Lebensversicherungen sind etwas, von dem wir alle hoffen, dass wir es nicht brauchen werden, aber wie wir wissen, ist das Leben unberechenbar. In diesem Artikel konzentrieren wir uns auf die Formulierung eines Datenmodells, das eine Lebensversicherungsgesellschaft verwenden kann, um ihre Informationen zu speichern.
Lebensversicherung als Konzept
Bevor wir mit der Diskussion des tatsächlichen Datenmodells für eine Lebensversicherungsgesellschaft beginnen, erinnern wir uns kurz daran, was eine Versicherung ist und wie sie funktioniert, damit wir eine bessere Vorstellung davon bekommen, womit wir arbeiten.
Versicherungen sind ein ziemlich altes Konzept, das sogar bis ins Mittelalter zurückreicht, als viele Zünfte Versicherungspolicen anboten, um ihre Mitglieder in unerwarteten Situationen zu schützen. Sogar der berühmte Astronom, Mathematiker, Wissenschaftler und Erfinder Edmund Halley versuchte sich im Versicherungswesen und arbeitete an Statistiken und Sterblichkeitsraten, die das Rückgrat moderner Versicherungsmodelle bildeten.
Warum sollten Sie für die Versicherung zahlen? Die Idee ist ganz einfach – Sie zahlen einen bestimmten Betrag (die Prämie) im Austausch für die Garantie der Versicherungsgesellschaft, dass Sie oder Ihre Familie finanziell entschädigt werden, wenn Ihnen oder Ihrem Eigentum etwas Unerwartetes passiert. Bei einer Lebensversicherung bestimmen Sie einen Begünstigten, der im Todesfall einen Geldbetrag (die Leistung) erhält. Die Idee ist, dass dieses Geld ihnen hilft, sich von ihrem Verlust zu erholen, insbesondere wenn Ihr Tod finanzielle Probleme verursacht.
Natürlich zahlen Versicherungsunternehmen in der Regel viel weniger Leistungen aus, als sie aus Prämien und aus der Anlage Ihres Geldes beispielsweise an der Börse verdienen. Andernfalls würden sie bankrott gehen und das ganze System würde zusammenbrechen!
Das ist so ziemlich das Wesentliche. Nachdem wir das geklärt haben, werfen wir einen Blick auf das Datenmodell einer typischen Lebensversicherungsgesellschaft.
Das Datenmodell:Übersicht
Das Datenmodell, mit dem wir arbeiten werden, besteht aus fünf Themenbereichen:
- Mitarbeiter
- Produkte
- Kunden
- Angebote
- Zahlungen
Wir werden jeden dieser Abschnitte in der oben aufgeführten Reihenfolge ausführlicher behandeln.
Themenbereich Nr. 1:Mitarbeiter
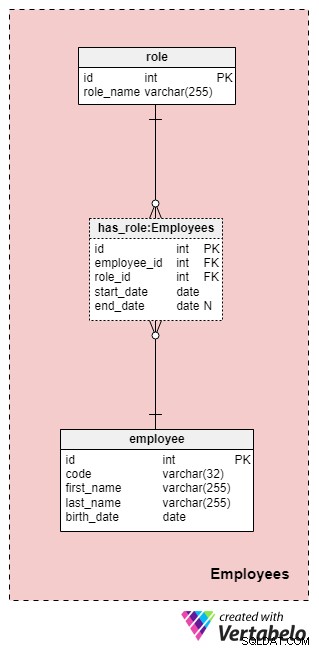
Dieser Bereich ist nicht unbedingt spezifisch für dieses Datenmodell, aber dennoch sehr wichtig, da die darin enthaltenen Tabellen von anderen Themenbereichen referenziert werden. Für die Zwecke unseres Versicherungsdatenmodells müssen wir natürlich wissen, wer welche Aktion durchgeführt hat (z>
Die Liste aller Mitarbeiter des Unternehmens wird im employee Tisch. Für jeden Mitarbeiter speichern wir die folgenden Informationen:
code— ein eindeutiger Schlüssel, der einen einzelnen Mitarbeiter identifiziert. Da der Code als Attribut in anderen Tabellen verwendet wird, dient er in dieser Tabelle als alternativer Schlüssel.first_nameundlast_name— den Vor- und Nachnamen des Mitarbeiters.birth_date— das Geburtsdatum des Arbeitnehmers.
