Beim Entwerfen einer Datenbank gibt es viel zu beachten, und nur wenige von uns können sich an alle wertvollen Tipps und Tricks erinnern, die wir gelernt haben. Werfen wir also einen Blick auf einige Online-Ressourcen, die Tipps und Best Practices für das Datenbankdesign enthalten. Während wir fortfahren, werde ich meine eigenen Meinungen zu den vorgestellten Ideen teilen, basierend auf meiner Erfahrung im Datenbankdesign.
Offensichtlich ist dieser Artikel keine vollständige Liste, aber ich habe versucht, einen Querschnitt von Quellen zu überprüfen und zu kommentieren. Hoffentlich finden Sie die Informationen, die Ihren Bedürfnissen und Zielen am besten entsprechen.
Als Randbemerkung war ich überrascht festzustellen, dass viele Artikel, die sich mit Datenbankdesign-Praktiken befassen, nur sehr wenige Beispiele enthielten; Die Online-Ressourcen, die ich für den Artikel über Fehler und Fehler überprüft habe, hatten einen höheren Prozentsatz davon. Dieser Mangel ist ein Nachteil, denn Beispiele sind extrem wichtig, um den Punkt zu vermitteln.
Datenbanktipps für erfahrene Designer
Beginnen wir zunächst mit Quellen, die fortgeschrittene Tipps und Best Practices für das Datenbankdesign enthalten. Diese sind für Designer, die bereits in der Datenmodellierung arbeiten und dies schon seit einiger Zeit tun. Einige Artikel zielen auf ein mittleres Niveau ab, aber wenn sie fortgeschrittene Konzepte behandeln, habe ich sie in diese Liste aufgenommen.
Datenbankrichtlinien (RDBMS/SQL)
von Steve Djajasaputra | SOA, Java, Softwareentwicklung – BlogSpot | 16. Januar 2013
Dieser Artikel von Herrn Djajasaputra ist ziemlich beeindruckend:Er listet zahlreiche Tipps für das Schema, Indizes und Ansichten auf; Er bietet auch eine ziemlich detaillierte Namenskonvention. Und seine Tipps gehen weiter (und weiter). Die Breite ist beeindruckend, aber es gibt fast keine Beispiele. Einige seiner Punkte könnten als umstritten betrachtet werden, aber insgesamt ist dies eine sehr solide Präsentation.
Besonders beeindruckt hat mich, dass er eine genaue Regel zur Verwendung natürlicher versus künstlicher (d. h. Ersatz- oder generierter) Primärschlüssel gibt. Er hält dies nett und einfach und gibt an, dass wir einen natürlichen Schlüssel bevorzugen sollten, weil er sinnvoll ist. Er stellt auch Richtlinien für die beste Verwendung eines künstlichen Schlüssels bereit – insbesondere, wenn der natürliche Schlüssel nicht eindeutig ist oder wenn Sie den Wert des natürlichen Schlüssels ändern müssen. In seinen eigenen Worten:
Bevorzugen Sie zunächst den natürlichen Schlüssel, da er aussagekräftiger ist und um Doppelungen zu vermeiden (vorhandene Spalte wiederverwenden). Es gibt jedoch Fälle, in denen Sie einen künstlichen Schlüssel benötigen:wenn der natürliche Schlüssel nicht eindeutig ist (z. B. Namen) oder wenn Sie den Wert ändern müssen.Da seine Liste mit Tipps so lang ist, kann ich mir nicht vorstellen, sie alle zu behalten. Aber auf jeden Abschnitt könnte verwiesen werden, wenn Sie an Datenbankdesign, Leistung, gespeicherten Prozeduren und Versionsverwaltung arbeiten. Es gibt auch einen Abschnitt zu Oracle-spezifischen Punkten, die nützlich wären, wenn Sie mit Oracle zusammenarbeiten oder planen, Oracle zu unterstützen.
Alles in allem ist dies eine sehr lohnenswerte und umfassende Ressource.
9 Tipps für besseres Datenbankdesign
von Jeffrey Edison | Vertabelo-Blog | 22. September 2015
Ich werde mir hier ein wenig Eigenwerbung gönnen.
