Ein häufiges Szenario in vielen Client-Server-Anwendungen besteht darin, dem Endbenutzer zu erlauben, die Sortierreihenfolge der Ergebnisse vorzugeben. Einige Leute möchten die Artikel mit den niedrigsten Preisen zuerst sehen, andere möchten die neuesten Artikel zuerst sehen und wieder andere möchten sie alphabetisch sehen. Dies ist in Transact-SQL schwierig zu erreichen, da Sie nicht einfach sagen können:
CREATE PROCEDURE dbo.SortOnSomeTable @SortColumn NVARCHAR(128) = N'key_col', @SortDirection VARCHAR(4) = 'ASC' AS BEGIN ... ORDER BY @SortColumn; -- or ... ORDER BY @SortColumn @SortDirection; END GO
Dies liegt daran, dass T-SQL keine Variablen an diesen Speicherorten zulässt. Wenn Sie nur @SortColumn verwenden, erhalten Sie:
Msg 1008, Level 16, State 1, Line xDas durch die ORDER BY-Nummer 1 identifizierte SELECT-Element enthält eine Variable als Teil des Ausdrucks, der eine Spaltenposition identifiziert. Variablen sind nur zulässig, wenn nach einem Ausdruck sortiert wird, der auf einen Spaltennamen verweist.
(Und wenn die Fehlermeldung sagt:„Ein Ausdruck, der auf einen Spaltennamen verweist“, finden Sie das vielleicht zweideutig, und ich stimme zu. Aber ich kann Ihnen versichern, dass dies nicht bedeutet, dass eine Variable ein geeigneter Ausdruck ist.)
Wenn Sie versuchen, @SortDirection anzuhängen, ist die Fehlermeldung etwas undurchsichtiger:
Nachricht 102, Ebene 15, Status 1, Zeile xFalsche Syntax in der Nähe von '@SortDirection'.
Es gibt einige Möglichkeiten, dies zu umgehen, und Ihr erster Instinkt könnte darin bestehen, dynamisches SQL zu verwenden oder den CASE-Ausdruck einzuführen. Aber wie bei den meisten Dingen gibt es Komplikationen, die Sie auf den einen oder anderen Weg zwingen können. Welche sollten Sie also verwenden? Lassen Sie uns untersuchen, wie diese Lösungen funktionieren könnten, und die Auswirkungen auf die Leistung für einige verschiedene Ansätze vergleichen.
Beispieldaten
Unter Verwendung einer Katalogansicht, die wir alle wahrscheinlich recht gut verstehen, sys.all_objects, habe ich die folgende Tabelle basierend auf einem Cross Join erstellt und die Tabelle auf 100.000 Zeilen beschränkt (ich wollte Daten, die viele Seiten füllen, aber das Abfragen hat nicht viel Zeit in Anspruch genommen und testen):
CREATE DATABASE OrderBy;
GO
USE OrderBy;
GO
SELECT TOP (100000)
key_col = ROW_NUMBER() OVER (ORDER BY s1.[object_id]), -- a BIGINT with clustered index
s1.[object_id], -- an INT without an index
name = s1.name -- an NVARCHAR with a supporting index
COLLATE SQL_Latin1_General_CP1_CI_AS,
type_desc = s1.type_desc -- an NVARCHAR(60) without an index
COLLATE SQL_Latin1_General_CP1_CI_AS,
s1.modify_date -- a datetime without an index
INTO dbo.sys_objects
FROM sys.all_objects AS s1
CROSS JOIN sys.all_objects AS s2
ORDER BY s1.[object_id]; (Der COLLATE-Trick besteht darin, dass viele Katalogansichten unterschiedliche Spalten mit unterschiedlichen Sortierungen haben, und dies stellt sicher, dass die beiden Spalten für die Zwecke dieser Demo übereinstimmen.)
