Heutzutage gibt es eine Reihe von Möglichkeiten, jemanden zu kontaktieren, richtig?
Wir haben verschiedene Telefone:Handy und Festnetz, privat und beruflich. Wir haben verschiedene Adressen – Wohn-, Post-, Rechnungs-, Geschäftsadressen usw. – und wahrscheinlich auch mehrere E-Mail-Adressen. Vergessen Sie nicht Skype und verschiedene Messaging-Apps. Fügen Sie jetzt LinkedIn und Facebook hinzu – die übrigens beide ihre eigenen Messaging-Elemente haben.
Vor nicht allzu langer Zeit gab es viele davon noch nicht. Sie können also ziemlich sicher sein, dass wir in ein paar Jahren eine neue Art der Kontaktaufnahme mit Menschen und Organisationen haben werden.
Können wir all diese Kontaktinformationen so modellieren, dass wir unser Datenbankdesign nicht ändern müssen, wenn „das Neueste“ auftaucht? Lesen Sie weiter, um es herauszufinden...
Das Parteikontaktstellen-Modell
Mit einem Wort, ja. Datenbanken können so gestaltet werden, dass sie Informationen enthalten, die wir noch nicht einmal haben.
Ich werde direkt hineinspringen und Ihnen die Lösung zeigen, dann werde ich beschreiben, wie die Teile zusammenarbeiten. Ich werde die verschiedenen Kontaktmöglichkeiten als Kontaktstellen bezeichnen , obwohl ich Kontaktmethoden gesehen habe und sogar Kontaktstellen verwendet.
Physisch werden all diese Kontaktpunkte in einer einzigen Tabellenspalte gespeichert, contact_point.contact_value . Denken Sie an eine Telefonnummer, eine E-Mail-Adresse oder eine Webadresse (URL) und Sie werden verstehen, warum wir sie alle hier speichern können; Auf dieser Ebene sind sie nur Zeichenfolgen (Varchars). Die Unterscheidung liegt in den Metadaten. Einzige Ausnahme hiervon ist die Postanschrift, die später noch genauer beschrieben wird.
Die gelben Tabellen auf der linken Seite enthalten Metadaten und die blauen Tabellen auf der rechten Seite Geschäftsdaten.
Die Hauptkategorien
Obwohl wir viele Möglichkeiten haben, jemanden zu kontaktieren, fallen diese tatsächlich in eine kleine Anzahl von Kategorien oder Typen. Sie werden sehen, was ich meine, wenn Sie sich die folgende Liste ansehen:
| Kontaktpunkttyp |
|---|
| Telefonnummer (Festnetz) |
| Handynummer |
| Faxnummer |
| E-Mail-Adresse |
| Postanschrift |
| Webadresse |
| Pager |
In gewissem Sinne sind diese physikalisch verschieden. Natürlich können Sie mit einem Mobiltelefon einen Festnetzanschluss oder ein anderes Mobiltelefon anrufen. Bei Sprachanrufen zwischen Festnetz und Handy ist die Unterscheidung nicht so wichtig. Trotzdem senden wir eine SMS eher an ein Mobiltelefon als an eine Festnetznummer.
Es ist jedoch unwahrscheinlich, dass Sie absichtlich eine Faxnummer anrufen. Was werden Sie schließlich dazu sagen, wenn Sie es hören, außer „Ups, falsche Nummer“? Es ist natürlich viel wahrscheinlicher, dass Sie mit einem anderen Faxgerät anrufen, egal ob physisch oder emuliert. Sie würden auch keinen Brief an das Festnetz senden oder versuchen, eine Postanschrift anzurufen.
Es ist wichtig, dass wir diese Typen unterscheiden, weil wir unterschiedlich mit ihnen interagieren. Dies gilt insbesondere dann, wenn Ihre Anwendung in irgendeiner Weise mit Kommunikationsdiensten integriert ist. Es muss wissen, mit welchem Typ es interagieren soll.