Dieser Artikel mit 9 Tipps für ein besseres Datenbankdesign basiert auf meiner Erfahrung als Designer und Architekt. Ich habe auch zusätzliche Erkenntnisse aus der Recherche der Best Practices anderer für das Datenbankdesign gewonnen.
Meine Liste stellt einige der Hauptprobleme dar, die bei der Arbeit mit Datenmodellen auftreten können. Ich habe die Tipps in der Reihenfolge angeordnet, in der sie während des Projektlebenszyklus auftreten (und nicht nach Wichtigkeit oder Häufigkeit), da dies zumindest meiner Meinung nach am nützlichsten wäre. Die Leser können dieser Checkliste bewährter Verfahren während des gesamten Lebenszyklus eines Projekts folgen.
Aus dem Artikel:
Um Al Capone (oder John Van Buren, Sohn des 8. US-Präsidenten) zu paraphrasieren:„Teste früh, teste oft“. Damit gehen Sie den Weg der Continuous Integration. Das Testen in einem frühen Entwicklungsstadium spart Zeit und Geld. Beim Testen der Datenbank sollte das Ziel sein, eine Produktionsumgebung zu simulieren:„Ein Tag im Leben der Datenbank“. Welche Volumina sind zu erwarten? Welche Benutzerinteraktionen sind wahrscheinlich? Werden die Grenzfälle behandelt?Durch die Beachtung dieser Tipps habe ich festgestellt, dass Datenbanken besser gestaltet und robuster werden. Obwohl keine dieser Aktivitäten sehr viel Zeit in Anspruch nehmen wird, kann jede einen enormen Einfluss auf die Qualität Ihres Datenmodells haben.
Ich hoffe, dass meine Liste mit Tipps für fortgeschrittene und fortgeschrittene Designer nützlich ist.
20 Best Practices für das Datenbankdesign
von Cagdas Basaraner | Code-Guthaben – BlogSpot | 24. Juli 2011
Herr Basaraner präsentiert uns eine interessante Liste mit 20 Best Practices für das Datenbankdesign. Ich hätte es vorgezogen, wenn er einige davon gruppiert hätte; Beispielsweise könnten die ersten vier Punkte alle unter „Gute Namenskonventionen verwenden“ behandelt werden.
Darüber hinaus gibt er an, dass die Verwendung einer synthetischen, generierten (ganzzahligen) ID als Primärschlüssel aller Tabellen eine bewährte Methode ist. Tatsächlich ist dies immer noch ein umstrittenes Thema mit Argumenten dafür und dagegen. Einige seiner Best Practices sind ziemlich allgemein gehalten, wie „Für … missionskritische [sic] Datenbanksysteme, Notfallwiederherstellung und Sicherheitsdienst verwenden …“ Ich widerspreche diesem Punkt nicht, aber er ist sehr hochrangig.
Auf der positiven Seite war dieser Artikel einer der wenigen, die die Verwendung eines objektrelationalen Mapping-Frameworks (ORM) erwähnten. Einige Kommentatoren waren mit der Formulierung des Tipps nicht einverstanden, aber zumindest wird die Verwendung eines ORM-Frameworks erwähnt:
Verwenden Sie ein ORM-Framework (Object Relational Mapping) (z. B. Hibernate, iBatis ...), wenn der Anwendungscode groß genug ist. Leistungsprobleme von ORM-Frameworks können durch detaillierte Konfigurationsparameter behandelt werden.Dennoch hätte diese Liste verbessert werden können. Es sollte eindeutig Punkte identifizieren, die nur für einige spezifisch sind Datenbankverwaltungssysteme (z. B. SQL Server). Präzise Statistiken über Leistung, Heuristik oder die Wichtigkeit, Zeit für Design aufzuwenden statt auf Wartung und Neugestaltung wäre gut gewesen. Es wurden auch mehr Beispiele benötigt, aber das ist ein Problem für die meisten dieser Artikel.
Wenn Sie mit SQL Server arbeiten, ein ORM-Framework verwenden möchten oder lieber eine Aufzählung mit Tipps als einen langen und detaillierten Artikel benötigen, dann ist dieser Artikel genau das Richtige für Sie.
