Die Verwaltung einer PostgreSQL-Installation umfasst die Überprüfung und Kontrolle einer Vielzahl von Aspekten des Software-/Infrastruktur-Stacks, auf dem PostgreSQL ausgeführt wird. Dies muss umfassen:
- Anwendungsoptimierung bezüglich Datenbanknutzung/Transaktionen/Verbindungen
- Datenbankcode (Abfragen, Funktionen)
- Datenbanksystem (Performance, HA, Backups)
- Hardware/Infrastruktur (Festplatten, CPU/Speicher)
Der PostgreSQL-Kern stellt die Datenbankschicht bereit, auf der wir darauf vertrauen, dass unsere Daten gespeichert, verarbeitet und bereitgestellt werden. Es bietet auch die gesamte Technologie für ein wirklich modernes, effizientes, zuverlässiges und sicheres System. Aber oft ist diese Technologie nicht als gebrauchsfertiges, verfeinertes Produkt der Business-/Enterprise-Klasse in der zentralen PostgreSQL-Distribution verfügbar. Stattdessen gibt es viele Produkte/Lösungen, entweder von der PostgreSQL-Community oder kommerzielle Angebote, die diese Anforderungen erfüllen. Diese Lösungen kommen entweder als benutzerfreundliche Verfeinerungen der Kerntechnologien oder Erweiterungen der Kerntechnologien oder sogar als Integration zwischen PostgreSQL-Komponenten und anderen Komponenten des Systems. In unserem vorherigen Blog mit dem Titel Zehn Tipps für den Produktionsstart mit PostgreSQL haben wir uns mit einigen dieser Tools befasst, die bei der Verwaltung einer PostgreSQL-Installation in der Produktion helfen können. In diesem Blog befassen wir uns ausführlicher mit den Aspekten, die bei der Verwaltung einer PostgreSQL-Installation in der Produktion berücksichtigt werden müssen, und mit den am häufigsten verwendeten Tools für diesen Zweck. Wir werden die folgenden Themen behandeln:
- Bereitstellung
- Verwaltung
- Skalierung
- Überwachung
Bereitstellung
Früher haben die Leute PostgreSQL von Hand heruntergeladen und kompiliert und dann die Laufzeitparameter und die Benutzerzugriffskontrolle konfiguriert. Es gibt immer noch einige Fälle, in denen dies erforderlich sein könnte, aber als die Systeme ausgereift und zu wachsen begannen, entstand der Bedarf an standardisierten Methoden zur Bereitstellung und Verwaltung von Postgresql. Die meisten Betriebssysteme bieten Pakete zum Installieren, Bereitstellen und Verwalten von PostgreSQL-Clustern. Debian hat sein eigenes Systemlayout standardisiert, das viele Postgresql-Versionen und viele Cluster pro Version gleichzeitig unterstützt. Das postgresql-common-Debian-Paket stellt die erforderlichen Tools bereit. Um beispielsweise einen neuen Cluster (namens i18n_cluster) für PostgreSQL Version 10 in Debian zu erstellen, können wir dies tun, indem wir die folgenden Befehle eingeben:
$ pg_createcluster 10 i18n_cluster -- --encoding=UTF-8 --data-checksumsAktualisieren Sie dann systemd:
$ sudo systemctl daemon-reloadund schließlich den neuen Cluster starten und verwenden:
$ sudo systemctl start example@sqldat.com_cluster.service
$ createdb -p 5434 somei18ndb(Beachten Sie, dass Debian verschiedene Cluster durch die Verwendung verschiedener Ports 5432, 5433 usw. handhabt)
Da der Bedarf an stärker automatisierten und massiven Bereitstellungen wächst, verwenden immer mehr Installationen Automatisierungstools wie Ansible, Chef und Puppet. Neben der Automatisierung und Reproduzierbarkeit von Bereitstellungen sind Automatisierungstools großartig, da sie eine gute Möglichkeit darstellen, die Bereitstellung und Konfiguration eines Clusters zu dokumentieren. Andererseits hat sich die Automatisierung zu einem großen eigenen Bereich entwickelt, der qualifizierte Mitarbeiter zum Schreiben, Verwalten und Ausführen automatisierter Skripte erfordert. Weitere Informationen zur PostgreSQL-Bereitstellung finden Sie in diesem Blog:Become a PostgreSQL DBA:Provisioning and Deployment.
