Die Leute fragen sich, ob sie ihr Bestes tun sollten, um Ausnahmen zu verhindern, oder sie einfach dem System überlassen sollten. Ich habe mehrere Diskussionen gesehen, in denen Leute darüber diskutierten, ob sie alles tun sollten, um eine Ausnahme zu verhindern, weil die Fehlerbehandlung "teuer" ist. Es besteht kein Zweifel, dass die Fehlerbehandlung nicht kostenlos ist, aber ich würde voraussagen, dass eine Einschränkungsverletzung mindestens so effizient ist, wie zuerst nach einer möglichen Verletzung zu suchen. Dies kann beispielsweise bei einer Schlüsselverletzung anders sein als bei einer statischen Beschränkungsverletzung, aber in diesem Beitrag werde ich mich auf erstere konzentrieren.
Die primären Ansätze, mit denen Menschen mit Ausnahmen umgehen, sind:
- Überlassen Sie es einfach der Engine, und lassen Sie alle Ausnahmen an den Aufrufer zurücksenden.
- Verwenden Sie
BEGIN TRANSACTIONundROLLBACKwenn@@ERROR <> 0. - Verwenden Sie
TRY/CATCHmitROLLBACKimCATCHBlock (SQL Server 2005+).
Und viele gehen davon aus, dass sie zuerst prüfen sollten, ob sie den Verstoß begehen werden, da es sauberer erscheint, das Duplikat selbst zu handhaben, als die Engine dazu zu zwingen. Meine Theorie ist, dass Sie vertrauen, aber überprüfen sollten; Betrachten Sie beispielsweise diesen Ansatz (meistens Pseudocode):
IF NOT EXISTS ([row that would incur a violation])
BEGIN
BEGIN TRY
BEGIN TRANSACTION;
INSERT ()...
COMMIT TRANSACTION;
END TRY
BEGIN CATCH
-- well, we incurred a violation anyway;
-- I guess a new row was inserted or
-- updated since we performed the check
ROLLBACK TRANSACTION;
END CATCH
END
Wir wissen, dass der IF NOT EXISTS check garantiert nicht, dass nicht jemand anderes die Zeile eingefügt hat, wenn wir zu INSERT kommen (es sei denn, wir platzieren aggressive Sperren auf der Tabelle und/oder verwenden SERIALIZABLE ), aber die äußere Überprüfung verhindert, dass wir versuchen, einen Fehler zu begehen und dann einen Rollback durchführen müssen. Wir halten uns aus dem gesamten TRY/CATCH heraus Struktur, wenn wir bereits wissen, dass die INSERT wird fehlschlagen, und es wäre logisch anzunehmen, dass dies – zumindest in einigen Fällen – effizienter ist als die Eingabe von TRY/CATCH unbedingt strukturieren. Dies macht in einem einzigen INSERT wenig Sinn Szenario, aber stellen Sie sich einen Fall vor, in dem in diesem TRY mehr passiert blockieren (und mehr potenzielle Verstöße, die Sie im Voraus überprüfen könnten, was bedeutet, dass Sie möglicherweise noch mehr Arbeit ausführen und dann zurücksetzen müssen, falls ein späterer Verstoß auftritt).
Nun wäre es interessant zu sehen, was passieren würde, wenn Sie eine nicht standardmäßige Isolationsstufe verwenden würden (etwas, das ich in einem zukünftigen Beitrag behandeln werde), insbesondere bei Parallelität. Für diesen Beitrag wollte ich jedoch langsam anfangen und diese Aspekte mit einem einzelnen Benutzer testen. Ich habe eine Tabelle namens dbo.[Objects] erstellt , eine sehr vereinfachte Tabelle:
CREATE TABLE dbo.[Objects] ( ObjectID INT IDENTITY(1,1), Name NVARCHAR(255) PRIMARY KEY ); GO
Ich wollte diese Tabelle mit 100.000 Zeilen mit Beispieldaten füllen. Um die Werte in der Namensspalte eindeutig zu machen (da der PK die Einschränkung ist, die ich verletzen wollte), habe ich eine Hilfsfunktion erstellt, die eine Anzahl von Zeilen und eine Mindestzeichenfolge akzeptiert. Die minimale Zeichenkette würde verwendet, um sicherzustellen, dass entweder (a) der Satz über dem Maximalwert in der Objekttabelle begann oder (b) der Satz beim Minimalwert in der Objekttabelle begann. (Ich werde diese manuell während der Tests spezifizieren, verifiziert einfach durch Inspizieren der Daten, obwohl ich diese Überprüfung wahrscheinlich in die Funktion hätte einbauen können.)
