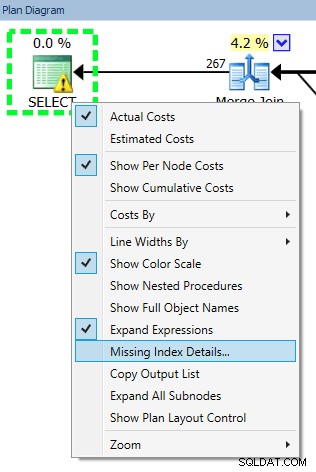
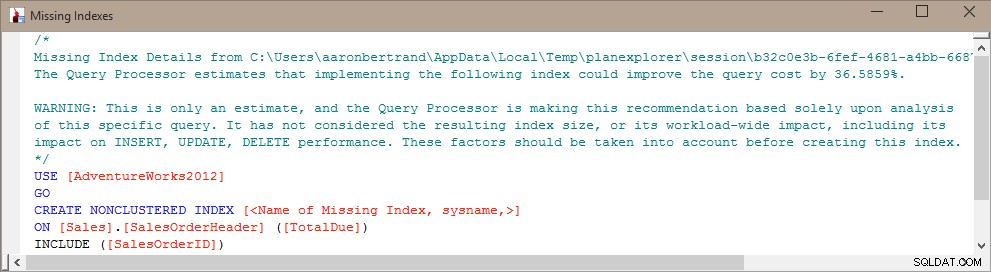
Kevin Kline (@kekline) und ich haben kürzlich ein Webinar zur Abfrageoptimierung abgehalten (eigentlich eines in einer Reihe), und eines der Dinge, die dabei aufkamen, war die Tendenz der Leute, jeden fehlenden Index zu erstellen, den SQL Server ihnen mitteilt eine gute Sache™ . Sie können sich über diese fehlenden Indizes aus dem Database Engine Tuning Advisor (DTA), den fehlenden Index-DMVs oder einem in Management Studio oder Plan Explorer angezeigten Ausführungsplan informieren (die alle nur Informationen von genau derselben Stelle weiterleiten):
Das Problem beim blinden Erstellen dieses Index besteht darin, dass SQL Server entschieden hat, dass er für eine bestimmte Abfrage (oder eine Handvoll Abfragen) nützlich ist, den Rest der Arbeitslast jedoch vollständig und einseitig ignoriert. Wie wir alle wissen, sind Indizes nicht „kostenlos“ – Sie bezahlen für Indizes sowohl im Rohspeicher als auch für die Wartung, die für DML-Operationen erforderlich ist. Bei einer schreibintensiven Arbeitslast macht es wenig Sinn, einen Index hinzuzufügen, der dazu beiträgt, eine einzelne Abfrage etwas effizienter zu machen, insbesondere wenn diese Abfrage nicht häufig ausgeführt wird. In diesen Fällen kann es sehr wichtig sein, Ihre Gesamtarbeitslast zu verstehen und ein gutes Gleichgewicht zwischen effizienten Abfragen und nicht zu hohen Kosten für die Indexpflege zu finden.
Ich hatte also die Idee, Informationen aus den fehlenden Index-DMVs, den DMV der Indexnutzungsstatistiken und Informationen zu Abfrageplänen zu „mischen“, um festzustellen, welche Art von Saldo derzeit vorhanden ist und wie das Hinzufügen des Index insgesamt abschneiden könnte.
Fehlende Indizes
Zunächst können wir einen Blick auf die fehlenden Indizes werfen, die SQL Server derzeit vorschlägt:
SELECT d.[object_id], s = OBJECT_SCHEMA_NAME(d.[object_id]), o = OBJECT_NAME(d.[object_id]), d.equality_columns, d.inequality_columns, d.included_columns, s.unique_compiles, s.user_seeks, s.last_user_seek, s.user_scans, s.last_user_scan INTO #candidates FROM sys.dm_db_missing_index_details AS d INNER JOIN sys.dm_db_missing_index_groups AS g ON d.index_handle = g.index_handle INNER JOIN sys.dm_db_missing_index_group_stats AS s ON g.index_group_handle = s.group_handle WHERE d.database_id = DB_ID() AND OBJECTPROPERTY(d.[object_id], 'IsMsShipped') = 0;
Dies zeigt die Tabelle(n) und Spalte(n), die in einem Index nützlich gewesen wären, wie viele Kompilierungen/Suchvorgänge/Scans verwendet worden wären und wann das letzte derartige Ereignis für jeden potenziellen Index aufgetreten ist. Sie können auch Spalten wie s.avg_total_user_cost einfügen und s.avg_user_impact wenn Sie diese Zahlen zur Priorisierung verwenden möchten.
