In Zeiten des harten Wettbewerbs sind Jobportale nicht nur Plattformen zum Veröffentlichen und Finden von Jobs. Sie nutzen fortschrittliche Dienste und Funktionen, um ihre Kunden bei der Stange zu halten. Lassen Sie uns in einige erweiterte Funktionen eintauchen und ein Datenmodell erstellen, das sie verarbeiten kann.
Ich habe die grundlegenden Funktionen, die für eine Jobportal-Website erforderlich sind, in einem früheren Artikel erläutert. Das Modell ist unten abgebildet. Wir betrachten dieses Modell als Basis, die wir an die neuen Anforderungen anpassen werden. Lassen Sie uns zunächst überlegen, was diese Anforderungen (oder Verbesserungen) sein sollten.
Was fügen wir dem Datenmodell des Online-Jobportals hinzu?
Kurz gesagt, wir werden unserem früheren Datenmodell vier Verbesserungen hinzufügen:
- Ein persönliches Dashboard für Arbeitssuchende. Dadurch werden alle ihre Bewerbungen nachverfolgt und Echtzeit-Updates zu Statusänderungen bereitgestellt (z
- Ein Profil-Dashboard. Diese zeigt an, wer das Profil eines Arbeitssuchenden besucht und wie oft sein Lebenslauf am letzten Tag, in der letzten Woche oder im letzten Monat heruntergeladen wurde.
- Bezahldienstverwaltung. Jobportale bieten häufig Dienstleistungen wie die Erstellung von Lebensläufen durch Experten, die Verwaltung sozialer Profile, Karriereberatung usw. an. Unsere neuen Funktionen können kostenpflichtige Angebote unterstützen.
- Vorantragsformularverwaltung. Wenn Bewerber eine Bewerbung einreichen, werden sie möglicherweise gebeten, einen kurzen Fragebogen zu Arbeitszeiten, Standorten und Zuverlässigkeitsüberprüfungen auszufüllen. Wir werden Möglichkeiten einbauen, damit dieses Formular von Personalvermittlern angepasst werden kann und Fragen und Antworten vom System erfasst werden können.
Verbesserung Nr. 1:Persönliches Dashboard
Zu beantwortende Fragen: Wie ist der aktuelle Status einer eingereichten Bewerbung? Kommt es für ein Vorstellungsgespräch in die engere Wahl? Wurde es überhaupt schon angesehen?
Wir können Bewerbungen nachverfolgen, indem wir die job_application_status_id eingeben Spalte in der job_post_activity Tisch. Diese Spalte enthält den aktuellen Status einer Bewerbung. Wir müssen eine weitere Tabelle erstellen, job_application_status , um alle möglichen Anwendungsstatus aufzunehmen. Einige Status können „eingereicht“, „wird geprüft“, „archiviert“, „abgelehnt“, „für Vorstellungsgespräch in die engere Wahl gezogen“, „im Rekrutierungsprozess“ usw. sein.
