
Viel zu oft sehe ich Leute, die sich darüber beschweren, wie ihr Transaktionsprotokoll ihre Festplatte übernommen hat. Oft stellt sich heraus, dass sie in einer großen Transaktion einen großen Löschvorgang wie das Löschen oder Archivieren von Daten durchgeführt haben.
Ich wollte einige Tests durchführen, um die Auswirkungen sowohl auf die Dauer als auch auf das Transaktionsprotokoll zu zeigen, wenn dieselbe Datenoperation in Blöcken im Vergleich zu einer einzelnen Transaktion ausgeführt wird. Ich habe eine Datenbank erstellt und sie mit einer sehr großen Tabelle gefüllt SalesOrderDetailEnlarged ,
Nachdem ich die Tabelle gefüllt hatte, habe ich die Datenbank gesichert, das Protokoll gesichert und eine DBCC SHRINKFILE ausgeführt (erschießen Sie mich nicht), damit die Auswirkungen auf die Protokolldatei von einer Basislinie aus ermittelt werden können (wobei wir uns sehr wohl bewusst sind, dass diese Operationen dazu führen, dass das Transaktionsprotokoll *wächst*).
Ich habe absichtlich eine mechanische Festplatte im Gegensatz zu einer SSD verwendet. Während wir vielleicht einen populäreren Trend zur Umstellung auf SSD sehen, ist dies noch nicht in ausreichend großem Umfang geschehen; in vielen Fällen ist es immer noch zu kostenintensiv, dies in großen Speichergeräten zu tun.
Die Tests
Also musste ich als nächstes bestimmen, was ich testen wollte, um die größte Wirkung zu erzielen. Da ich erst gestern in eine Diskussion mit einem Kollegen über das Löschen von Daten in Blöcken verwickelt war, habe ich mich für Löschungen entschieden. Und da der gruppierte Index für diese Tabelle auf SalesOrderID liegt , wollte ich nicht verwenden – das wäre zu einfach (und würde sehr selten der Art und Weise entsprechen, wie Löschungen im wirklichen Leben gehandhabt werden). Also entschied ich mich stattdessen für eine Reihe von ProductID Werte, was sicherstellen würde, dass ich eine große Anzahl von Seiten treffen würde und viel Protokollierung erfordern würde. Ich habe durch die folgende Abfrage bestimmt, welche Produkte gelöscht werden sollen:
SELECT TOP (3) ProductID, ProductCount = COUNT(*) FROM dbo.SalesOrderDetailEnlarged GROUP BY ProductID ORDER BY ProductCount DESC;
Dies führte zu folgenden Ergebnissen:
ProductID ProductCount --------- ------------ 870 187520 712 135280 873 134160
Dadurch würden 456.960 Zeilen (ca. 10 % der Tabelle) gelöscht, verteilt auf viele Bestellungen. Dies ist in diesem Zusammenhang keine realistische Änderung, da die vorberechneten Bestellsummen durcheinander geraten und Sie ein Produkt nicht wirklich aus einer bereits versandten Bestellung entfernen können. Aber die Verwendung einer Datenbank, die wir alle kennen und lieben, entspricht beispielsweise dem Löschen eines Benutzers von einer Forumsseite und auch dem Löschen aller seiner Nachrichten – ein reales Szenario, das ich in freier Wildbahn gesehen habe.
Ein Test wäre also, das folgende One-Shot-Löschen durchzuführen:
DELETE dbo.SalesOrderDetailEnlarged WHERE ProductID IN (712, 870, 873);
Ich weiß, dass dies einen massiven Scan erfordern und das Transaktionsprotokoll stark belasten wird. Das ist sozusagen der Punkt. :-)
Während das lief, habe ich ein anderes Skript zusammengestellt, das diese Löschung in Blöcken durchführt:25.000, 50.000, 75.000 und 100.000 Zeilen gleichzeitig. Jeder Chunk wird in einer eigenen Transaktion festgeschrieben (so dass Sie, wenn Sie das Skript stoppen müssen, dies tun können und alle vorherigen Chunks bereits festgeschrieben werden, anstatt von vorne beginnen zu müssen), und je nach Wiederherstellungsmodell wird gefolgt entweder durch einen CHECKPOINT oder ein BACKUP LOG um die laufenden Auswirkungen auf das Transaktionsprotokoll zu minimieren. (Ich werde auch ohne diese Operationen testen.) Es wird ungefähr so aussehen (ich werde mich bei diesem Test nicht mit Fehlerbehandlung und anderen Feinheiten beschäftigen, aber Sie sollten nicht so unbekümmert sein):
SET NOCOUNT ON;
DECLARE @r INT;
SET @r = 1;
WHILE @r > 0
BEGIN
BEGIN TRANSACTION;
DELETE TOP (100000) -- this will change
dbo.SalesOrderDetailEnlarged
WHERE ProductID IN (712, 870, 873);
SET @r = @@ROWCOUNT;
COMMIT TRANSACTION;
-- CHECKPOINT; -- if simple
-- BACKUP LOG ... -- if full
END
Natürlich würde ich nach jedem Test die Originalsicherung der Datenbank WITH REPLACE, RECOVERY wiederherstellen , stellen Sie das Wiederherstellungsmodell entsprechend ein und führen Sie den nächsten Test aus.
