Zu Ihren Verantwortlichkeiten als DBA (oder DBCC CHECKDB . Sie können ein Stück weit dorthin gelangen, indem Sie einen einfachen Wartungsplan mit einer „Check Database Integrity Task“ erstellen – meiner Meinung nach ist dies jedoch nur das Aktivieren eines Kontrollkästchens.
Wenn Sie genauer hinsehen, können Sie nur sehr wenig steuern, wie die Aufgabe funktioniert. Sogar das recht umfangreiche Eigenschaften-Panel zeigt eine ganze Menge Einstellungen für den Unterplan für die Wartung, aber praktisch nichts über DBCC Befehle, die es ausführen wird. Persönlich denke ich, dass Sie einen viel proaktiveren und kontrollierteren Ansatz verfolgen sollten, wie Sie Ihre CHECKDB ausführen Vorgänge in Produktionsumgebungen, indem Sie Ihre eigenen Jobs erstellen und Ihr DBCC manuell erstellen Befehle. Sie können Ihren Zeitplan oder die Befehle selbst an verschiedene Datenbanken anpassen – zum Beispiel ist die ASP.NET-Mitgliederdatenbank wahrscheinlich nicht so wichtig wie Ihre Verkaufsdatenbank und könnte weniger häufige und/oder weniger gründliche Überprüfungen vertragen.
Aber für Ihre wichtigen Datenbanken dachte ich, ich würde einen Beitrag zusammenstellen, um einige der Dinge zu beschreiben, die ich untersuchen würde, um die Unterbrechung DBCC zu minimieren Befehle verursachen können – und vor welchen Mythen und Marketing-Rummeln Sie sich hüten sollten. Und ich möchte Paul „Mr. DBCC“ Randal (@PaulRandal) für seinen wertvollen Beitrag danken – nicht nur zu diesem speziellen Beitrag, sondern auch für die endlosen Ratschläge, die er in seinem Blog #sqlhelp und im SQLskills-Immersionstraining gibt.
Bitte nehmen Sie alle diese Ideen mit Vorsicht und tun Sie Ihr Bestes, um angemessene Tests in Ihrer Umgebung durchzuführen – nicht alle dieser Vorschläge führen zu einer besseren Leistung in allen Umgebungen. Aber Sie sind es sich selbst, Ihren Benutzern und Ihren Stakeholdern schuldig, zumindest die Auswirkungen zu berücksichtigen, die Ihre CHECKDB hat Betriebsabläufe haben könnten, und ergreifen Sie Maßnahmen, um diese Auswirkungen nach Möglichkeit zu mindern – ohne unnötige Risiken einzugehen, indem Sie nicht die richtigen Dinge überprüfen.
Reduzieren Sie das Rauschen und verbrauchen Sie alle Fehler
Egal, wo Sie CHECKDB ausführen verwenden Sie immer den WITH NO_INFOMSGS Möglichkeit. Dadurch werden einfach alle irrelevanten Ausgaben unterdrückt, die Ihnen nur mitteilen, wie viele Zeilen in jeder Tabelle enthalten sind. Wenn Sie an diesen Informationen interessiert sind, können Sie sie durch einfache Abfragen von DMVs erhalten und nicht während DBCC läuft. Das Unterdrücken der Ausgabe macht es viel unwahrscheinlicher, dass Sie eine wichtige Nachricht verpassen, die in all dieser fröhlichen Ausgabe verborgen ist.
Ebenso sollten Sie immer den WITH ALL_ERRORMSGS verwenden Option, aber insbesondere, wenn Sie SQL Server 2008 RTM oder SQL Server 2005 ausführen (in diesen Fällen wird die Liste der Fehler pro Objekt möglicherweise auf 200 gekürzt). Für jede CHECKDB Bei anderen Vorgängen als schnellen Ad-hoc-Prüfungen sollten Sie erwägen, die Ausgabe in eine Datei umzuleiten. Management Studio ist auf 1000 Ausgabezeilen von DBCC CHECKDB beschränkt , sodass Ihnen möglicherweise einige Fehler entgehen, wenn Sie diese Zahl überschreiten.