Natürlich könnten wir sicherlich noch viele andere mitarbeiterbezogene Attribute in diese Tabelle aufnehmen, aber diese vier sind vorerst mehr als genug. Wir werden diesem Muster im gesamten Artikel folgen und versuchen, die Dinge so einfach wie möglich zu halten, aber beachten Sie, dass Sie dieses Datenmodell auf jeden Fall um zusätzliche Informationen erweitern können.
Da Mitarbeiter ihre Rolle in unserem Unternehmen jederzeit ändern können, benötigen wir eine Wörterbuchtabelle, um Unternehmensrollen darzustellen, und eine Tabelle, um Werte zu speichern. Die Liste aller möglichen Rollen, die Mitarbeiter bei unserer Lebensversicherung einnehmen können, ist in der role Wörterbuch. Es hat nur ein Attribut namens role_name die eindeutig identifizierende Werte enthält.
Wir verknüpfen Mitarbeiter und Rollen mithilfe von has_role Tisch. Neben den Fremdschlüsseln employee_id und role_id speichern wir zwei Werte:start_date und end_date . Diese beiden Werte bezeichnen den Bereich, in dem diese Unternehmensrolle für einen bestimmten Mitarbeiter aktiv war. Das end_date enthält den Wert null, bis ein Enddatum für die Rolle dieses Mitarbeiters bestimmt wurde. Der alternative Schlüssel für diese Tabelle ist die Kombination aus employee_id , role_id und start_date . Um zu vermeiden, dass dieselbe Rolle für denselben Mitarbeiter dupliziert wird, müssen wir jedes Mal, wenn wir der Tabelle einen neuen Datensatz hinzufügen oder einen vorhandenen aktualisieren, programmgesteuert nach Überschneidungen suchen.
Themenbereich Nr. 2:Produkte
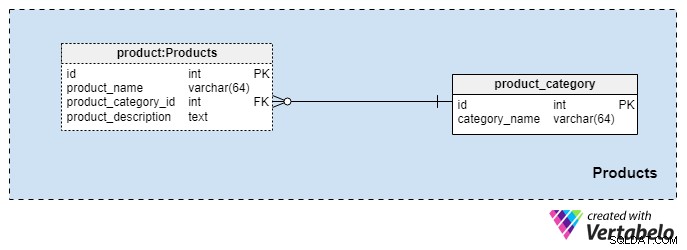
Dieser Themenbereich ist recht klein und enthält nur zwei Tabellen. Werte aus diesen Tabellen sind Voraussetzungen für unsere anderen Fachgebiete, daher gehen wir kurz darauf ein.
Die product_category Wörterbuch speichert die allgemeinsten Kategorien von Produkten, die wir unseren Kunden anbieten möchten. Der einzige Wert, den wir in dieser Tabelle speichern, ist der eindeutige category_name um die Art der von uns angebotenen Versicherungen zu bezeichnen, z. B. eine persönliche Lebensversicherung, eine Familienlebensversicherung usw.
Wir kategorisieren unsere Produkte noch weiter mit dem product Tisch. Diese Tabelle stellt die tatsächlichen Produkte dar, die wir verkaufen, und nicht ihre Kategorien. Wie Sie sich vorstellen können, können wir Produkte nach Dauer gruppieren (z. B. 10 oder 20 Jahre oder sogar ein Leben lang). Wenn wir uns dafür entscheiden, haben wir wahrscheinlich Produkte mit derselben product_category_id aber unterschiedliche Namen und Beschreibungen. Für jedes Produkt speichern wir die folgenden grundlegenden Informationen:
product_name— der Name dieses Produkts. Er wird als alternativer Schlüssel für diese Tabelle in Kombination mit derproduct_category_idverwendet Attribut. Es ist unwahrscheinlich, dass wir zwei Produkte mit demselben Namen haben, die zu unterschiedlichen Kategorien gehören, aber es ist dennoch möglich.product_category_id— identifiziert die Kategorie, zu der dieses Produkt gehört.product_description— Textbeschreibung dieses Produkts.