Wie Parteien Kontaktstellen nutzen
Dies ist wahrscheinlich ein bisschen intuitiver, ein bisschen mehr im Einklang damit, wie wir über Kontakttypen denken. Hier ist eine längere Liste (aber nicht vollständig!), die Ihnen helfen wird, ein Gefühl für diese Typen zu bekommen:
| Parteikontakttyp (Kontaktpunkttyp) |
|---|
| Konferenzleitung (Telefonnummer) |
| Rechnungsadresse (Postanschrift) |
| Lieferadresse (Postanschrift) |
| Durchwahl (Telefonnummer) |
| Ferien-/Urlaubsadresse (Postanschrift) |
| Ferien-/Urlaubstelefon (Telefonnummer) |
| Heimatadresse (Postanschrift) |
| Telefon zu Hause (Telefonnummer) |
| Telefon/Fax zu Hause (Telefonnummer) |
| LinkedIn-Profil (Webadresse) |
| Hauptadresse (Postanschrift) |
| Haupt-E-Mail (E-Mail-Adresse) |
| Hauptfax (Faxnummer) |
| Haupttelefon (Telefonnummer) |
| Hauptwebsite (Webadresse) |
| Persönliche E-Mail (E-Mail-Adresse) |
| Persönliches Fax (Faxnummer) |
| Persönliches Handy (Handynummer) |
| Persönlicher Pager (Pager) |
| Persönliche Website (Webadresse) |
| Sekundäre Adresse (Postanschrift) |
| Zweittelefon (Telefonnummer) |
| Social-Media-Profil (Webadresse) |
| Arbeitsadresse (Postanschrift) |
| Arbeits-E-Mail (E-Mail-Adresse) |
| Arbeitsfax (Faxnummer) |
| Mobil arbeiten (Handynummer) |
| Geschäftstelefon (Telefonnummer) |
Die Postanschrift – ein Sonderfall
Mit Ausnahme einer Postanschrift werden alle diese Kontaktstellenarten in einem einzigen Feld gespeichert. Dies erfordert normalerweise eine Reihe von Zeilen (oder Feldern).
Es gibt hier einen Blog-Artikel, der eine einfache, sprachunabhängige Möglichkeit zum Speichern von Postanschriften vorschlägt. Wenn Ihre Anforderungen eher einfach sind – z.B. Adressetiketten so zu drucken, wie sie in das System eingegeben werden – dieser Ansatz wird wahrscheinlich ausreichen. Wenn Ihre Anforderungen anspruchsvoller sind, müssen Sie wahrscheinlich eine andere Lösung entwickeln.
Um eine Vorstellung davon zu bekommen, wie komplex die Adressierung sein kann, werfen Sie einen kurzen Blick auf dieses Schema für Adresstypen des britischen Standards BS7666. Der Standard umfasst eine Reihe von Teilen, die Straßenverzeichnisse, Grundstücks- und Grundstücksverzeichnisse und Lieferstellen abdecken. Es wird nicht zwischen Gewerbe- oder Wohnimmobilien unterschieden; zwischen bewohntem, bebautem oder unbebautem Land; zwischen städtischen oder ländlichen Gebieten; oder zwischen postalisch adressierbaren Einheiten und nicht postalisch adressierbaren Einheiten s wie Kommunikationsmasten (Türme). Um dies zu erreichen, werden Begriffe eingeführt, mit denen die meisten von uns wahrscheinlich nicht vertraut sind, wie z. Bekannte Beispiele für PAOs sind der Name eines Gebäudes oder eine Hausnummer. Ein sekundäres adressierbares Objekt (SAO) wird jedem adressierbaren Objekt gegeben, das durch Bezugnahme auf ein PAO adressiert wird. Dies könnte der erste Stock eines benannten Gebäudes sein.