Dann habe ich vor der Optimierung ein typisches geclustertes / nicht geclustertes Indexpaar erstellt, das in einer solchen Tabelle vorhanden sein könnte (ich kann object_id nicht für den Schlüssel verwenden, da der Cross Join Duplikate erstellt):
CREATE UNIQUE CLUSTERED INDEX key_col ON dbo.sys_objects(key_col); CREATE INDEX name ON dbo.sys_objects(name);
Anwendungsfälle
Wie oben erwähnt, möchten Benutzer diese Daten möglicherweise auf verschiedene Arten geordnet sehen, also lassen Sie uns einige typische Anwendungsfälle aufzeigen, die wir unterstützen (und mit Unterstützung meine ich demonstrieren) wollen:
- Sortiert nach key_col aufsteigend ** Standard, wenn es dem Benutzer egal ist
- Geordnet nach object_id (aufsteigend/absteigend)
- Nach Namen geordnet (aufsteigend/absteigend)
- Sortiert nach type_desc (aufsteigend/absteigend)
- Geordnet nach modify_date (aufsteigend/absteigend)
Wir belassen die key_col-Reihenfolge als Standard, da sie am effizientesten sein sollte, wenn der Benutzer keine Vorlieben hat; Da key_col ein willkürlicher Ersatz ist, der dem Benutzer nichts sagen sollte (und ihm möglicherweise nicht einmal angezeigt wird), gibt es keinen Grund, die umgekehrte Sortierung für diese Spalte zuzulassen.
Ansätze, die nicht funktionieren
Der häufigste Ansatz, den ich sehe, wenn jemand anfängt, dieses Problem anzugehen, besteht darin, eine Ablaufsteuerungslogik in die Abfrage einzuführen. Sie erwarten, dass sie dazu in der Lage sind:
SELECT key_col, [object_id], name, type_desc, modify_date
FROM dbo.sys_objects
ORDER BY
IF @SortColumn = 'key_col'
key_col
IF @SortColumn = 'object_id'
[object_id]
IF @SortColumn = 'name'
name
...
IF @SortDirection = 'ASC'
ASC
ELSE
DESC; Dies funktioniert offensichtlich nicht. Als nächstes sehe ich, dass CASE falsch eingeführt wird und eine ähnliche Syntax verwendet:
SELECT key_col, [object_id], name, type_desc, modify_date
FROM dbo.sys_objects
ORDER BY CASE @SortColumn
WHEN 'key_col' THEN key_col
WHEN 'object_id' THEN [object_id]
WHEN 'name' THEN name
...
END CASE @SortDirection WHEN 'ASC' THEN ASC ELSE DESC END; Dies ist näher, aber es scheitert aus zwei Gründen. Zum einen ist CASE ein Ausdruck, der genau einen Wert eines bestimmten Datentyps zurückgibt; Dadurch werden inkompatible Datentypen zusammengeführt, wodurch der CASE-Ausdruck unterbrochen wird. Die andere ist, dass es keine Möglichkeit gibt, die Sortierrichtung auf diese Weise bedingt anzuwenden, ohne dynamisches SQL zu verwenden.
