Auf der ganzen Welt ist die Website des Jobportals ein bekannter Bestandteil der Internetlandschaft. Big Player wie Indeed und Monster haben die Stellensuche und das Recruiting zu einer wahren Online-Branche gemacht. Lassen Sie uns in die elementaren Funktionen eintauchen, die von Jobportalen genutzt werden, und ein Datenmodell erstellen, das sie unterstützen kann.
Menschen lieben es, Zeit zu sparen, indem sie technologische Innovationen nutzen; Das Online-Jobportal ist eine andere Version von intelligenter arbeiten, nicht härter. Arbeitssuchende und Unternehmen erkennen gleichermaßen den Wert einer Online-Suche:Sie erhalten eine bessere Reichweite bei höheren Geschwindigkeiten und geringeren Kosten.
Die Branche der Jobportale ist zumindest in Bezug auf das Traffic-Volumen mittlerweile recht stabil. Jobsuchende nutzen diese Portale, um Stellen in vielen Branchen zu finden, und bewegen sich über die IT hinaus in Sektoren wie Engineering, Vertrieb, Fertigung und Finanzdienstleistungen. Sie bekommen jedoch harte Konkurrenz durch soziale Medien und professionelle Networking-Sites wie LinkedIn. Aber es gibt noch Möglichkeiten zu erkunden, wie z. B. die Ausweitung ihrer Durchdringung auf ländliche Gebiete und kleinere Städte.
Wie gesagt, wir werden dieses Thema aus der Perspektive des Datenbankdesigns untersuchen. Beginnen wir damit, die grundsätzlichen Erwartungen an ein Jobportal aufzuzählen.
Was erwarten Menschen von einem Online-Jobportal?
Sowohl Arbeitgeber als auch Arbeitssuchende erwarten die folgenden Funktionen von einer Online-Stellenbörse:
- Personen können sich als Arbeitssuchende registrieren, ihre Profile erstellen und nach Jobs suchen, die ihren Fähigkeiten entsprechen.
- Benutzer können ihre bestehenden Lebensläufe hochladen. Wenn sie keinen haben, sollten sie in der Lage sein, ein Formular auszufüllen und einen Lebenslauf erstellen zu lassen.
- Personen können sich direkt auf ausgeschriebene Stellen bewerben.
- Unternehmen können sich registrieren, Jobs veröffentlichen und Profile von Jobsuchenden durchsuchen.
- Mehrere Vertreter eines Unternehmens sollten Jobs registrieren und veröffentlichen können.
- Unternehmensvertreter können eine Liste von Stellenbewerbern anzeigen und sie kontaktieren, ein Vorstellungsgespräch initiieren oder andere Aktionen im Zusammenhang mit ihrer Stelle durchführen.
- Registrierte Benutzer sollten in der Lage sein, nach Jobs zu suchen und die Ergebnisse nach Standort, erforderlichen Fähigkeiten, Gehalt, Erfahrungsniveau usw. zu filtern.
Aufbau des Datenmodells
Nachdem ich die oben genannten Anforderungen berücksichtigt habe, habe ich mir drei große Funktionskategorien ausgedacht:
- Benutzer verwalten – Wie das Portal Benutzer verwaltet, d. h. Arbeitssuchende, HR-Mitarbeiter und unabhängige oder beratende Personalvermittler. (Für die Zwecke dieses Modells werden einzelne Personalvertreter und unabhängige oder beratende Personalvermittler als Unternehmen behandelt, zumindest in Bezug auf die Art und Weise, wie sie das Portal nutzen.)
- Profile erstellen – Wie das Portal es Arbeitssuchenden und Organisationen ermöglicht, Profile und Lebensläufe zu erstellen.
- Posten und Nachschlagen von Jobs – Wie das Portal das Posten, Suchen und Bewerben von Stellen erleichtert.
Sehen wir uns jeden dieser Bereiche separat an.