Obwohl es sich nicht unbedingt um ein Leistungsproblem handelt, verhindert die Verwendung dieser Optionen, dass Sie den Prozess erneut ausführen müssen. Dies ist besonders wichtig, wenn Sie sich mitten in der Notfallwiederherstellung befinden.
Logische Prüfungen nach Möglichkeit auslagern
In den meisten Fällen CHECKDB verbringt den größten Teil seiner Zeit damit, die Daten logisch zu prüfen. Wenn Sie die Möglichkeit haben, diese Überprüfungen an einer echten Kopie durchzuführen der Daten können Sie sich auf die physische Struktur Ihrer Produktionssysteme konzentrieren und den sekundären Server verwenden, um alle logischen Prüfungen durchzuführen und diese Last vom primären zu verringern. Durch sekundären Server , ich meine nur folgendes:
- Der Ort, an dem Sie Ihre vollständigen Wiederherstellungen testen – weil Sie Ihre Wiederherstellungen testen, richtig?
Andere Leute (insbesondere die gigantische Marketingmacht Microsoft) haben Sie vielleicht davon überzeugt, dass andere Arten von sekundären Servern für DBCC geeignet sind Schecks. Zum Beispiel:
- eine lesbare sekundäre AlwaysOn-Verfügbarkeitsgruppe;
- ein Snapshot einer gespiegelten Datenbank;
- ein sekundär versendetes Protokoll;
- SAN-Spiegelung;
- oder andere Variationen…
Leider ist dies nicht der Fall, und keiner dieser sekundären Server ist ein gültiger, zuverlässiger Ort, an dem Sie Ihre Überprüfungen als Alternative zum primären durchführen können. Nur eine Eins-zu-Eins-Sicherung kann als echte Kopie dienen; alles andere, das auf Dinge wie die Anwendung von Protokollsicherungen angewiesen ist, um einen konsistenten Zustand zu erreichen, wird Integritätsprobleme auf dem Primärserver nicht zuverlässig widerspiegeln.
Anstatt also zu versuchen, Ihre logischen Prüfungen auf eine Sekundärseite auszulagern und sie niemals auf der Primärseite durchzuführen, schlage ich Folgendes vor:
- Stellen Sie sicher, dass Sie die Wiederherstellungen Ihrer vollständigen Sicherungen regelmäßig testen. Und nein, das beinhaltet nicht
COPY_ONLYSicherungen von einer sekundären AG aus den gleichen Gründen wie oben – dies wäre nur gültig, wenn Sie die sekundäre Wiederherstellung gerade mit einer vollständigen Wiederherstellung initiiert haben. - Führen Sie
DBCC CHECKDBaus oft gegen die volle wiederherstellen, bevor Sie etwas anderes tun. Auch hier wird durch das erneute Abspielen von Protokolldatensätzen diese Datenbank als echte Kopie ungültig der Quelle. - Führen Sie
DBCC CHECKDBaus gegen Ihre primäre, möglicherweise aufgeteilt auf eine Weise, die Paul Randal vorschlägt, und/oder in einem weniger häufigen Zeitplan und/oder mitPHYSICAL_ONLYöfter als nicht. Dies kann davon abhängen, wie oft und zuverlässig Sie auftreten (2). - Gehen Sie niemals davon aus, dass Prüfungen gegen die Sekundärseite ausreichen. Selbst bei einer exakten Kopie Ihrer primären Datenbank können immer noch physische Probleme im E/A-Subsystem Ihrer primären Datenbank auftreten, die niemals auf die sekundäre Datenbank übertragen werden.