Ansätze, die funktionieren
Die drei primären Ansätze, die ich gesehen habe, sind die folgenden:
Gruppieren Sie kompatible Typen und Richtungen zusammen
Um CASE mit ORDER BY verwenden zu können, muss für jede Kombination aus kompatiblen Typen und Richtungen ein eigener Ausdruck vorhanden sein. In diesem Fall müssten wir so etwas verwenden:
CREATE PROCEDURE dbo.Sort_CaseExpanded
@SortColumn NVARCHAR(128) = N'key_col',
@SortDirection VARCHAR(4) = 'ASC'
AS
BEGIN
SET NOCOUNT ON;
SELECT key_col, [object_id], name, type_desc, modify_date
FROM dbo.sys_objects
ORDER BY
CASE WHEN @SortDirection = 'ASC' THEN
CASE @SortColumn
WHEN 'key_col' THEN key_col
WHEN 'object_id' THEN [object_id]
END
END,
CASE WHEN @SortDirection = 'DESC' THEN
CASE @SortColumn
WHEN 'key_col' THEN key_col
WHEN 'object_id' THEN [object_id]
END
END DESC,
CASE WHEN @SortDirection = 'ASC' THEN
CASE @SortColumn
WHEN 'name' THEN name
WHEN 'type_desc' THEN type_desc
END
END,
CASE WHEN @SortDirection = 'DESC' THEN
CASE @SortColumn
WHEN 'name' THEN name
WHEN 'type_desc' THEN type_desc
END
END DESC,
CASE WHEN @SortColumn = 'modify_date'
AND @SortDirection = 'ASC' THEN modify_date
END,
CASE WHEN @SortColumn = 'modify_date'
AND @SortDirection = 'DESC' THEN modify_date
END DESC;
END Sie könnten sagen, wow, das ist ein hässlicher Code, und ich würde Ihnen zustimmen. Ich denke, das ist der Grund, warum viele Leute ihre Daten im Frontend zwischenspeichern und die Präsentationsschicht damit befassen, sie in verschiedenen Reihenfolgen herumzujonglieren. :-)
Sie können diese Logik ein wenig weiter reduzieren, indem Sie alle Nicht-String-Typen in Strings konvertieren, die korrekt sortiert werden, z. B.
CREATE PROCEDURE dbo.Sort_CaseCollapsed
@SortColumn NVARCHAR(128) = N'key_col',
@SortDirection VARCHAR(4) = 'ASC'
AS
BEGIN
SET NOCOUNT ON;
SELECT key_col, [object_id], name, type_desc, modify_date
FROM dbo.sys_objects
ORDER BY
CASE WHEN @SortDirection = 'ASC' THEN
CASE @SortColumn
WHEN 'key_col' THEN RIGHT('000000000000' + RTRIM(key_col), 12)
WHEN 'object_id' THEN
RIGHT(COALESCE(NULLIF(LEFT(RTRIM([object_id]),1),'-'),'0')
+ REPLICATE('0', 23) + RTRIM([object_id]), 24)
WHEN 'name' THEN name
WHEN 'type_desc' THEN type_desc
WHEN 'modify_date' THEN CONVERT(CHAR(19), modify_date, 120)
END
END,
CASE WHEN @SortDirection = 'DESC' THEN
CASE @SortColumn
WHEN 'key_col' THEN RIGHT('000000000000' + RTRIM(key_col), 12)
WHEN 'object_id' THEN
RIGHT(COALESCE(NULLIF(LEFT(RTRIM([object_id]),1),'-'),'0')
+ REPLICATE('0', 23) + RTRIM([object_id]), 24)
WHEN 'name' THEN name
WHEN 'type_desc' THEN type_desc
WHEN 'modify_date' THEN CONVERT(CHAR(19), modify_date, 120)
END
END DESC;
END Trotzdem ist es ein ziemlich hässliches Durcheinander, und Sie müssen die Ausdrücke zweimal wiederholen, um mit den verschiedenen Sortierrichtungen fertig zu werden. Ich würde auch vermuten, dass die Verwendung von OPTION RECOMPILE für diese Abfrage verhindern würde, dass Sie durch Parameter-Sniffing gestochen werden. Außer im Standardfall ist es nicht so, dass der Großteil der Arbeit, die hier geleistet wird, kompiliert wird.