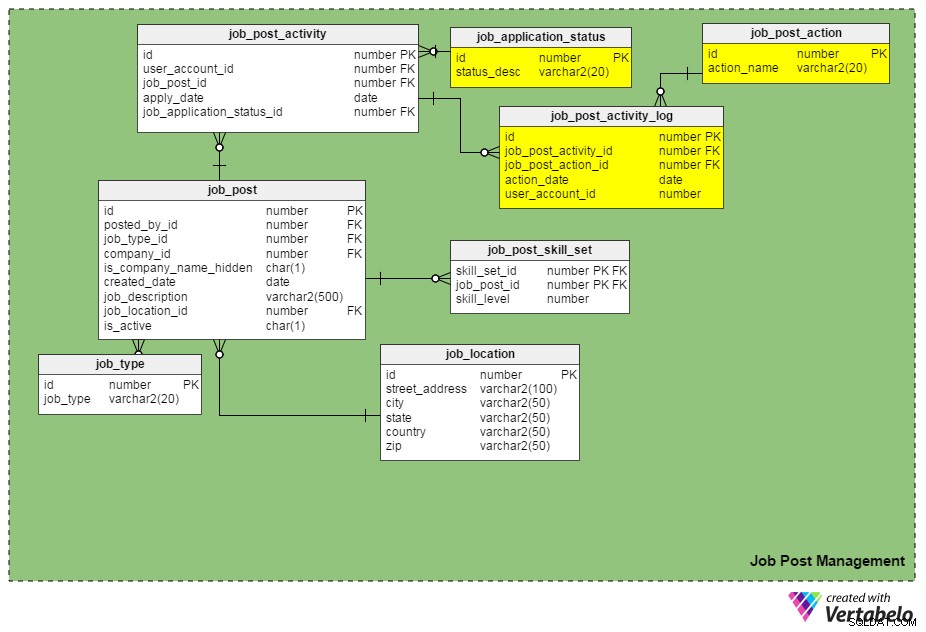
Eine weitere neue Tabelle, job_post_activity_log , speichert Informationen zu allen Aktionen, die bei Stellenbewerbungen durchgeführt wurden, wer die Aktion durchgeführt hat und wann sie durchgeführt wurde. Diese Tabelle enthält die folgenden Spalten:
id– Der Primärschlüssel der Tabelle.job_post_activity_id– Die Anwendungs-ID, auf der die Aktion ausgeführt wird.job_post_action_id– Die ID der durchgeführten Aktion. Dies ist ein Fremdschlüssel, der mitjob_post_actionTisch. Zu den Arten von Aktionen, die wir hier möglicherweise speichern, gehören „eingereicht“, „angesehen“, „interviewt“, „schriftlicher Test absolviert“, „Angebot in Bearbeitung“, „Angebot versendet“, „Angebot angenommen“ usw.action_date– Das Datum, an dem eine Aktion durchgeführt wurde.user_account_id– Die ID der Person, die die Aktion ausgeführt hat.
Ist „job_post_action“ identisch mit „job_application_status“? Wie unterscheiden sie sich?
Sie scheinen auf den ersten Blick identisch zu sein, aber sie sind tatsächlich verschieden. Es gibt triftige Gründe, warum wir zwei ähnliche Felder benötigen:
- Ein Kandidat wird von zwei oder mehr Personen getrennt interviewt. In diesem Fall bleibt der Bewerbungsstatus derselbe (d. h. „im Einstellungsverfahren“), bis alle Interviewrunden abgeschlossen sind. Aufzeichnungen für jeden einzelnen Interviewer werden jedoch in das
job_post_activity_logTabelle, und sie haben die Aktion „interviewed“. - Eine Bewerbung kann von mehr als einem Personalvermittler im selben Unternehmen eingesehen werden. Durch die Verwendung dieser beiden Attribute verlieren Sie keine Bewerberinformationen.
- Das Unterbreiten eines Angebots an einen ausgewählten Kandidaten unterliegt mehreren Genehmigungen (d. h. Genehmigung durch das Finanzteam, Genehmigung durch den Leiter der Einstellungsabteilung usw.). In diesem Fall bleibt der Status einer Stellenbewerbung „Angebot in Prüfung“, aber die Datenbank kann mit dem
job_post_activity_logTabelle.
Verbesserung Nr. 2:Ein Profil-Dashboard
Zu beantwortende Fragen: Wer hat mein Profil kürzlich gefunden? Wie oft wurde es im letzten Monat, in der letzten Woche oder am letzten Tag von Personalvermittlern angesehen? Haben sich Personalvermittler von Top-Unternehmen mein Profil angesehen?
Die Antworten auf all diese Fragen finden Sie im profile_visit_log Tisch. Diese Tabelle erfasst alle Profilbesuchsdaten, einschließlich wer ein Profil besucht hat, wann es angesehen wurde und so weiter. Die Spalten in dieser Tabelle sind:
id– Der Primärschlüssel der Tabelle.seeker_profile_id– Welches Profil besucht wurde.visit_date– Wann auf das Profil zugegriffen wurde.user_account_id– Wer hat das Profil gesehen?is_resume_downloaded– Eine Markierungsspalte, die angibt, ob der zugehörige Lebenslauf während des Besuchs heruntergeladen wurde. Diese Spalte hilft uns abzuleiten, wie oft ein Lebenslauf von Personalvermittlern heruntergeladen wird.is_job_notification_sent– Eine weitere Flag-Spalte, die angibt, ob eine Stellenbenachrichtigung an den Inhaber des Profils gesendet wurde.