1. Benutzer verwalten
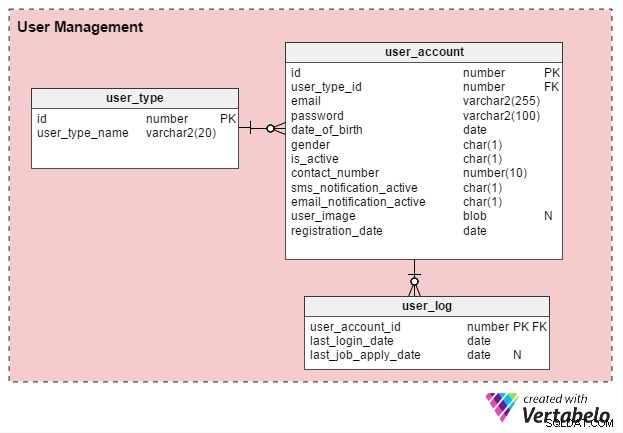
Es gibt hauptsächlich zwei Arten von Benutzern von Online-Jobportalen:einzelne Arbeitssuchende und Personalvermittler (oder unabhängige Personalberater). Lassen Sie uns eine Tabelle mit dem Namen user_type um diese Aufzeichnungen zu speichern. Zu Beginn wird es zwei Datensätze geben – einen für Arbeitssuchende und einen für Personalvermittler. (Bei Bedarf können wir jederzeit zusätzliche Datensatztypen erstellen.)
Benutzer müssen sich registrieren, bevor sie das Portal nutzen können. Das user_account Tabelle speichert ihre grundlegenden Kontodetails. Ich habe früher überlegt, diese Tabelle „user“ zu nennen, aber da user in fast allen Datenbanken ein systemdefiniertes Schlüsselwort ist, bleibe ich lieber bei „user_account“.
Das user_account Tabelle hat die folgenden Spalten:
- id – Dies ist sowohl der Primärschlüssel der Tabelle als auch eine eindeutige Kennung für jeden Benutzer. Auf diese ID wird von anderen Tabellen im Datenmodell verwiesen.
- user_type_id – Dies gibt an, ob der Benutzer ein Arbeitssuchender oder ein Personalvermittler ist.
- E-Mail – Diese Spalte enthält die E-Mail-Adresse des Benutzers. Sie fungiert als weitere Benutzerkennung für das Portal.
- Passwort – Dies speichert ein verschlüsseltes Kontopasswort (das von Benutzern während der Registrierung erstellt wird).
- Geburtsdatum und Geschlecht – Wie der Name schon sagt, enthalten diese Spalten das Geburtsdatum und das Geschlecht der Benutzer.
- ist_aktiv – Anfänglich wäre diese Spalte „Y“, aber Benutzer können ihr Profil auf „Inaktiv“ oder „N“ setzen. Diese Spalte speichert ihre Wahl.
- Kontaktnummer – Dies ist die Telefonnummer (normalerweise mobil), die bei der Registrierung angegeben wurde. Benutzer können unter dieser Nummer SMS-Benachrichtigungen erhalten. Es kann dieselbe Nummer sein (oder auch nicht), die der Jobsuchende in seinem Profil oder Lebenslauf aufführt.
- sms_notification_active und email_notification_active – Diese Spalten speichern die Präferenzen der Benutzer in Bezug auf den Erhalt von Benachrichtigungen per Text und/oder E-Mail.
- Benutzerbild – Dies ist ein Attribut vom Typ BLOB, das das Profilbild jedes Benutzers speichert. Da dieses Portal nur ein Profilbild pro Nutzer erlaubt, ist es sinnvoll dieses hier zu hinterlegen.
- Registrierungsdatum – In dieser Spalte wird festgehalten, wann sich der Benutzer beim Portal registriert hat.
