Es gibt viele Anwendungsfälle für das Generieren einer Folge von Werten in SQL Server. Ich spreche nicht von einer persistenten IDENTITY Spalte (oder die neue SEQUENCE in SQL Server 2012), sondern ein vorübergehender Satz, der nur für die Lebensdauer einer Abfrage verwendet wird. Oder sogar die einfachsten Fälle – wie das einfache Anhängen einer Zeilennummer an jede Zeile in einer Ergebnismenge –, bei denen möglicherweise eine ROW_NUMBER() hinzugefügt wird -Funktion zur Abfrage (oder noch besser in der Präsentationsschicht, die ohnehin Zeile für Zeile durch die Ergebnisse schleifen muss).
Ich spreche von etwas komplizierteren Fällen. Beispielsweise haben Sie möglicherweise einen Bericht, der Verkäufe nach Datum anzeigt. Eine typische Abfrage könnte sein:
SELECT OrderDate = CONVERT(DATE, OrderDate), OrderCount = COUNT(*) FROM dbo.Orders GROUP BY CONVERT(DATE, OrderDate) ORDER BY OrderDate;
Das Problem bei dieser Abfrage besteht darin, dass es für diesen Tag keine Zeile gibt, wenn an einem bestimmten Tag keine Bestellungen vorliegen. Dies kann zu Verwirrung, irreführenden Daten oder sogar falschen Berechnungen (denken Sie an Tagesdurchschnittswerte) für die nachgeschalteten Verbraucher der Daten führen.
Daher müssen diese Lücken mit Daten gefüllt werden, die in den Daten nicht vorhanden sind. Und manchmal stopfen Leute ihre Daten in eine #temp-Tabelle und verwenden ein WHILE Schleife oder einen Cursor, um die fehlenden Daten einzeln einzugeben. Ich werde diesen Code hier nicht zeigen, weil ich seine Verwendung nicht befürworten möchte, aber ich habe ihn überall gesehen.
Bevor wir jedoch zu tief in Datumsangaben einsteigen, lassen Sie uns zuerst über Zahlen sprechen, da Sie immer eine Folge von Zahlen verwenden können, um eine Folge von Datumsangaben abzuleiten.
Zahlentabelle
Ich bin seit langem ein Befürworter der Speicherung einer zusätzlichen "Zahlentabelle" auf der Festplatte (und übrigens auch einer Kalendertabelle).
Hier ist eine Möglichkeit, eine einfache Zahlentabelle mit 1.000.000 Werten zu generieren:
SELECT TOP (1000000) n = CONVERT(INT, ROW_NUMBER() OVER (ORDER BY s1.[object_id])) INTO dbo.Numbers FROM sys.all_objects AS s1 CROSS JOIN sys.all_objects AS s2 OPTION (MAXDOP 1); CREATE UNIQUE CLUSTERED INDEX n ON dbo.Numbers(n) -- WITH (DATA_COMPRESSION = PAGE) ;
Warum MAXDOP 1? Siehe den Blogbeitrag von Paul White und sein Connect-Element in Bezug auf Zeilenziele.
Viele Menschen sind jedoch gegen den Hilfstabellenansatz. Ihr Argument:Warum all diese Daten auf der Festplatte (und im Arbeitsspeicher) speichern, wenn sie die Daten on-the-fly generieren können? Mein Zähler soll realistisch sein und darüber nachdenken, was Sie optimieren; Berechnungen können teuer sein, und sind Sie sicher, dass die spontane Berechnung einer Reihe von Zahlen immer billiger sein wird? Was den Speicherplatz betrifft, nimmt die Numbers-Tabelle nur etwa 11 MB komprimiert und 17 MB unkomprimiert ein. Und wenn auf die Tabelle häufig genug verwiesen wird, sollte sie immer im Speicher sein, um den Zugriff schnell zu machen.
Werfen wir einen Blick auf einige Beispiele und einige der gebräuchlicheren Ansätze, die verwendet werden, um sie zu erfüllen. Ich hoffe, wir sind uns alle einig, dass wir diese Probleme auch bei 1.000 Werten nicht mit einer Schleife oder einem Cursor lösen wollen.
Generieren einer Folge von 1.000 Zahlen
Beginnen wir ganz einfach und generieren wir eine Reihe von Zahlen von 1 bis 1.000.