Die Ergebnisse
Das Ergebnis des ersten Tests war überhaupt nicht sehr überraschend. Um das Löschen in einer einzigen Anweisung durchzuführen, dauerte es 42 Sekunden vollständig und 43 Sekunden einfach. In beiden Fällen vergrößerte sich das Protokoll auf 579 MB.
Die nächste Testreihe hatte einige Überraschungen für mich. Einer ist, dass diese Chunking-Methoden zwar die Auswirkungen auf die Protokolldatei erheblich reduzierten, aber nur wenige Kombinationen in der Dauer nahe kamen und keine wirklich schneller war. Ein weiterer Grund ist, dass Chunking bei der vollständigen Wiederherstellung (ohne Durchführung einer Protokollsicherung zwischen den Schritten) im Allgemeinen besser abschneidet als entsprechende Vorgänge bei der einfachen Wiederherstellung. Hier sind die Ergebnisse für Dauer und Protokollauswirkung:
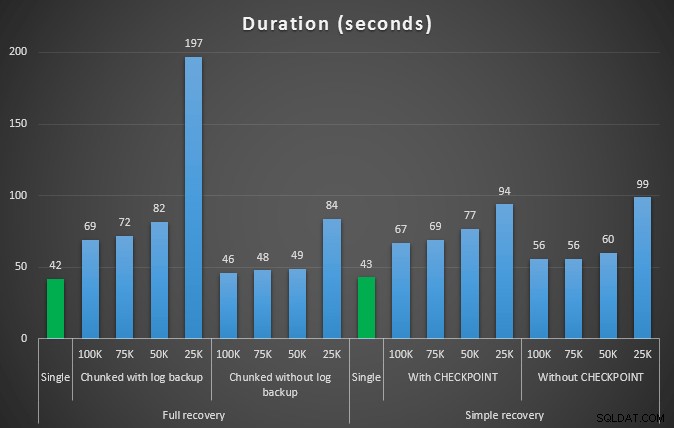
Dauer in Sekunden verschiedener Löschvorgänge, die 457.000 Zeilen entfernen
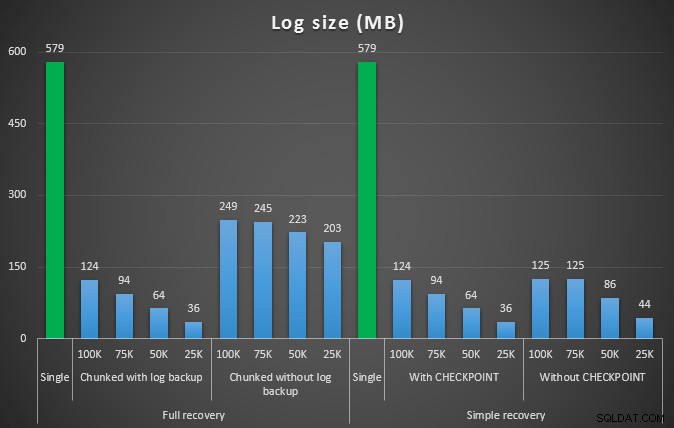
Protokollgröße in MB nach verschiedenen Löschvorgängen, bei denen 457.000 Zeilen entfernt wurden
Auch hier gilt im Allgemeinen, dass die Protokollgröße zwar erheblich reduziert wird, die Dauer jedoch verlängert wird. Sie können diese Art von Skalierung verwenden, um zu bestimmen, ob es wichtiger ist, die Auswirkungen auf den Speicherplatz zu reduzieren oder den Zeitaufwand zu minimieren. Für eine geringe Dauer (und schließlich werden die meisten dieser Prozesse im Hintergrund ausgeführt) können Sie erhebliche Einsparungen (bis zu 94 % in diesen Tests) bei der Nutzung des Protokollspeicherplatzes erzielen.
