Im Allgemeinen erhalten Menschen nicht gerne unerwünschte E-Mails. Trotzdem abonnieren sie manchmal Newsletter, um einen Rabatt zu erhalten oder um über neue Produkte auf dem Laufenden zu bleiben. Dieser Artikel stellt einen Ansatz zum Entwerfen einer Newsletter-Datenbank vor.
Warum sich Gedanken über Newsletter-E-Mails machen?
Newsletter-Abonnenten stellen eine äußerst wertvolle Kundengruppe dar – sie interessieren sich für unsere Produkte, sie vertrauen uns und verbringen Zeit damit, unsere Angebote und Aktionen zu prüfen. Darüber hinaus ist das Versenden von E-Mails an Kunden eines der billigsten Tools im Online-Marketing. Es muss jedoch sorgfältig vorgegangen werden – die Daten müssen täglich aktualisiert werden (da die Leute sich an- und abmelden) und von hoher Qualität sein (wir möchten keine unerwünschten E-Mails versenden, da dies das Markenimage negativ beeinflusst).
Daher stellt sich die Frage, wie dieser Prozess der Gewinnung qualitativ hochwertiger Daten und deren täglicher Aktualisierung verwaltet werden kann. Es gibt viele Möglichkeiten ...
Und der Gewinner ist...
Kundenanalyse! Heutzutage ist der wichtigste Faktor, um der Konkurrenz einen Schritt voraus zu sein, Erkenntnisse aus Daten zu gewinnen und auf dieser Grundlage Geschäftsentscheidungen zu treffen. Wäre es nicht toll, die Historie des Newsletter-Versands durchzugehen und deren Intensität und Effektivität zu analysieren? Für jeden Kunden? Und diese dann mit Einkaufsdaten verknüpfen, Interessen des Kunden aufdecken, individuelle Empfehlungen aufbereiten und diese per personalisierter E-Mail versenden?
Ein solcher Ansatz würde sicherlich unsere Conversion Rate (CR) erhöhen. Die Conversion Rate ist eine der wichtigsten Kennzahlen im Online-Marketing; Es zeigt, wie viele Personen einen Kauf tätigen, nachdem sie einige unserer Werbematerialien (Anzeigen, Newsletter usw.) gesehen haben. Ein hohes CR bedeutet erhöhte Geschäftseffektivität.
Nachdem wir nun einige der damit verbundenen Marketingaktivitäten verstanden haben, kommen wir zum Datenmodell!
Beginnen wir mit der Modellierung einer Newsletter-Datenbank!
Wenn wir uns direkt einarbeiten, sehen wir, dass die beiden Haupttabellen im Modell der client und newsletter Tabellen.
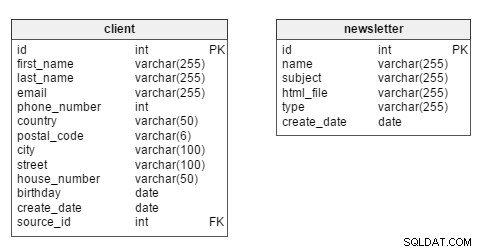
Da wir hauptsächlich an Clientanalysen interessiert sind, wird der client Der Tisch sollte in der Mitte des Modells bleiben. In dieser Tabelle hat jeder Client seine eigene eindeutige id . Wir speichern auch solche Informationen wie den first_name des Kunden und last_name , Kontaktinformationen (email , phone_number , Straße), birthday , create_date (als der Datensatz des Kunden in die Datenbank eingegeben wurde) und seine source_id – d.h. ob sie sich auf unserer Seite registriert haben oder ein Geschäftspartner uns ihre Daten zur Verfügung gestellt hat.
Der newsletter Tabelle speichert Daten zu jeder Newsletter-Erstellung. Newsletter können anhand ihrer eindeutigen id identifiziert werden . Jeder wird durch einen name beschrieben (z. B. „Neue Damenkollektion – Herbst 2016“), E-Mail subject („Die modischsten Klamotten für sie – jetzt kaufen!“), html_file (die Datei, die den HTML-Code für diesen bestimmten Newsletter enthält), Newsletter-type (z. B. „neue Kollektion“, „Geburtstags-Newsletter“) und das create_date .