(Hinweis:Dieser Artikel erschien auch auf mehreren anderen Websites, darunter CodeBuild, Java Code Geeks und DZone.)
Grundlagen des Datenbankdesigns. 10 Dinge, die Sie unbedingt tun müssen
von Michelle A. Poolet | SQL Server Pro | 1. März 2011
Ein Teil der Tipps von Ms. Poolet ist ganz normal und kann in vielen anderen Ressourcen gefunden werden, aber es gibt auch ein paar eher ungewöhnliche Punkte. Unter ihren generischen Punkten fördert sie die Verwendung von Subtypen und Supertypen (dem ich stark zustimme), da dies objektorientiertes Design widerspiegelt und von Entwicklern leicht verstanden werden kann. Aus ihrem Artikel:
Scheuen Sie sich nicht, Supertype- und Subtype-Entitäten in Ihr Design im CDM und weiter einzubeziehen. Die Untertypen stellen Klassifikationen oder Kategorien des Obertyps dar… Entitäten werden als Untertypen dargestellt, wenn es mehr als ein einzelnes Wort oder einen Ausdruck braucht, um die Entität zu kategorisieren.
Wenn eine Kategorie ein Eigenleben hat, mit separaten Attributen, die beschreiben, wie die Kategorie aussieht und sich verhält, und getrennten Beziehungen zu anderen Entitäten, dann ist es an der Zeit, die Supertype/Subtype-Struktur aufzurufen . Andernfalls wird ein vollständiges Verständnis der Daten und der Geschäftsregeln, die die Datenerfassung vorantreiben, verhindert.
Einige ihrer Kommentare beziehen sich speziell auf MS SQL Server, auch wenn es sich bei den Kommentaren eigentlich um allgemeine Themen handelt. Ein Hauptpunkt, den Frau Poolet anführt, ist sehr SQL Server-spezifisch:„Speichern Sie Code, der die Daten einer Datenbank berührt, als gespeicherte Prozedur“.
Dies ist in Ordnung, wenn Sie nur ein einzelnes Datenbankverwaltungssystem wie SQL Server unterstützen möchten. Aber für portable Implementierungen wäre das kein guter Rat. Im Allgemeinen entwerfe ich für die Portabilität auf mindestens zwei Verwaltungssysteme mit unterschiedlicher Sprachunterstützung für gespeicherte Prozeduren. Daher würde ich diese Praxis vermeiden.
Dieser Artikel ist am nützlichsten für Leute, die für SQL Server entwickeln und sich auf den amerikanischen Markt (und nicht auf ein internationales System) konzentrieren. Als im Ausland lebende Amerikanerin fand ich jedoch, dass einige ihrer Beispiele etwas zu „USA-zentriert“ sind. Beispielsweise versteht ein Nicht-Amerikaner möglicherweise nicht, was ein Zip+4 ist domain ist und hätte daher kein Verständnis dafür, warum eine dieser Domains ein NOT NULL-Merkmal haben sollte.
Um dies zu veranschaulichen, habe ich ein Datenmodell für beide amerikanischen nichtamerikanischen Adressen erstellt. Wir gehen davon aus, dass unser Datenmodell möglicherweise erfordert, dass Entitäten mit mehr als einer Adresse verknüpft sind:zum Beispiel eine für die Rechnungsstellung, eine für den Versand. Die erste Adresse würde einer Zahlungsmethode zugeordnet; In diesem Fall würde die Adresse verwendet, um Ihr Recht zur Autorisierung dieser Zahlung zu überprüfen. Die Lieferadresse ist natürlich der Ort, an den die Bestellung geliefert wird.
Lassen Sie uns eine amerikanische Adresse als Teil eines Datenbankmodells für Kundenbestellungen erstellen. (Hinweis:Dies ist kein vollständiges Modell, sondern ein Beispiel für das Speichern von Produktbestellungen.)