Um uns eine Visualisierung davon zu geben, habe ich es schnell in ein UML-Modellierungstool zurückentwickelt. Folgendes erhalten wir:
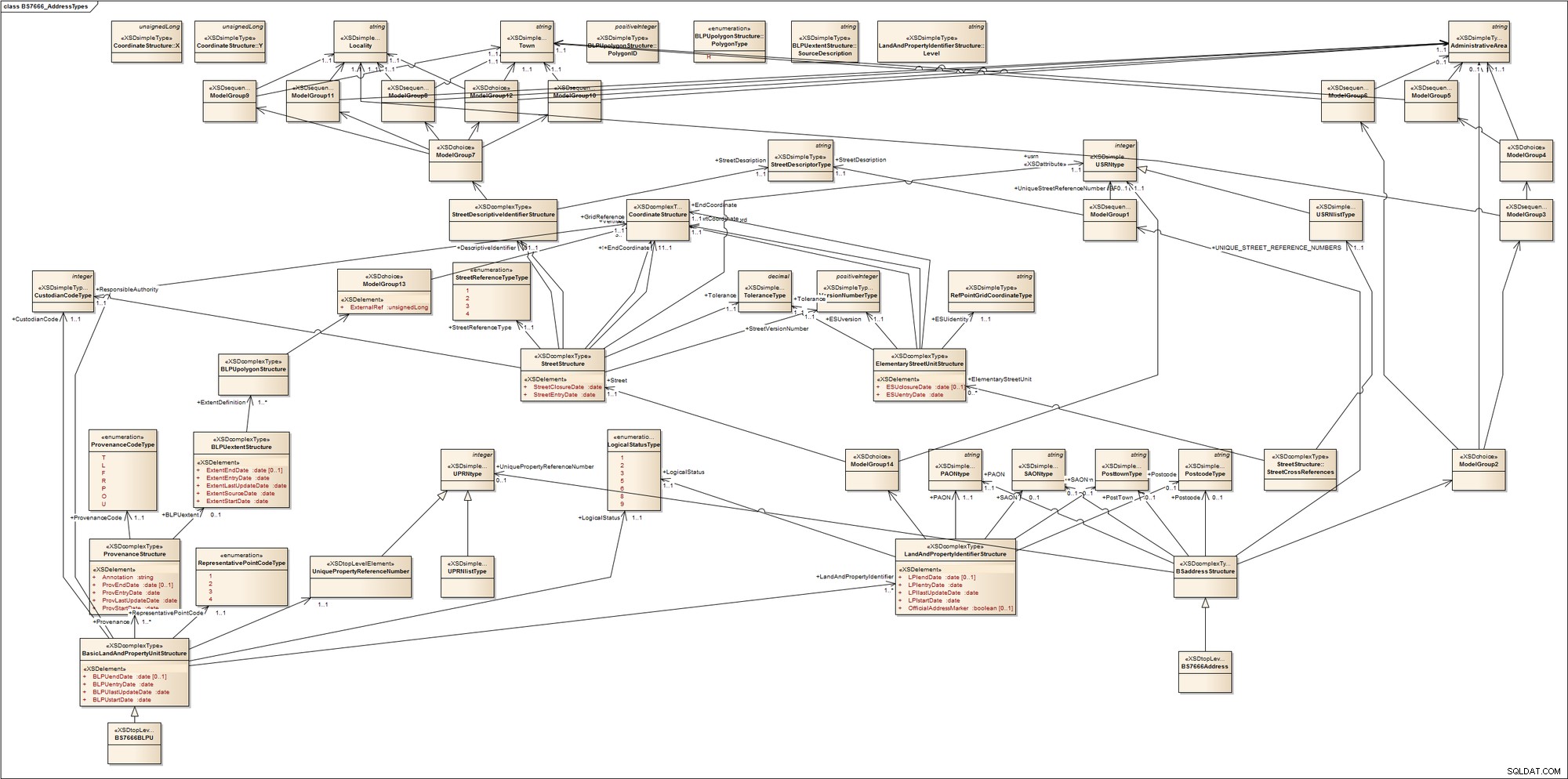
Mein Punkt ist, dass es ziemlich kompliziert und chaotisch werden kann; die Adressierung in manchen Domains kann sehr komplex sein.
Wenn Sie dies zu einer einzigen relationalen Tabelle zusammenfassen, erhalten Sie etwa Folgendes:
Während dies BS7666-Adresskomponenten erfasst, sagt es Ihnen nicht, wie das Modell funktioniert. Die gesamte relationale Logik des XML-Schemas wird in der Anwendungslogik versteckt.
Diese beiden Diagramme repräsentieren zwei Extreme der Datenmodellierung . Aber gibt es einen Mittelweg, um Adressen zu modellieren?
Es ist tatsächlich möglich, ein relativ einfaches Adressmodell zu haben, das flexibel und konfigurierbar ist.