Themenbereich Nr. 3:Kunden
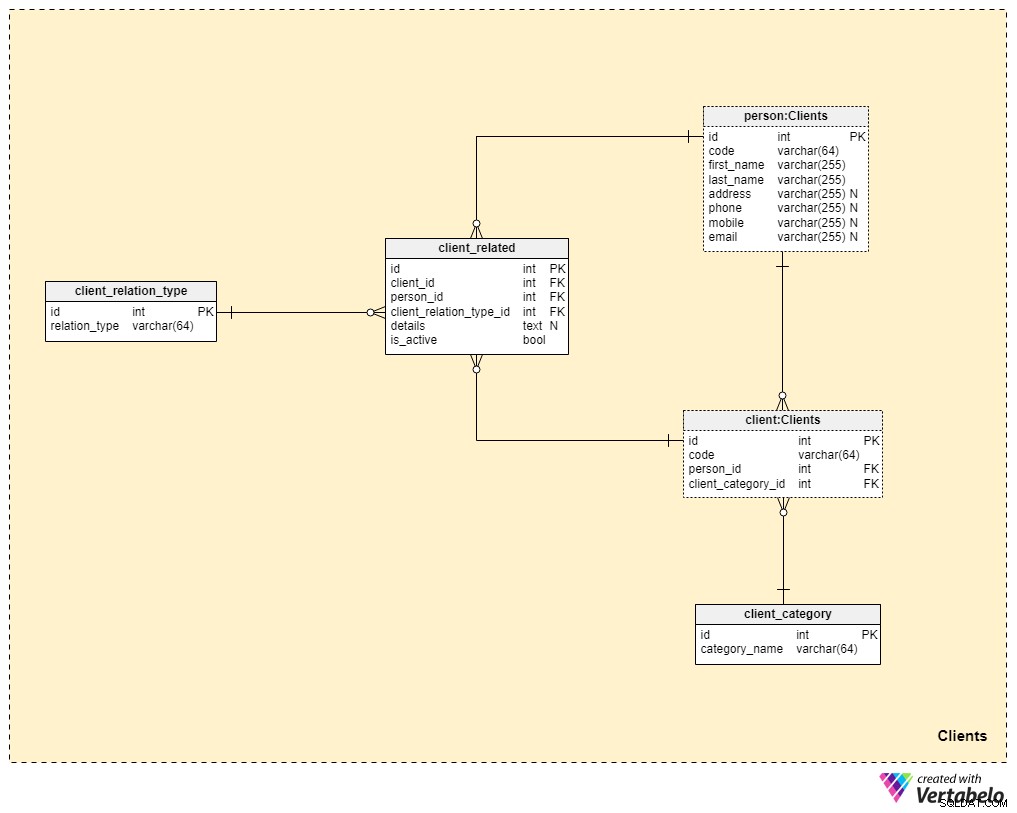
Wir kommen dem Kern unseres Datenmodells jetzt viel näher, aber wir sind noch nicht ganz dort. Lebensversicherungen sind einzigartig, da eine Police auf ein Familienmitglied oder eine andere Person übertragen werden kann, während Policen für andere Versicherungsformen (z. B. Krankenversicherung oder Autoversicherung) einem einzigen Kunden gehören und nicht übertragbar sind. Aus diesem Grund müssen wir nicht nur Informationen über den Kunden speichern, dem die Police gehört, sondern auch Informationen über verbundene Personen und deren Beziehung zum Kunden.
Wir beginnen mit dem client Tisch. Für jeden Kunden speichern wir den eindeutigen Code, der für diesen Kunden generiert oder manuell eingefügt wurde, sowie die Fremdschlüssel, die auf die Tabelle mit ihren persönlichen Daten verweisen (person_id ) und die Tabelle mit unserer internen Kategorisierung (client_category_id ).