Zahlentabelle
Mit einer Zahlentabelle ist diese Aufgabe natürlich ziemlich einfach:
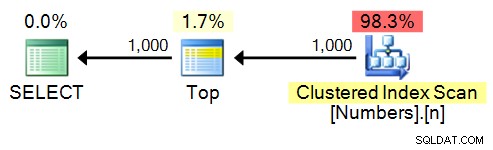
SELECT TOP (1000) n FROM dbo.Numbers ORDER BY n;
Plan:
spt_values
Dies ist eine Tabelle, die von internen gespeicherten Prozeduren für verschiedene Zwecke verwendet wird. Seine Online-Nutzung scheint weit verbreitet zu sein, obwohl es nicht dokumentiert und nicht unterstützt ist, es eines Tages verschwinden könnte und weil es nur eine endliche, nicht eindeutige und nicht zusammenhängende Menge von Werten enthält. Es gibt 2.164 eindeutige und 2.508 Gesamtwerte in SQL Server 2008 R2; 2012 gibt es 2.167 einzigartige und 2.515 insgesamt. Dies schließt Duplikate, negative Werte und sogar die Verwendung von DISTINCT ein , viele Lücken, sobald Sie die Zahl 2.048 überschritten haben. Die Problemumgehung besteht also darin, ROW_NUMBER() zu verwenden um eine fortlaufende Sequenz zu generieren, beginnend bei 1, basierend auf den Werten in der Tabelle.
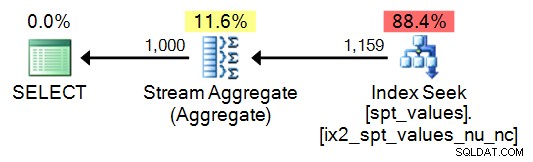
SELECT TOP (1000) n = ROW_NUMBER() OVER (ORDER BY number) FROM [master]..spt_values ORDER BY n;
Plan:

Allerdings könnten Sie für nur 1.000 Werte eine etwas einfachere Abfrage schreiben, um dieselbe Sequenz zu generieren:
SELECT DISTINCT n = number FROM master..[spt_values] WHERE number BETWEEN 1 AND 1000;
Dies führt natürlich zu einem einfacheren Plan, bricht aber ziemlich schnell zusammen (sobald Ihre Sequenz mehr als 2.048 Zeilen umfassen muss):
In jedem Fall empfehle ich die Verwendung dieser Tabelle nicht; Ich füge es zu Vergleichszwecken hinzu, nur weil ich weiß, wie viel davon da draußen ist und wie verlockend es sein könnte, Code, auf den Sie stoßen, einfach wiederzuverwenden.
sys.all_objects
Ein anderer Ansatz, der im Laufe der Jahre einer meiner Favoriten war, ist die Verwendung von sys.all_objects . Wie spt_values , gibt es keine zuverlässige Möglichkeit, eine zusammenhängende Sequenz direkt zu generieren, und wir haben die gleichen Probleme bei der Behandlung einer endlichen Menge (knapp 2.000 Zeilen in SQL Server 2008 R2 und etwas mehr als 2.000 Zeilen in SQL Server 2012), aber für 1.000 Zeilen wir können dieselbe ROW_NUMBER() verwenden Trick. Der Grund, warum ich diesen Ansatz mag, ist, dass (a) weniger Bedenken bestehen, dass diese Ansicht bald verschwinden wird, (b) die Ansicht selbst dokumentiert und unterstützt wird und (c) sie auf jeder Datenbank auf jeder Version seit SQL Server ausgeführt werden kann 2005, ohne Datenbankgrenzen überschreiten zu müssen (einschließlich enthaltener Datenbanken).
SELECT TOP (1000) n = ROW_NUMBER() OVER (ORDER BY [object_id]) FROM sys.all_objects ORDER BY n;
Plan:

Gestapelte CTEs
Ich glaube, Itzik Ben-Gan gebührt die höchste Anerkennung für diesen Ansatz; Im Grunde konstruieren Sie einen CTE mit einer kleinen Menge von Werten, dann erstellen Sie das kartesische Produkt gegen sich selbst, um die Anzahl der benötigten Zeilen zu generieren. Und wieder, anstatt zu versuchen, eine zusammenhängende Menge als Teil der zugrunde liegenden Abfrage zu generieren, können wir einfach ROW_NUMBER() anwenden zum Endergebnis.