- Immer
DBCCanalysieren Ausgang. Es einfach auszuführen und zu ignorieren, um es von irgendeiner Liste abzuhaken, ist genauso hilfreich, wie Backups auszuführen und Erfolg zu behaupten, ohne jemals zu testen, ob Sie dieses Backup bei Bedarf tatsächlich wiederherstellen können.
Experimentieren Sie mit den Trace-Flags 2549, 2562 und 2566
Ich habe zwei Trace-Flags (2549 und 2562) gründlich getestet und festgestellt, dass sie zu erheblichen Leistungsverbesserungen führen können, aber Lonny berichtet, dass sie nicht mehr notwendig oder nützlich sind. Wenn Sie 2016 oder neuer verwenden, überspringen Sie diesen gesamten Abschnitt . Wenn Sie eine ältere Version verwenden, werden diese beiden Trace-Flags in KB #2634571 ausführlicher beschrieben, aber im Wesentlichen:
- Trace-Flag 2549
- Dies optimiert den checkdb-Prozess, indem jede einzelne Datenbankdatei so behandelt wird, als befinde sie sich auf einer eindeutigen zugrunde liegenden Festplatte. Dies ist in Ordnung, wenn Ihre Datenbank eine einzelne Datendatei enthält oder wenn Sie wissen, dass sich jede Datenbankdatei tatsächlich auf einem separaten Laufwerk befindet. Wenn Ihre Datenbank mehrere Dateien enthält und diese eine einzelne, direkt angeschlossene Spindel gemeinsam nutzen, sollten Sie sich vor diesem Trace-Flag in Acht nehmen, da es mehr schaden als nützen kann.
WICHTIG :sql.sasquatch meldet eine Regression in diesem Trace-Flag-Verhalten in SQL Server 2014.
- Dies optimiert den checkdb-Prozess, indem jede einzelne Datenbankdatei so behandelt wird, als befinde sie sich auf einer eindeutigen zugrunde liegenden Festplatte. Dies ist in Ordnung, wenn Ihre Datenbank eine einzelne Datendatei enthält oder wenn Sie wissen, dass sich jede Datenbankdatei tatsächlich auf einem separaten Laufwerk befindet. Wenn Ihre Datenbank mehrere Dateien enthält und diese eine einzelne, direkt angeschlossene Spindel gemeinsam nutzen, sollten Sie sich vor diesem Trace-Flag in Acht nehmen, da es mehr schaden als nützen kann.
- Trace-Flag 2562
- Dieses Flag behandelt den gesamten checkdb-Prozess als einen einzelnen Stapel, auf Kosten einer höheren tempdb-Nutzung (bis zu 5 % der Datenbankgröße).
- Verwendet einen besseren Algorithmus, um zu bestimmen, wie Seiten aus der Datenbank gelesen werden, wodurch Latch-Konflikte reduziert werden (insbesondere für
DBCC_MULTIOBJECT_SCANNER). Beachten Sie, dass sich diese spezielle Verbesserung im Codepfad von SQL Server 2012 befindet, sodass Sie auch ohne Ablaufverfolgungsflag davon profitieren. Dies kann Fehler vermeiden wie:
Zeitüberschreitung beim Warten auf Latch:Klasse 'DBCC_MULTIOBJECT_SCANNER'.
- Die beiden obigen Trace-Flags sind in den folgenden Versionen verfügbar:
- Kumulatives Update für SQL Server 2008 Service Pack 2 9+
(10.00.4330 -> 10.00.5499)SQL Server 2008 Service Pack 3 Kumulatives Update 4+
(10.00.5775+)Kumulatives Update für SQL Server 2008 R2 RTM 11+
(10.50.1809 -> 10.50.2424)SQL Server 2008 R2 Service Pack 1 Kumulatives Update 4+
(10.50.2796 -> 10.50.3999)SQL Server 2008 R2 Service Pack 2
(10.50.4000+)SQL Server 2012, alle Versionen
(11.00.2100+) - Trace-Flag 2566
- Wenn Sie immer noch SQL Server 2005 verwenden, versucht dieses Trace-Flag, das in 2005 SP2 CU#9 (9.00.3282) eingeführt wurde (obwohl es nicht im Knowledge Base-Artikel dieses kumulativen Updates, KB #953752, dokumentiert ist), die schlechte Leistung zu korrigieren von
DATA_PURITYprüft auf x64-basierten Systemen. An einem Punkt konnten Sie weitere Details in KB #945770 sehen, aber es scheint, dass dieser Artikel sowohl von der Support-Website von Microsoft als auch von der WayBack-Maschine bereinigt wurde. Dieses Ablaufverfolgungsflag sollte in neueren Versionen von SQL Server nicht mehr erforderlich sein, da das Problem im Abfrageprozessor behoben wurde.