Die client_category Wörterbuch ermöglicht es uns, Kunden basierend auf ihren demografischen und finanziellen Details zu gruppieren. Die Kundenkategorien werden dann verwendet, um die Versicherungspolice zu bestimmen, die wir einem bestimmten Kunden anbieten können. Hier speichern wir nur eine Liste eindeutiger Werte, die wir dann Kunden zuweisen.
Da wir über Lebensversicherungen sprechen, gehen wir davon aus, dass ein Kunde eine einzelne Person ist. Wie bereits erwähnt, kann es jedoch andere Personen geben, die mit dem Kunden verwandt sind, auf die die Police übertragen werden kann oder die die Versicherungsleistung nach dem Tod des Kunden erhalten können. Aus diesem Grund haben wir eine separate person Tisch. Für jeden Datensatz in dieser Tabelle speichern wir die folgenden Informationen:
code— ein automatisch generierter oder manuell eingefügter Wert zur eindeutigen Identifizierung der betreffenden Person.first_nameundlast_name— den Vor- bzw. Nachnamen der Person.address,phone,mobileundemail— Kontaktdaten dieser Person, die alle willkürliche Werte enthalten.
Die verbleibenden zwei Tabellen in diesem Themenbereich werden benötigt, um die Art der Beziehung zwischen Kunden und anderen Personen zu beschreiben.
Die Liste aller möglichen Beziehungstypen wird im client_relation_type Wörterbuch. Wie bei anderen Wörterbüchern enthält dieses eine Liste eindeutiger Namen, die wir später verwenden, wenn wir die Beziehung zwischen einem bestimmten Kunden und einer anderen Person beschreiben.
Tatsächliche Beziehungsdaten werden im client_related Tisch. Für jeden Datensatz in dieser Tabelle speichern wir Verweise auf den Kunden (client_id ), die zugehörige Person (person_id ), die Art dieser Beziehung (client_relation_type_id ), alle zusätzlichen Details (details ), falls vorhanden, und ein Flag, das angibt, ob die Beziehung derzeit aktiv ist (is_active ). Der alternative Schlüssel in dieser Tabelle wird durch die Kombination von client_id definiert , person_id und client_relation_type_id .
Themenbereich Nr. 4:Angebote
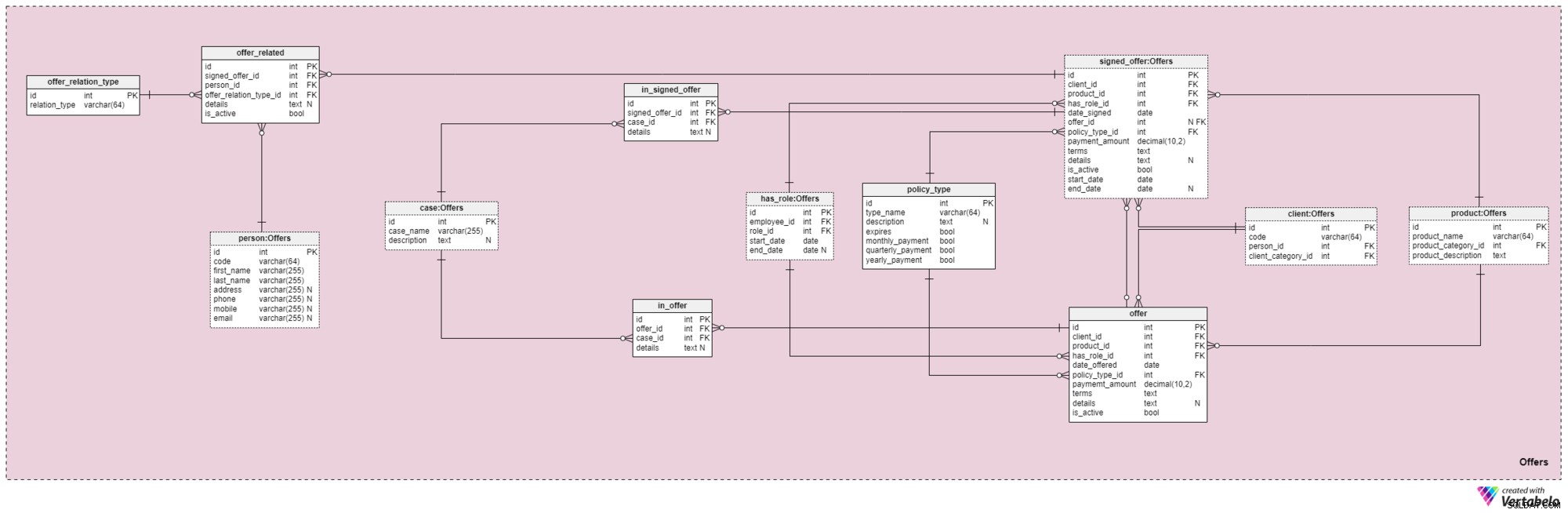
Dieser und der folgende Themenbereich bilden den Kern dieses Datenmodells. Sie decken Angebote und unterzeichnete Policen sowie Zahlungen im Zusammenhang mit Angeboten ab. Zunächst beschreiben wir den Themenbereich Angebote. Es mag komplex erscheinen, da es 12 Tabellen enthält. Vier dieser 12 (has_role , product , client , und person ) wurden in früheren Themenbereichen beschrieben, daher werden wir unsere Diskussion hier nicht wiederholen.