Wenden Sie einen Rang mit Fensterfunktionen an
Ich habe diesen netten Trick von AndriyM entdeckt, obwohl er in Fällen am nützlichsten ist, in denen alle potenziellen Sortierspalten von kompatiblen Typen sind, ansonsten ist der für ROW_NUMBER() verwendete Ausdruck ebenso komplex. Der cleverste Teil ist, dass wir, um zwischen aufsteigender und absteigender Reihenfolge zu wechseln, einfach die ROW_NUMBER() mit 1 oder -1 multiplizieren. Wir können es in dieser Situation wie folgt anwenden:
CREATE PROCEDURE dbo.Sort_RowNumber
@SortColumn NVARCHAR(128) = N'key_col',
@SortDirection VARCHAR(4) = 'ASC'
AS
BEGIN
SET NOCOUNT ON;
;WITH x AS
(
SELECT key_col, [object_id], name, type_desc, modify_date,
rn = ROW_NUMBER() OVER (
ORDER BY CASE @SortColumn
WHEN 'key_col' THEN RIGHT('000000000000' + RTRIM(key_col), 12)
WHEN 'object_id' THEN
RIGHT(COALESCE(NULLIF(LEFT(RTRIM([object_id]),1),'-'),'0')
+ REPLICATE('0', 23) + RTRIM([object_id]), 24)
WHEN 'name' THEN name
WHEN 'type_desc' THEN type_desc
WHEN 'modify_date' THEN CONVERT(CHAR(19), modify_date, 120)
END
) * CASE @SortDirection WHEN 'ASC' THEN 1 ELSE -1 END
FROM dbo.sys_objects
)
SELECT key_col, [object_id], name, type_desc, modify_date
FROM x
ORDER BY rn;
END
GO Auch hier kann OPTION RECOMPILE helfen. Außerdem stellen Sie in einigen dieser Fälle möglicherweise fest, dass Bindungen von den verschiedenen Plänen unterschiedlich gehandhabt werden – wenn Sie beispielsweise nach Namen bestellen, sehen Sie normalerweise key_col in aufsteigender Reihenfolge innerhalb jedes Satzes von doppelten Namen, aber Sie können auch sehen die Werte verwechselt. Um im Fall von Unentschieden ein besser vorhersagbares Verhalten bereitzustellen, können Sie jederzeit eine zusätzliche ORDER BY-Klausel hinzufügen. Beachten Sie, dass Sie beim Hinzufügen von key_col zum ersten Beispiel einen Ausdruck daraus machen müssen, damit key_col nicht zweimal in ORDER BY aufgeführt wird (Sie können dies beispielsweise mit key_col + 0 tun).
Dynamisches SQL
Viele Leute haben Vorbehalte gegenüber dynamischem SQL – es ist nicht lesbar, es ist ein Nährboden für SQL-Injection, es führt zu Plan-Cache-Bloat, es macht den Zweck der Verwendung gespeicherter Prozeduren zunichte … Einige davon sind einfach unwahr, andere sind leicht zu mildern. Ich habe hier einige Validierungen hinzugefügt, die genauso einfach zu jedem der oben genannten Verfahren hinzugefügt werden könnten:
CREATE PROCEDURE dbo.Sort_DynamicSQL
@SortColumn NVARCHAR(128) = N'key_col',
@SortDirection VARCHAR(4) = 'ASC'
AS
BEGIN
SET NOCOUNT ON;
-- reject any invalid sort directions:
IF UPPER(@SortDirection) NOT IN ('ASC','DESC')
BEGIN
RAISERROR('Invalid parameter for @SortDirection: %s', 11, 1, @SortDirection);
