Es gab viele Kommentare nach meinem Post letzte Woche über das Teilen von Strings. Ich denke, der Punkt des Artikels war nicht so offensichtlich, wie er hätte sein können:dass es nicht vorteilhaft wäre, viel Zeit und Mühe darauf zu verwenden, eine von Natur aus langsame Aufteilungsfunktion auf der Grundlage von T-SQL zu "perfektionieren". Seitdem habe ich die neueste Version von Jeff Modens String-Splitting-Funktion gesammelt und sie mit den anderen verglichen:
ALTER FUNCTION [dbo].[DelimitedSplitN4K]
(@pString NVARCHAR(4000), @pDelimiter NCHAR(1))
RETURNS TABLE WITH SCHEMABINDING AS
RETURN
WITH E1(N) AS (
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1
),
E2(N) AS (SELECT 1 FROM E1 a, E1 b),
E4(N) AS (SELECT 1 FROM E2 a, E2 b),
cteTally(N) AS (SELECT TOP (ISNULL(DATALENGTH(@pString)/2,0))
ROW_NUMBER() OVER (ORDER BY (SELECT NULL)) FROM E4),
cteStart(N1) AS (SELECT 1 UNION ALL
SELECT t.N+1 FROM cteTally t WHERE SUBSTRING(@pString,t.N,1) = @pDelimiter
),
cteLen(N1,L1) AS(SELECT s.N1,
ISNULL(NULLIF(CHARINDEX(@pDelimiter,@pString,s.N1),0)-s.N1,4000)
FROM cteStart s
)
SELECT ItemNumber = ROW_NUMBER() OVER(ORDER BY l.N1),
Item = SUBSTRING(@pString, l.N1, l.L1)
FROM cteLen l;
GO (Die einzigen Änderungen, die ich vorgenommen habe:Ich habe es für die Anzeige formatiert und die Kommentare entfernt. Sie können die Originalquelle hier abrufen.)
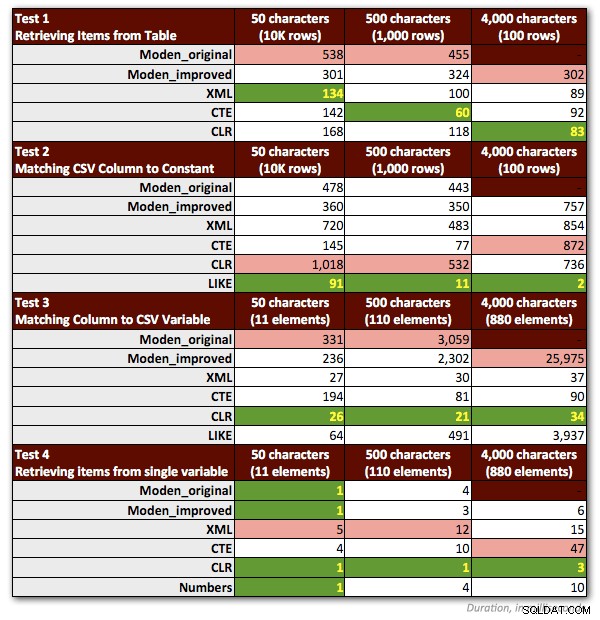
Ich musste einige Anpassungen an meinen Tests vornehmen, um Jeffs Funktion angemessen darzustellen. Am wichtigsten:Ich musste alle Proben verwerfen, die Zeichenfolgen> 4.000 Zeichen enthielten. Also habe ich die 5.000-Zeichen-Strings in der dbo.strings-Tabelle auf 4.000 Zeichen geändert und mich nur auf die ersten drei Nicht-MAX-Szenarien konzentriert (wobei ich die vorherigen Ergebnisse für die ersten beiden beibehalten und den dritten Test erneut für die neuen ausgeführt habe 4.000 Zeichen lange Zeichenfolgen). Auch die Zahlentabelle habe ich bei allen Tests bis auf einen weggelassen, weil klar war, dass die Performance dort immer mindestens um den Faktor 10 schlechter war. Die folgende Grafik zeigt noch einmal die Performance der Funktionen in jedem der vier Tests gemittelt über 10 Läufe und immer mit einem kalten Cache und sauberen Puffern.
Hier sind also meine leicht überarbeiteten bevorzugten Methoden für jede Art von Aufgabe:
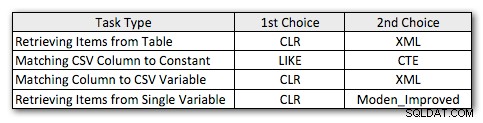
Sie werden feststellen, dass CLR meine Methode der Wahl geblieben ist, außer in dem einen Fall, in dem die Aufteilung keinen Sinn macht. Und in Fällen, in denen CLR keine Option ist, sind die XML- und CTE-Methoden im Allgemeinen effizienter, außer im Fall der Einzelvariablenaufteilung, bei der Jeffs Funktion sehr wohl die beste Option sein kann. Aber angesichts der Tatsache, dass ich möglicherweise mehr als 4.000 Zeichen unterstützen muss, schafft es die Numbers-Tabellenlösung in bestimmten Situationen, in denen ich CLR nicht verwenden darf, möglicherweise wieder auf meine Liste.
Ich verspreche, dass mein nächster Beitrag, in dem es um Listen geht, überhaupt nicht über das Aufteilen über T-SQL oder CLR sprechen wird und zeigen wird, wie dieses Problem unabhängig vom Datentyp vereinfacht werden kann.
Nebenbei habe ich diesen Kommentar in einer der Versionen von Jeffs Funktionen bemerkt, die in den Kommentaren gepostet wurde:Ich danke auch demjenigen, der den ersten Artikel geschrieben hat, den ich je über „Zahlentabellen“ gesehen habe, der sich unter der folgenden URL befindet, und an Adam Machanic dafür, dass Sie mich vor vielen Jahren dazu geführt haben.https://web.archive.org/web/20150411042510/https://sqlserver2000.databases.aspfaq.com/why-should-i-consider-using-an -hilfszahlentabelle.html
Dieser Artikel wurde 2004 von mir geschrieben. Wer auch immer den Kommentar zur Funktion hinzugefügt hat, gerne geschehen. :-)