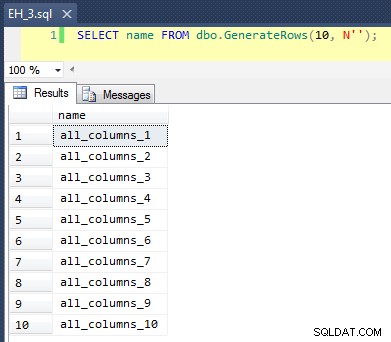
CREATE FUNCTION dbo.GenerateRows(@n INT, @minString NVARCHAR(32)) RETURNS TABLE AS RETURN ( SELECT TOP (@n) name = name + '_' + RTRIM(rn) FROM ( SELECT a.name, rn = ROW_NUMBER() OVER (PARTITION BY a.name ORDER BY a.name) FROM sys.all_objects AS a CROSS JOIN sys.all_objects AS b WHERE a.name >= @minString AND b.name >= @minString ) AS x ); GO
Dies wendet einen CROSS JOIN an von sys.all_objects auf sich selbst, wobei an jeden Namen eine eindeutige row_number angehängt wird, sodass die ersten 10 Ergebnisse so aussehen würden:
Die Tabelle mit 100.000 Zeilen zu füllen war einfach:
INSERT dbo.[Objects](name) SELECT name FROM dbo.GenerateRows(100000, N'') ORDER BY name; GO
Da wir nun neue eindeutige Werte in die Tabelle einfügen werden, habe ich eine Prozedur erstellt, um am Anfang und am Ende jedes Tests eine Bereinigung durchzuführen – zusätzlich zum Löschen aller neu hinzugefügten Zeilen wird auch aufgeräumt Cache und Puffer. Nicht etwas, das Sie natürlich in eine Prozedur auf Ihrem Produktionssystem codieren möchten, aber ganz gut für lokale Leistungstests.
CREATE PROCEDURE dbo.EH_Cleanup -- P.S. "EH" stands for Error Handling, not "Eh?" AS BEGIN SET NOCOUNT ON; DELETE dbo.[Objects] WHERE ObjectID > 100000; DBCC FREEPROCCACHE; DBCC DROPCLEANBUFFERS; END GO
Ich habe auch eine Protokolltabelle erstellt, um die Start- und Endzeiten für jeden Test zu verfolgen:
CREATE TABLE dbo.RunTimeLog ( LogID INT IDENTITY(1,1), Spid INT, InsertType VARCHAR(255), ErrorHandlingMethod VARCHAR(255), StartDate DATETIME2(7) NOT NULL DEFAULT SYSUTCDATETIME(), EndDate DATETIME2(7) ); GO
Schließlich verarbeitet die gespeicherte Testprozedur eine Vielzahl von Dingen. Wir haben drei verschiedene Fehlerbehandlungsmethoden, wie oben beschrieben:„JustInsert“, „Rollback“ und „TryCatch“; Wir haben auch drei verschiedene Einfügungstypen:(1) alle Einfügungen sind erfolgreich (alle Zeilen sind eindeutig), (2) alle Einfügungen schlagen fehl (alle Zeilen sind Duplikate) und (3) halbe Einfügungen sind erfolgreich (die Hälfte der Zeilen ist eindeutig und die Hälfte die Zeilen sind Duplikate). Damit verbunden sind zwei unterschiedliche Ansätze:Überprüfen Sie die Verletzung, bevor Sie die Einfügung versuchen, oder fahren Sie einfach fort und lassen Sie die Engine feststellen, ob sie gültig ist. Ich dachte, dies würde einen guten Vergleich der verschiedenen Fehlerbehandlungstechniken in Kombination mit unterschiedlichen Wahrscheinlichkeiten von Kollisionen ermöglichen, um zu sehen, ob ein hoher oder niedriger Kollisionsprozentsatz die Ergebnisse erheblich beeinflussen würde.