Beachten Sie, dass ich keinen dieser Tests mit aktivierter Komprimierung ausprobiert habe (möglicherweise ein zukünftiger Test!) und die Einstellungen für die automatische Vergrößerung des Protokolls auf den schrecklichen Standardwerten (10 %) belassen habe – teilweise aus Faulheit und teilweise, weil viele Umgebungen da draußen sie beibehalten haben diese schreckliche Einstellung.
Aber was, wenn ich mehr Daten habe?
Als nächstes dachte ich, ich sollte dies auf einer etwas größeren Datenbank testen. Also habe ich eine andere Datenbank erstellt und eine neue, größere Kopie von dbo.SalesOrderDetailEnlarged erstellt . In der Tat etwa zehnmal größer. Diesmal anstelle eines Primärschlüssels auf SalesOrderID, SalesorderDetailID , habe ich es einfach zu einem gruppierten Index gemacht (um Duplikate zuzulassen) und es so gefüllt:
SELECT c.*
INTO dbo.SalesOrderDetailReallyReallyEnlarged
FROM AdventureWorks2012.Sales.SalesOrderDetailEnlarged AS c
CROSS JOIN
(
SELECT TOP 10 Number FROM master..spt_values
) AS x;
CREATE CLUSTERED INDEX so ON dbo.SalesOrderDetailReallyReallyEnlarged
(SalesOrderID,SalesOrderDetailID);
-- I also made this index non-unique:
CREATE NONCLUSTERED INDEX rg ON dbo.SalesOrderDetailReallyReallyEnlarged(rowguid);
CREATE NONCLUSTERED INDEX p ON dbo.SalesOrderDetailReallyReallyEnlarged(ProductID); Aufgrund von Speicherplatzbeschränkungen musste ich für diesen Test die VM meines Laptops verlassen (und wählte eine 40-Core-Box mit 128 GB RAM, die zufällig quasi im Leerlauf herumsaß :-)), und immer noch es war keineswegs ein schneller Prozess. Das Füllen der Tabelle und das Erstellen der Indizes dauerte ca. 24 Minuten.
Die Tabelle hat 48,5 Millionen Zeilen und belegt 7,9 GB auf der Festplatte (4,9 GB Daten und 2,9 GB Index).
Diesmal meine Abfrage, um einen guten Kandidatensatz ProductID zu ermitteln zu löschende Werte:
SELECT TOP (3) ProductID, ProductCount = COUNT(*) FROM dbo.SalesOrderDetailReallyReallyEnlarged GROUP BY ProductID ORDER BY ProductCount DESC;
Ergab die folgenden Ergebnisse:
ProductID ProductCount --------- ------------ 870 1828320 712 1318980 873 1308060
Wir werden also 4.455.360 Zeilen löschen, etwas weniger als 10 % der Tabelle. Nach einem ähnlichen Muster wie im obigen Test werden wir alle auf einmal löschen, dann in Blöcken von 500.000, 250.000 und 100.000 Zeilen.