Operationen planen
Als nächstes werfen wir einen Blick auf die Operationen, die in allen Plänen verwendet werden, die wir für die Objekte zwischengespeichert haben, die durch unsere fehlenden Indizes identifiziert wurden.
CREATE TABLE #planops
(
o INT,
i INT,
h VARBINARY(64),
uc INT,
Scan_Ops INT,
Seek_Ops INT,
Update_Ops INT
);
DECLARE @sql NVARCHAR(MAX) = N'';
SELECT @sql += N'
UNION ALL SELECT o,i,h,uc,Scan_Ops,Seek_Ops,Update_Ops
FROM
(
SELECT o = ' + RTRIM([object_id]) + ',
i = ' + RTRIM(index_id) +',
h = pl.plan_handle,
uc = pl.usecounts,
Scan_Ops = p.query_plan.value(''count(//RelOp[@LogicalOp = ''''Index Scan'''''
+ ' or @LogicalOp = ''''Clustered Index Scan'''']/*/'
+ 'Object[@Index=''''' + QUOTENAME(name) + '''''])'', ''int''),
Seek_Ops = p.query_plan.value(''count(//RelOp[@LogicalOp = ''''Index Seek'''''
+ ' or @LogicalOp = ''''Clustered Index Seek'''']/*/'
+ 'Object[@Index=''''' + QUOTENAME(name) + '''''])'', ''int''),
Update_Ops = p.query_plan.value(''count(//Update/Object[@Index='''''
+ QUOTENAME(name) + '''''])'', ''int'')
FROM sys.dm_exec_cached_plans AS pl
CROSS APPLY sys.dm_exec_query_plan(pl.plan_handle) AS p
WHERE p.dbid = DB_ID()
AND p.query_plan IS NOT NULL
) AS x
WHERE Scan_Ops + Seek_Ops + Update_Ops > 0'
FROM sys.indexes AS i
WHERE i.index_id > 0
AND EXISTS (SELECT 1 FROM #candidates WHERE [object_id] = i.[object_id]);
SET @sql = ';WITH xmlnamespaces (DEFAULT '
+ 'N''https://schemas.microsoft.com/sqlserver/2004/07/showplan'')
' + STUFF(@sql, 1, 16, '');
INSERT #planops EXEC sp_executesql @sql; Ein Freund von dba.SE, Mikael Eriksson, schlug die folgenden zwei Abfragen vor, die auf einem größeren System viel besser abschneiden als die XML / UNION-Abfrage, die ich oben zusammengeschustert habe, also könnten Sie zuerst damit experimentieren. Sein abschließender Kommentar war, dass er "nicht überraschend herausgefunden hat, dass weniger XML eine gute Sache für die Leistung ist. :)" In der Tat.
-- alternative #1
with xmlnamespaces (default 'https://schemas.microsoft.com/sqlserver/2004/07/showplan')
insert #planops
select o,i,h,uc,Scan_Ops,Seek_Ops,Update_Ops
from
(
select o = i.object_id,
i = i.index_id,
h = pl.plan_handle,
uc = pl.usecounts,
Scan_Ops = p.query_plan.value('count(//RelOp[@LogicalOp
= ("Index Scan", "Clustered Index Scan")]/*/Object[@Index = sql:column("i2.name")])', 'int'),
Seek_Ops = p.query_plan.value('count(//RelOp[@LogicalOp
= ("Index Seek", "Clustered Index Seek")]/*/Object[@Index = sql:column("i2.name")])', 'int'),
Update_Ops = p.query_plan.value('count(//Update/Object[@Index = sql:column("i2.name")])', 'int')
from sys.indexes as i
cross apply (select quotename(i.name) as name) as i2
cross apply sys.dm_exec_cached_plans as pl
cross apply sys.dm_exec_query_plan(pl.plan_handle) AS p
where exists (select 1 from #candidates as c where c.[object_id] = i.[object_id])
and p.query_plan.exist('//Object[@Index = sql:column("i2.name")]') = 1
and p.[dbid] = db_id()
and i.index_id > 0
) as T
where Scan_Ops + Seek_Ops + Update_Ops > 0;
-- alternative #2
with xmlnamespaces (default 'https://schemas.microsoft.com/sqlserver/2004/07/showplan')
insert #planops
select o = coalesce(T1.o, T2.o),
i = coalesce(T1.i, T2.i),
h = coalesce(T1.h, T2.h),
uc = coalesce(T1.uc, T2.uc),
Scan_Ops = isnull(T1.Scan_Ops, 0),
Seek_Ops = isnull(T1.Seek_Ops, 0),
Update_Ops = isnull(T2.Update_Ops, 0)
from
(
select o = i.object_id,
i = i.index_id,