Wir erstellen eine weitere Tabelle, user_log , das eine Aufzeichnung des letzten Anmeldedatums der Benutzer und ihres letzten Bewerbungsdatums speichert. Es gibt viele Funktionen, die aus diesem Wissen aufgebaut werden können. Beispielsweise können wir diese Informationen verwenden, um die Frage Sucht Benutzer X aktiv nach einem Job zu beantworten ? Wenn ja, kann ihnen ein Produkt zur Erstellung eines effektiven Lebenslaufs angeboten werden. Nutzer, die nicht aktiv nach einem Job suchen, würden ein solches Angebot nicht erhalten.
2. Erstellen von Profilen
Wir können diesen Abschnitt weiter in zwei Bereiche unterteilen:Unternehmens- oder Organisationsprofile und Profile von Arbeitssuchenden.
Unternehmensprofile
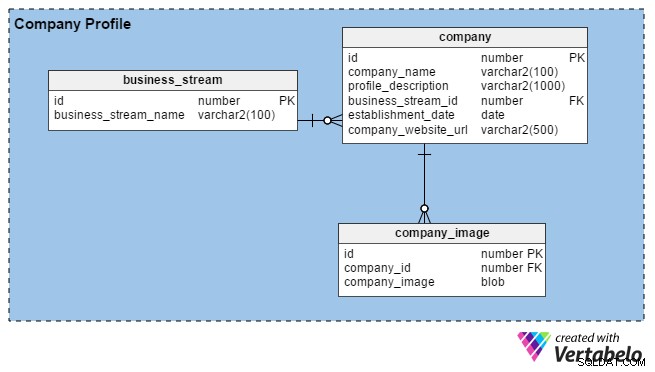
Normalerweise erstellen HR-Teams Unternehmensprofile, indem sie Details über ihre Organisation und Bilder ihrer Büros, Gebäude usw. eingeben. Ihr Hauptziel ist es, gute Talente anzuziehen. Wenn sich Personalvermittler beim Portal registrieren, können auch sie Profile ihres Unternehmens (oder ihrer persönlichen Marke, wenn sie unabhängig sind) erstellen, indem sie einige grundlegende Details angeben, wie z. B. wie lange sie im Geschäft sind, ihren Standort und ihren Hauptgeschäftszweig ( B. Fertigung, IT-Dienstleistungen, Finanzen usw.).
Das Portal ermöglicht HR- und Consulting-Recruitern, so viele Bilder hochzuladen, wie sie möchten (im Gegensatz zu Arbeitssuchenden, die nur eines hochladen können). Daher haben wir das company_image Tabelle zum Speichern mehrerer Bilder für jedes Recruiter-Konto. Die company_id Spalte in dieser Tabelle ist ein Fremdschlüssel, der sich auf die eindeutige Kennung bezieht, die in company Tabelle.
Im company Tabelle haben wir die folgenden Spalten:
- id – Der Primärschlüssel dieser Tabelle dient auch zur eindeutigen Identifizierung von Firmen.
- Unternehmensname – Wie der Spaltenname vermuten lässt, enthält dies den rechtlichen Namen eines Unternehmens.
- Profilbeschreibung – Enthält eine kurze Beschreibung der einzelnen Unternehmen.
- business_stream_id – Diese Spalte zeigt, zu welchem Geschäftsbereich ein Unternehmen gehört. Beispielsweise kann ein Öl- und Gasexplorationsunternehmen IT-Ingenieure einstellen, aber sein Hauptgeschäftszweig bleibt „Öl und Gas“.
- Einrichtungsdatum – In dieser Spalte erfahren Sie, wie alt ein Unternehmen ist.
- Unternehmenswebsite-URL – Dies ist eine obligatorische (nicht nullfähige) Spalte. Es enthält einen Verweis auf die offizielle Website des Unternehmens, damit Arbeitssuchende weitere Informationen finden können.
Schließlich der business_stream Die Tabelle hat nur zwei Attribute, eine ID, die der Primärschlüssel für diese Tabelle ist, und eine Beschreibung des Hauptgeschäftszweigs des Unternehmens (business_stream_name ).