Verwaltung
Die Verwaltung eines Live-Systems umfasst Aufgaben wie:Planung von Backups und Überwachung ihres Status, Notfallwiederherstellung, Konfigurationsmanagement, Hochverfügbarkeitsmanagement und automatisches Failover-Handling. Das Sichern eines Postgresql-Clusters kann auf verschiedene Arten erfolgen. Low-Level-Tools:
- herkömmliches pg_dump (logisches Backup)
- Sicherungen auf Dateisystemebene (physische Sicherung)
- pg_basebackup (physisches Backup)
Oder höhere Ebene:
- Barmann
- PgBackRest
Jede dieser Möglichkeiten deckt unterschiedliche Anwendungsfälle und Wiederherstellungsszenarien ab und ist unterschiedlich komplex. PostgreSQL-Backup ist eng mit den Begriffen PITR, WAL-Archivierung und Replikation verbunden. Im Laufe der Jahre hat sich das Erstellen, Testen und schließlich (Daumen drücken!) Verwenden von Backups mit PostgreSQL zu einer komplexen Aufgabe entwickelt. Einen schönen Überblick über die Backup-Lösungen für PostgreSQL findet man in diesem Blog:Top Backup Tools for PostgreSQL.
In Bezug auf Hochverfügbarkeit und automatisches Failover ist das absolute Minimum, das eine Installation haben muss, um dies zu implementieren, Folgendes:
- Eine funktionierende Grundschule
- Ein Hot-Standby, das WAL-Streaming vom primären Server akzeptiert
- Im Falle eines fehlgeschlagenen Primärservers eine Methode, um dem Primärserver mitzuteilen, dass er nicht mehr der Primärserver ist (manchmal als STONITH bezeichnet)
- Ein Heartbeat-Mechanismus, um die Konnektivität zwischen den beiden Servern und den Zustand des Primärservers zu prüfen
- Eine Methode, um das Failover durchzuführen (z. B. über pg_ctl promote oder trigger file)
- Ein automatisiertes Verfahren zur Wiederherstellung der alten Primärdatenbank als neue Standby-Instanz:Sobald eine Unterbrechung oder ein Ausfall auf der Primärdatenbank erkannt wird, muss eine Standby-Instanz als neue Primärdatenbank heraufgestuft werden. Die alte primäre ist nicht mehr gültig oder verwendbar. Das System muss also eine Möglichkeit haben, diesen Zustand zwischen dem Failover und der Neuerstellung des alten primären Servers als neuen Standby-Server zu handhaben. Dieser Zustand wird degenerierter Zustand genannt, und PostgreSQL stellt ein Tool namens pg_rewind bereit, um den Prozess zu beschleunigen, die alte Primärdatenbank von der neuen Primärdatenbank wieder in einen synchronisierbaren Zustand zu versetzen.
- Eine Methode für bedarfsgesteuerte/geplante Umschaltungen
Ein weit verbreitetes Tool, das alle oben genannten Aufgaben übernimmt, ist Repmgr. Wir beschreiben die minimale Einrichtung, die eine erfolgreiche Umstellung ermöglicht. Wir beginnen mit einem funktionierenden primären PostgreSQL 10.4-System, das auf FreeBSD 11.1 ausgeführt wird, manuell erstellt und installiert, und repmgr 4.0, das ebenfalls manuell erstellt und für diese Version (10.4) installiert wurde. Wir werden zwei Hosts namens fbsd (192.168.1.80) und fbsdclone (192.168.1.81) mit identischen Versionen von PostgreSQL und repmgr verwenden. Auf dem primären (ursprünglich fbsd , 192.168.1.80) stellen wir sicher, dass die folgenden PostgreSQL-Parameter gesetzt sind:
max_wal_senders = 10
wal_level = 'logical'
hot_standby = on
archive_mode = 'on'
archive_command = '/usr/bin/true'
wal_keep_segments = '1000' Dann erstellen wir den repmgr-Benutzer (als Superuser) und die Datenbank:
example@sqldat.com:~ % createuser -s repmgr
example@sqldat.com:~ % createdb repmgr -O repmgrund richten Sie die hostbasierte Zugriffskontrolle in pg_hba.conf ein, indem Sie die folgenden Zeilen oben einfügen:
local replication repmgr trust
host replication repmgr 127.0.0.1/32 trust
host replication repmgr 192.168.1.0/24 trust
local repmgr repmgr trust
host repmgr repmgr 127.0.0.1/32 trust
host repmgr repmgr 192.168.1.0/24 trustWir stellen sicher, dass wir die kennwortlose Anmeldung für den Benutzer repmgr in allen Knoten des Clusters einrichten, in unserem Fall fbsd und fbsdclone, indem wir authorisierte_keys in .ssh festlegen und dann .ssh freigeben. Dann erstellen wir repmrg.conf auf der Primärseite als:
example@sqldat.com:~ % cat /etc/repmgr.conf
node_id=1
node_name=fbsd
conninfo='host=192.168.1.80 user=repmgr dbname=repmgr connect_timeout=2'
data_directory='/usr/local/var/lib/pgsql/data'Dann registrieren wir die primäre:
example@sqldat.com:~ % repmgr -f /etc/repmgr.conf primary register
NOTICE: attempting to install extension "repmgr"
NOTICE: "repmgr" extension successfully installed
