Ein wiederkehrendes Ereignis ist per Definition ein Ereignis, das in einem Intervall wiederkehrt; es wird auch als periodisches Ereignis bezeichnet. Es gibt viele Anwendungen, die es ihren Benutzern ermöglichen, wiederkehrende Ereignisse einzurichten. Wie verwaltet ein Datenbanksystem wiederkehrende Ereignisse? In diesem Artikel untersuchen wir eine Möglichkeit, wie sie gehandhabt werden.
Wiederholungen sind für Anwendungen nicht einfach zu handhaben. Es kann zu einer Hurrikan-Aufgabe werden, insbesondere wenn es darum geht, jedes mögliche wiederkehrende Szenario abzudecken – einschließlich der Erstellung zweiwöchentlicher oder vierteljährlicher Ereignisse oder der Möglichkeit, alle zukünftigen Ereignisinstanzen neu zu planen.
Zwei Möglichkeiten zur Verwaltung wiederkehrender Ereignisse
Mir fallen mindestens zwei Möglichkeiten ein, periodische Aufgaben in einem Datenmodell zu handhaben. Bevor wir sie besprechen, lassen Sie uns kurz die Anforderungen dieser Aufgabe durchgehen. Auf den Punkt gebracht bedeutet effektives Management:
- Benutzer dürfen regelmäßige und wiederkehrende Ereignisse erstellen.
- Tägliche, wöchentliche, zweiwöchentliche, monatliche, vierteljährliche, zweijährliche und jährliche Ereignisse können ohne Enddatumseinschränkungen erstellt werden.
- Benutzer können eine Instanz einer Veranstaltung oder alle zukünftigen Instanzen einer Veranstaltung neu planen oder stornieren.
Unter Berücksichtigung dieser Parameter kommen zwei Möglichkeiten in Betracht, wiederkehrende Ereignisse im Datenmodell zu verwalten. Wir nennen sie den naiven Weg und den Expertenweg.
Der naive Weg: Speichern aller möglichen wiederkehrenden Instanzen eines Ereignisses als separate Zeilen in einer Tabelle. In dieser Lösung benötigen wir nur eine Tabelle, nämlich event . Diese Tabelle hat Spalten wie event_title , start_date , end_date , is_full_day_event usw. Das start_date und end_date Spalten sind Zeitstempel-Datentypen; Auf diese Weise können sie Veranstaltungen unterbringen, die nicht den ganzen Tag dauern.
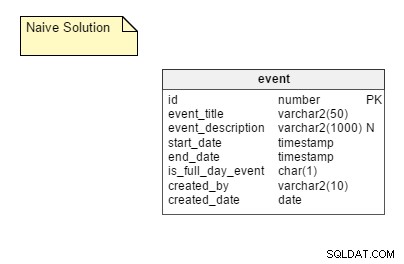
Die Vorteile: Dies ist ein recht unkomplizierter Ansatz und am einfachsten zu implementieren.
Die Nachteile: Der naive Weg hat einige erhebliche Nachteile, darunter:
- Die Notwendigkeit, alle möglichen Instanzen eines Ereignisses zu speichern. Wenn Sie die Bedürfnisse einer großen Benutzerbasis berücksichtigen, ist ein großer Teil des Speicherplatzes erforderlich. Allerdings ist Platz recht günstig, sodass dieser Punkt keine großen Auswirkungen hat.
- Ein sehr chaotischer Aktualisierungsprozess. Angenommen, eine Veranstaltung wird verschoben. In diesem Fall muss jemand alle Instanzen davon aktualisieren. Beim Umplanen muss eine große Anzahl von DML-Vorgängen durchgeführt werden, was sich negativ auf die Anwendungsleistung auswirkt.