Das offer und signed_offer Tabellen haben ähnliche Strukturen, da sie zum Speichern sehr ähnlicher Daten in unserem Modell verwendet werden. Jedoch während offer wird hauptsächlich verwendet, um alle Policen (und ihre Details) zu speichern, die wir unseren Kunden angeboten haben, der signed_offer Die Tabelle wird ausschließlich zum Speichern von Informationen über Kunden verwendet, die tatsächlich Policen bei unserem Unternehmen unterzeichnet haben. Wir werden diese Tabellen zusammen abdecken und alle Unterschiede feststellen, wo sie erscheinen. Die Attribute in diesen beiden Tabellen lauten wie folgt:
client_id— Verweis auf die eindeutige Kennung des Kunden, der ein bestimmtes Angebot unterzeichnet hat.product_id— Verweis auf die eindeutige Kennung des Produkts, das im unterzeichneten Angebot enthalten war.has_role_id— Verweis auf die ID des Mitarbeiters und die Rolle, die er zum Zeitpunkt der Angebotspräsentation/-unterzeichnung innehatte.date_offeredunddate_signed— tatsächliche Daten, die angeben, wann dieses Angebot dem Kunden vorgelegt bzw. wann es unterzeichnet wurde.offer_id— ein Verweis auf das vorherige Angebot für diesen Kunden. Dies kann einen Wert von null enthalten, da der Kunde eine Police hätte unterschreiben können, ohne ein vorheriges Angebot des Unternehmens zu haben, z. B. wenn er sich selbst an uns gewandt hätte. Dieses Attribut gehört unbedingt zumsigned_offerTabelle.policy_type_id— Verweis auf das Policentyp-Wörterbuch, das die Art der Police angibt, die wir dem Kunden angeboten oder von ihm unterzeichnen ließen.payment_amount— den Betrag, den der Kunde regelmäßig für die Police bezahlen muss.terms— alle Bedingungen der Vereinbarung im Textformat (XML). In diesem Attribut sollen alle wichtigen Details zum finanziellen Teil der Police hinterlegt werden. Beispiele für Text, den wir speichern könnten, sind der Gesamtbetrag der Police, die Anzahl der Zahlungen, die der Kunde leisten muss, und so weiter.details— alle zusätzlichen Details im Textformat.is_active— Flag, das angibt, ob der Datensatz noch aktiv ist.start_dateundend_date— Geben Sie den Zeitraum an, in dem diese Richtlinie aktiv ist/war. Wenn die Richtlinie auf Lebenszeit unterzeichnet wurde, enthält end_date den Wert null.