- Wenn Sie immer noch SQL Server 2005 verwenden, versucht dieses Trace-Flag, das in 2005 SP2 CU#9 (9.00.3282) eingeführt wurde (obwohl es nicht im Knowledge Base-Artikel dieses kumulativen Updates, KB #953752, dokumentiert ist), die schlechte Leistung zu korrigieren von
Wenn Sie eines dieser Ablaufverfolgungsflags verwenden, empfehle ich dringend, sie mit DBCC TRACEON auf Sitzungsebene festzulegen und nicht als Ablaufverfolgungsflag beim Start. Sie können sie nicht nur deaktivieren, ohne SQL Server durchlaufen zu müssen, sondern sie auch nur dann implementieren, wenn bestimmte CHECKDB ausgeführt werden Befehle, im Gegensatz zu Operationen, die irgendeine Art von Reparatur verwenden.
E/A-Auswirkung reduzieren:tempdb optimieren
DBCC CHECKDB kann tempdb stark nutzen, planen Sie also dort die Ressourcennutzung ein. Dies ist normalerweise in jedem Fall eine gute Sache. Für CHECKDB Sie sollten tempdb richtig Platz zuweisen; das Letzte, was Sie wollen, ist für CHECKDB Fortschritt (und alle anderen gleichzeitigen Vorgänge) auf ein automatisches Wachstum warten müssen. Mit WITH ESTIMATEONLY können Sie sich ein Bild von den Anforderungen machen , wie Paul hier erklärt. Beachten Sie jedoch, dass die Schätzung aufgrund eines Fehlers in SQL Server 2008 R2 recht niedrig sein kann. Achten Sie auch bei Verwendung des Ablaufverfolgungsflags 2562 darauf, den zusätzlichen Platzbedarf zu berücksichtigen.
Und natürlich sind auch hier alle typischen Ratschläge zur Optimierung von tempdb auf nahezu jedem System angebracht:Stellen Sie sicher, dass tempdb auf einem eigenen Satz schnell ist Spindeln, stellen Sie sicher, dass sie so dimensioniert ist, dass sie alle anderen gleichzeitigen Aktivitäten aufnehmen kann, ohne wachsen zu müssen, stellen Sie sicher, dass Sie eine optimale Anzahl von Datendateien verwenden usw. Einige andere Ressourcen, die Sie in Betracht ziehen könnten:
- Optimieren der tempdb-Leistung (MSDN)
- Kapazitätsplanung für tempdb (MSDN)
- Jeden Tag ein SQL Server-DBA-Mythos:(12/30) tempdb sollte immer eine Datendatei pro Prozessorkern haben
E/A-Auswirkung reduzieren:Snapshot steuern
Um CHECKDB auszuführen , versuchen moderne Versionen von SQL Server, einen versteckten Snapshot Ihrer Datenbank auf demselben Laufwerk zu erstellen (oder auf allen Laufwerken, wenn sich Ihre Datendateien über mehrere Laufwerke erstrecken). Sie können diesen Mechanismus nicht steuern, aber wenn Sie steuern möchten, wo CHECKDB funktioniert, erstellen Sie zunächst Ihren eigenen Snapshot (Enterprise Edition erforderlich) auf einem beliebigen Laufwerk und führen Sie DBCC aus Befehl gegen den Snapshot. In beiden Fällen sollten Sie diesen Vorgang während einer relativen Ausfallzeit ausführen, um die Copy-on-Write-Aktivität zu minimieren, die den Snapshot durchlaufen wird. Und Sie möchten nicht, dass dieser Zeitplan mit umfangreichen Schreibvorgängen wie der Indexwartung oder ETL in Konflikt gerät.