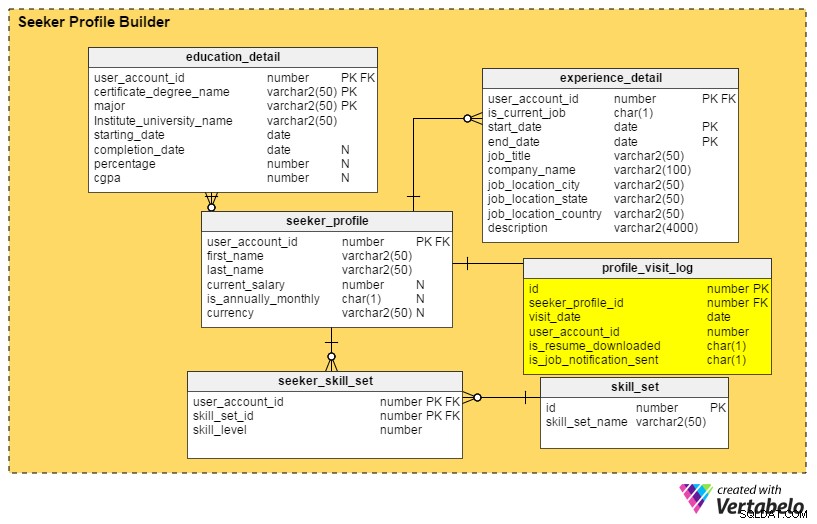
Verbesserung Nr. 3:Bezahldienstverwaltung
Frage zur Antwort: Wie können Online-Portale zusätzliche kostenpflichtige Dienste nutzen?
Neben einer Plattform für die Veröffentlichung und Suche von Jobs bieten viele Online-Portale andere Dienstleistungen an, wie z. B. die Erstellung von Lebensläufen durch Experten, Karriereberatung usw. Sie bieten auch Produkte an, die Arbeitssuchenden helfen, ihren Traumjob in ihrer Traumstadt zu finden. Eine der führenden Jobbörsen bietet beispielsweise ein Produkt an, das Ihr Profil ganz oben auf den Listen der Personalvermittler hält, damit Sie mehr Vorstellungsgespräche erhalten. Die meisten dieser Produkte oder Dienstleistungen sind auf Abonnementbasis erhältlich. Wenn ein Nutzer einen Dienst oder ein Produkt kauft, zahlt er über einen bestimmten Zeitraum (d. h. einen Monat, drei Monate, ein Jahr) für die Nutzung dieses Produkts oder Dienstes.
Beim Betrachten dieser Jobportale ist mir aufgefallen, dass kaum Produkte oder Dienstleistungen einzeln angeboten werden. Meistens werden mehrere Produkte und Dienstleistungen zu einem Paket gebündelt, und dieses Paket wird entweder Arbeitssuchenden oder Personalvermittlern angeboten.