Wise Coders Solutions empfiehlt, separate Felder für Hausnummern und Straßennamen zu definieren und diese Felder auf NOT NULL zu setzen; dies würde jede Adresse verbieten, die keine Hausnummer und keinen Straßennamen hat. Aber was ist mit Leuten, die Postfächer benutzen? Ihre Adressen werden normalerweise als „PO Box 123“ geschrieben. Sollen wir sie zwingen, als Hausnummer die Postfachnummer und als Straßenname „Postfach“ anzugeben? Ich glaube nicht.
Stattdessen verwenden wir ein Formular mit „Adresszeile 1“ und „Adresszeile 2“. Mehrere Leute haben sich gegen die Verwendung von Zahlen in Feldnamen ausgesprochen, aber für mich ist dies eine ziemlich offensichtliche Lösung. Außerdem habe ich maximale Feldlängen (35 und 70 Zeichen) definiert, die für internationale Zahlungen typisch sind.
Beachten Sie, dass das US- und das Nicht-US-Design beide ein Feld für Regionen innerhalb eines Landes haben, aber das US-Design erfordert, dass eine zweistellige Abkürzung für den Bundesstaat enthalten ist. Beachten Sie außerdem, dass das US-Design keine Adressen in anderen Ländern zulässt.
Wenn Sie Bedenken hinsichtlich der globalen Nutzung Ihrer Datenbank haben, müssen Sie während der Entwurfsphase global denken. Sind unsere Datenbanken für den multinationalen Einsatz unserer Anwendungen vorbereitet?
Lehren aus schlechtem Data-Warehouse-Design
von Michelle A. Poolet | SQL Server Pro | 15. Juni 2009
Dieser Artikel wirft einen Blick auf das Data Warehouse (DWH) und einige seiner Design- und Implementierungsprobleme. Es gibt einen leichten Fokus auf SQL Server, aber es ist ein ziemlich orthodoxer Überblick über das Design für Data Warehousing und Business Intelligence. Unterstützung zu haben und benutzerfreundliche Schnittstellen zu erstellen sind vielleicht nicht die nützlichsten Tipps, aber ich widerspreche ihnen nicht – ich glaube einfach nicht, dass sie Teil des DWH-Designs sind.
Ms. Poolet erklärt, dass der Extract-Transform-Load (ETL)-Prozess Datenqualitätsprüfungen durchführen und möglicherweise Daten „bereinigen“ sollte, bis ein akzeptabler Standard der Datenqualität erreicht ist. Meiner Meinung nach besteht die Gefahr, dass ein Data Warehouse entsteht, das die aus dem Quellsystem extrahierten Informationen nicht richtig widerspiegelt. Die Datenbereinigung sollte in den Quellsystemen durchgeführt werden. ETL sollte Daten nur transformieren, damit sie in das Data Warehouse geladen werden können.
Positiv zu vermerken ist, dass die Empfehlung, ETL-Routinen zu recyceln oder wiederverwendbare zu erstellen, von hoher Relevanz ist. Außerdem stimme ich Frau Poolet in Bezug auf die Skalierbarkeit zu. Ihre Kommentare zu Risikomanagement und Compliance, insbesondere zum Sarbanes-Oxley Act, scheinen ziemlich spezifisch zu sein; Ich gehe davon aus, dass diese aus ihrem Geschäftsfeld stammen.
Schließlich hat sie eine schöne Checkliste mit Punkten in Bezug auf Dimensionen, Faktentabellen und Schemaauswahlen während des OLAP-Designs (Online Analytical Processing). Diese scheinen während des Datenbankentwurfsprozesses sehr relevant zu sein. Ich hätte mir diese Liste länger gewünscht, mit mehr Details oder Beispielen, aber ich war froh, dass diese praktischen Tipps enthalten waren.