;WITH e1(n) AS
(
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1
), -- 10
e2(n) AS (SELECT 1 FROM e1 CROSS JOIN e1 AS b), -- 10*10
e3(n) AS (SELECT 1 FROM e1 CROSS JOIN e2) -- 10*100
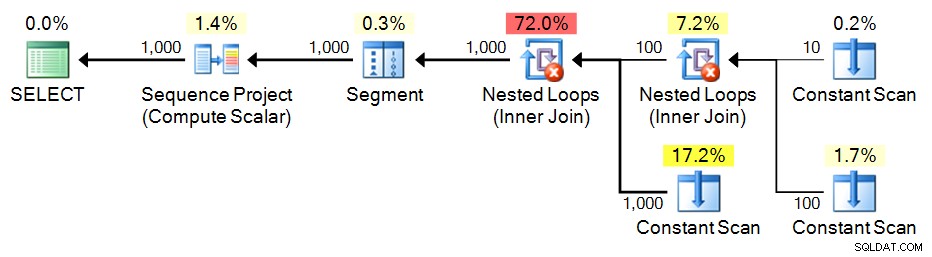
SELECT n = ROW_NUMBER() OVER (ORDER BY n) FROM e3 ORDER BY n; Plan:
Rekursiver CTE
Schließlich haben wir einen rekursiven CTE, der 1 als Anker verwendet und 1 hinzufügt, bis wir das Maximum erreichen. Zur Sicherheit gebe ich das Maximum sowohl im WHERE an -Klausel des rekursiven Teils und in MAXRECURSION Einstellung. Je nachdem, wie viele Nummern Sie benötigen, müssen Sie möglicherweise MAXRECURSION einstellen auf 0 .
;WITH n(n) AS
(
SELECT 1
UNION ALL
SELECT n+1 FROM n WHERE n < 1000
)
SELECT n FROM n ORDER BY n
OPTION (MAXRECURSION 1000); Plan:
Leistung
Natürlich sind die Leistungsunterschiede bei 1.000 Werten vernachlässigbar, aber es kann nützlich sein, zu sehen, wie sich diese verschiedenen Optionen verhalten:
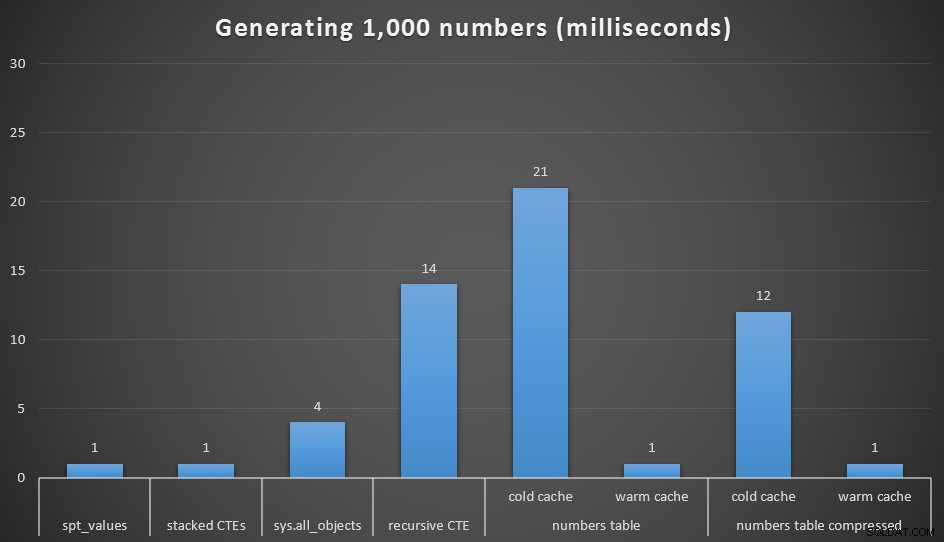
Laufzeit in Millisekunden zum Generieren von 1.000 zusammenhängenden Nummern
Ich habe jede Abfrage 20 Mal ausgeführt und durchschnittliche Laufzeiten genommen. Ich habe auch die dbo.Numbers getestet in komprimierten und unkomprimierten Formaten und mit einem Cold-Cache und einem Warm-Cache. Mit einem warmen Cache konkurriert es sehr eng mit den anderen schnellsten Optionen da draußen (spt_values , nicht empfohlen, und gestapelte CTEs), aber der erste Treffer ist relativ teuer (obwohl ich fast lachen muss, wenn ich es so nenne).
Fortsetzung folgt...
Wenn dies Ihr typischer Anwendungsfall ist und Sie sich nicht weit über 1.000 Zeilen hinauswagen, dann hoffe ich, dass ich die schnellsten Wege zum Generieren dieser Zahlen gezeigt habe. Wenn Ihr Anwendungsfall eine größere Anzahl ist oder Sie nach Lösungen suchen, um Datumsfolgen zu generieren, bleiben Sie dran. Später in dieser Serie werde ich das Generieren von Sequenzen von 50.000 und 1.000.000 Zahlen und Datumsbereichen von einer Woche bis zu einem Jahr untersuchen.
[ Teil 1 | Teil 2 | Teil 3 ]