IRI stellt jetzt auch Fuzzy-Suchfunktionen bereit, sowohl in seiner kostenlosen Datenbank und seinen Flat-File-Profiling-Tools als auch als verfügbare Feldfunktionsbibliotheken in IRI CoSort, FieldShield und Voracity, um die Datenqualität, Sicherheit und MDM-Fähigkeiten zu verbessern. Dies ist der erste einer Reihe von Artikeln über IRI-Fuzzy-Search-Lösungen, die ihre Anwendung zur Verbesserung der Datenqualität behandeln.
Einführung
Die Richtigkeit oder Zuverlässigkeit von Daten ist eines der großen „V“-Wörter (zusammen mit Volumen, Vielfalt, Geschwindigkeit und Wert), über die IRI et al. im Kontext von Daten- und Unternehmensinformationsmanagement sprechen. Im Allgemeinen definiert IRI zweifelhafte Daten als Daten mit einem oder mehreren dieser Attribute:
- Niedrige Qualität, weil sie inkonsistent, ungenau oder unvollständig ist
- Mehrdeutig (denken Sie an MDM), ungenau (unstrukturiert) oder irreführend (soziale Medien)
- Voreingenommen (Umfragefrage), verrauscht (überflüssig oder kontaminiert) oder anormal (Ausreißer)
- Aus anderen Gründen ungültig (Sind die Daten für die beabsichtigte Verwendung richtig und genau?)
- Unsicher – enthält es PII oder Geheimnisse, und ist das richtig maskiert, reversibel usw.?
Dieser Artikel konzentriert sich nur auf neue Fuzzy-Search-Lösungen für das erste Problem, die Datenqualität. Andere Artikel in diesem Blog diskutieren, wie die IRI-Software die anderen vier Wahrhaftigkeitsprobleme angeht; Bitten Sie um Hilfe, wenn Sie sie nicht finden können.
Über unscharfe Suche
Fuzzy-Suchen finden Wörter oder Wortgruppen (Werte), die anderen Wörtern oder Wortgruppen (Werten) ähnlich, aber nicht unbedingt identisch sind. Diese Art der Suche hat viele Verwendungsmöglichkeiten, z. B. das Auffinden von Sequenzfehlern, Rechtschreibfehlern, vertauschten Zeichen und anderen, die wir später behandeln werden.
Eine Fuzzy-Suche nach ungefähren Wörtern oder Ausdrücken kann dabei helfen, Daten zu finden, die möglicherweise Duplikate zuvor gespeicherter Daten sind. Möglicherweise wurden die Daten jedoch durch Nutzereingaben oder automatische Korrekturen so verändert, dass die Datensätze unabhängig erscheinen.
Der Rest des Artikels behandelt vier Fuzzy-Suchfunktionen, die IRI jetzt unterstützt, wie Sie sie verwenden, um Ihre Daten zu durchsuchen und diese Datensätze zurückzugeben, die den Suchwert annähern.
1. Levenshtein
Der Levenshtein-Algorithmus funktioniert, indem er zwei Wörter oder Sätze nimmt und zählt, wie viele Bearbeitungsschritte erforderlich sind, um ein Wort oder einen Satz in das andere umzuwandeln. Je weniger Schritte erforderlich sind, desto wahrscheinlicher ist es, dass das Wort oder der Ausdruck übereinstimmt. Die Schritte, die die Levenshtein-Funktion ausführen kann, sind:
- Einfügung eines Zeichens in das Wort oder den Satz
- Löschung eines Zeichens aus dem Wort oder Ausdruck
- Ersetzung eines Zeichens in einem Wort oder Satz durch ein anderes
Das folgende ist ein CoSort SortCL-Programm (Auftragsskript), das die Verwendung der Levenshtein-Fuzzy-Suchfunktion demonstriert:
/INFILE=LevenshteinSample.dat /PROCESS=RECORD /FIELD=(ID, TYPE=ASCII, POSITION=1, SEPARATOR="\t") /FIELD=(NAME, TYPE=ASCII, POSITION=2, SEPARATOR="\t") /REPORT /OUTFILE=LevenshteinOutput.csv /PROCESS=CSV /FIELD=(ID, TYPE=ASCII, POSITION=1, SEPARATOR=",") /FIELD=(NAME, TYPE=ASCII, POSITION=2, SEPARATOR=",") /FIELD=(FS_RESULT=fs_levenshtein(NAME, "Barney Oakley"), POSITION=3, SEPARATOR=",") /INCLUDE WHERE FS_RESULT GT 50
Es gibt zwei Teile, die verwendet werden müssen, um die gewünschte Ausgabe zu erzeugen.