11 wichtige Regeln für das Datenbankdesign, denen ich folge
von Shivprasad Koirala | Code-Projekt | 25. Februar 2014
Ich mag die vernünftigen und klaren Ratschläge am Anfang dieses Artikels sehr. Konzepte wie „berücksichtigen Sie die Art der Anwendung“ und „unterteilen Sie Ihre Daten in logische Teile“ sind genau richtig. Dies sind wichtige Hilfen bei der Erstellung Ihres Datenmodells. Wie Herr Koirala sagt:
Wenn Sie mit dem Datenbankdesign beginnen, ist das erste, was Sie analysieren müssen, die Art der Anwendung, für die Sie entwerfen, ob sie transaktional oder analytisch ist. Sie werden feststellen, dass viele Entwickler standardmäßig Normalisierungsregeln anwenden, ohne über die Art der Anwendung nachzudenken, und sich später mit Leistungs- und Anpassungsproblemen befassen.Es gibt jedoch ein paar Punkte, die mich nicht überzeugen. Nehmen Sie zum Beispiel das Zentralisieren von Name-Wert-Paaren in einer einzigen Tabelle. Dieses One True Lookup Table (OTLT)-Design wird diskutiert, aber es wird allgemein als schlechte Praxis oder zumindest als Anti-Pattern im Design angesehen. Ich stehe auf der Seite der Anti-OTLT-Gruppe; Diese Tabellen führen zu zahlreichen Problemen. Als Äquivalent zu dieser Praxis könnten wir die Softwareentwicklungsanalogie verwenden, einen einzigen Enumerator zu verwenden, um alle möglichen Werte aller möglichen Konstanten darzustellen.
Zur Erinnerung:Die OTLT-Tabelle sieht normalerweise ungefähr so aus, wobei Einträge aus mehreren Domänen in dieselbe Tabelle geworfen werden. Ich stimme der Anti-OTLT-Gruppe zu; Diese Tabellen führen zu zahlreichen Problemen.
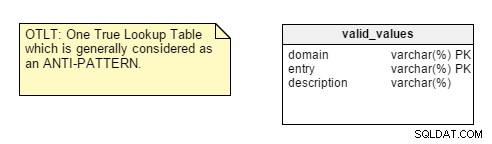
Außerdem wirken einige Punkte etwas esoterisch, wie „auf durch Trennzeichen getrennte Daten achten“. Dies ist zwar ein gültiger Punkt, aber einer, an den ich normalerweise nicht denke, wenn ich ein neues Datenmodell erstelle.
Herr Koirala hat ein paar OLAP-Designelemente, die im Allgemeinen nicht in anderen Best-Practice-Listen erwähnt werden. Seine Einbeziehung eines Dimensions- und Faktendesigns kann nützlich sein, aber es könnte auch gefährlich für unerfahrene Designer sein.
Dieser Artikel ist interessant, wenn Sie von Anfang an zu einer fortgeschritteneren Datenmodellierung übergehen. Es wird Ihnen helfen, den analytischen und den transaktionalen Charakter Ihrer zukünftigen Modelle zu berücksichtigen.
Big Data:Fünf einfache Leistungstipps für das Datenbankdesign
von Dave Beulke | davebeulke.com | 19. März 2013

Der Artikel von Herrn Beulke befasst sich mit leistungsorientierten Designtipps. Er zeigt, wie man die richtige Normalisierung überprüft:weder zu viel noch zu wenig. (Übernormalisierung wirkt sich negativ auf die Datenbankleistung aus.)
Außerdem ist die Verwendung von natürlichen Geschäftsschlüsseln anstelle von generierten Primärschlüsseln ein guter Rat, wenn Sie vermeiden möchten, dass bei jedem Datenbankzugriff ein Geschäftsschlüssel in eine generierte Zeilen-ID übersetzt wird.