Unter Berücksichtigung all dieser Punkte habe ich das folgende Datenmodell für die Einbindung kostenpflichtiger Dienste und Produkte in unsere bestehende Online-Jobbörse entwickelt:
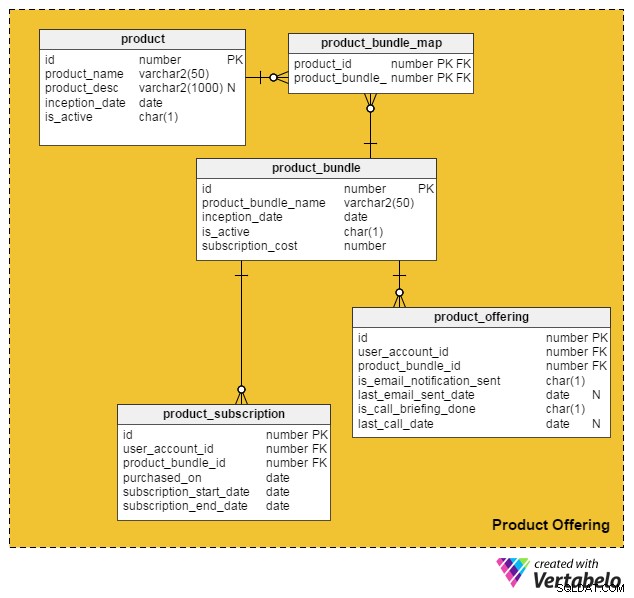
Das product Tabelle enthält Details zu einzelnen Produkten. (Wir bezeichnen sowohl Produkte als auch Dienstleistungen als „Produkte“). Die Spalten in dieser Tabelle sind:
id– Der Primärschlüssel dieser Tabelle, der jedem auf unserem Portal angebotenen Produkt eine eindeutige ID gibt.product_name– Enthält den Produktnamen.product_desc– Speichert eine kurze Beschreibung des Produkts.inception_date– Das Datum, an dem ein Produkt eingeführt wurde.is_active– Ob ein Produkt aktiv ist oder nicht.
Da Produkte und Dienstleistungen in einem Bündel zusammengefasst und Kunden angeboten werden können, habe ich das product_bundle Tabelle zum Speichern von Datensätzen aller solcher Bündel. Die Attribute sind:
id– Der Primärschlüssel der Tabelle, der eine eindeutige ID für jedes Produktpaket bereitstellt.product_bundle_name– Speichert den Namen des Bundles.inception_date– Das Datum, an dem das Bündel eingeführt wurde.is_active– Gibt an, ob ein Paket aktiv ist oder nicht.subscription_cost– Speichert den für das Bundle geforderten Preis.
Kann den Kunden ein einzelnes Produkt angeboten werden?
Ja. In diesem Datenmodell kann ein einzelnes Produkt ein eigenes „Bündel“ sein. Die folgenden Tabellen behandeln diese und einige andere wichtige Funktionalitäten.
Die product_bundle_map Tabelle speichert eine Liste aller Produkte, die Teil eines Bundles sind. Seine Attribute sind selbsterklärend.
Die nächste Tabelle, product_subscription , kommt ins Spiel, wenn Kunden Produktpakete abonnieren. Es zeichnet auf, welche Kunden welche Bundles abonniert haben. Die Spalten in dieser Tabelle sind:
id– Der Primärschlüssel der Tabelle.user_account_id– Der Benutzer, der das Paket gekauft hat.product_bundle_id– Das vom Benutzer gekaufte Produktpaket.purchased_on– Das Kaufdatum.subscription_start_date– Das Datum, an dem das Abonnement beginnt. Beachten Sie, dass das Kaufdatum des Produkts und das Startdatum des Abonnements unterschiedlich sein können. Daher haben wir zwei verschiedene Spalten für diese.subscription_end_date– Wann endet das Abonnement.
Die Abschlusstabelle, product_offering , wird hauptsächlich für Marketingzwecke verwendet. Normalerweise analysieren Jobportale die jüngsten Aktivitäten der Benutzer (sowohl von Arbeitssuchenden als auch von Personalvermittlern) und entscheiden dann, welche Produkte für welche Benutzer von Vorteil sind. Anschließend nutzen sie E-Mails oder Telefonanrufe, um Kunden mit ausgewählten Angeboten zu kontaktieren. Die Spalten für diese Tabelle sind:
id– Der Primärschlüssel der Tabelle.user_account_id– Der Nutzer, den das Jobportal anspricht.product_bundle_id– Das Produkt-Bundle, das die Portal-Vermarkter auf den Nutzer abgestimmt haben.is_email_notification_sent– Ob eine E-Mail bezüglich des Produktangebots gesendet wurde.last_email_sent_date– Wann der Benutzer zuletzt eine Produkt-E-Mail vom Marketingteam erhalten hat. Es ist üblich, dass Vermarkter mehrere Benachrichtigungen an einen Benutzer senden und regelmäßig andere Benachrichtigungen senden. In dieser Spalte wird das Datum gespeichert, an dem die letzte Benachrichtigung gesendet wurde.is_call_briefing_done– Ob der Kunde einen Anruf erhalten hat, in dem er über ein Produkt informiert wurde.last_call_date–Das Datum des letzten Telefonats. Es können mehrere Anrufe (Folgeanrufe) bei Kunden erfolgen.