Adresskomponenten
Ein Adressbestandteil ist typischerweise eine Zeile auf einem Adressetikett, oder besser gesagt eine Art von Zeile auf einem Adressetikett. Die Art von Komponenten, die wir normalerweise für britische Adressen verwenden, sind in der folgenden Tabelle aufgeführt:
| Adresskomponententyp |
|---|
| Adressat |
| Bereich |
| Gebäudename |
| Gebäudenummer |
| Land |
| Grafschaft |
| Abteilungsname |
| Abhängige Ortschaft |
| Name der abhängigen Durchgangsstraße |
| Doppelt abhängiger Ort |
| Internationale Postleitzahl |
| Stufe |
| Ort |
| Mailsort SSC |
| Organisationsname |
| PAO-Endnummer |
| PAO-Endungssuffix |
| PAO-Startnummer |
| PAO-Startsuffix |
| PAO-Text |
| Postfach |
| Postleitzahl |
| Poststadt |
| Postleitzahl |
| Postleitzahlentyp |
| SAO-Endnummer |
| SAO-Endungssuffix |
| SAO-Startnummer |
| SAO-Startsuffix |
| SAO-Text |
| Straße |
| Straßenbeschreibung |
| Nebengebäudename |
| Durchfahrtsname |
| Stadt |
Sie könnten drei oder vier Adresszeilen haben, plus den Postort und die Postleitzahl. Die Schwierigkeit, auf die Sie stoßen werden, besteht jedoch darin, herauszufinden, was diese Zeilen tatsächlich enthalten wenn es darauf ankommt – z. beim Mapping von Daten zwischen Systemen. Wenn Sie Datenprofile erstellen, werden Sie feststellen, dass Adresszeile 3 manchmal einen abhängigen Ort enthält, manchmal aber auch einen Landkreis oder einen Ort. Jetzt sind Sie bei der Verarbeitung natürlicher Sprache (NLP); man muss den Unterschied erkennen zwischen Ort und Landkreis. Und die Permutationen vervielfachen sich, wenn Sie weitere Länder hinzufügen.
Daher müssen wir alle Adressbestandteile für alle Länder definieren, in denen wir tätig sind.
Adressformate
Adressformate bestehen aus zwei Teilen:einem Header und seinem Detail. Der Header ist im Grunde der Name oder Titel, der das Adressformat darstellt ist bekannt durch. Beispiele könnten sein:
| Adressformattyp |
|---|
| Generisch 3-zeilig |
| Generisch 5-zeilig |
| British Forces Post Office (BFPO) |
| International |
| Postanschrift (PAF) |
| USA Adresse |
| Französische Adresse |
Am Beispiel des britischen Full Post Office Address Format (PAF) definieren wir dann die folgenden Adressformatkomponenten:
| Format | Komponente | Sequenz | Ist obligatorisch? |
|---|---|---|---|
| PAF | Adressat | 1 | N |
| PAF | Organisationsname | 2 | N |
| PAF | Abteilungsname | 3 | N |
| PAF | Postfach | 4 | N |
| PAF | Gebäudename | 5 | N |
| PAF | Nebengebäudename | 6 | N |
| PAF | Gebäudenummer | 7 | N |
| PAF | Durchgangsstraße | 8 | N |
| PAF | Straße | 9 | N |
| PAF | Doppelte abhängige Lokalität | 10 | N |
| PAF | Abhängige Ortschaft | 11 | N |
| PAF | Poststadt | 12 | J |
| PAF | Postleitzahl | 13 | J |
Unsere Anwendung liest diese Metadaten und zeigt die Adressbestandteile in der richtigen Reihenfolge an. Wenn eine Adresserfassung erforderlich ist, teilen uns die Metadaten mit, ob die Adresskomponente obligatorisch ist oder nicht.
Häufiger fordert unsere Anwendung die Postleitzahl vom Endbenutzer an und sucht die entsprechenden Werte und füllt die Adresskomponenten automatisch aus. Bei einigen Anwendungen kann der Benutzer die Adresse bearbeiten; andere [lästige] nicht!
Es wird im PDM nicht angezeigt, aber wenn Ihre Organisation international tätig ist, können Sie eine Viele-zu-Viele-Beziehung zwischen address_format_type definieren und country damit das korrekte Adressformat (basierend auf dem Land des Benutzers) dem Endbenutzer (party) angezeigt wird ).
Wann und nur wenn der contact_point ist eine Postanschrift contact_point_type , muss es eine Beziehung zu einem address_format_type haben. Umgekehrt folgt daraus, dass nicht-postalische Adresstypen nie eine Beziehung zu einem address_format_type haben . Außerdem muss das Format unverändert bleiben für die Lebensdauer des contact_point , andernfalls führen Sie die Möglichkeit von Datenintegritätsproblemen ein. (Damit dies nicht der Fall ist , das Ziel address_format_components muss eine Teilmenge der Quelle address_format_components sein ).
Die Spalte contact_value hat für eine Postanschrift keine Bedeutung, da die Werte in einem ddress_line.line_content gespeichert werden . Umgekehrt contact_value ist für alle anderen contact_point_types obligatorisch . Grundsätzlich contact_point.contact_value und address_line.line_content schließen sich gegenseitig aus.