Die Verwendung geeigneter Benennungsstandards und Spaltentypen ist ebenfalls ein guter Rat. Der Punkt über die übermäßige Verwendung von Nullable-Spalten ist stichhaltig:Das Erstellen aller Spalten als Nullable-Spalten ist ein Fehler, aber das Definieren einer Spalte als Nullable-Spalte kann für eine bestimmte Geschäftsfunktion erforderlich sein. In den eigenen Worten des Autors:
Sind alle Spalten NULL-fähig? Innerhalb der Datenbankspaltendefinitionen sollten gute Datendomänen, Bereiche und Werte analysiert, bewertet und für die Geschäftsanwendung prototypisiert werden. Gute Standardwerte, ein begrenzter Wertebereich und immer ein Wert sind am besten für Leistung und Anwendungslogik. NULL-fähige Spalten sind nur gut, wenn Daten unbekannt sind oder noch keinen Wert haben. Das Todesdatum einer Person ist das klassische Beispiel für eine NULL-fähige Spalte, da sie unbekannt ist, es sei denn, sie sind bereits tot. Stellen Sie sicher, dass Ihr Datenbankdesign bekannte Daten darstellt und nur ein Minimum an NULL-fähigen Spalten verwendet.Die Tipps von Herrn Beulke sind alle sehr solide, wenn auch etwas unoriginell. Ich hätte mir mehr Big-Data-Elemente gewünscht – so lautet schließlich der Titel des Artikels. Am Ende hatte ich das Gefühl, dass es dem Artikel sowohl an Tiefe als auch an Breite mangelte und er keine Beispiele hatte, um die Punkte zu verdeutlichen. Er bietet jedoch wertvolle Ratschläge in Bezug auf Normalisierung und natürliche Schlüssel.
10 Best Practices für das Datenbankdesign
von Ann All | Enterprise-Apps heute | 15. Juli 2014
Ten Database Design Best Practices wird eigentlich als eine Reihe von Folien präsentiert. Ms. All enthält Informationen von erfahrenen Entwicklern wie Michael Blaha. Er fördert die Wiederverwendung Ihrer Best Practices und Muster. Diese sind verstanden und erprobt und insofern Datenmodellen vorzuziehen, die von Grund auf neu erstellt werden müssen. Aus dem Artikel von Frau All:
Beispielsweise rekonstruiere ich häufig Datenbanken – Datenbanken einer zu ersetzenden Anwendung sowie Datenbanken verwandter Anwendungen. Diese bestehenden Datenbanken haben oft kein verfügbares Datenmodell. Aber ein Datenmodell ist im Datenbankschema implizit und kann zumindest teilweise mit Datenbank-Reverse-Engineering-Techniken extrahiert werden. … Es gibt bewährte Datendarstellungen, die häufig vorkommen und nicht von Grund auf neu erstellt werden müssen.Dies ist eine kurze Diashow, die Datenmodelldesigner schnell durchsehen und die Tipps finden können, die sie ansprechen. Für mich ist der Wiederverwendungstipp einer meiner Favoriten.
Best Practices für Datenbanken
von Cunningham &Cunningham, Inc.
Diese Best Practices begannen ganz gut, gerieten dann aber in einige heikle Probleme. Ich bin nicht davon überzeugt, dass die angebotenen Ratschläge immer zutreffend sind.
Auf der positiven Seite gibt es sehr schöne Beschreibungen kontroverser „Best Practices“, wie z. B. immer automatisch generierte Ersatzschlüssel zu verwenden und gespeicherte Prozeduren zu verwenden oder zu vermeiden. Als Beispiel:
Ein früherer Autor schrieb:"Vermeiden Sie im Allgemeinen Primärschlüssel, die eine Bedeutung haben. Namen sind nicht eindeutig, und viele scheinbar eindeutige Kennungen wie Sozialversicherungsnummern sind es aufgrund von Problemen mit der Zuverlässigkeit von Daten in der realen Welt tatsächlich nicht." Kurz gesagt, dies ist eine Empfehlung, immer einen automatisch generierten (normalerweise numerischen) SurrogateKey anstelle eines domänenbasierten LogicalKey zu haben. Dies ist eine ziemlich einfache Antwort auf ein komplexes Problem, obwohl es eine ist, die in einer Reihe von Fällen ausreicht und zumindest besser ist, als überhaupt keinen Primärschlüssel zu haben.(Anmerkung des Autors:Ich konnte diesen „vorherigen Autor“ bei der Suche nach diesen beiden Sätzen bei Google nicht finden.)
Außerdem wird ein Link zu einem zusammenfassenden Artikel über die Hauptargumente auf beiden Seiten der Debatte zwischen Autoschlüsseln und Domänenschlüsseln bereitgestellt.