NOTICE: primary node record (id: 1) registeredUnd prüfen Sie den Status des Clusters:
example@sqldat.com:~ % repmgr -f /etc/repmgr.conf cluster show
ID | Name | Role | Status | Upstream | Location | Connection string
----+------+---------+-----------+----------+----------+---------------------------------------------------------------
1 | fbsd | primary | * running | | default | host=192.168.1.80 user=repmgr dbname=repmgr connect_timeout=2Wir arbeiten nun am Standby, indem wir repmgr.conf wie folgt setzen:
example@sqldat.com:~ % cat /etc/repmgr.conf
node_id=2
node_name=fbsdclone
conninfo='host=192.168.1.81 user=repmgr dbname=repmgr connect_timeout=2'
data_directory='/usr/local/var/lib/pgsql/data'Außerdem stellen wir sicher, dass das gerade in der Zeile oben angegebene Datenverzeichnis existiert, leer ist und die richtigen Berechtigungen hat:
example@sqldat.com:~ % rm -fr data && mkdir data
example@sqldat.com:~ % chmod 700 dataWir müssen jetzt zu unserem neuen Standby klonen:
example@sqldat.com:~ % repmgr -h 192.168.1.80 -U repmgr -f /etc/repmgr.conf --force standby clone
NOTICE: destination directory "/usr/local/var/lib/pgsql/data" provided
NOTICE: starting backup (using pg_basebackup)...
HINT: this may take some time; consider using the -c/--fast-checkpoint option
NOTICE: standby clone (using pg_basebackup) complete
NOTICE: you can now start your PostgreSQL server
HINT: for example: pg_ctl -D /usr/local/var/lib/pgsql/data start
HINT: after starting the server, you need to register this standby with "repmgr standby register"Und starten Sie den Standby:
example@sqldat.com:~ % pg_ctl -D data startAn diesem Punkt sollte die Replikation wie erwartet funktionieren, überprüfen Sie dies, indem Sie pg_stat_replication (fbsd) und pg_stat_wal_receiver (fbsdclone) abfragen. Der nächste Schritt ist die Registrierung des Standby:
example@sqldat.com:~ % repmgr -f /etc/repmgr.conf standby registerJetzt können wir den Status des Clusters entweder auf dem Standly oder dem Primary abrufen und überprüfen, ob der Standby registriert ist:
example@sqldat.com:~ % repmgr -f /etc/repmgr.conf cluster show
ID | Name | Role | Status | Upstream | Location | Connection string
----+-----------+---------+-----------+----------+----------+---------------------------------------------------------------
1 | fbsd | primary | * running | | default | host=192.168.1.80 user=repmgr dbname=repmgr connect_timeout=2
2 | fbsdclone | standby | running | fbsd | default | host=192.168.1.81 user=repmgr dbname=repmgr connect_timeout=2Nehmen wir nun an, dass wir eine geplante manuelle Umschaltung durchführen möchten, um z. einige Verwaltungsarbeiten am Knoten fbsd zu erledigen. Auf dem Standby-Knoten führen wir den folgenden Befehl aus:
example@sqldat.com:~ % repmgr -f /etc/repmgr.conf standby switchover
…
NOTICE: STANDBY SWITCHOVER has completed successfullyDie Umschaltung wurde erfolgreich durchgeführt! Mal sehen, was Cluster Show gibt:
example@sqldat.com:~ % repmgr -f /etc/repmgr.conf cluster show
ID | Name | Role | Status | Upstream | Location | Connection string
----+-----------+---------+-----------+-----------+----------+---------------------------------------------------------------
1 | fbsd | standby | running | fbsdclone | default | host=192.168.1.80 user=repmgr dbname=repmgr connect_timeout=2
2 | fbsdclone | primary | * running | | default | host=192.168.1.81 user=repmgr dbname=repmgr connect_timeout=2Die beiden Server haben die Rollen getauscht! Repmgr stellt den repmgrd-Daemon bereit, der Überwachung, automatisches Failover sowie Benachrichtigungen/Warnungen bereitstellt. Durch die Kombination von repmgrd mit pgbouncer ist es möglich, eine automatische Aktualisierung der Verbindungsinformationen der Datenbank zu implementieren, wodurch ein Fencing für den ausgefallenen primären Knoten bereitgestellt wird (wodurch verhindert wird, dass der ausgefallene Knoten von der Anwendung verwendet wird) sowie eine minimale Ausfallzeit für die Anwendung bereitgestellt wird. Bei komplexeren Schemata besteht eine andere Idee darin, Keepalived mit HAProxy zusätzlich zu pgbouncer und repmgr zu kombinieren, um Folgendes zu erreichen:
- Lastenausgleich (Skalierung)
- hohe Verfügbarkeit
Beachten Sie, dass ClusterControl auch das Failover von PostgreSQL-Replikations-Setups verwaltet und HAProxy und VirtualIP integriert, um Client-Verbindungen automatisch zum funktionierenden Master umzuleiten. Weitere Informationen finden Sie in diesem Whitepaper zur PostgreSQL-Automatisierung.