- Behandlung von Ausnahmen. Alle Ausnahmen müssen ordnungsgemäß gehandhabt werden, insbesondere wenn Sie zurückgehen und den ursprünglichen Termin bearbeiten müssen, nachdem Sie eine Ausnahme gemacht haben. Angenommen, Sie verschieben die dritte Instanz eines wiederkehrenden Ereignisses um einen Tag nach vorne. Was ist, wenn Sie die Zeit des ursprünglichen Ereignisses nachträglich bearbeiten? Fügen Sie am ursprünglichen Tag ein anderes Ereignis ein und lassen das vorgezogene Ereignis? Verknüpfung der Ausnahme aufheben? Versuchen Sie, es entsprechend zu ändern?
Event_id– Auf diese Spalte wird vomeventTabelle und fungiert in dieser Tabelle als Primärschlüssel. Es zeigt die identifizierende Beziehung zwischeneventundrecurring_patternTische. Diese Spalte stellt auch sicher, dass für jedes Ereignis maximal ein wiederkehrendes Muster vorhanden ist.Recurring_type_id– Diese Spalte gibt die Art der Wiederholung an, ob täglich, wöchentlich, monatlich oder jährlich.Max_num_of_occurrances– Es gibt Zeiten, in denen wir das genaue Enddatum eines Ereignisses nicht kennen, aber wir wissen, wie viele Ereignisse (Meetings) erforderlich sind, um es abzuschließen. Diese Spalte speichert eine beliebige Zahl, die das logische Ende für ein Ereignis definiert.Separation_count– Sie fragen sich vielleicht, wie ein zweiwöchentlicher oder zweijährlicher Termin konfiguriert werden kann, wenn es nur vier mögliche Wiederholungstypen gibt (täglich, wöchentlich, monatlich, jährlich). Die Antwort ist derseparation_countSäule. Diese Spalte gibt das Intervall (in Tagen, Wochen oder Monaten) an, bevor die nächste Ereignisinstanz zulässig ist. Wenn beispielsweise ein Ereignis alle zwei Wochen konfiguriert werden muss, dann separation_count =„1“ um diese Anforderung zu erfüllen. Der Standardwert für diese Spalte ist „0“.- Die
recurring_type_idwäre „wöchentlich“. - Der
separation_countwäre „1“. - Der
day_of_weekwäre „2“. Week_of_month– Diese Spalte ist für Ereignisse, die für eine bestimmte Woche des Monats geplant sind – d. h. die erste, zweite, letzte, vorletzte usw. Wir können diese Werte als 1,2,3, 4, ... speichern (gezählt von Monatsanfang) oder -1,-2,-3,... (gezählt ab Monatsende).Day_of_month– Es gibt Fälle, in denen ein Ereignis an einem bestimmten Tag des Monats geplant ist, z. B. am 25. Diese Säule erfüllt diese Anforderung. Wieweek_of_month, kann es mit positiven Zahlen ( „7“ für den 7. Tag ab Monatsanfang) oder negativen Zahlen ( „-7“ für den 7. Tag ab Monatsende) gefüllt werden.- Die
recurring_type_idwäre „monatlich“. - Der
separation_countwäre „2“. - Der
day_of_monthwäre „11“. - Alle verbleibenden Spalten wären null.
- Ereignisse, die an Feiertagen stattfinden. Wenn ein bestimmtes Ereignis an einem Feiertag eintritt, sollte es automatisch auf den Werktag unmittelbar nach dem Feiertag verschoben werden? Oder soll es automatisch gekündigt werden? Unter welchen Umständen würde eines dieser beiden zutreffen?
- Konflikte zwischen Ereignissen. Was ist, wenn bestimmte Ereignisse (die sich gegenseitig ausschließen) auf denselben Tag fallen?
Der Expertenweg: Speichern eines wiederkehrenden Musters und programmgesteuertes Generieren vergangener und zukünftiger Ereignisinstanzen. Diese Lösung behebt die Nachteile der naiven Lösung. In diesem Artikel erklären wir Ihnen die Expertenlösung im Detail.