Für diese Tests habe ich 40.000 Zeilen als Gesamtzahl der Einfügeversuche ausgewählt, und in der Prozedur führe ich eine Vereinigung von 20.000 eindeutigen oder nicht eindeutigen Zeilen mit 20.000 anderen eindeutigen oder nicht eindeutigen Zeilen durch. Sie können sehen, dass ich die Cutoff-Strings in der Prozedur fest codiert habe; Bitte beachten Sie, dass diese Unterbrechungen auf Ihrem System mit ziemlicher Sicherheit an einer anderen Stelle auftreten werden.
CREATE PROCEDURE dbo.EH_Insert @ErrorHandlingMethod VARCHAR(255), @InsertType VARCHAR(255), @RowSplit INT = 20000 AS BEGIN SET NOCOUNT ON; -- clean up any new rows and drop buffers/clear proc cache EXEC dbo.EH_Cleanup; DECLARE @CutoffString1 NVARCHAR(255), @CutoffString2 NVARCHAR(255), @Name NVARCHAR(255), @Continue BIT = 1, @LogID INT; -- generate a new log entry INSERT dbo.RunTimeLog(Spid, InsertType, ErrorHandlingMethod) SELECT @@SPID, @InsertType, @ErrorHandlingMethod; SET @LogID = SCOPE_IDENTITY(); -- if we want everything to succeed, we need a set of data -- that has 40,000 rows that are all unique. So union two -- sets that are each >= 20,000 rows apart, and don't -- already exist in the base table: IF @InsertType = 'AllSuccess' SELECT @CutoffString1 = N'database_audit_specifications_1000', @CutoffString2 = N'dm_clr_properties_1398'; -- if we want them all to fail, then it's easy, we can just -- union two sets that start at the same place as the initial -- population: IF @InsertType = 'AllFail' SELECT @CutoffString1 = N'', @CutoffString2 = N''; -- and if we want half to succeed, we need 20,000 unique -- values, and 20,000 duplicates: IF @InsertType = 'HalfSuccess' SELECT @CutoffString1 = N'database_audit_specifications_1000', @CutoffString2 = N''; DECLARE c CURSOR LOCAL STATIC FORWARD_ONLY READ_ONLY FOR SELECT name FROM dbo.GenerateRows(@RowSplit, @CutoffString1) UNION ALL SELECT name FROM dbo.GenerateRows(@RowSplit, @CutoffString2); OPEN c; FETCH NEXT FROM c INTO @Name; WHILE @@FETCH_STATUS = 0 BEGIN SET @Continue = 1; -- let's only enter the primary code block if we -- have to check and the check comes back empty -- (in other words, don't try at all if we have -- a duplicate, but only check for a duplicate -- in certain cases: IF @ErrorHandlingMethod LIKE 'Check%' BEGIN IF EXISTS (SELECT 1 FROM dbo.