Laden Sie noch heute das Whitepaper PostgreSQL-Verwaltung und -Automatisierung mit ClusterControl herunterErfahren Sie, was Sie wissen müssen, um PostgreSQL bereitzustellen, zu überwachen, zu verwalten und zu skalierenLaden Sie das Whitepaper herunterSkalierung
Ab PostgreSQL 10 (und 11) gibt es immer noch keine Möglichkeit, Multi-Master-Replikation zu haben, zumindest nicht vom Core PostgreSQL. Dies bedeutet, dass nur die ausgewählte (schreibgeschützte) Aktivität hochskaliert werden kann. Die Skalierung in PostgreSQL wird durch das Hinzufügen weiterer Hot-Standbys erreicht, wodurch mehr Ressourcen für schreibgeschützte Aktivitäten bereitgestellt werden. Mit repmgr ist es einfach, neuen Standby hinzuzufügen, wie wir zuvor über Standby-Klon gesehen haben und Standby registrieren Befehle. Hinzugefügte (oder entfernte) Standbys müssen der Konfiguration des Load-Balancers bekannt gemacht werden. HAProxy ist, wie oben im Management-Thema erwähnt, ein beliebter Load Balancer für PostgreSQL. Normalerweise ist es mit Keepalived gekoppelt, das virtuelle IP über VRRP bereitstellt. Eine schöne Übersicht über die Verwendung von HAProxy und Keepalived zusammen mit PostgreSQL finden Sie in diesem Artikel:PostgreSQL Load Balancing Using HAProxy &Keepalived.
Überwachung
Eine Übersicht darüber, was in PostgreSQL überwacht werden sollte, finden Sie in diesem Artikel:Wichtige Dinge zur Überwachung in PostgreSQL – Analysieren Ihrer Arbeitslast. Es gibt viele Tools, die System- und Postgresql-Überwachung über Plugins bereitstellen können. Einige Tools decken den Bereich der grafischen Darstellung historischer Werte ab (munin), andere Tools decken den Bereich der Überwachung von Live-Daten und der Bereitstellung von Live-Warnungen ab (nagios), während einige Tools beide Bereiche abdecken (zabbix). Eine Liste solcher Tools für PostgreSQL finden Sie hier:https://wiki.postgresql.org/wiki/Monitoring. Ein beliebtes Tool für die Offline-Überwachung (protokolldateibasiert) ist pgBadger. pgBadger ist ein Perl-Skript, das funktioniert, indem es das PostgreSQL-Protokoll analysiert (das normalerweise die Aktivität eines Tages abdeckt), Informationen extrahiert, Statistiken berechnet und schließlich eine schicke HTML-Seite erstellt, die die Ergebnisse präsentiert. pgBadger beschränkt sich nicht auf die log_line_prefix-Einstellung, es kann sich an Ihr bereits vorhandenes Format anpassen. Zum Beispiel, wenn Sie in Ihrer postgresql.conf so etwas eingestellt haben:
log_line_prefix = '%r [%p] %c %m %a %example@sqldat.com%d line:%l 'dann könnte der Befehl pgbadger zum Analysieren der Protokolldatei und zum Produzieren der Ergebnisse wie folgt aussehen:
./pgbadger --prefix='%r [%p] %c %m %a %example@sqldat.com%d line:%l ' -Z +2 -o pgBadger_$today.html $yesterdayfile.log && rm -f $yesterdayfile.logpgBadger bietet Berichte für:
- Übersichtsstatistik (hauptsächlich SQL-Traffic)
- Verbindungen (pro Sekunde, pro Datenbank/Benutzer/Host)
- Sitzungen (Anzahl, Sitzungszeiten, pro Datenbank/Benutzer/Host/Anwendung)
- Checkpoints (Puffer, Wal-Dateien, Aktivität)
- Nutzung temporärer Dateien
- Aktivität vakuumieren/analysieren (pro Tabelle, entfernte Tupel/Seiten)
- Schlösser
- Abfragen (nach Typ/Datenbank/Benutzer/Host/Anwendung, Dauer nach Benutzer)
- Top (Abfragen:am langsamsten, zeitaufwändig, häufiger, normalisiert am langsamsten)
- Ereignisse (Fehler, Warnungen, schwerwiegende Fehler usw.)