Das vorgeschlagene Modell
Ereignisse erstellen
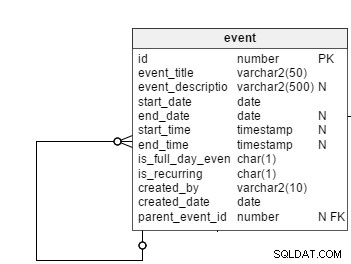
Alle geplanten Ereignisse, unabhängig davon, ob sie regelmäßig oder wiederkehrend sind, werden im event Tisch. Nicht alle Ereignisse sind wiederkehrende Ereignisse, daher benötigen wir eine Flag-Spalte, is_recurring , in dieser Tabelle, um wiederkehrende Ereignisse explizit anzugeben. Der event_title und event_description Spalten speichern das Thema und eine kurze Zusammenfassung der Ereignisse. Ereignisbeschreibungen sind optional, weshalb diese Spalte nullfähig ist.
Wie der Name schon sagt, das start_date und end_date Spalten enthalten die Start- und Enddaten von Ereignissen. Bei regelmäßigen Ereignissen speichern diese Spalten das tatsächliche Start- und Enddatum. Sie speichern jedoch auch die Daten des ersten und letzten Auftretens periodischer Ereignisse. Wir behalten das end_date bei als nullable, da Benutzer wiederkehrende Ereignisse ohne Enddatum konfigurieren können. In diesem Fall würden zukünftige Ereignisse bis zu einem hypothetischen Enddatum (z. B. für ein Jahr) in der Benutzeroberfläche angezeigt.
Das is_full_date_event Spalte gibt an, ob es sich bei einer Veranstaltung um eine ganztägige Veranstaltung handelt. Bei einer ganztägigen Veranstaltung die start_time und end_time Spalten wären null; das ist der Grund, diese beiden Spalten nullable zu lassen.
Der created_by und created_date Spalten speichern, welcher Benutzer ein Ereignis erstellt hat, und das Datum, an dem dieses Ereignis erstellt wurde.
Als nächstes kommt die parent_event_id Säule. Dies spielt in unserem Datenmodell eine große Rolle. Seine Bedeutung erkläre ich später.
Wiederholungen verwalten
Jetzt kommen wir direkt zur Hauptproblemstellung:Was ist, wenn ein wiederkehrendes Ereignis im event Tabelle – d.h. der is_recurring Flag für das Ereignis ist „Y“?
Wie bereits erläutert, speichern wir ein wiederkehrendes Muster für Ereignisse, damit wir alle zukünftigen Vorkommnisse konstruieren können. Beginnen wir mit der Erstellung des recurring_pattern Tisch. Diese Tabelle hat die folgenden Spalten:
Betrachten wir die Bedeutung der verbleibenden Spalten in Bezug auf die verschiedenen Arten von Wiederholungen.
Tägliche Wiederholung
Müssen wir wirklich ein Muster für ein täglich wiederkehrendes Ereignis erfassen? Nein, da alle Details, die zum Generieren eines täglichen Wiederholungsmusters erforderlich sind, bereits im event Tabelle.
Das einzige Szenario, das ein Muster erfordert, ist, wenn Ereignisse für jeden zweiten Tag oder alle X Tage geplant sind. In diesem Fall der separation_count Spalte wird uns helfen, das Wiederholungsmuster zu verstehen und weitere Instanzen abzuleiten.
Wöchentliche Wiederholung
Wir benötigen nur eine zusätzliche Spalte, day_of_week , um zu speichern, an welchem Wochentag dieses Ereignis stattfindet. Unter der Annahme, dass Montag der erste Tag der Woche und Sonntag der letzte ist, wären mögliche Werte 1,2,3,4,5,6 und 7. Entsprechende Änderungen am Code, der einzelne Ereignisvorkommen generiert, sollten nach Bedarf vorgenommen werden. Alle verbleibenden Spalten wären bei wöchentlichen Ereignissen null.