[Objects] WHERE Name = @Name) SET @Continue = 0; END IF @Continue = 1 BEGIN -- just let the engine catch IF @ErrorHandlingMethod LIKE '%Insert' BEGIN INSERT dbo.[Objects](name) SELECT @name; END -- begin a transaction, but let the engine catch IF @ErrorHandlingMethod LIKE '%Rollback' BEGIN BEGIN TRANSACTION; INSERT dbo.[Objects](name) SELECT @name; IF @@ERROR <> 0 BEGIN ROLLBACK TRANSACTION; END ELSE BEGIN COMMIT TRANSACTION; END END -- use try / catch IF @ErrorHandlingMethod LIKE '%TryCatch' BEGIN BEGIN TRY BEGIN TRANSACTION; INSERT dbo.[Objects](name) SELECT @Name; COMMIT TRANSACTION; END TRY BEGIN CATCH ROLLBACK TRANSACTION; END CATCH END END FETCH NEXT FROM c INTO @Name; END CLOSE c; DEALLOCATE c; -- update the log entry UPDATE dbo.RunTimeLog SET EndDate = SYSUTCDATETIME() WHERE LogID = @LogID; -- clean up any new rows and drop buffers/clear proc cache EXEC dbo.EH_Cleanup; END GO
Jetzt können wir diese Prozedur mit verschiedenen Argumenten aufrufen, um das unterschiedliche Verhalten zu erhalten, nach dem wir suchen, indem wir versuchen, 40.000 Werte einzufügen (und natürlich wissen, wie viele in jedem Fall erfolgreich sein oder fehlschlagen sollten). Für jede 'Fehlerbehandlungsmethode' (versuchen Sie einfach die Einfügung, verwenden Sie begin tran/rollback oder try/catch) und jeden Einfügungstyp (alle erfolgreich, halb erfolgreich und keine erfolgreich), kombiniert mit der Frage, ob auf die Verletzung geprüft werden soll oder nicht Erstens gibt uns dies 18 Kombinationen:
EXEC dbo.EH_Insert 'JustInsert', 'AllSuccess', 20000; EXEC dbo.EH_Insert 'JustInsert', 'HalfSuccess', 20000; EXEC dbo.EH_Insert 'JustInsert', 'AllFail', 20000; EXEC dbo.EH_Insert 'JustTryCatch', 'AllSuccess', 20000; EXEC dbo.EH_Insert 'JustTryCatch', 'HalfSuccess', 20000; EXEC dbo.EH_Insert 'JustTryCatch', 'AllFail', 20000; EXEC dbo.EH_Insert 'JustRollback', 'AllSuccess', 20000; EXEC dbo.EH_Insert 'JustRollback', 'HalfSuccess', 20000; EXEC