Möglicherweise haben Sie Vorschläge gesehen, um CHECKDB zu erzwingen um im Offline-Modus mit WITH TABLOCK ausgeführt zu werden Möglichkeit. Ich rate dringend von diesem Ansatz ab. Wenn Ihre Datenbank aktiv verwendet wird, wird die Auswahl dieser Option die Benutzer nur frustrieren. Und wenn die Datenbank nicht aktiv verwendet wird, sparen Sie keinen Speicherplatz, indem Sie einen Snapshot vermeiden, da keine Copy-on-Write-Aktivität gespeichert werden muss.
E/A-Auswirkungen reduzieren:665/1450/1452-Fehler vermeiden
In einigen Fällen wird möglicherweise einer der folgenden Fehler angezeigt:
Das Betriebssystem hat den Fehler 1450 (Es sind nicht genügend Systemressourcen vorhanden, um den angeforderten Dienst auszuführen.) während eines Schreibvorgangs am Offset 0x[…] in die Datei mit dem Handle 0x[…] an SQL Server zurückgegeben. Dies ist normalerweise ein vorübergehender Zustand, und der SQL Server wiederholt den Vorgang immer wieder. Wenn der Zustand fortbesteht, müssen sofortige Maßnahmen ergriffen werden, um ihn zu beheben.
Das Betriebssystem hat während eines Schreibvorgangs bei Offset 0x[…] in Datei „[Datei]“
den Fehler 665 (der angeforderte Vorgang konnte aufgrund einer Dateisystembeschränkung nicht abgeschlossen werden) an SQL Server zurückgegeben
Hier finden Sie einige Tipps, um das Risiko dieser Fehler während CHECKDB zu verringern Operationen und Reduzierung ihrer Auswirkungen im Allgemeinen – mit mehreren verfügbaren Fixes, abhängig von Ihrem Betriebssystem und Ihrer SQL Server-Version:
- Sparse File Errors:1450 oder 665 aufgrund von Dateifragmentierung:Fixes und Problemumgehungen
- SQL Server meldet Betriebssystemfehler 1450 oder 1452 oder 665 (Wiederholungen)
CPU-Belastung reduzieren
DBCC CHECKDB ist standardmäßig multithreaded (jedoch nur in der Enterprise Edition). Wenn Ihr System CPU-gebunden ist oder Sie nur CHECKDB möchten Um weniger CPU auf Kosten einer längeren Laufzeit zu verbrauchen, können Sie die Parallelität auf verschiedene Arten reduzieren:
- Verwenden Sie Resource Governor auf 2008 und höher, solange Sie die Enterprise Edition ausführen. Um nur DBCC-Befehle auf einen bestimmten Ressourcenpool oder eine bestimmte Arbeitsauslastungsgruppe auszurichten, müssen Sie eine Klassifizierungsfunktion schreiben, die die Sitzungen identifizieren kann, die diese Arbeit ausführen (z. B. eine bestimmte Anmeldung oder eine Job_id).