Ergebnisse:
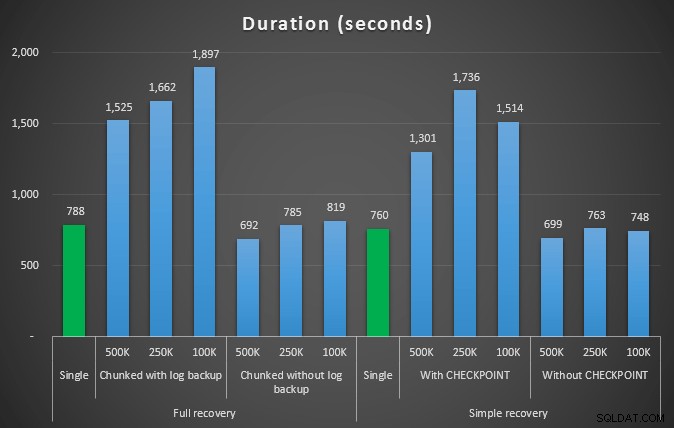 Dauer in Sekunden verschiedener Löschvorgänge, die 4,5 Millionen Zeilen entfernen
Dauer in Sekunden verschiedener Löschvorgänge, die 4,5 Millionen Zeilen entfernen
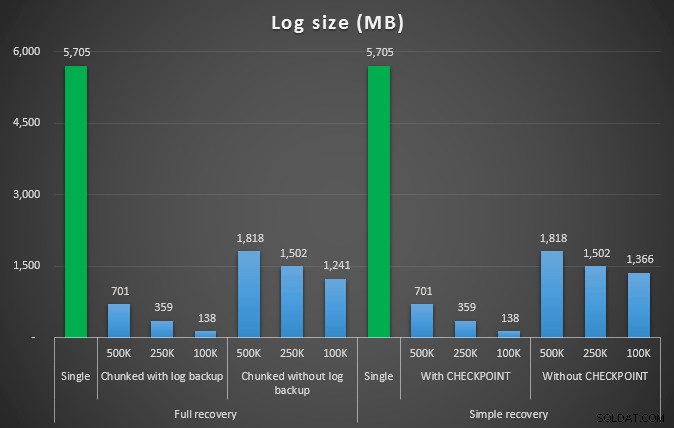 Protokollgröße in MB, nachdem durch verschiedene Löschvorgänge 4,5 Millionen Zeilen entfernt wurden
Protokollgröße in MB, nachdem durch verschiedene Löschvorgänge 4,5 Millionen Zeilen entfernt wurden
Auch hier sehen wir eine deutliche Reduzierung der Protokolldateigröße (über 97 % in Fällen mit der kleinsten Chunk-Größe von 100 KB); In dieser Größenordnung sehen wir jedoch einige Fälle, in denen wir das Löschen auch in kürzerer Zeit durchführen, selbst mit all den Autogrow-Ereignissen, die aufgetreten sein müssen. Das klingt für mich sehr nach Win-Win!
Dieses Mal mit einem größeren Protokoll
Nun war ich neugierig, wie sich diese verschiedenen Löschvorgänge im Vergleich zu einer Protokolldatei verhalten würden, die für solch große Operationen voreingestellt ist. Um bei unserer größeren Datenbank zu bleiben, habe ich die Protokolldatei vorab auf 6 GB erweitert, sie gesichert und dann die Tests erneut ausgeführt:
ALTER DATABASE delete_test MODIFY FILE (NAME=delete_test_log, SIZE=6000MB);
Ergebnisse, Vergleich der Dauer mit einer festen Protokolldatei mit dem Fall, in dem die Datei kontinuierlich automatisch wachsen musste:
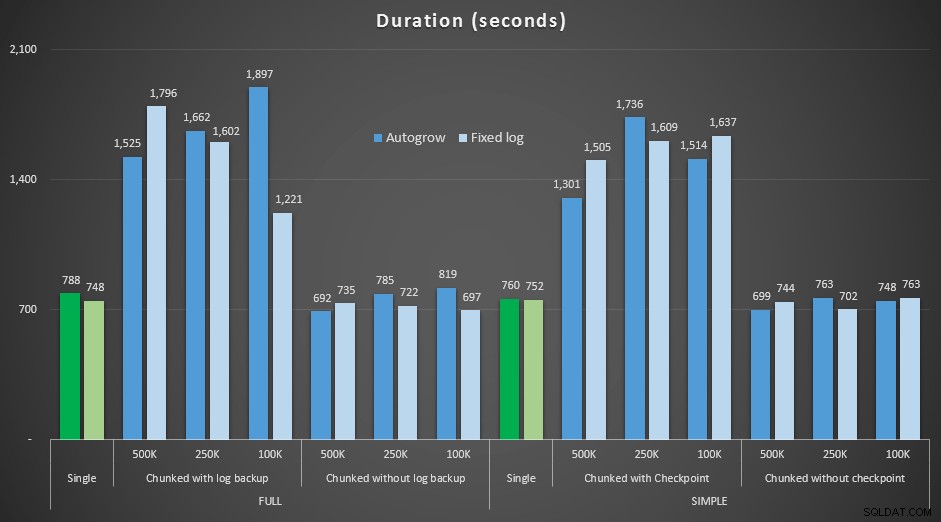
Dauer in Sekunden verschiedener Löschvorgänge, die 4,5 Millionen Zeilen entfernen , Vergleich von fester Protokollgröße und automatischer Vergrößerung
Wieder sehen wir, dass die Methoden, die Löschungen in Stapel aufteilen und nach jedem Schritt *keine* Protokollsicherung oder einen Prüfpunkt durchführen, in Bezug auf die Dauer mit der entsprechenden einzelnen Operation konkurrieren. Sehen Sie tatsächlich, dass die meisten tatsächlich in weniger Gesamtzeit ausgeführt werden, mit dem zusätzlichen Vorteil, dass andere Transaktionen zwischen den Schritten ein- und aussteigen können. Was eine gute Sache ist, es sei denn, Sie möchten, dass dieser Löschvorgang alle nicht verwandten Transaktionen blockiert.