h = t.plan_handle,
uc = t.usecounts,
Scan_Ops = sum(case when t.LogicalOp in ('Index Scan', 'Clustered Index Scan') then 1 else 0 end),
Seek_Ops = sum(case when t.LogicalOp in ('Index Seek', 'Clustered Index Seek') then 1 else 0 end)
from (
select
r.n.value('@LogicalOp', 'varchar(100)') as LogicalOp,
o.n.value('@Index', 'sysname') as IndexName,
pl.plan_handle,
pl.usecounts
from sys.dm_exec_cached_plans as pl
cross apply sys.dm_exec_query_plan(pl.plan_handle) AS p
cross apply p.query_plan.nodes('//RelOp') as r(n)
cross apply r.n.nodes('*/Object') as o(n)
where p.dbid = db_id()
and p.query_plan is not null
) as t
inner join sys.indexes as i
on t.IndexName = quotename(i.name)
where t.LogicalOp in ('Index Scan', 'Clustered Index Scan', 'Index Seek', 'Clustered Index Seek')
and exists (select 1 from #candidates as c where c.object_id = i.object_id)
group by i.object_id,
i.index_id,
t.plan_handle,
t.usecounts
) as T1
full outer join
(
select o = i.object_id,
i = i.index_id,
h = t.plan_handle,
uc = t.usecounts,
Update_Ops = count(*)
from (
select
o.n.value('@Index', 'sysname') as IndexName,
pl.plan_handle,
pl.usecounts
from sys.dm_exec_cached_plans as pl
cross apply sys.dm_exec_query_plan(pl.plan_handle) AS p
cross apply p.query_plan.nodes('//Update') as r(n)
cross apply r.n.nodes('Object') as o(n)
where p.dbid = db_id()
and p.query_plan is not null
) as t
inner join sys.indexes as i
on t.IndexName = quotename(i.name)
where exists
(
select 1 from #candidates as c where c.[object_id] = i.[object_id]
)
and i.index_id > 0
group by i.object_id,
i.index_id,
t.plan_handle,
t.usecounts
) as T2
on T1.o = T2.o and
T1.i = T2.i and
T1.h = T2.h and
T1.uc = T2.uc;
Jetzt im #planops Tabelle haben Sie eine Reihe von Werten für plan_handle damit Sie jeden der einzelnen Pläne im Spiel gegen die Objekte untersuchen können, bei denen festgestellt wurde, dass ein nützlicher Index fehlt. Wir werden es im Moment nicht dafür verwenden, aber Sie können es leicht mit Querverweisen versehen:
SELECT OBJECT_SCHEMA_NAME(po.o), OBJECT_NAME(po.o), po.uc,po.Scan_Ops,po.Seek_Ops,po.Update_Ops, p.query_plan FROM #planops AS po CROSS APPLY sys.dm_exec_query_plan(po.h) AS p;
Jetzt können Sie auf einen der Ausgabepläne klicken, um zu sehen, was sie derzeit mit Ihren Objekten tun. Beachten Sie, dass einige der Pläne wiederholt werden, da ein Plan mehrere Operatoren haben kann, die auf verschiedene Indizes in derselben Tabelle verweisen.
Indexnutzungsstatistiken
Als Nächstes werfen wir einen Blick auf die Statistiken zur Indexnutzung, damit wir sehen können, wie viel tatsächliche Aktivität derzeit gegen unsere Kandidatentabellen (und insbesondere für Aktualisierungen) ausgeführt wird.
SELECT [object_id], index_id, user_seeks, user_scans, user_lookups, user_updates INTO #indexusage FROM sys.dm_db_index_usage_stats AS s WHERE database_id = DB_ID() AND EXISTS (SELECT 1 FROM #candidates WHERE [object_id] = s.[object_id]);
Seien Sie nicht beunruhigt, wenn sehr wenige oder gar keine Pläne im Cache Aktualisierungen für einen bestimmten Index anzeigen, obwohl die Indexnutzungsstatistiken zeigen, dass diese Indizes aktualisiert wurden. Das bedeutet nur, dass die Update-Pläne derzeit nicht im Cache sind, was verschiedene Gründe haben kann – zum Beispiel könnte es eine sehr leselastige Arbeitslast sein und sie sind veraltet, oder sie sind alle Single- verwenden und optimize for ad hoc workloads aktiviert ist.