Es gibt auch den policy_type Wörterbuch, das wir zuvor kurz erwähnt haben. Wir brauchen ein gewisses Maß an Flexibilität, wie wir dasselbe Produkt verschiedenen Kunden anbieten, basierend auf Faktoren wie Alter, Gesundheit, Familienstand, Kreditrisiko und so weiter. Für jeden Richtlinientyp speichern wir einen type_name Identifikator, eine zusätzliche textuelle description , ein Flag mit dem Namen "expired", das angibt, ob die Police ablaufen kann, und ein weiteres Flag, das angibt, ob die Prämien dieses Policentyps monatlich, vierteljährlich oder jährlich gezahlt werden müssen. Einige erwartete Policentypen sind:Term Life, Whole Life, Universal Life, Guaranteed Universal Life, Variable Life, Variable Universal Life und Life Insurance After Retirement.
Weiter müssen wir nun alle Fälle und Situationen definieren, die eine bestimmte Police abdecken kann. Wir müssen diese Fälle bestimmten Angeboten und unterzeichneten Angeboten zuordnen.
Die Liste aller möglichen Fälle, die unsere Policen abdecken, ist im case Wörterbuch. Jeder Datensatz in dieser Tabelle kann durch seinen case_name eindeutig identifiziert werden und hat eine zusätzliche description , falls erforderlich.
Der in_offer und in_signed_offer Tabellen haben dieselbe Struktur, weil sie dieselben Daten speichern. Der einzige Unterschied zwischen den beiden besteht darin, dass die erste Fälle in der Police speichert, die dem Kunden lediglich angeboten wurde, während die zweite Fälle in der vom Kunden unterzeichneten Police speichert. Für jeden Datensatz in diesen beiden Tabellen speichern wir das eindeutige Paar offer_id /signed_offer_id und case_id , wobei letzteres den von der Police abgedeckten Fall oder Vorfall bezeichnet. Alle anderen Details werden bei Bedarf in einem Textattribut gespeichert.
Wie bereits erwähnt, beziehen sich Lebensversicherungspolicen fast immer nicht nur auf Kunden, sondern auch auf deren Familienmitglieder oder Verwandte. Diese Relationen müssen wir auch in diesem Bereich hinterlegen. Sie werden zum Zeitpunkt der Unterzeichnung einer Richtlinie definiert, können aber auch während der Laufzeit der Richtlinie geändert werden.
Als erstes müssen wir ein Wörterbuch erstellen, das alle möglichen Werte enthält, die einer Relation zugewiesen werden können. In unserem Modell ist dies der offer_relation_type Wörterbuch. Abgesehen vom Primärschlüssel enthält diese Tabelle nur ein Attribut – den relation_type – die nur eindeutige Werte enthalten kann.
Wir sind fast da! Die letzte Tabelle in diesem Themenbereich trägt den Titel offer_related . Es bezieht sich ein unterzeichnetes Angebot auf jeden, der mit dem Kunden verwandt ist. Daher müssen wir Verweise auf die signierte Richtlinie speichern (signed_offer_id ) und die zugehörige Person (person_id ) und geben Sie auch die Art dieser Beziehung an (offer_relation_type_id ). Außerdem müssen wir details speichern auf diesen Datensatz beziehen und ein Flag erstellen, um zu prüfen, ob er in unserem System noch gültig ist.