Dagegen fand ich die Tipps „Betriebssystem, Daten und Anmeldung auf unterschiedliche physikalische Platten aufteilen“ und „RAID verwenden“ etwas obskur. Verstehen Sie mich nicht falsch – das ist unter Umständen ein guter Ratschlag, aber ich würde ihn nicht in meine Top-20-Liste aufnehmen.
Tipps zum Datenbankdesign
von Wise Coders
Diese Sammlung enthält einige einzigartige und interessante Tipps, wie z. B. die Empfehlung, Transaktionen so schnell wie möglich abzuschließen.
Ich stimme jedoch nicht allen Designtipps hier vollständig zu. Zum Beispiel:
Nehmen Sie ein Feld „Status“ mit den Werten „Aktiv“, „Inaktiv“ und „Inaktiv“ an. Sie können den Wert als vollständigen Namen speichern, dies kann jedoch ineffizient sein. Das Speichern einer Aufzählung oder eines Zeichens (1) mit möglichen Werten wie „a“, „i“, „d“ verbraucht beispielsweise weniger Speicherplatz in der Datenbank.Dies ist, gelinde gesagt, umstritten – andere Quellen raten davon ab, solche „Geheimcodes“ zu verwenden. Verwenden Sie stattdessen eine separate Tabelle, um diese Statuscodes zu speichern.
Darüber hinaus sind die mit Leistungshinweisen verbundenen Statistiken fragwürdig, und der Artikel enthält keine Beispiele.
Positiv anzumerken ist, dass dies eine schöne kurze Liste von Tipps ist, die fortgeschrittenen Datenbankmodellierern zugänglich sein sollten.
Ressourcen für angehende Datenbankdesigner
Sehen wir uns nun einige Artikel für diejenigen an, die gerade erst mit dem Datenbankdesign beginnen.
Die Grundlagen eines guten Datenbankdesigns in der Webentwicklung
von Kayla Knight | Onextrapixel.com | 17. März 2011
Hier werden wir etwas fortgeschrittener, mit Ratschlägen, die von der Funktionalität bis hin zu Modellierungswerkzeugen reichen.
Ms. Knight führt uns durch eine Einführung in das Datenbankdesign. Ihr Artikel ist interessant, weil er Datenbanken für die Webentwicklung betont. Trotzdem sind ihre Punkte ziemlich universell und können in vielen Situationen auf das Datenbankdesign angewendet werden.
Der Artikel beginnt damit, dass wir gebeten werden, umfassend über die Funktionalität nachzudenken, nicht nur über die Datenbank:
Denken Sie außerhalb der Datenbank. Versuchen Sie, darüber nachzudenken, was die Website tun muss. Wenn beispielsweise eine Mitglieder-Website benötigt wird, könnte der erste Instinkt darin bestehen, an alle Daten zu denken, die jeder Benutzer speichern muss. Vergiss es, das ist für später. Schreiben Sie lieber auf, dass Benutzer und ihre Informationen in der Datenbank gespeichert werden müssen, und was noch? Was müssen diese Mitglieder auf der Website tun? Werden sie Beiträge veröffentlichen, Dateien oder Fotos hochladen oder Nachrichten senden? Dann braucht die Datenbank einen Platz für Dateien/Fotos, Posts und Nachrichten.Von dort aus führt Frau Knight den Leser in Datenbank-Design-Tools und die Schritte, die mit dem Prozess verbunden sind. Ihr Artikel enthält Beispiele und Links zu anderen Ressourcen.
Ich denke, dass dieser Artikel eine großartige Einführung für angehende Datenbankdesigner wäre, und er sollte gut mit den Geek Girl's funktionieren Serie.
Erkunden von Tipps zum Datenbankdesign
von Doug Lowe | Für Dummies
Mr. Lowes „Dummies“-Liste ist eine breite Reihe grundlegender Designtipps. Sie können viele davon an anderer Stelle finden, aber es ist nützlich, sie an einem Ort zu haben. Sie werden nichts Einzigartiges oder höchst Kontroverses finden, außer einer Empfehlung, gespeicherte Prozeduren zu verwenden. Ich stelle diese starke Aussage immer in Frage, da ich mir große Sorgen um die Portierbarkeit von Datenmodellen für mehrere DBM-Systeme mache.