Alles zusammenfügen
Die folgende Abfrage zeigt Ihnen für jeden vorgeschlagenen fehlenden Index die Anzahl der Lesevorgänge, die ein Index unterstützt haben könnte, die Anzahl der Schreib- und Lesevorgänge, die derzeit gegen die vorhandenen Indizes erfasst wurden, das Verhältnis dieser und die Anzahl der zugehörigen Pläne dieses Objekt und die Gesamtzahl der Nutzungen für diese Pläne:
;WITH x AS
(
SELECT
c.[object_id],
potential_read_ops = SUM(c.user_seeks + c.user_scans),
[write_ops] = SUM(iu.user_updates),
[read_ops] = SUM(iu.user_scans + iu.user_seeks + iu.user_lookups),
[write:read ratio] = CONVERT(DECIMAL(18,2), SUM(iu.user_updates)*1.0 /
SUM(iu.user_scans + iu.user_seeks + iu.user_lookups)),
current_plan_count = po.h,
current_plan_use_count = po.uc
FROM
#candidates AS c
LEFT OUTER JOIN
#indexusage AS iu
ON c.[object_id] = iu.[object_id]
LEFT OUTER JOIN
(
SELECT o, h = COUNT(h), uc = SUM(uc)
FROM #planops GROUP BY o
) AS po
ON c.[object_id] = po.o
GROUP BY c.[object_id], po.h, po.uc
)
SELECT [object] = QUOTENAME(c.s) + '.' + QUOTENAME(c.o),
c.equality_columns,
c.inequality_columns,
c.included_columns,
x.potential_read_ops,
x.write_ops,
x.read_ops,
x.[write:read ratio],
x.current_plan_count,
x.current_plan_use_count
FROM #candidates AS c
INNER JOIN x
ON c.[object_id] = x.[object_id]
ORDER BY x.[write:read ratio];
Wenn Ihr Schreib-Lese-Verhältnis zu diesen Indizes bereits> 1 (oder> 10!) ist, gibt dies meiner Meinung nach Anlass zu einer Pause, bevor Sie blind einen Index erstellen, der dieses Verhältnis nur erhöhen könnte. Die Anzahl von potential_read_ops gezeigt, kann dies jedoch ausgleichen, wenn die Zahl größer wird. Wenn die potential_read_ops Zahl sehr klein ist, möchten Sie die Empfehlung wahrscheinlich vollständig ignorieren, bevor Sie sich überhaupt die Mühe machen, die anderen Metriken zu untersuchen – also könnten Sie ein WHERE hinzufügen Klausel, um einige dieser Empfehlungen herauszufiltern.
Ein paar Anmerkungen:
- Dies sind Lese- und Schreibvorgänge, keine einzeln gemessenen Lese- und Schreibvorgänge von 8.000 Seiten.
- Das Verhältnis und die Vergleiche sind größtenteils lehrreich; Es könnte sehr gut sein, dass 10.000.000 Schreibvorgänge alle eine einzelne Zeile betreffen, während 10 Lesevorgänge wesentlich mehr Auswirkungen haben könnten. Dies ist nur als grobe Richtlinie gedacht und geht davon aus, dass Lese- und Schreibvorgänge ungefähr gleich gewichtet werden.
- Sie können auch geringfügige Variationen einiger dieser Abfragen verwenden, um herauszufinden – abgesehen von den fehlenden Indizes, die SQL Server empfiehlt – wie viele Ihrer aktuellen Indizes verschwenderisch sind. Es gibt viele Ideen dazu online, einschließlich dieses Beitrags von Paul Randal (@PaulRandal).
Ich hoffe, das gibt Ihnen einige Ideen, um mehr Einblick in das Verhalten Ihres Systems zu erhalten, bevor Sie sich entscheiden, einen Index hinzuzufügen, den Sie von einem Tool erstellen lassen sollten. Ich hätte dies als eine riesige Abfrage erstellen können, aber ich denke, die einzelnen Teile geben Ihnen einige Kaninchenlöcher, die Sie untersuchen können, wenn Sie dies wünschen.
Sonstige Anmerkungen
Möglicherweise möchten Sie dies auch erweitern, um aktuelle Größenmetriken, die Breite der Tabelle und die Anzahl der aktuellen Zeilen (sowie alle Vorhersagen über zukünftiges Wachstum) zu erfassen. Dies kann Ihnen eine gute Vorstellung davon geben, wie viel Speicherplatz ein neuer Index einnehmen wird, was je nach Ihrer Umgebung ein Problem darstellen kann. Ich kann dies in einem zukünftigen Beitrag behandeln.
Natürlich müssen Sie bedenken, dass diese Metriken nur so nützlich sind, wie es Ihre Betriebszeit erfordert. Die DMVs werden nach einem Neustart (und manchmal in anderen, weniger störenden Szenarien) gelöscht. Wenn Sie also der Meinung sind, dass diese Informationen über einen längeren Zeitraum nützlich sind, sollten Sie möglicherweise regelmäßige Snapshots erstellen.