Themenbereich Nr. 5:Zahlungen
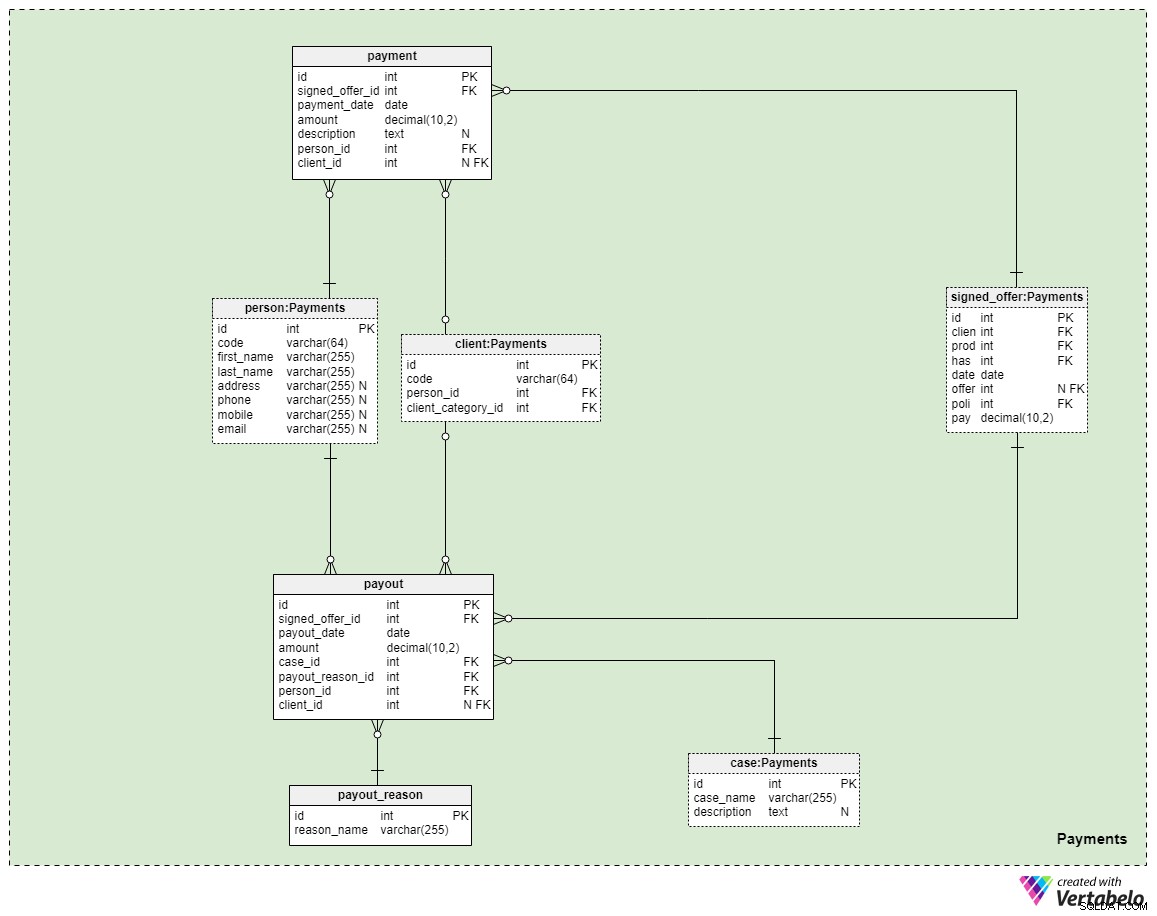
Der letzte Themenbereich in unserem Modell betrifft Zahlungen. Hier führen wir nur drei neue Tabellen ein:payment , payout_reason , und payout .
Alle Zahlungen im Zusammenhang mit Policen werden in payment Tisch. Wir haben hier nur die wichtigsten Attribute aufgenommen:
signed_offer_id— Verweis auf die eindeutige Kennung des unterzeichneten Angebots (Richtlinie).payment_date— das Datum, an dem diese Zahlung geleistet wurde.amount— der tatsächlich gezahlte Betrag.description— eine optionale Beschreibung der Zahlung im Textformat.person_id— Verweis auf die eindeutige Kennung der Person, die die Zahlung vorgenommen hat. Beachten Sie, dass der Kunde, der das Angebot unterschrieben hat, nicht unbedingt die einzige Person ist, die eine Zahlung vornehmen kann.client_id— Verweis auf die eindeutige Kennung des Kunden, der die Zahlung getätigt hat. Dieses Attribut enthält nur dann einen Wert, wenn der Kunde selbst die Zahlung geleistet hat.
Die verbleibenden zwei Tabellen stellen vielleicht den wichtigsten Grund dar, warum wir für Lebensversicherungen zahlen – dass, falls uns etwas passieren sollte, Auszahlungen an unsere Familienmitglieder oder Lebens-/Geschäftspartner erfolgen. Wie dies geschieht, hängt alles von Ihrer Situation und den Bedingungen der von Ihnen unterzeichneten spezifischen Police ab. Wir verwenden zwei einfache Tabellen, um diese Fälle abzudecken.