dbo.EH_Insert 'JustRollback', 'AllFail', 20000; EXEC dbo.EH_Insert 'CheckInsert', 'AllSuccess', 20000; EXEC dbo.EH_Insert 'CheckInsert', 'HalfSuccess', 20000; EXEC dbo.EH_Insert 'CheckInsert', 'AllFail', 20000; EXEC dbo.EH_Insert 'CheckTryCatch', 'AllSuccess', 20000; EXEC dbo.EH_Insert 'CheckTryCatch', 'HalfSuccess', 20000; EXEC dbo.EH_Insert 'CheckTryCatch', 'AllFail', 20000; EXEC dbo.EH_Insert 'CheckRollback', 'AllSuccess', 20000; EXEC dbo.EH_Insert 'CheckRollback', 'HalfSuccess', 20000; EXEC dbo.EH_Insert 'CheckRollback', 'AllFail', 20000;
Nachdem wir dies ausgeführt haben (es dauert etwa 8 Minuten auf meinem System), haben wir einige Ergebnisse in unserem Protokoll. Ich habe den gesamten Stapel fünf Mal durchlaufen lassen, um sicherzustellen, dass wir anständige Durchschnittswerte erhalten, und um Anomalien auszugleichen. Hier sind die Ergebnisse:
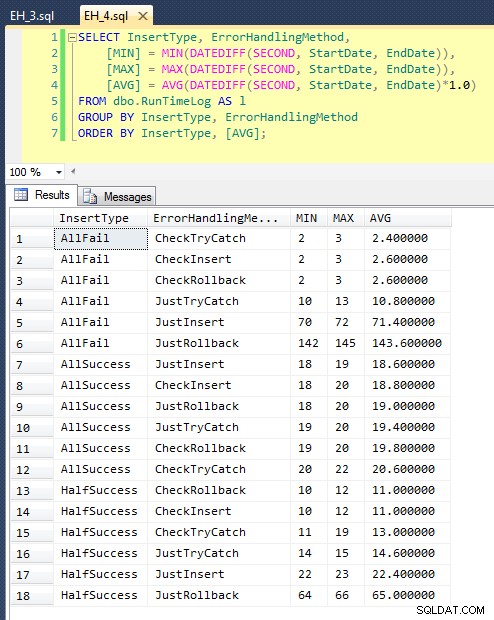
Das Diagramm, das alle Dauern auf einmal darstellt, zeigt einige ernsthafte Ausreißer:
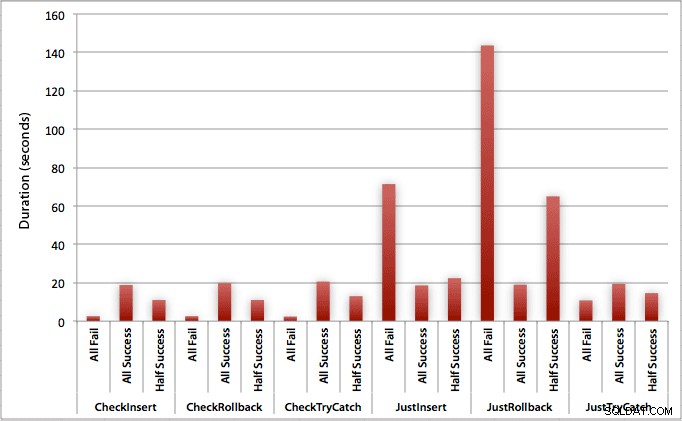
Sie können sehen, dass in Fällen, in denen wir eine hohe Fehlerrate erwarten (in diesem Test 100 %), das Starten einer Transaktion und das Zurücksetzen bei weitem der unattraktivste Ansatz ist (3,59 Millisekunden pro Versuch), während Sie die Engine einfach anheben lassen ein Fehler ist etwa halb so schlimm (1,785 Millisekunden pro Versuch). Der nächste schlechteste Performer war der Fall, in dem wir eine Transaktion beginnen und sie dann zurücksetzen, in einem Szenario, in dem wir davon ausgehen, dass etwa die Hälfte der Versuche fehlschlägt (durchschnittlich 1,625 Millisekunden pro Versuch). Die 9 Fälle auf der linken Seite des Diagramms, in denen wir zuerst nach dem Verstoß suchen, wagten sich nicht über 0,515 Millisekunden pro Versuch.
Allerdings verdeutlichen die einzelnen Diagramme für jedes Szenario (hoher Prozentsatz an Erfolg, hoher Prozentsatz an Fehlern und 50-50) die Auswirkungen jeder Methode.
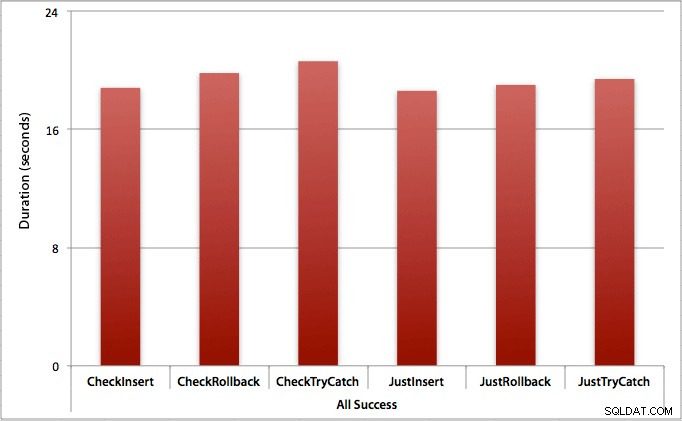
Wo alle Einfügungen erfolgreich sind