Profile von Arbeitssuchenden
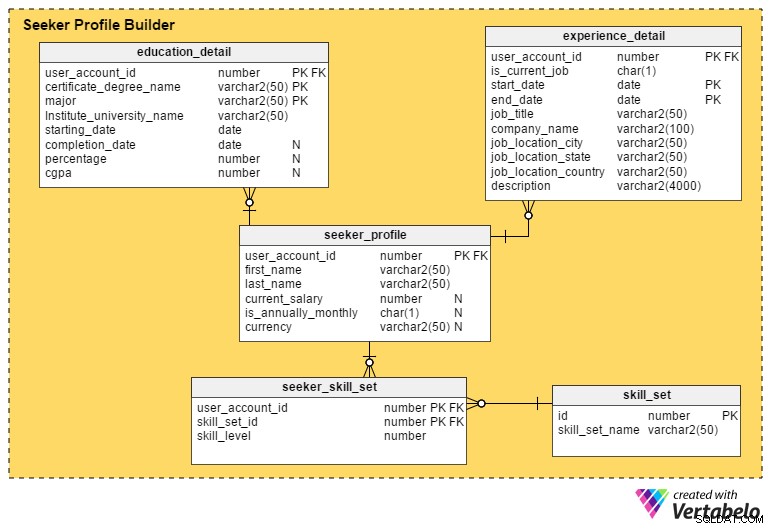
Dies ist der kritischste Bereich eines Jobportals. Wenn ein Portal nicht so viele Details wie möglich von Arbeitssuchenden erfasst, ist es für Personalvermittler schwierig, die Profile oder Kandidaten in die engere Wahl zu ziehen.
Das seeker_profile Die Tabelle enthält zusätzliche Details, die während des Registrierungsprozesses nicht erfasst wurden. Es enthält diese Felder:
- user_account_id – Auf diese Spalte wird vom
user_accountTabelle und fungiert als Primärschlüssel für diese Tabelle. Es stellt sicher, dass es maximal ein Profil pro Stellensuchendem gibt. - Vorname und Nachname – Wie die Namen vermuten lassen, enthalten diese Spalten den Vor- und Nachnamen des Arbeitssuchenden.
- aktuelles_Gehalt – Dieses Attribut enthält das aktuelle Gehalt des Stellensuchenden. Es ist nullable, weil die Leute es vielleicht nicht offenlegen wollen.
- ist_jährlich_monatlich – Dies definiert, ob ihr Gehalt pro Jahr oder pro Monat beträgt.
- Währung – Hier wird die Währung des Gehalts gespeichert.
Das education_detail Die Tabelle speichert den Bildungsverlauf jedes Arbeitssuchenden, wie von ihm angegeben. Es hat einen zusammengesetzten Primärschlüssel, der aus der user_account_id besteht , certificate_graduate_name und Hauptfach Säulen. Dadurch wird sichergestellt, dass Benutzer nur einen eingeben Aufzeichnung für jeden Abschluss oder jedes Zertifikat. Die Tabelle enthält diese Attribute:
- user_account_id – Auf diese Spalte wird vom
user_accountTabelle und dient als Primärschlüssel für diese Tabelle. - certificate_graduate_name – Dies ist die Art des Zertifikats oder Abschlusses; z.B. Abitur, Sekundarstufe II, Absolvent, Postgraduierter oder Berufsabschluss.
- Hauptfach – In dieser Spalte steht der Hauptstudiengang des Zeugnisses bzw. Abschlusses – z.B. einen Bachelor-Abschluss mit Schwerpunkt Informatik.
- institut_universitätsname – Dies ist das Institut, die Schule oder die Universität, die den Abschluss oder das Zertifikat verliehen hat.
- Startdatum – Dieses Attribut speichert das Datum, an dem der Benutzer in ein Bildungsprogramm aufgenommen wurde.