Die Many-to-Many-Beziehung zwischen Partei und Kontaktstelle
Sie können an contact_point denken (plus address_line ) mit den Werten und party_contact als Definition der Verwendung. Dies ermöglicht einen einzelnen contact_point um mehrere Verwendungsmöglichkeiten zu haben . Unsere private [Post-]Adresse kann je nach Kontext auch unsere Rechnungs- und Lieferadresse sein.
Bisher ging die Erzählung davon aus, dass eine Partei einen bestimmten contact_point besitzt . Aber das Datenmodell erzwingt diese Eigentumsregel nicht! Es macht keinerlei solche Einschränkung. Bei diesem Design gibt es noch eine weitere Möglichkeit:mehrere Parteien für dieselben Kontaktpunkte.
Sie müssen die Auswirkungen sorgfältig abwägen, bevor Sie sich auf diesen Weg wagen.
Hier ist ein Beispiel. Im Vereinigten Königreich beschäftigen Awarding Organizations (AOs) im Allgemeinen Lehrer als Prüfer. Ein Lehrer hat zwei Beziehungen:eine mit der Schule, an der er oder sie arbeitet, und eine andere mit der AO als Prüfer. Die Schule wird eine Bank mit contact_points haben mit verschiedenen Telefonnummern und ggf. einer oder mehreren Postanschriften. Dies sind Dinge wie die Hauptadresse der Schule (Postanschrift), Haupt-E-Mail (E-Mail-Adresse), Haupt-Fax (Faxnummer) und Haupt-Telefon (Telefonnummer).
Es ist durchaus möglich, dass unser Prüfer dieselben contact_points verwendet wie seine Schule, aber er oder sie verwendet party_contact sie als arbeitsbezogen zu definieren. Wenn sich die Haupttelefonnummer der Schule ändert, wird die Arbeitsnummer des Lehrers automatisch aktualisiert, was ziemlich praktisch ist.
Wenn Sie diesen Weg einschlagen, müssen Sie auf Anwendungsebene definieren welche Partei oder Parteien berechtigt sind, contact_points zu aktualisieren .
Ein kurzes Wort zur Leistung
Die gelben Metadatentabellen werden ständig von Abfragen verwendet. Folglich bleiben sie wahrscheinlich in Erinnerung. Auf den meisten RDBMSs können Sie Tabellen in den Arbeitsspeicher pinnen, um dies sicherzustellen. In Oracle würde ich diese als indexorganisierte Tabellen erstellen, die klein sind und eine gute Leistung erbringen. Tun Sie, was auch immer das Äquivalent für Ihr RDBMS ist.
Sie möchten auch sicherstellen, dass party_contact Zeilen werden in demselben Block (oder derselben Seite) unter Verwendung eines gruppierten Indexes auf party_id zusammengelegt . Machen Sie dasselbe mit address_line.contact_point_id . Dies reduziert die Menge an IO.
Eine weitere Option besteht, wenn Sie eine party wünschen einen contact_point exklusiv zu besitzen . Sie können dann contact_point zusammenführen in party_contact um party_contact_point zu erstellen (immer noch geclustert auf party_id ). Dies vereinfacht das Modell und könnte die Leistung verbessern.
Ändern von Kontakten bedeutet nicht, Datenbanken zu ändern
Wir leben in einer Zeit, in der man sagen kann, dass Veränderung die einzige Konstante ist.
Das bedeutet nicht, dass sich jede Änderung auf Ihre Datenbank auswirken muss. Mit ein wenig Überlegung können wir unsere Designs zukunftssicher machen – vielleicht mehr als bisher. Dies hilft uns, schnell auf die unvermeidlichen Veränderungen zu reagieren.
Wenn Sie ein Projekt auf der grünen Wiese beginnen, würde ich empfehlen, das Parteienmodell (zu dem Contact Point gehört) für Organisationen und Personen zu verwenden. Warum öffnen Sie das Modell nicht und passen es an Ihre Bedürfnisse an? Bitte zögern Sie nicht, sich eine Kopie zu besorgen und sie zu Ihrer eigenen zu machen.
Aber wenn Ihre Datenbank oder Datenbanken bereits bestimmt sind, kann das Schema, das ich hier vorgestellt habe, immer noch in XML-Form verwendet werden, um Ihre Nutzlast bei der Integration von Daten zwischen Systemen zu definieren.