In diesem Fall sehen wir, dass der Aufwand für die Überprüfung auf die Verletzung zunächst vernachlässigbar ist, mit einem durchschnittlichen Unterschied von 0,7 Sekunden im gesamten Stapel (oder 125 Mikrosekunden pro Einfügeversuch):
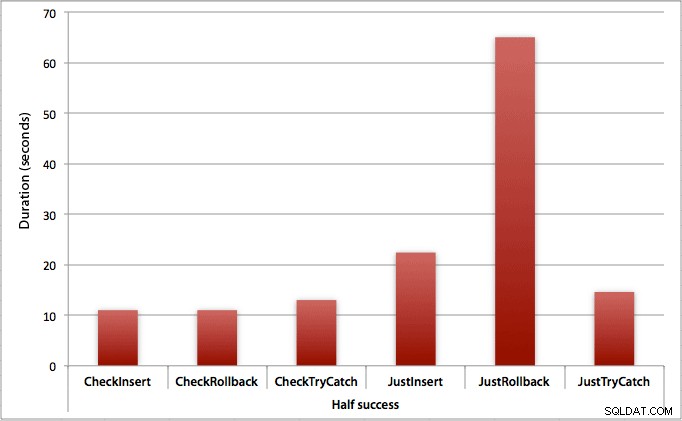
Wo nur die Hälfte der Einfügungen gelingt
Wenn die Hälfte der Einfügungen fehlschlägt, sehen wir einen großen Sprung in der Dauer für die Einfügungs-/Rollback-Methoden. Das Szenario, in dem wir eine Transaktion starten und zurücksetzen, ist im gesamten Batch etwa 6-mal langsamer als bei der ersten Überprüfung (1,625 Millisekunden pro Versuch gegenüber 0,275 Millisekunden pro Versuch). Sogar die TRY/CATCH-Methode ist 11 % schneller, wenn wir zuerst prüfen:
Wo alle Einfügungen versagen
Wie Sie vielleicht erwarten, zeigt dies die deutlichsten Auswirkungen der Fehlerbehandlung und die offensichtlichsten Vorteile der ersten Überprüfung. Die Rollback-Methode ist in diesem Fall fast 70-mal langsamer, wenn wir nicht prüfen, verglichen mit der Überprüfung (3,59 Millisekunden pro Versuch gegenüber 0,065 Millisekunden pro Versuch):
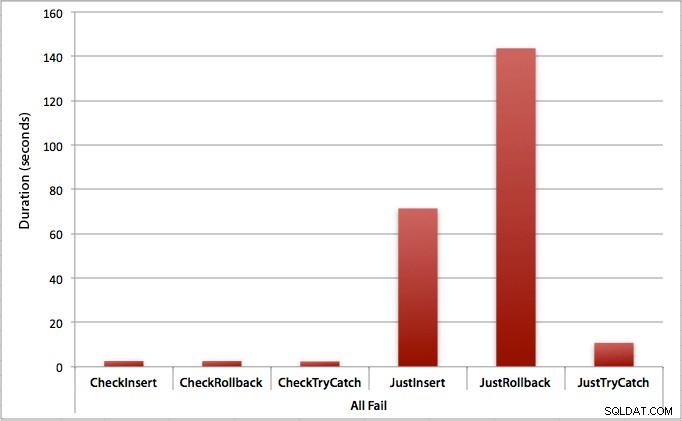
Was sagt uns das? Wenn wir glauben, dass wir eine hohe Ausfallrate haben werden, oder keine Ahnung haben, wie hoch unsere potenzielle Ausfallrate sein wird, dann wird es sich enorm lohnen, zuerst zu prüfen, um Verstöße in der Engine zu vermeiden. Selbst in dem Fall, dass wir jedes Mal eine erfolgreiche Beilage haben, sind die Kosten für die erste Überprüfung gering und durch die potenziellen Kosten der späteren Fehlerbehandlung leicht zu rechtfertigen (es sei denn, Ihre erwartete Fehlerrate beträgt genau 0 %).
Daher denke ich, dass ich vorerst bei meiner Theorie bleiben werde, dass es in einfachen Fällen sinnvoll ist, nach einer möglichen Verletzung zu suchen, bevor Sie SQL Server sagen, dass er trotzdem fortfahren und einfügen soll. In einem zukünftigen Beitrag werde ich mich mit den Auswirkungen verschiedener Isolationsstufen, Parallelität und vielleicht sogar einiger anderer Fehlerbehandlungstechniken auf die Leistung befassen.
[Nebenbei bemerkt habe ich im Februar eine gekürzte Version dieses Beitrags als Tipp für mssqltips.com geschrieben.]