- Fertigstellungsdatum – Dies ist das Datum, an dem der Abschluss oder das Zertifikat verliehen wurde. Dieses Attribut ist jedoch nullable; Menschen können ihr Programm noch absolvieren, während sie nach einem Job suchen, oder sie haben das Programm möglicherweise ganz abgebrochen.
- Prozentsatz und cgpa – Diese Spalten speichern den Notenprozentsatz oder CGPA (kumulativer Notendurchschnitt), den Benutzer in ihrem Studiengang oder Zertifikatskurs erreicht haben.
Das experience_detail table hält Aufzeichnungen über die bisherige und aktuelle Berufserfahrung der Benutzer. Es enthält die folgenden wichtigen Spalten:
- user_account_id – Auf diese Spalte wird vom
user_accountTabelle und ist der Primärschlüssel für diese Tabelle. - ist_aktueller_Job – Dies ist eine Indikatorspalte, die den aktuellen Job des Benutzers anzeigt. Diese Spalte spielt auch eine wichtige Rolle, um die aktuellen Standorte der Benutzer abzuleiten und wie lange sie ihre aktuelle Position halten.
- Startdatum – Dies speichert, wenn ein Benutzer einen Job startet.
- Enddatum – Dies speichert, wenn ein Benutzer einen Job beendet.
- job_title – Enthält Informationen über die Jobrolle des Benutzers.
- Unternehmensname – Dieses Attribut enthält den relevanten Firmennamen, der mit einem Job verknüpft ist.
- job_location_city – Dies bezeichnet die Stadt, in der sich der Arbeitsplatz befand.
- job_location_state – Gibt das Bundesland an, in dem sich der Job befand.
- job_location_country – Dies bezeichnet das Land, in dem sich der Arbeitsplatz befand.
- Beschreibung – In dieser Spalte werden Details zu Jobrollen und Verantwortlichkeiten, Herausforderungen und Erfolgen gespeichert.
Arbeitssuchende können mehrere Fähigkeiten besitzen. Um Aufzeichnungen über all diese Fähigkeiten zu führen, erstellen wir die Tabelle seeker_skill_set . Die Spalten sind:
- user_account_id – Auf diese Spalte wird vom
user_accountTabelle und ist der Primärschlüssel für diese Tabelle. - skill_set_id – Diese ID gibt an, welche Fähigkeiten der Benutzer besitzt.
- skill_level – Dieses numerische Attribut quantifiziert das Fachwissen von Arbeitssuchenden in einer bestimmten Fähigkeit. Eine Zahl von 1 (Anfänger) bis 10 (Experte) gibt ihr Erfahrungsniveau an.
Schließlich das skill_set Die Tabelle enthält Beschreibungen aller Fertigkeiten, auf die in der skill_set_id der obigen Tabelle verwiesen wird Attribut. Es enthält nur zwei Spalten, einen skill_set_name und die zugehörige id .
3. Posten und Nachschlagen von Jobs
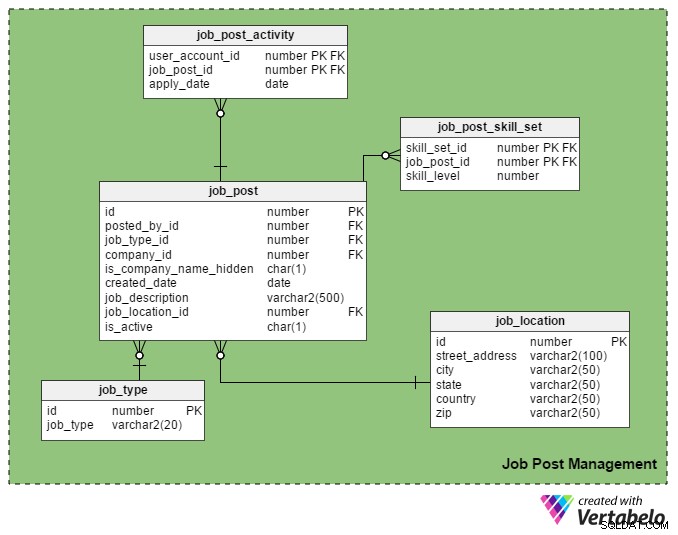
Dies ist der wichtigste USP (Unique Selling Point) eines Jobportals. Nur registrierte Personalvermittler dürfen eine Stelle auf dem Portal veröffentlichen und nur registrierte Stellensuchende dürfen sich darauf bewerben.