FS_Result=fs_levenshtein(NAME, "Barney Oakley")
Diese Zeile ruft die Funktion fs_levenshtein auf und speichert das Ergebnis im Feld FS_RESULT. Die Funktion benötigt zwei Eingabeparameter:
- Das Feld, in dem die Fuzzy-Suche ausgeführt werden soll (NAME in unserem Beispiel)
- Die Zeichenfolge, mit der das Eingabefeld verglichen wird („Barney Oakley“ in unserem Beispiel).
/INCLUDE WHERE FS_RESULT GT 50
Diese Zeile vergleicht das Feld FS_RESULT und prüft, ob es größer als 50 ist, dann werden nur Datensätze mit einem FS_RESULT von mehr als 50 ausgegeben. Das Folgende zeigt die Ausgabe unseres Beispiels.

Wie die Ausgabe zeigt, ist diese Art der Suche nützlich, um Folgendes zu finden:
- Verkettete Namen
- Rauschen
- Rechtschreibfehler
- Vertauschte Zeichen
- Transkriptionsfehler
- Tippfehler
Die Levenshtein-Funktion ist daher auch nützlich, um häufige Dateneingabefehler zu identifizieren. Die Ausführung dauert jedoch von den vier Algorithmen am längsten, da er jedes Zeichen in einer Zeichenfolge mit jedem Zeichen in der anderen vergleicht.
2. Würfelkoeffizient
Der Würfelkoeffizient oder Würfelalgorithmus zerlegt Wörter oder Sätze in Zeichenpaare, vergleicht diese Paare und zählt die Übereinstimmungen. Je mehr Übereinstimmungen die Wörter haben, desto wahrscheinlicher ist es, dass das Wort selbst eine Übereinstimmung ist.
Das folgende SortCL-Skript demonstriert die unscharfe Suchfunktion mit Würfelkoeffizienten.
/INFILE=DiceSample.dat /PROCESS=RECORD /FIELD=(ID, TYPE=ASCII, POSITION=1, SEPARATOR="\t") /FIELD=(NAME, TYPE=ASCII, POSITION=2, SEPARATOR="\t") /REPORT /OUTFILE=DiceOutput.csv /PROCESS=CSV /FIELD=(ID, TYPE=ASCII, POSITION=1, SEPARATOR=",") /FIELD=(NAME, TYPE=ASCII, POSITION=2, SEPARATOR=",") /FIELD=(FS_RESULT=fs_dice(NAME, "Robert Thomas Smith"), POSITION=3, SEPARATOR=",") /INCLUDE WHERE FS_RESULT GT 50
Es gibt zwei Teile, die verwendet werden müssen, um uns die gewünschte Ausgabe zu liefern.
FS_Result=fs_dice(NAME, "Robert Thomas Smith")
Diese Zeile ruft die Funktion fs_dice auf und speichert das Ergebnis im Feld FS_RESULT. Die Funktion benötigt zwei Eingabeparameter:
- Das Feld, auf dem die Fuzzy-Suche ausgeführt werden soll (NAME in unserem Beispiel).
- Der String, mit dem das Eingabefeld verglichen wird („Robert Thomas Smith“ in unserem Beispiel).
/INCLUDE WHERE FS_RESULT GT 50
Diese Zeile vergleicht das Feld FS_RESULT und prüft, ob es größer als 50 ist, dann werden nur Datensätze mit einem FS_RESULT von mehr als 50 ausgegeben. Das Folgende zeigt die Ausgabe unseres Beispiels.
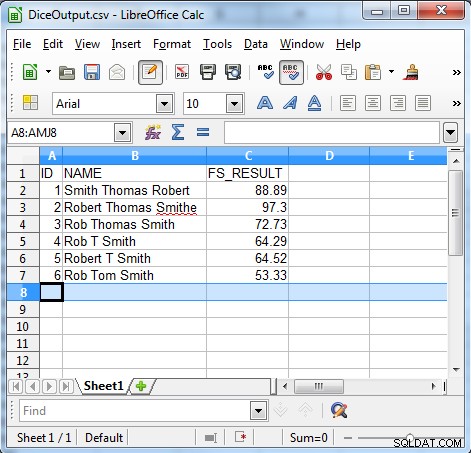
Wie die Ausgabe zeigt, ist der Würfelkoeffizienten-Algorithmus nützlich, um inkonsistente Daten zu finden, wie z. B.:
- Sequenzfehler
- Unfreiwillige Korrekturen
- Spitznamen
- Initialen und Spitznamen
- Unvorhersehbare Verwendung von Initialen
- Lokalisierung
Der Würfelalgorithmus ist schneller als der Levenshtein, kann aber weniger genau werden, wenn es viele einfache Fehler wie Tippfehler gibt.