Marketing-Zustimmungen
Um Marketinginformationen (per Post, Telefon, E-Mail oder SMS) zu versenden, muss ein Unternehmen die Zustimmung seiner Kunden einholen. In unserem Modell werden Einwilligungen in einer separaten Tabelle mit dem Namen marketing_consent . Es speichert Informationen über die aktuellen Marketingeinwilligungen für alle unsere Kunden. Zustimmungen werden als boolesche Variablen codiert – TRUE (stimmt der Marketingkommunikation zu) oder FALSE (stimmt nicht zu).
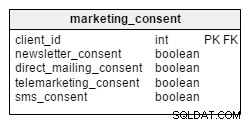
Es ist sehr wichtig, Informationen darüber zu speichern, wann ein Kunde zugestimmt hat, Werbung über jeden Kommunikationskanal zu erhalten. Es ist auch von Vorteil, aufzuzeichnen, wann sie ihre Zustimmung für jeden Kanal zurückgezogen haben. Für solche Zwecke muss der consent_change Tabelle wurde entworfen.
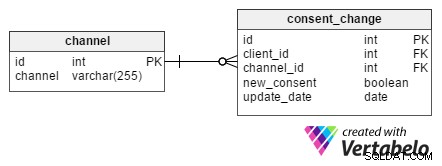
Jede Änderung hat eine eindeutige id und wird einem bestimmten Client durch seine client_id zugewiesen . Wenn ein Kunde darum bittet, aus Newsletter-E-Mails entfernt zu werden, wird die Newsletter-id aus dem channel Tabelle wird auch in consent_change channel_id der Tabelle Attribut. Die new_consent -Attribut ist ein boolescher Wert (TRUE oder FALSE) und stellt neue Marketingeinwilligungen dar.
Das update_date Spalte enthält das Datum, an dem ein Kunde eine Änderung angefordert hat. Diese Struktur ermöglicht es uns, an einem bestimmten Tag eine Reihe von Einwilligungen für alle Kunden zu extrahieren. Es ist äußerst nützlich, wenn sich ein Kunde darüber beschwert, eine E-Mail zu erhalten, nachdem er sich bereits von unserem Newsletter abgemeldet hat. Mit diesen gespeicherten Informationen können wir überprüfen, wann die Abmeldung erfolgt ist, und hoffentlich bestätigen, dass sie nach dem Versand des E-Mail-Newsletters erfolgt ist.
Aussendungen in Ordnung halten
Ein perfektes Datenbankmodell für den Newsletter-Versand zu entwerfen, ist kein Kinderspiel. Wieso den? Nun, natürlich müssen wir in der Lage sein, jede einzelne Newsletter-Erstellung (also Layout, Grafiken, Produkte, Links usw.) zu identifizieren. Wir wissen auch, dass eine Kreation mehrfach verschickt werden kann:Manager können entscheiden, dass ein Bündel von E-Mails morgens an die Hälfte der Kunden und abends an die andere Hälfte gesendet wird. Daher ist es entscheidend zu erfassen, welche Kunden wann welchen Newsletter erhalten haben. Deshalb besteht dieser Teil des Modells aus drei Tabellen:
- Der
newsletterTabelle – die wir zuvor beschrieben haben. - Der
newsletter_sendoutTabelle – die einen einzelnen Versand identifiziert. Zum Beispiel der Weihnachtsnewsletter (id ="2512") wurde am 10. Dezember um 18:00 Uhr per E-Mail verschickt. Durch diese Aufzeichnungen können Vermarkter denselben Newsletter zu unterschiedlichen Zeiten an verschiedene Kundengruppen senden. - Die
sendout_receiversTabelle – die Daten über die Empfänger jeder Aussendung sammelt. Es gibt einen Datensatz für jede E-Mail von jedem Versand. Jede Zeile hat drei Spalten:id(identifiziert das Ereignis des Sendens einer E-Mail an einen Client),client_id(zur Identifizierung von Kunden aus unserer Datenbank) undnl_sendout_id(Kennzeichnung einer Newsletter-Versendung).
Hier ist das vollständige Newsletter-Modell:
Irgendwelche Ideen zur Verbesserung dieses Modells?
Eine Möglichkeit besteht darin, eine response Tisch. Darin würden die Reaktionen der Kunden gespeichert – ob sie die E-Mail geöffnet, auf die Anzeige geklickt oder die Nachricht nie gesehen haben, weil sie als Spam markiert wurde. Wo sollen wir die response Tabelle zu unserem Modell und welche Beziehung soll angewendet werden? Teilen Sie Ihre Gedanken im Kommentarbereich unten mit.