Die Operatoren ROLLUP und CUBE werden verwendet, um Ergebnisse zurückzugeben, die von den Spalten in der GROUP BY-Klausel aggregiert wurden.
Die Funktionen GROUPING und GROUPING_ID werden verwendet, um festzustellen, ob die Spalten in der GROUP BY-Liste aggregiert sind (unter Verwendung der ROLLUP- oder CUBE-Operatoren) oder nicht.
Es gibt zwei Hauptunterschiede zwischen den Funktionen GROUPING und GROUPING_ID.
Sie lauten wie folgt:
- Die GROUPING-Funktion ist auf eine einzelne Spalte anwendbar, während die Spaltenliste für die GROUPING_ID-Funktion mit der Spaltenliste in der GROUP BY-Klausel übereinstimmen muss.
- Die GROUPING-Funktion gibt an, ob eine Spalte in der GROUP BY-Liste aggregiert ist oder nicht. Es gibt 1 zurück, wenn die Ergebnismenge aggregiert ist, und 0, wenn die Ergebnismenge nicht aggregiert ist.
Andererseits gibt die GROUPING_ID-Funktion auch eine ganze Zahl zurück. Es führt jedoch die Binär-Dezimal-Konvertierung durch, nachdem es das Ergebnis aller GROUPING-Funktionen verkettet hat.
In diesem Artikel werden wir anhand von Beispielen die Funktionen GROUPING und GROUPING_ID in Aktion sehen.
Einige Dummy-Daten vorbereiten
Lassen Sie uns wie immer einige Dummy-Daten erstellen, die wir für das Beispiel verwenden werden, mit dem wir in diesem Artikel arbeiten werden.
Führen Sie das folgende Skript aus:
CREATE Database company;
USE company;
CREATE TABLE employee
(
id INT PRIMARY KEY,
name VARCHAR(50) NOT NULL,
gender VARCHAR(50) NOT NULL,
salary INT NOT NULL,
department VARCHAR(50) NOT NULL
)
INSERT INTO employee
VALUES
(1, 'David', 'Male', 5000, 'Sales'),
(2, 'Jim', 'Female', 6000, 'HR'),
(3, 'Kate', 'Female', 7500, 'IT'),
(4, 'Will', 'Male', 6500, 'Marketing'),
(5, 'Shane', 'Female', 5500, 'Finance'),
(6, 'Shed', 'Male', 8000, 'Sales'),
(7, 'Vik', 'Male', 7200, 'HR'),
(8, 'Vince', 'Female', 6600, 'IT'),
(9, 'Jane', 'Female', 5400, 'Marketing'),
(10, 'Laura', 'Female', 6300, 'Finance'),
(11, 'Mac', 'Male', 5700, 'Sales'),
(12, 'Pat', 'Male', 7000, 'HR'),
(13, 'Julie', 'Female', 7100, 'IT'),
(14, 'Elice', 'Female', 6800,'Marketing'),
(15, 'Wayne', 'Male', 5000, 'Finance')
Im obigen Skript haben wir eine Datenbank namens „Company“ erstellt. Wir haben dann eine Tabelle „Mitarbeiter“ in der Firmendatenbank erstellt. Schließlich haben wir einige Dummy-Datensätze in die Employee-Tabelle eingefügt.
GROUPING-Funktion
Wie oben erwähnt, gibt die GROUPING-Funktion 1 zurück, wenn die Ergebnismenge aggregiert ist, und 0, wenn die Ergebnismenge nicht aggregiert ist.
Werfen Sie einen Blick auf das folgende Skript, um die GROUPING-Funktion in Aktion zu sehen.
SELECT department AS Department, gender AS Gender, sum(salary) as Salary_Sum, GROUPING(department) as GP_Department, GROUPING(gender) as GP_Gender FROM employee GROUP BY ROLLUP (department, gender)
Das obige Skript zählt die Summe der Gehälter aller männlichen und weiblichen Mitarbeiter, die zuerst nach der Spalte „Abteilung“ und dann nach der Spalte „Geschlecht“ gruppiert werden. Zwei weitere Spalten werden hinzugefügt, um das Ergebnis der GROUPING-Funktion anzuzeigen, die auf die Spalten „Department“ und „Gender“ angewendet wird.
Der ROLLUP-Operator wird verwendet, um die Summe der Gehälter in Form von Gesamtsummen und Zwischensummen anzuzeigen.
Die Ausgabe des obigen Skripts sieht so aus.
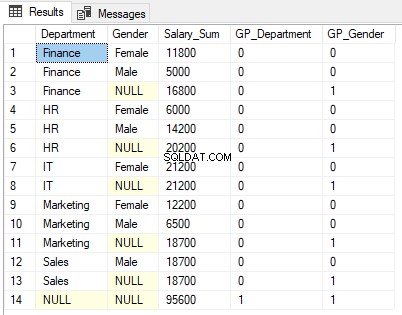
Schauen Sie sich die Ausgabe genau an. Die Summe der Gehälter wird nach Geschlecht nach Abteilungsgeschlecht angezeigt (Zeile 1, 2, 4, 5, 7, 9, 10 und 12). Es wird dann auch nur nach Geschlecht aggregiert (Zeile 3, 6, 8, 11 und 13). Schließlich wird die Gesamtsumme der Gehälter, aggregiert nach Abteilung und Geschlecht, in Zeile 14 angezeigt.
1 wird in der GROUPING-Funktionsspalte GP_Gender für Zeilen angezeigt, in denen Ergebnisse nach Geschlecht aggregiert werden, d. h. Zeilen 3, 6, 8, 11 und 13. Dies liegt daran, dass die GP_Gender-Spalte das Ergebnis der GROUPING-Funktion enthält, die auf die Gender-Spalte angewendet wird.