Hier ist einer von Mr. Lowes vernünftigen Tipps:
Vermeiden Sie Felder mit Namen wie „CustomerType“, bei denen der Wert des Felds eine von mehreren Konstanten ist, die an keiner anderen Stelle in der Datenbank definiert sind, z. B. „R“ für „Retail“ oder „W“ für „Wholesale“. Möglicherweise haben Sie heute nur diese beiden Kundentypen, aber die Anforderungen der Anwendung können sich in Zukunft ändern und einen dritten Kundentyp erfordern.Diese Empfehlungen sind am besten geeignet, wenn Sie mit SQL Server arbeiten.
Fünf einfache Tipps zum Datenbankdesign
von Lamont Adams | TechRepublic | 25. Juni 2001
Das Schlüsselwort für diese Ressource ist „einfach“. Sie finden diese Informationen mit weiteren Erläuterungen und Beispielen in anderen Artikeln.
Allerdings ist der Rat von Herrn Adams, „die Schlüssel des Benutzers wegzunehmen“, ein interessanter Punkt, der an anderen Stellen selten erwähnt wird. Er fährt fort:
Berücksichtigen Sie bei der Entscheidung, welches Feld oder welche Felder als Schlüssel in einer Tabelle verwendet werden sollen, immer die Felder, die Benutzer bearbeiten werden. Es ist normalerweise keine gute Idee, ein vom Benutzer bearbeitbares Feld als Schlüssel auszuwählen.Herr Adams meint damit, dass Sie die potenzielle Anforderung des Benutzers, Felder zu bearbeiten, berücksichtigen sollten, wenn Sie entscheiden, welche Felder als Schlüssel verwendet werden sollen. Ich hätte mir mehr Erklärungen zu Alternativen wie synthetischen/generierten Schlüsseln gewünscht, aber das Konzept ist gut.
Ich war mit dem letzten Punkt nicht einverstanden. Er empfiehlt einen „Fudge-Faktor“ für jede Tabelle, die Sie entwerfen:
Nichts ist schlimmer, als zu entdecken oder darüber informiert zu werden, dass Ihrer „fertigen“ Datenbank ein Feld für eine entscheidende Information fehlt. In einem Unternehmen, für das ich arbeitete, kam dies so häufig vor, dass wir anfingen, „Datenbanken einfrieren“ als „Datenbank-Slushes“ zu bezeichnen.Meiner Meinung nach bedeutet dies im Grunde „ein paar zusätzliche Textfelder am Ende hinzuzufügen“. Dies scheint einigen anderen Tipps von Herrn Adams zu widersprechen, insbesondere denen zum Verständnis der Geschäftsanforderungen und zur Verwendung aussagekräftiger Namen. Diese zusätzlichen Fudge-Felder würden einfach so etwas wie „extra1“ oder „extra2“ heißen. Was ist ihr Geschäftsbedarf? Und wie sind diese aussagekräftigen Namen? Obwohl ich die meisten seiner Designtipps mag, halte ich mich nicht an diesen „Fudge-Faktor“.
Datenbankdesign:Lobende Erwähnungen
Natürlich gibt es auch andere Artikel, die Tipps und Best Practices für das Datenbankdesign beschreiben. Weiteres Material finden Sie unter den folgenden Links:
Relationales Datenbankdesign:Eine Einführung in Best Practices | von Digital Ethos | 24. Dezember 2012
Best Practices für das Entwerfen von Datenbankschemas (Anfänger) | von Jim Murphy | 28. März 2011
IT Best Practices:Datenbankdesign | von der University of Nebraska-Lincoln
Online-Datenbankdesign-Ressourcen:Wohin würden Sie gehen?
Wie bereits erwähnt, ist diese Liste definitiv nicht als erschöpfende Untersuchung aller Datenbankdesign-Artikel im Internet gedacht. Vielmehr haben wir mehrere Artikel identifiziert, die wir für nützlich halten oder die einen bestimmten Schwerpunkt haben, den Sie möglicherweise hilfreich finden.
Bitte zögern Sie nicht, weitere Artikel zu empfehlen.