Verbesserung Nr. 4:Verwaltung von Vorantragsformularen
Frage zur Antwort: Wie kann ein Personalvermittler ein individuelles Einwilligungsformular erhalten, das von allen potenziellen Stellenbewerbern ausgefüllt wird?
Oft müssen Arbeitssuchende spezifische Fragen beantworten, wenn sie sich um eine Stelle bewerben. Dazu gehören häufig Dinge wie die Zustimmung zu einer Überprüfung des kriminellen Hintergrunds. Es gibt jedoch verschiedene andere Arten von Einwilligungen, die erforderlich sein können. Beispielsweise kann ein Job im Marketing viele Reisen erfordern; Jobs im Bereich Business Process Outsourcing (BPO) erfordern möglicherweise, dass Mitarbeiter in Friedhofsschichten (d. h. Spätschichten) arbeiten. Diese werden in Vorantragsformularen behandelt.
Es ist immer am besten, die Zustimmung einzuholen, wenn die Bewerbung eingereicht wird. Auf diese Weise werden sich Kandidaten, die diese Anforderungen nicht erfüllen wollen, nicht um die Stelle bewerben.
Lassen Sie mich, bevor ich zum Datenmodell springe, zunächst einige grundlegende Fakten zu Einwilligungsformularen hervorheben:
- Eine Stellenausschreibung kann mehr als eine Einverständniserklärung haben.
- Jedes Einwilligungsformular enthält verschiedene Fragen, die mit verschiedenen Abschnitten verknüpft sind.
- Eine Frage kann als obligatorisch oder optional festgelegt werden, je nachdem, wie die Frage im Formular gekennzeichnet ist. Eine Frage kann in einer Form optional und in einer anderen obligatorisch sein.
- Jede Frage kann entweder mit (1) ja, (2) nein oder (3) nicht zutreffend beantwortet werden.
- Alle Antworten werden aufgezeichnet.
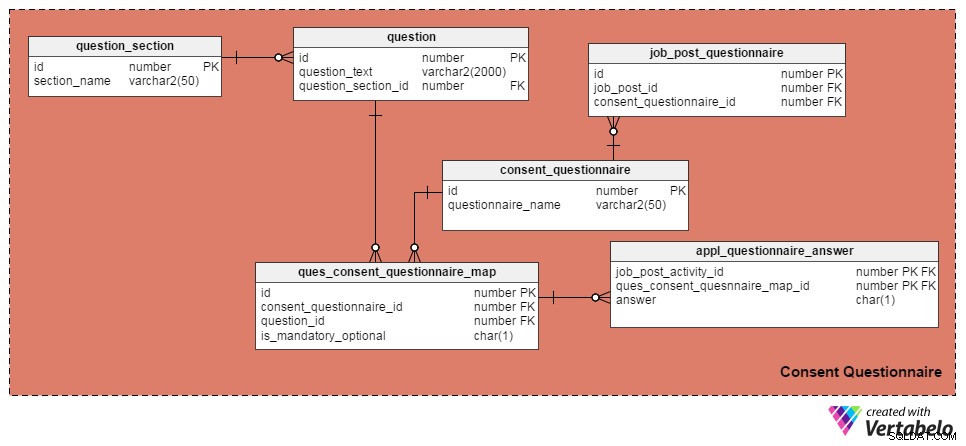
Ich habe die folgenden vier Tabellen verwendet, um Fragen und Einverständniserklärungen zu verwalten. Die erste, die question Tabelle, enthält eine Liste von Fragen. Es hat diese Attribute:
id– Der Primärschlüssel der Tabelle, der jeder Frage eine eindeutige ID-Nummer gibt.question_text– Speichert den eigentlichen Fragetext.question_section_id– Der Abschnitt, in dem die Frage erscheint. (Z. B. „Haben Sie mindestens fünf Jahre in der Softwareentwicklung gearbeitet?“ würde im Abschnitt „Berufserfahrung“ erscheinen.) Dies ist eine Fremdschlüsselspalte, auf die aus demquestion_sectionTabelle.