Der job_post table ist die Haupttabelle in diesem Themenbereich. Wie Sie sich vorstellen können, enthält es Details zu Stellenausschreibungen. Alle anderen Tabellen in diesem Abschnitt werden um ihn herum erstellt und mit ihm verknüpft.
- id – Dies ist der Primärschlüssel dieser Tabelle. Jeder Stellenausschreibung wird eine eindeutige Nummer zugewiesen, auf die in anderen Tabellen verwiesen wird.
- posted_by_id – Diese Spalte enthält die register_user_id des Personalvermittlers, der die Stelle ausgeschrieben hat.
- job_type_id – Diese Spalte kennzeichnet, ob es sich um eine unbefristete oder befristete Stelle (Vertrag) handelt.
- Unternehmens-ID – In dieser Spalte wird die ID des Unternehmens gespeichert, das sich auf die Stellenausschreibung bezieht. Es ist ein Verweis auf das
companyTabelle. - is_company_name_hidden – Dies ist eine Flag-Spalte, die anzeigt, ob der Name des Unternehmens Arbeitssuchenden angezeigt werden soll. Personalvermittler ziehen es möglicherweise vor, keine Firmennamen auf ihrem Post zu zeigen. Stattdessen verwenden sie Begriffe wie „Global Automobile Company“, „California-based IT Company“ usw.
- Erstellungsdatum – Hier wird das Datum der Stellenausschreibung gespeichert.
- job_description – Hier finden Sie eine kurze Stellenbeschreibung.
- job_location_id – Dies bezieht sich auf ein Attribut im
job_locationTabelle, die den tatsächlichen Standort des Jobs speichert:Straße, Stadt, Bundesland, Land und Postleitzahl. - ist_aktiv – Dies zeigt an, ob ein Job noch offen ist. Recruiter können ihre Stellen als inaktiv markieren, sobald die Stellen besetzt sind.
Das job_post_skill_set In der Tabelle werden Details zu den für einen Job erforderlichen Fähigkeiten gespeichert. Die Tabellenstruktur ist identisch mit dem seeker_skill_set Tisch.
Und die letzte Tabelle in diesem Abschnitt, die job_post_activity Tabelle enthält Details darüber, welche Arbeitssuchenden sich wann auf eine Stelle bewerben.
Was würden Sie diesem Online-Jobportal-Datenmodell hinzufügen?
Die heutigen Online-Jobportale bieten mehr als nur eine Plattform, um Jobs zu veröffentlichen und sich zu bewerben. Sie beinhalten oft andere professionelle Dienstleistungen wie:
- Ein persönliches Dashboard, um Bewerbungen im Auge zu behalten
- Echtzeit-Updates für Anwendungen
- Video-Lebenslauf-Ersteller
- Expertenservice zum Verfassen von Lebensläufen
- LinkedIn oder andere Profilersteller für soziale Medien
- Gehaltsberichte über Jobrollen, Unternehmen, Branchen oder geografische Standorte hinweg
Wenn wir diese Funktionen in unser System einbauen wollten, welche zusätzlichen Änderungen müssten wir vornehmen? Fallen Ihnen noch weitere Must-Haves in einem Jobportal ein?
Bitte teilen Sie uns Ihre Meinung im Kommentarbereich mit.