, Sie sind daran interessiert, die Zeilen mit den NULLen in der val-Spalte zu entfernen. Hier gibt es keinen impliziten Schritt, der die Zeilen mit den NULLEN entfernt. Da der val-Spaltenalias außerdem als Teil der FROM-Klausel erstellt wird, ist er für die WHERE-Klausel zugänglich. Wenn Sie also an der Entfernung der NULL-Werte interessiert sind, können Sie dies in der WHERE-Klausel ausdrücklich angeben, indem Sie direkt mit dem Alias der Wertespalte interagieren, etwa so:
SELECT custid, orderyear, valFROM dbo.CustOrders CROSS APPLY ( VALUES(2017, [2017]), (2018, [2018]), (2019, [2019]) ) AS A(orderyear, val)WHERE val IS NICHT NULL;
Der Punkt ist, dass Sie mit dieser Syntax steuern können, ob Sie NULL-Werte behalten oder entfernen möchten. Es ist auf andere Weise flexibler als der UNPIVOT-Operator, da Sie mehrere nichtpivotierte Kennzahlen wie val und qty handhaben können. Mein Fokus in diesem Artikel lag jedoch auf der Fallstricke im Zusammenhang mit NULL-Werten, daher bin ich nicht auf diesen Aspekt eingegangen.
Schlussfolgerung
Das Design der PIVOT- und UNPIVOT-Operatoren führt manchmal zu Fehlern und Fallstricken in Ihrem Code. Die Syntax des PIVOT-Operators lässt Sie das Gruppierungselement nicht explizit angeben. Wenn Sie dies nicht erkennen, können unerwünschte Gruppierungselemente entstehen. Als Best Practice wird empfohlen, dass Sie einen Tabellenausdruck als Eingabe für den PIVOT-Operator verwenden und deshalb explizit steuern, was das Gruppierungselement ist.
Mit der Syntax des UNPIVOT-Operators können Sie nicht steuern, ob Zeilen mit NULL-Werten in der Ergebniswertspalte entfernt oder beibehalten werden sollen. Als Problemumgehung verwenden Sie entweder eine umständliche Lösung mit den Funktionen ISNULL und NULLIF oder eine Lösung, die auf dem APPLY-Operator und der VALUES-Klausel basiert.
Ich erwähnte auch zwei Feedback-Elemente mit Vorschlägen zur Verbesserung der PIVOT- und UNPIVOT-Operatoren mit expliziteren Optionen zur Steuerung des Verhaltens des Operators und seiner Elemente.