Nehmen wir eine klassische Art von wöchentlichem Ereignis:das zweiwöchentliche Auftreten. In diesem Fall sagen wir, dass es jede zweite Woche an einem Dienstag, dem zweiten Tag der Woche, passiert. Also:

Monatliche Wiederholung
Außer day_of_week , benötigen wir zwei weitere Spalten, um jedes Szenario mit monatlicher Wiederholung zu erfüllen. Kurz gesagt sind diese Spalten:
Betrachten wir nun ein komplizierteres Beispiel – ein vierteljährliches Ereignis. Angenommen, ein Unternehmen plant eine vierteljährliche Ergebnisprognose für den 11. Tag des ersten Monats in jedem Quartal (normalerweise Januar, April, Juli und Oktober). Also in diesem Fall:
Im obigen Beispiel gehen wir davon aus, dass der Benutzer die Quartalsergebnisprognose im Januar erstellt. Bitte beachten Sie, dass diese Trennungslogik ab dem Monat, der Woche oder dem Tag zu zählen beginnt, an dem das Ereignis erstellt wird.
Auf ähnliche Weise können halbjährliche Ereignisse als monatliche Ereignisse mit einem
Die jährliche Wiederholung ist recht einfach. Wir haben Spalten für bestimmte Wochentage und den Monat, sodass wir nur eine zusätzliche Spalte für den Monat des Jahres benötigen. Wir haben diese Spalte
Kommen wir nun zu den Ausnahmen. Was passiert, wenn eine bestimmte Instanz einer wiederkehrenden Veranstaltung abgesagt oder verschoben wird? Alle diese Instanzen werden separat in
Sehen wir uns zwei Spalten an,
Abgesehen von diesen beiden Spalten verhalten sich alle übrigen Spalten genauso wie im
Es gibt Anwendungen, die es Benutzern ermöglichen, alle zukünftigen Instanzen eines wiederkehrenden Ereignisses neu zu planen. In solchen Fällen haben wir zwei Möglichkeiten. Wir können alle zukünftigen Instanzen in
Mit dieser Lösung können wir alle vergangenen Vorkommnisse eines Ereignisses abrufen, selbst wenn sein Wiederholungsmuster geändert wurde.
Es gibt einige komplexere Bereiche rund um wiederkehrende Ereignisse, die wir nicht besprochen haben. Hier sind zwei:
Welche Änderungen müssen wir vornehmen, um diese Fähigkeiten einzubauen? Bitte teilen Sie uns Ihre Meinung im Kommentarbereich mit.separation_count protokolliert werden von „5“.
Jährliche Wiederholung
month_of_year genannt .
Behandlung von Ausnahmen bei wiederkehrenden Ereignissen
event_instance_exception Tisch. Is_rescheduled und is_cancelled . Diese Spalten geben an, ob diese Instanz auf ein späteres Datum/eine spätere Uhrzeit verschoben oder insgesamt storniert wird. Warum habe ich dafür zwei getrennte Spalten? Denken Sie nur an Veranstaltungen, die erst verschoben und dann später komplett abgesagt wurden. Dies geschieht, und wir haben eine Möglichkeit, es mit diesen Spalten aufzuzeichnen. event Tabelle.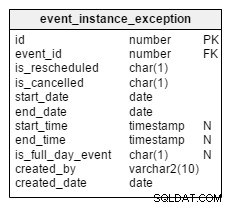
Warum zwei Events mit
parent_event_id verknüpfen? ?event_instance_exception speichern (Hinweis:keine akzeptable Lösung). Oder wir können ein neues Ereignis mit neuen Datums-/Uhrzeitparametern im event Tabelle und verknüpfen Sie es mit seinem früheren Ereignis (dem übergeordneten Ereignis) mittels id_parent_event Säule. Wie kann die Behandlung wiederkehrender Ereignisse verbessert werden?