Der Bildschirm mit den Sitzungen sieht folgendermaßen aus:
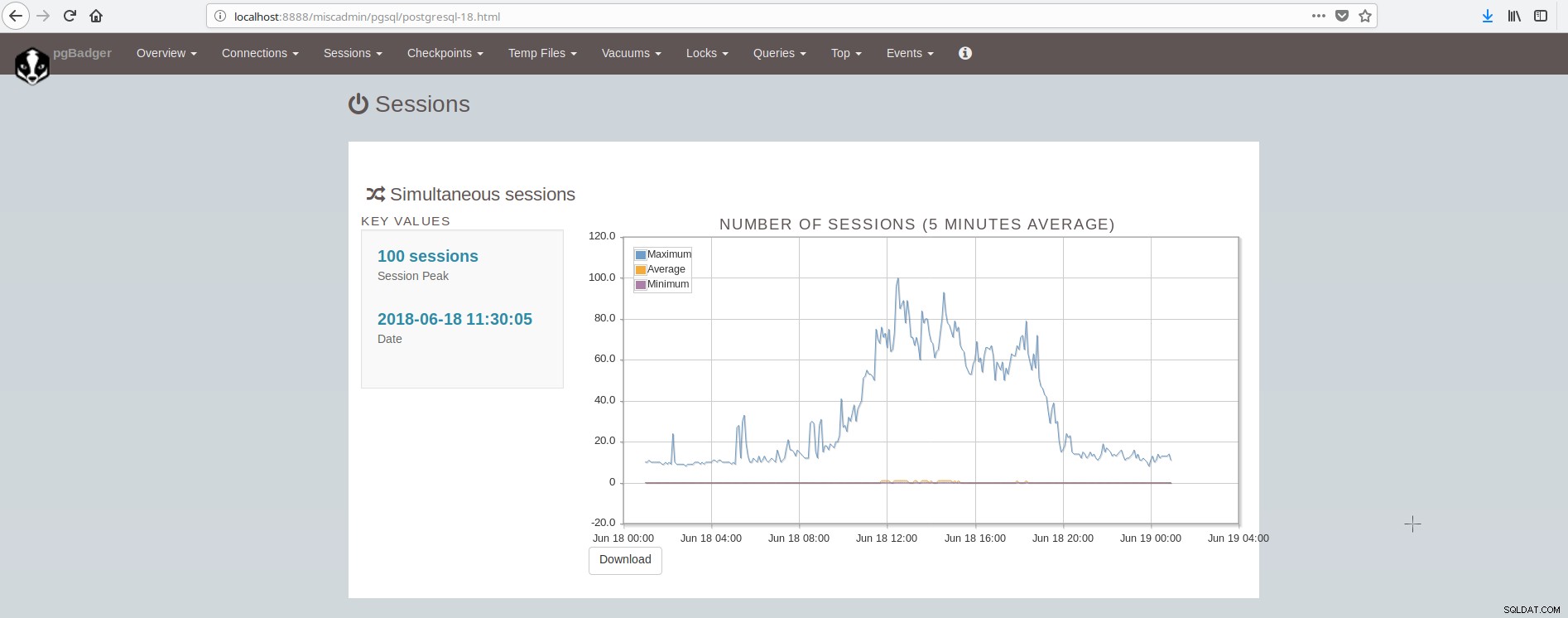
Wie wir zusammenfassen können, muss die durchschnittliche PostgreSQL-Installation viele Tools integrieren und pflegen, um eine moderne, zuverlässige und schnelle Infrastruktur zu haben, und dies ist ziemlich komplex, es sei denn, es sind große Teams an PostgreSQL und Systemadministration beteiligt. Eine gute Suite, die all das und noch mehr macht, ist ClusterControl.