3. Metaphone und 4. Soundex
Die Metaphone- und Soundex-Algorithmen vergleichen Wörter oder Sätze anhand ihrer phonetischen Laute. Soundex tut dies, indem es das Wort oder den Satz durchliest und einzelne Zeichen betrachtet, während Metaphone sowohl einzelne Zeichen als auch Zeichengruppen betrachtet. Dann geben beide Codes basierend auf der Schreibweise und Aussprache des Wortes aus.
Das folgende SortCL-Skript demonstriert die Suchfunktionen von Soundex und Metasphone:
/INFILE=SoundexSample.dat /PROCESS=RECORD /FIELD=(ID, TYPE=ASCII, POSITION=1, SEPARATOR="\t") /FIELD=(NAME, TYPE=ASCII, POSITION=2, SEPARATOR="\t") /REPORT /OUTFILE=SoundexOutput.csv /PROCESS=CSV /FIELD=(ID, TYPE=ASCII, POSITION=1, SEPARATOR=",") /FIELD=(NAME, TYPE=ASCII, POSITION=2, SEPARATOR=",") /FIELD=(SE_RESULT=fs_soundex(NAME, "John"), POSITION=3, SEPARATOR=",") /FIELD=(MP_RESULT=fs_metaphone(NAME, "John"), POSITION=3, SEPARATOR=",") /INCLUDE WHERE (SE_RESULT GT 0) OR (MP_RESULT GT 0)
In jedem Fall gibt es drei Teile, die verwendet werden müssen, um uns die gewünschte Ausgabe zu liefern.
SE_RESULT=fs_soundex(NAME, "John") MP_RESULT=fs_metaphone(NAME, "John")
Die Zeile ruft die Funktion auf und speichert das Ergebnis im Feld RESULT. Die Funktionen nehmen beide zwei Eingabeparameter:
- Das Feld, in dem die Fuzzy-Suche ausgeführt werden soll (NAME in unserem Beispiel)
- Der xtring, mit dem das Eingabefeld verglichen wird („John“ in unserem Beispiel)
/INCLUDE WHERE (SE_RESULT GT 0) OR (MP_RESULT GT 0)
Diese Zeile vergleicht die Felder SE_RESULT und MP_RESULT und prüft und gibt die Zeile zurück, wenn eines der Felder größer als 0 ist.
Soundex gibt entweder 100 für eine Übereinstimmung oder 0 zurück, wenn es keine Übereinstimmung gibt. Metaphone hat spezifischere Ergebnisse und gibt 100 für eine starke Übereinstimmung, 66 für eine normale Übereinstimmung und 33 für eine geringe Übereinstimmung zurück.
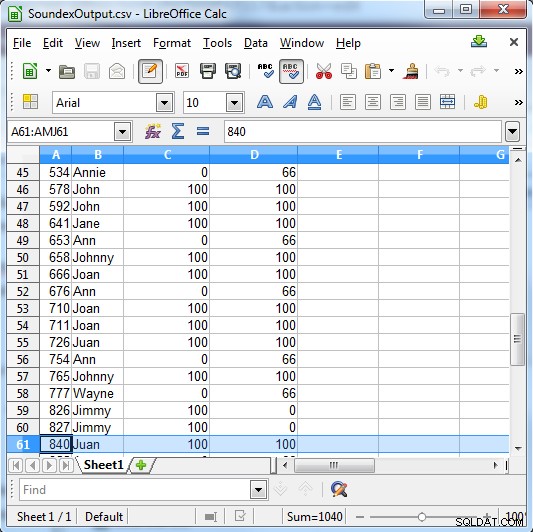
Spalte C zeigt die Soundex-Ergebnisse. Spalte D zeigt die Metaphone-Ergebnisse
Wie die Ausgabe zeigt, ist diese Art der Suche nützlich, um Folgendes zu finden:
- Phonetische Fehler
Bitte senden Sie unten Feedback zu diesem Artikel, und wenn Sie daran interessiert sind, diese Funktionen zu nutzen, wenden Sie sich bitte an Ihren IRI-Vertreter. Siehe unseren nächsten Artikel zur Verwendung dieser Algorithmen im Datenkonsolidierungs-(Qualitäts-)Assistenten der IRI Workbench.