RETURN -1;
END
-- reject any unexpected column names:
IF LOWER(@SortColumn) NOT IN (N'key_col', N'object_id', N'name', N'type_desc', N'modify_date')
BEGIN
RAISERROR('Invalid parameter for @SortColumn: %s', 11, 1, @SortColumn);
RETURN -1;
END
SET @SortColumn = QUOTENAME(@SortColumn);
DECLARE @sql NVARCHAR(MAX);
SET @sql = N'SELECT key_col, [object_id], name, type_desc, modify_date
FROM dbo.sys_objects
ORDER BY ' + @SortColumn + ' ' + @SortDirection + ';';
EXEC sp_executesql @sql;
END Leistungsvergleiche
Ich habe für jede der obigen Prozeduren eine gespeicherte Wrapper-Prozedur erstellt, damit ich alle Szenarien problemlos testen kann. Die vier Wrapper-Prozeduren sehen wie folgt aus, wobei der Prozedurname natürlich variiert:
CREATE PROCEDURE dbo.Test_Sort_CaseExpanded AS BEGIN SET NOCOUNT ON; EXEC dbo.Sort_CaseExpanded; -- default EXEC dbo.Sort_CaseExpanded N'name', 'ASC'; EXEC dbo.Sort_CaseExpanded N'name', 'DESC'; EXEC dbo.Sort_CaseExpanded N'object_id', 'ASC'; EXEC dbo.Sort_CaseExpanded N'object_id', 'DESC'; EXEC dbo.Sort_CaseExpanded N'type_desc', 'ASC'; EXEC dbo.Sort_CaseExpanded N'type_desc', 'DESC'; EXEC dbo.Sort_CaseExpanded N'modify_date', 'ASC'; EXEC dbo.Sort_CaseExpanded N'modify_date', 'DESC'; END
Und dann habe ich mithilfe von SQL Sentry Plan Explorer tatsächliche Ausführungspläne (und die dazugehörigen Metriken) mit den folgenden Abfragen generiert und den Vorgang zehnmal wiederholt, um die Gesamtdauer zusammenzufassen:
DBCC DROPCLEANBUFFERS; DBCC FREEPROCCACHE; EXEC dbo.Test_Sort_CaseExpanded; --EXEC dbo.Test_Sort_CaseCollapsed; --EXEC dbo.Test_Sort_RowNumber; --EXEC dbo.Test_Sort_DynamicSQL; GO 10
Ich habe die ersten drei Fälle auch mit OPTION RECOMPILE getestet (macht für den dynamischen SQL-Fall nicht viel Sinn, da wir wissen, dass es jedes Mal ein neuer Plan sein wird) und alle vier Fälle mit MAXDOP 1, um Parallelitätsstörungen zu eliminieren. Hier sind die Ergebnisse:
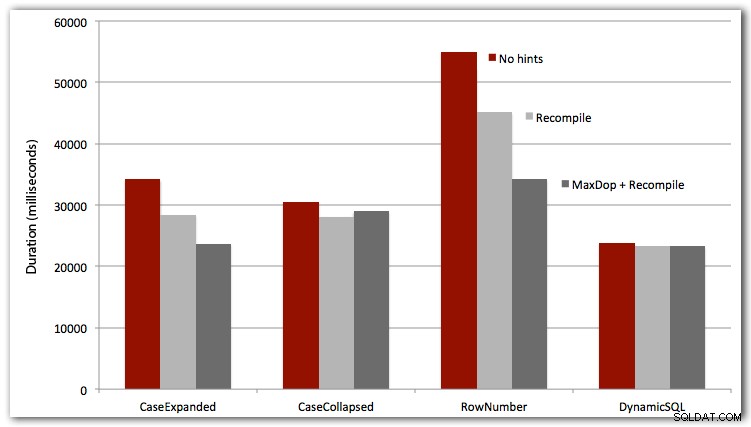
Schlussfolgerung
Für absolute Leistung gewinnt dynamisches SQL jedes Mal (wenn auch nur mit einem kleinen Vorsprung bei diesem Datensatz). Der ROW_NUMBER()-Ansatz war zwar clever, aber in jedem Test der Verlierer (sorry AndriyM).
Noch lustiger wird es, wenn Sie eine WHERE-Klausel einführen wollen, ganz zu schweigen von Paging. Diese drei sind wie der perfekte Sturm, um Komplexität in etwas zu bringen, das als einfache Suchanfrage beginnt. Je mehr Permutationen Ihre Abfrage hat, desto wahrscheinlicher möchten Sie die Lesbarkeit aus dem Fenster werfen und dynamisches SQL in Kombination mit der Einstellung „Optimieren für Ad-hoc-Workloads“ verwenden, um die Auswirkungen von Einzelnutzungsplänen in Ihrem Plancache zu minimieren.



