Das Hervorheben von Treffern ist eine Funktion, von der sich viele Leute wünschen, dass die Volltextsuche von SQL Server nativ unterstützt wird. Hier können Sie das gesamte Dokument (oder einen Auszug) zurückgeben und auf die Wörter oder Ausdrücke hinweisen, die dazu beigetragen haben, dieses Dokument mit der Suche abzugleichen. Dies auf effiziente und genaue Weise zu tun, ist keine leichte Aufgabe, wie ich aus erster Hand erfahren habe.
Als Beispiel für Treffer-Hervorhebung:Wenn Sie eine Suche in Google oder Bing durchführen, erhalten Sie die Schlüsselwörter sowohl im Titel als auch im Auszug fett gedruckt (zum Vergrößern auf eines der Bilder klicken):

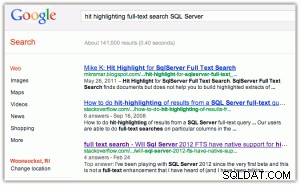
[Nebenbei finde ich hier zwei Dinge amüsant:(1) dass Bing Microsoft-Eigenschaften viel mehr bevorzugt als Google, und (2) dass Bing sich die Mühe macht, 2,2 Millionen Ergebnisse zurückzugeben, von denen viele wahrscheinlich irrelevant sind.]
Diese Auszüge werden allgemein als „Snippets“ oder „abfrageorientierte Zusammenfassungen“ bezeichnet. Wir fragen seit einiger Zeit nach dieser Funktionalität in SQL Server, haben aber noch keine guten Nachrichten von Microsoft gehört:
- Connect #295100 :Zusammenfassungen der Volltextsuche (Hervorhebung von Treffern)
- Connect #722324 :Wäre schön, wenn die SQL-Volltextsuche Snippet-/Hervorhebungsunterstützung bieten würde
Die Frage taucht ab und zu auch bei Stack Overflow auf:
- Hervorhebung von Treffern für Ergebnisse aus einer SQL Server-Volltextabfrage
- Wird Sql Server 2012 FTS native Unterstützung für die Hervorhebung von Treffern haben?
Es gibt einige Teillösungen. Dieses Skript von Mike Kramar erzeugt zum Beispiel einen durch Treffer hervorgehobenen Auszug, wendet aber nicht dieselbe Logik (wie etwa sprachspezifische Wörtertrennung) auf das Dokument selbst an. Es verwendet auch eine absolute Zeichenanzahl, sodass der Auszug mit Teilwörtern beginnen und enden kann (wie ich gleich demonstrieren werde). Letzteres ist ziemlich einfach zu beheben, aber ein weiteres Problem ist, dass es das gesamte Dokument in den Speicher lädt, anstatt irgendeine Art von Streaming durchzuführen. Ich vermute, dass dies bei Volltextindizes mit großen Dokumentgrößen ein spürbarer Leistungseinbruch sein wird. Im Moment konzentriere ich mich auf eine relativ kleine durchschnittliche Dokumentgröße (35 KB).
Ein einfaches Beispiel
Nehmen wir also an, wir haben eine sehr einfache Tabelle mit einem definierten Volltextindex:
CREATE FULLTEXT CATALOG [FTSDemo];GO CREATE TABLE [dbo].[Document]( [ID] INT IDENTITY(1001,1) NOT NULL, [Url] NVARCHAR(200) NOT NULL, [Date] DATE NOT NULL , [Titel] NVARCHAR(200) NOT NULL, [Inhalt] NVARCHAR(MAX) NOT NULL, CONSTRAINT PK_DOCUMENT PRIMARY KEY(ID));GO CREATE VOLLTEXTINDEX AUF [dbo].[Dokument]( [Inhalt] SPRACHE [Englisch] , [Titel] SPRACHE [Englisch])KEY INDEX [PK_Document] ON ([FTSDemo]);
Diese Tabelle ist mit einigen Dokumenten (insbesondere 7) gefüllt, wie der Unabhängigkeitserklärung und Nelson Mandelas Rede „Ich bin bereit zu sterben“. Eine typische Volltextsuche in dieser Tabelle könnte folgendermaßen aussehen:
SELECT d.Title, d.[Content]FROM dbo.[Document] AS d INNER JOIN CONTAINSTABLE(dbo.[Document], *, N'states') AS t ON d.ID =t.[KEY] ORDER BY [RANK] DESC;
Das Ergebnis gibt 4 von 7 Zeilen zurück:

Verwenden Sie jetzt eine UDF-Funktion wie die von Mike Kramar:
SELECT d.Title, Excerpt =dbo.HighLightSearch(d.[Content], N'states', 'font-weight:bold', 80)FROM dbo.[Document] AS dINNER JOIN CONTAINSTABLE(dbo.[Document ], *, N'states') AS tON d.ID =t.[KEY]ORDER BY [RANK] DESC;
Die Ergebnisse zeigen, wie der Auszug funktioniert:a <SPAN> -Tag wird beim ersten Schlüsselwort eingefügt, und der Auszug wird basierend auf einem Offset von dieser Position ausgeschnitten (ohne Rücksicht auf die Verwendung vollständiger Wörter):

(Auch dies ist etwas, das behoben werden kann, aber ich möchte sicher sein, dass ich das, was jetzt da draußen ist, richtig darstellt.)
ThinkHighlight
Eran Meyuchas von Interactive Thoughts hat eine Komponente entwickelt, die viele dieser Probleme löst. ThinkHighlight ist als CLR-Assembly mit zwei CLR-Skalarwertfunktionen implementiert:
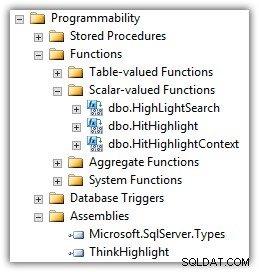
(Sie sehen auch Mike Kramars UDF in der Liste der Funktionen.)
Ohne auf alle Details zur Installation und Aktivierung der Assembly auf Ihrem System einzugehen, sehen Sie hier, wie die obige Abfrage mit ThinkHighlight dargestellt würde:
SELECT d.Title, Excerpt =dbo.HitHighlight(dbo.HitHighlightContext('Document', 'Content', N'states', -1), 'top-fragment', 100, d.ID)FROM dbo. [Dokument] AS dINNER JOIN CONTAINSTABLE(dbo.[Dokument], *, N'states') AS tON d.ID =t.[KEY]ORDER BY t.[RANK] DESC; Die Ergebnisse zeigen, wie die relevantesten Schlüsselwörter hervorgehoben werden, und daraus wird ein Auszug basierend auf vollständigen Wörtern und einem Versatz vom hervorgehobenen Begriff abgeleitet:

Einige zusätzliche Vorteile, die ich hier nicht demonstriert habe, sind die Möglichkeit, verschiedene Zusammenfassungsstrategien auszuwählen, die Darstellung jedes Schlüsselworts (statt aller) mit eindeutigem CSS zu steuern, sowie die Unterstützung für mehrere Sprachen und sogar Dokumente im Binärformat (die meisten IFilters werden unterstützt).
Leistungsergebnisse
Zunächst habe ich die Laufzeitmetriken für die drei Abfragen mit SQL Sentry Plan Explorer anhand der 7-Zeilen-Tabelle getestet. Die Ergebnisse waren:

Als nächstes wollte ich sehen, wie sie sich bei einer viel größeren Datengröße vergleichen würden. Ich habe die Tabelle in sich selbst eingefügt, bis ich bei 4.000 Zeilen war, und dann die folgende Abfrage ausgeführt:
SET STATISTICS TIME ON;GO SELECT /* FTS */ d.Title, d.[Content]FROM dbo.[Document] AS d INNER JOIN CONTAINSTABLE(dbo.[Document], *, N'states') AS tON d.ID =t.[KEY]ORDER BY [RANK] DESC;GO SELECT /* UDF */ d.Title, Excerpt =dbo.HighLightSearch(d.[Content], N'states', 'font-weight:fett', 100)FROM dbo.[Dokument] AS dINNER JOIN CONTAINSTABLE(dbo.[Dokument], *, N'states') AS tON d.ID =t.[KEY]ORDER BY [RANK] DESC;GO SELECT / * ThinkHighlight */ d.Title, Excerpt =dbo.HitHighlight(dbo.HitHighlightContext('Document', 'Content', N'states', -1), 'top-fragment', 100, d.ID)FROM dbo. [Dokument] AS dINNER JOIN CONTAINSTABLE(dbo.[Dokument], *, N'states') AS tON d.ID =t.[KEY]ORDER BY t.[RANK] DESC;GO SET STATISTICS TIME OFF;GO
Ich habe auch sys.dm_exec_memory_grants überwacht, während die Abfragen ausgeführt wurden, um Diskrepanzen bei den Speicherzuweisungen zu erkennen. Ergebnisse, die über 10 Läufe gemittelt werden:
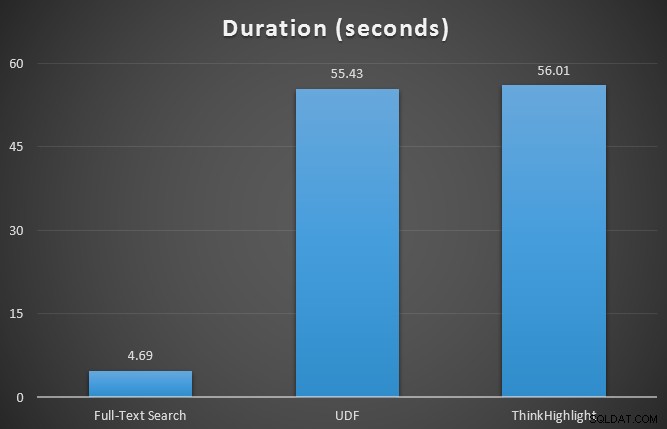
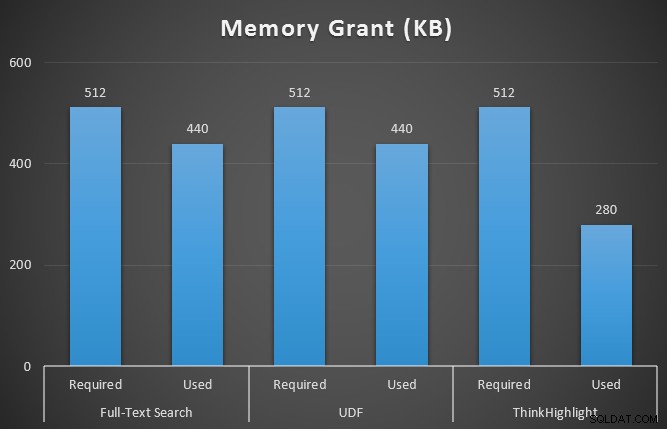
Während beide Optionen zur Hervorhebung von Treffern einen erheblichen Nachteil gegenüber gar keiner Hervorhebung mit sich bringen, stellt die ThinkHighlight-Lösung – mit flexibleren Optionen – einen sehr geringen Mehraufwand in Bezug auf die Dauer dar (~1 %), während sie deutlich weniger Speicher verbraucht (36 %). als die UDF-Variante.
Schlussfolgerung
Es sollte nicht überraschen, dass das Hervorheben von Treffern ein teurer Vorgang ist und aufgrund der Komplexität dessen, was unterstützt werden muss (denken Sie an mehrere Sprachen), dass es nur sehr wenige Lösungen gibt. Ich denke, Mike Kramar hat hervorragende Arbeit geleistet, indem er eine Basis-UDF erstellt hat, die Ihnen einen guten Weg zur Lösung des Problems bringt, aber ich war angenehm überrascht, ein robusteres kommerzielles Angebot zu finden – und fand es sehr stabil, sogar in der Beta-Form. Ich habe vor, gründlichere Tests mit einem breiteren Spektrum an Dokumentgrößen und -typen durchzuführen. Wenn die Hervorhebung von Treffern ein Teil Ihrer Anwendungsanforderungen ist, sollten Sie in der Zwischenzeit Mike Kramars UDF ausprobieren und ThinkHighlight für eine Probefahrt nutzen.