In ähnlicher Weise enthält Zeile 14 die aggregierte Summe aller Abteilungen und aller Spalten. Daher wird 1 für die Spalten GP_Department und GP_Gender zurückgegeben.
Sie können sehen, dass NULL in den Spalten „Abteilung“ und „Geschlecht“ in der Ausgabe angezeigt wird, in der die Ergebnisse aggregiert werden. Beispielsweise wird in Zeile 3 NULL in der Spalte „Geschlecht“ angezeigt, da die Ergebnisse nach der Spalte „Geschlecht“ aggregiert werden und daher kein Spaltenwert zum Anzeigen vorhanden ist. Wir möchten nicht, dass unsere Nutzer NULL sehen, ein besseres Wort hier könnte „Alle Geschlechter“ sein.
Dazu müssen wir unser Skript wie folgt modifizieren:
SELECT CASE WHEN GROUPING(department) = 1 THEN 'All Departments' ELSE ISNULL(department, 'Unknown') END as Department, CASE WHEN GROUPING(gender) = 1 THEN 'All Genders' ELSE ISNULL(gender, 'Unknown') END as Gender, sum(salary) as Salary_Sum FROM employee GROUP BY ROLLUP (department, gender)
Wenn im obigen Skript die auf die Abteilungsspalte angewendete GROUPING-Funktion 1 zurückgibt und „Alle Abteilungen“ in der Abteilungsspalte angezeigt wird. Andernfalls, wenn die Abteilungsspalte den Wert NULL enthält, wird „Unbekannt“ angezeigt. Die Geschlechtsspalte wurde auf die gleiche Weise geändert.
Das Ausführen des obigen Skripts gibt folgende Ergebnisse zurück:
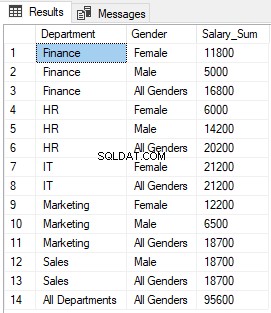
Sie können sehen, dass NULL in den Spalten Abteilung und Geschlecht, wo die GROUPING-Funktion 1 zurückgibt, durch „Alle Abteilungen“ bzw. „Alle Geschlechter“ ersetzt wurde.
GROUPING_ID-Funktion
Die GROUPING_ID-Funktion verkettet die Ausgabe der GROUPING-Funktionen, die auf alle in der GROUP BY-Klausel angegebenen Spalten angewendet werden. Es führt dann eine Binär-Dezimal-Konvertierung durch, bevor es die endgültige Ausgabe zurückgibt.
Lassen Sie uns zuerst die Ausgabe verketten, die von der GROUPING-Funktion zurückgegeben wird, die auf die Spalten „Department“ und „Gender“ angewendet wird. Sehen Sie sich das folgende Skript an:
USE company SELECT department AS Department, gender AS Gender, sum(salary) as Salary_Sum, CAST(GROUPING(department) AS VARCHAR(1)) + CAST(GROUPING(gender) AS VARCHAR (1)) as Grouping FROM employee GROUP BY ROLLUP (department, gender)
In der Ausgabe sehen Sie 0 und 1, die von der GROUPING-Funktion zurückgegeben werden, die miteinander verkettet sind. Die Ausgabe sieht so aus:
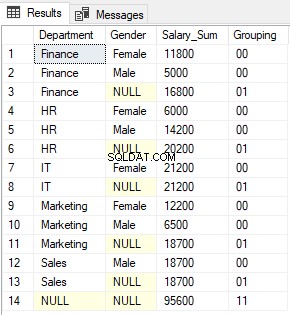
Die GROUPING_ID-Funktion gibt einfach das dezimale Äquivalent des Binärwerts zurück, der als Ergebnis der Verkettung der von den GROUPING-Funktionen zurückgegebenen Werte gebildet wird.
Führen Sie das folgende Skript aus, um die GROUPING ID-Funktion in Aktion zu sehen:
USE company SELECT department AS Department, gender AS Gender, sum(salary) as Salary_Sum, CAST(GROUPING(department) AS VARCHAR(1)) + CAST(GROUPING(gender) AS VARCHAR (1)) as Grouping, GROUPING_ID(department, gender) as Grouping_Id FROM employee GROUP BY ROLLUP (department, gender)
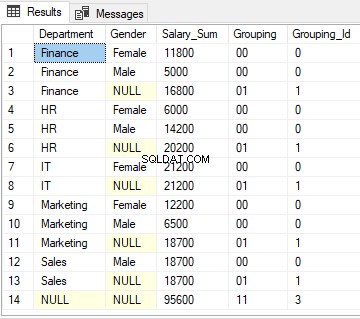
Für Zeile 1 gibt die GRUPPIERUNGS-ID-Funktion 0 zurück, da das dezimale Äquivalent von „00“ null ist.
Für die Zeilen 3, 6, 8, 11 und 13 gibt die GROUPING_ID-Funktion 1 zurück, da das Dezimaläquivalent von „01“ 1 ist.
Schließlich gibt die GROUPIND_ID-Funktion für Zeile 14 3 zurück, da das binäre Äquivalent von „11“ 3 ist.
Die Ausgabe des obigen Skripts sieht so aus:
Siehe auch:
Microsoft:Grouping_ID-Übersicht
Microsoft:Gruppierungsübersicht
YouTube:Gruppierung &Gruppierungs_ID