Der question_section Tabelle speichert Abschnittsinformationen. Es ist eine Möglichkeit, Fragen zum gleichen Thema zu gruppieren. Abgesehen von der id -Attribut, das der Primärschlüssel für die Tabelle ist, ist das einzige Attribut section_name , was selbsterklärend ist.
Der consent_questionnaire Tabelle enthält Namen von Einverständniserklärungen. Auch seine beiden Attribute sind selbsterklärend.
Die ques_consent_questionnaire_map Tabelle ist der Kern dieses Themenbereichs. Alle anderen Tabellen in diesem Themenbereich sind direkt oder indirekt damit verbunden. Sein Zweck ist es, eine Liste von Fragen zu führen, die mit Einwilligungsformularen verknüpft sind. Die Spalten in dieser Tabelle sind:
id– Der Primärschlüssel dieser Tabelle.consent_questionnaire_id– Die ID-Nummer der Einwilligungserklärung.question_id– Die ID-Nummer der Frage.is_mandatory_optional– Gibt an, ob die Frage für ein bestimmtes Einwilligungsformular obligatorisch oder optional ist. Eine Frage kann Teil mehrerer Einwilligungsformulare sein, aber sie kann in einigen obligatorisch und in anderen optional sein. Das ist der einzige Grund dafür, diese Spalte hier zu belassen, anstatt sie in derquestionTabelle.
In den nächsten Tabellen werden wir Einwilligungsformulare für einzelne Stellenausschreibungen besprechen und die Antworten der Kandidaten aufzeichnen. Beginnen wir mit dem job_post_questionnaire Tabelle, in der Informationen darüber gespeichert sind, welche Einwilligungsformulare Teil einer Stellenausschreibung sind. Es kann eine oder mehrere Einverständniserklärungen geben, die mit einer Stellenausschreibung gekennzeichnet sind. Die Spalten in dieser Tabelle sind:
id– Der Primärschlüssel der Tabelle.job_post_id– Gibt an, mit welcher Stellenausschreibung die Einverständniserklärung getaggt ist.consent_questionnaire_id– Die Einverständniserklärung, die mit einer Stellenanzeige verknüpft ist.
Als nächstes die appl_questionnaire_answer Tabelle protokolliert die einzelnen Antworten auf jede Frage des Einwilligungsformulars, wie sie von den Antragstellern ausgefüllt wurde. Die Spalten in dieser Tabelle sind:
job_post_activity_id– Eine Fremdschlüsselspalte, auf die vonjob_post_activityTisch. Es speichert Informationen über den Kandidaten, der die Frage beantwortet hat.quest_consent_quesnnaire_map_id– Eine weitere Fremdschlüsselspalte, auf die von derquest_consent_questionnaire_mapTisch. Es wird gespeichert, welche Frage aus welcher Einwilligungserklärung beantwortet wird.answer– Die eigentliche Antwort des Stellenbewerbers. Ich habe es als CHAR(1)-Spalte beibehalten, da alle Fragen in unserem Modell mit „Ja“ (Antwort =„Y“), „Nein“ (Antwort =„N“) oder „Nicht zutreffend“ (Antwort ='X').
Das neue und verbesserte Online-Jobportal-Datenmodell
Unten sehen Sie das fertige Datenmodell.
Was würden Sie hinzufügen?
Können Sie sich weitere Funktionen vorstellen, die Sie unserem Online-Jobportal hinzufügen könnten? Bitte teilen Sie Ihre Ansichten im Kommentarbereich mit.