Das erste ist ein Wörterbuch mit dem Titel payout_reason und verfügt über eine klassische Wörterbuchstruktur. Abgesehen vom Primärschlüsselattribut haben wir nur ein Attribut – den reason_name – die eine Liste eindeutiger Werte speichert, die angeben, warum diese Auszahlung vorgenommen wurde.
Die letzte Tabelle im Modell ist die payout Tisch. Es ist der payment Tabelle, aber die wichtigsten Unterschiede sind unten aufgeführt:
payout_date— das Datum, an dem die Auszahlung erfolgt ist.case_id— Verweis auf die eindeutige Kennung des betreffenden Falls oder Vorfalls, der die Zahlung ausgelöst hat. Diese sollte mit einer der in der Richtlinie enthaltenen IDs übereinstimmen.payout_reason_id— Verweis auf das Lexikon, das den Auszahlungsgrund näher beschreibt. Während der Auszahlungsfall kürzer und allgemeiner ist, bietet der Auszahlungsgrund genauere Details dazu, was passiert ist.person_idundclient_id— Verweist auf die Person bzw. den Kunden im Zusammenhang mit der Auszahlung.
Zusammenfassung
Fantastisch! Wir haben unser Datenmodell für Lebensversicherungen erfolgreich aufgebaut. Bevor wir unsere Diskussion abschließen, ist es erwähnenswert, dass in diesem Modell noch viel mehr abgedeckt werden kann. In diesem Artikel wollten wir hauptsächlich die Grundlagen des Modells behandeln, um Ihnen eine Vorstellung davon zu geben, wie es aussieht und funktioniert. Hier sind einige weitere Details, die man in ein solches Datenmodell einbauen könnte:
- Zusätzliche Policen-Upgrades sind in unserem aktuellen Modell nicht abgedeckt (z. B. wenn Sie jährliche Angebote für bestehende Policen machen möchten, können Sie dies mit dieser Struktur nicht tun). Wir sollten ein paar weitere Tabellen hinzufügen, um alle Richtlinienänderungen für präsentierte/signierte Angebote zu speichern.
- Auf jeglichen Papierkram wird bewusst verzichtet. Natürlich ist mit einer bestimmten Lebensversicherung eine Menge Papierkram verbunden, insbesondere für den Unterzeichnungsprozess und die Auszahlungen. Wir könnten Dokumente anhängen, die den Kundenstatus zum Zeitpunkt der Unterzeichnung der Police und alle Änderungen auf dem Weg dorthin beschreiben, sowie alle Dokumente im Zusammenhang mit Auszahlungen.
- Dieses Modell enthält nicht die Struktur, die für die Berechnung des politischen Risikos erforderlich ist. Wir sollten alle Parameter haben, die wir testen müssen, und alle Bereiche, die bestimmen, wie sich der Wert eines Kunden auf die Gesamtberechnung auswirkt. Die Ergebnisse dieser Berechnungen müssten für jedes Angebot und jede unterzeichnete Police gespeichert werden.
- Die Rechnungsstruktur ist in Wirklichkeit viel komplexer als das, was wir im Themenbereich Zahlungen behandelt haben. Wir haben in unserem Modell nicht einmal Finanzkonten erwähnt.
Natürlich ist das Versicherungsgeschäft recht komplex. Wir haben in diesem Artikel nur ein Datenmodell für Lebensversicherungen besprochen – können Sie sich vorstellen, wie sich dieses Datenmodell entwickeln würde, wenn wir ein Unternehmen führen würden, das eine Reihe verschiedener Versicherungsarten anbietet? Es würde sicherlich viel Planung und Überlegung erfordern, ein organisiertes Datenmodell für ein solches Unternehmen zu präsentieren.
Wenn Sie Vorschläge oder Ideen zur Verbesserung unseres Datenmodells haben, teilen Sie uns dies bitte in den Kommentaren unten mit!