Schlussfolgerung
Es ist klar, dass es keine einzelne, richtige Antwort auf dieses Problem gibt – es gibt viele inhärente „es kommt darauf an“-Variablen. Es kann einige Experimente erfordern, um Ihre magische Zahl zu finden, da es ein Gleichgewicht zwischen dem Overhead gibt, der zum Sichern des Protokolls erforderlich ist, und wie viel Arbeit und Zeit Sie bei verschiedenen Chunk-Größen sparen. Wenn Sie jedoch vorhaben, eine große Anzahl von Zeilen zu löschen oder zu archivieren, ist es sehr wahrscheinlich, dass Sie insgesamt besser dran sind, wenn Sie die Änderungen in Blöcken durchführen, anstatt in einer massiven Transaktion – auch wenn die Zahlen für die Dauer zu sprechen scheinen dass eine weniger attraktive Operation. Es geht nicht nur um die Dauer – wenn Sie keine ausreichend vorab zugewiesene Protokolldatei haben und nicht den Speicherplatz für eine so massive Transaktion haben, ist es wahrscheinlich viel besser, das Wachstum der Protokolldatei auf Kosten der Dauer zu minimieren. In diesem Fall sollten Sie die Diagramme zur Dauer oben ignorieren und auf die Diagramme zur Protokollgröße achten.
Wenn Sie sich den Speicherplatz leisten können, möchten Sie Ihr Transaktionsprotokoll möglicherweise trotzdem entsprechend vorab dimensionieren. Je nach Szenario war die Verwendung der standardmäßigen Autogrow-Einstellungen in meinen Tests manchmal etwas schneller als die Verwendung einer festen Protokolldatei mit viel Platz. Außerdem kann es schwierig sein, genau abzuschätzen, wie viel Sie für eine große Transaktion benötigen, die Sie noch nicht ausgeführt haben. Wenn Sie kein realistisches Szenario testen können, versuchen Sie Ihr Bestes, sich Ihr Worst-Case-Szenario vorzustellen – und verdoppeln Sie es dann zur Sicherheit. Kimberly Tripp (Blog | @KimberlyLTripp) hat einige großartige Ratschläge in diesem Beitrag:8 Steps to better Transaction Log throughput – schauen Sie sich in diesem Zusammenhang insbesondere Punkt 6 an. Unabhängig davon, wie Sie sich entscheiden, Ihren Log-Speicherplatzbedarf zu berechnen, wenn Sie den Speicherplatz trotzdem benötigen, sollten Sie ihn besser rechtzeitig rechtzeitig nutzen, als Ihre Geschäftsprozesse anzuhalten, während sie auf ein automatisches Wachstum warten ( egal mehrere!).
Ein weiterer sehr wichtiger Aspekt, den ich nicht explizit gemessen habe, ist die Auswirkung auf die Parallelität – eine Reihe kürzerer Transaktionen hat theoretisch weniger Einfluss auf gleichzeitige Vorgänge. Während ein einzelner Löschvorgang etwas weniger Zeit in Anspruch nahm als die längeren Batch-Vorgänge, hielt er alle seine Sperren für die gesamte Dauer, während die Chunk-Vorgänge es anderen in der Warteschlange befindlichen Transaktionen ermöglichen würden, sich zwischen jede Transaktion einzuschleichen. In einem zukünftigen Beitrag werde ich versuchen, diese Auswirkungen genauer zu untersuchen (und ich habe auch Pläne für andere tiefere Analysen).