- Verwenden Sie das Trace-Flag 2528, um die Parallelität für
DBCC CHECKDBzu deaktivieren (sowieCHECKFILEGROUPundCHECKTABLE). Das Ablaufverfolgungsflag 2528 wird hier beschrieben. Dies gilt natürlich nur in der Enterprise Edition, denn trotz allem, was Books Online derzeit sagt, ist die Wahrheit, dassCHECKDBläuft nicht parallel in der Standard Edition. - Während der
DBCCDer Befehl selbst unterstütztMAXDOPnicht (zumindest vor SQL Server 2014 SP2) wird die globale Einstellungmax degree of parallelismrespektiert . Wahrscheinlich nicht etwas, was ich in der Produktion tun würde, es sei denn, ich hätte keine anderen Optionen, aber dies ist eine übergreifende Möglichkeit, bestimmteDBCCzu steuern Befehle, wenn Sie sie nicht expliziter ansprechen können.
Wir haben um eine bessere Kontrolle über die Anzahl der CPUs gebeten, die DBCC CHECKDB ausführen verwendet, aber sie wurden bis SQL Server 2014 SP2 wiederholt verweigert. Sie können also jetzt WITH MAXDOP = n hinzufügen zum Befehl.
Meine Ergebnisse
Ich wollte einige dieser Techniken in einer Umgebung demonstrieren, die ich kontrollieren konnte. Ich habe AdventureWorks2012 installiert und es dann mit dem von Jonathan Kehayias (Blog | @SQLPoolBoy) geschriebenen AW-Erweiterungsskript erweitert, wodurch die Datenbank auf etwa 7 GB angewachsen ist. Dann habe ich eine Reihe von CHECKDB ausgeführt Befehle dagegen und zeitlich festgelegt. Ich habe eine einfache DBCC CHECKDB verwendet allein, dann verwenden alle anderen Befehle WITH NO_INFOMSGS, ALL_ERRORMSGS . Dann vier Tests mit (a) keinen Trace-Flags, (b) 2549, (c) 2562 und (d) sowohl 2549 als auch 2562. Dann habe ich diese vier Tests wiederholt, aber den PHYSICAL_ONLY hinzugefügt Option, die alle logischen Prüfungen umgeht. Die Ergebnisse (gemittelt über 10 Testläufe) sind aussagekräftig:
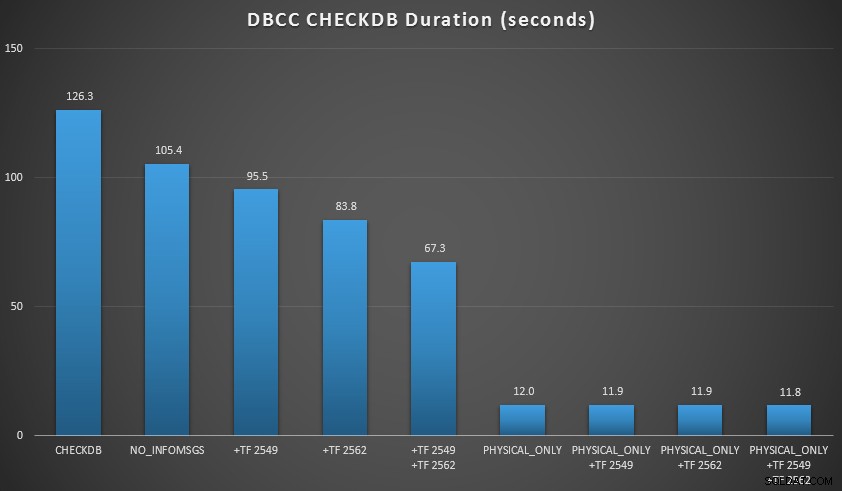
CHECKDB-Ergebnisse gegen 7-GB-Datenbank
Dann habe ich die Datenbank weiter erweitert, indem ich viele Kopien der beiden erweiterten Tabellen erstellte, was zu einer Datenbankgröße knapp über 70 GB führte, und die Tests erneut ausgeführt. Die Ergebnisse, wiederum gemittelt über 10 Testläufe:
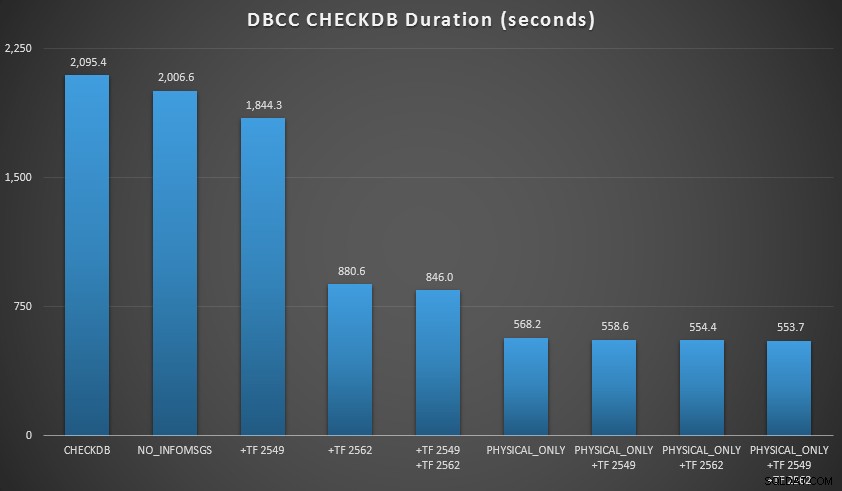
CHECKDB-Ergebnisse gegen 70-GB-Datenbank
In diesen beiden Szenarien habe ich Folgendes gelernt (wieder unter Berücksichtigung dessen, dass Ihre Laufleistung variieren kann und Sie Ihre eigenen Tests durchführen müssen, um aussagekräftige Schlussfolgerungen zu ziehen):
- Wenn ich logische Prüfungen durchführen muss:
- Bei kleinen Datenbankgrößen ist die
NO_INFOMSGSOption kann die Verarbeitungszeit erheblich verkürzen, wenn die Prüfungen in SSMS ausgeführt werden. Bei größeren Datenbanken nimmt dieser Vorteil jedoch ab, da die Zeit und Arbeit, die für die Weitergabe der Informationen aufgewendet wird, einen so unbedeutenden Teil der Gesamtdauer ausmacht. 21 Sekunden von 2 Minuten sind beträchtlich; 88 Sekunden von 35 Minuten, nicht so sehr. - Die beiden von mir getesteten Trace-Flags hatten einen erheblichen Einfluss auf die Leistung – was einer Laufzeitverkürzung von 40–60 % entspricht, wenn beide zusammen verwendet werden.
- Bei kleinen Datenbankgrößen ist die
- Wenn ich logische Prüfungen auf einen sekundären Server verschieben kann (wieder unter der Annahme, dass ich an anderer Stelle logische Prüfungen gegen eine echte Kopie durchführe ):
- Ich kann die Verarbeitungszeit auf meiner primären Instanz im Vergleich zu einer standardmäßigen
CHECKDBum 70–90 % reduzieren Anruf ohne Optionen. - In meinem Szenario hatten die Trace-Flags sehr wenig Einfluss auf die Dauer bei der Ausführung von
PHYSICAL_ONLYSchecks.
- Ich kann die Verarbeitungszeit auf meiner primären Instanz im Vergleich zu einer standardmäßigen
Natürlich, und ich kann das nicht genug betonen, sind dies relativ kleine Datenbanken und werden nur verwendet, damit ich wiederholte, gemessene Tests in angemessener Zeit durchführen kann. Dieser Server hatte 80 logische CPUs und 128 GB RAM, und ich war der einzige Benutzer. Dauer und Interaktion mit anderen Workloads auf dem System können diese Ergebnisse ziemlich verzerren. Hier ist ein kurzer Einblick in die typische CPU-Auslastung mit SQL Sentry während einer der CHECKDB Operationen (und keine der Optionen hat die Gesamtauswirkung auf die CPU wirklich geändert, nur die Dauer):
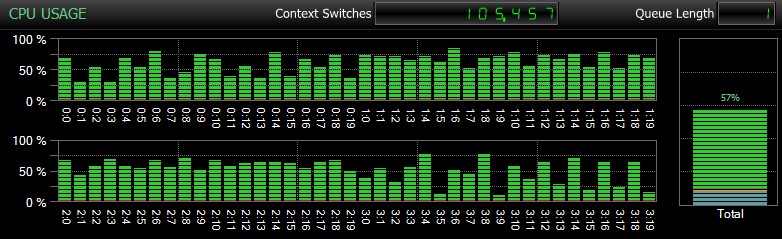
CPU-Auswirkung während CHECKDB – Beispielmodus
Und hier ist eine weitere Ansicht, die ähnliche CPU-Profile für drei verschiedene Beispiel-CHECKDB zeigt Operationen im historischen Modus (ich habe eine Beschreibung der drei Tests in diesem Bereich überlagert):
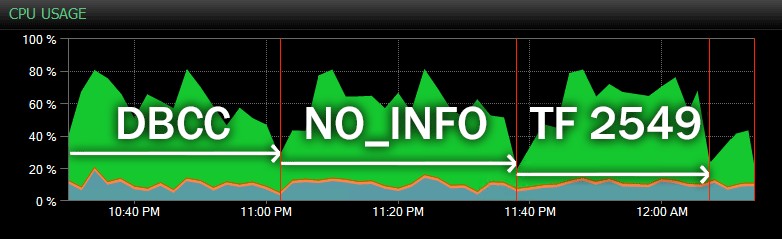
CPU-Auswirkung während CHECKDB – historischer Modus
Bei noch größeren Datenbanken, die auf stärker ausgelasteten Servern gehostet werden, sehen Sie möglicherweise unterschiedliche Auswirkungen, und Ihre Laufleistung wird sehr wahrscheinlich variieren. Führen Sie daher bitte Ihre Due Diligence durch und testen Sie diese Optionen und Trace-Flags während einer typischen gleichzeitigen Arbeitslast, bevor Sie entscheiden, wie Sie CHECKDB angehen möchten .
Schlussfolgerung
DBCC CHECKDB ist ein sehr wichtiger, aber oft unterschätzter Teil Ihrer Verantwortung als DBA oder Architekt und entscheidend für den Schutz Ihrer Unternehmensdaten. Nehmen Sie diese Verantwortung nicht auf die leichte Schulter und tun Sie Ihr Bestes, um sicherzustellen, dass Sie nichts opfern, um die Auswirkungen auf Ihre Produktionsinstanzen zu verringern. Am wichtigsten:Schauen Sie über die Marketingdatenblätter hinaus, um sicherzugehen, dass Sie verstehen, wie gültig diese Versprechen sind und ob Sie bereit sind, die Daten Ihres Unternehmens darauf zu setzen. Bei einigen Schecks zu sparen oder sie an ungültige sekundäre Standorte zu verlagern, könnte eine Katastrophe sein, die auf uns wartet.
Sie sollten auch diese PSS-Artikel lesen:
- Eine schnellere CHECKDB – Teil I
- Eine schnellere CHECKDB – Teil II
- Eine schnellere CHECKDB – Teil III
- Eine schnellere CHECKDB – Teil IV (SQL CLR UDTs)
Und dieser Beitrag von Brent Ozar:
- 3 Möglichkeiten, DBCC CHECKDB schneller auszuführen
Schließlich, wenn Sie eine ungelöste Frage zu DBCC CHECKDB haben , posten Sie es unter dem Hashtag #sqlhelp auf Twitter. Paul überprüft dieses Tag häufig, und da sein Bild im Hauptartikel von Books Online erscheinen sollte, ist es wahrscheinlich, dass er es kann, wenn jemand darauf antworten kann. Wenn es für 140 Zeichen zu komplex ist, können Sie hier fragen (und ich werde dafür sorgen, dass Paul es irgendwann sieht) oder auf einer Forumsseite wie Database Administrators Stack Exchange posten.