Eine einfache Definition des Medians ist:
Der Median ist der mittlere Wert in einer sortierten Liste von ZahlenUm das ein wenig zu konkretisieren, können wir den Median einer Liste von Zahlen mit dem folgenden Verfahren ermitteln:
- Sortieren Sie die Nummern (in aufsteigender oder absteigender Reihenfolge, egal welche).
- Die mittlere Zahl (nach Position) in der sortierten Liste ist der Median.
- Wenn es zwei "gleich mittlere" Zahlen gibt, ist der Median der Durchschnitt der beiden mittleren Werte.
Aaron Bertrand hat zuvor mehrere Methoden zur Berechnung des Medians in SQL Server getestet:
- Wie kann der Median am schnellsten berechnet werden?
- Beste Ansätze für gruppierten Median
Rob Farley hat kürzlich einen weiteren Ansatz hinzugefügt, der auf Installationen vor 2012 abzielt:
- Mittelwerte vor SQL 2012
Dieser Artikel stellt eine neue Methode vor, die einen dynamischen Cursor verwendet.
Die OFFSET-FETCH-Methode von 2012
Wir beginnen mit der Betrachtung der leistungsstärksten Implementierung, die von Peter Larsson erstellt wurde. Es verwendet den OFFSET von SQL Server 2012 Erweiterung zu ORDER BY -Klausel, um effizient die eine oder zwei mittlere Zeilen zu lokalisieren, die zur Berechnung des Medians benötigt werden.
OFFSET einzelner Median
Aarons erster Artikel testete die Berechnung eines einzelnen Medians über eine Tabelle mit zehn Millionen Zeilen:
CREATE TABLE dbo.obj
(
id integer NOT NULL IDENTITY(1,1),
val integer NOT NULL
);
INSERT dbo.obj WITH (TABLOCKX)
(val)
SELECT TOP (10000000)
AO.[object_id]
FROM sys.all_columns AS AC
CROSS JOIN sys.all_objects AS AO
CROSS JOIN sys.all_objects AS AO2
WHERE AO.[object_id] > 0
ORDER BY
AC.[object_id];
CREATE UNIQUE CLUSTERED INDEX cx
ON dbo.obj(val, id);
Peter Larssons Lösung mit OFFSET Erweiterung ist:
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE @Count bigint = 10000000
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
SELECT
Median = AVG(1.0 * SQ1.val)
FROM
(
SELECT O.val
FROM dbo.obj AS O
ORDER BY O.val
OFFSET (@Count - 1) / 2 ROWS
FETCH NEXT 1 + (1 - @Count % 2) ROWS ONLY
) AS SQ1;
SELECT Peso = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME()); Der obige Code codiert das Ergebnis des Zählens der Zeilen in der Tabelle fest. Alle getesteten Methoden zur Berechnung des Medians benötigen diese Anzahl, um die mittleren Zeilennummern zu berechnen, es handelt sich also um konstante Kosten. Das Weglassen der Zeilenzähloperation aus dem Timing vermeidet eine mögliche Variationsquelle.
Der Ausführungsplan für OFFSET Lösung ist unten gezeigt:

Der Top-Operator überspringt schnell die unnötigen Zeilen und übergibt nur die ein oder zwei Zeilen, die zur Berechnung des Medians an das Stream-Aggregat benötigt werden. Bei Ausführung mit warmem Cache und deaktivierter Ausführungsplanerfassung wird diese Abfrage 910 ms ausgeführt im Durchschnitt auf meinem Laptop. Dies ist eine Maschine mit einem Intel i7 740QM-Prozessor mit 1,73 GHz und deaktiviertem Turbo (aus Konsistenzgründen).
OFFSET Gruppierter Median
Aarons zweiter Artikel testete die Leistung der Berechnung eines Medians pro Gruppe unter Verwendung einer Umsatztabelle mit einer Million Zeilen und zehntausend Einträgen für jeden von hundert Verkäufern:
CREATE TABLE dbo.Sales
(
SalesPerson integer NOT NULL,
Amount integer NOT NULL
);
WITH X AS
(
SELECT TOP (100)
V.number
FROM master.dbo.spt_values AS V
GROUP BY
V.number
)
INSERT dbo.Sales WITH (TABLOCKX)
(
SalesPerson,
Amount
)
SELECT
X.number,
ABS(CHECKSUM(NEWID())) % 99
FROM X
CROSS JOIN X AS X2
CROSS JOIN X AS X3;
CREATE CLUSTERED INDEX cx
ON dbo.Sales
(SalesPerson, Amount);
Auch hier verwendet die leistungsstärkste Lösung OFFSET :
DECLARE @s datetime2 = SYSUTCDATETIME();
DECLARE @Result AS table
(
SalesPerson integer PRIMARY KEY,
Median float NOT NULL
);
INSERT @Result
SELECT d.SalesPerson, w.Median
FROM
(
SELECT SalesPerson, COUNT(*) AS y
FROM dbo.Sales
GROUP BY SalesPerson
) AS d
CROSS APPLY
(
SELECT AVG(0E + Amount)
FROM
(
SELECT z.Amount
FROM dbo.Sales AS z WITH (PAGLOCK)
WHERE z.SalesPerson = d.SalesPerson
ORDER BY z.Amount
OFFSET (d.y - 1) / 2 ROWS
FETCH NEXT 2 - d.y % 2 ROWS ONLY
) AS f
) AS w(Median);
SELECT Peso = DATEDIFF(MILLISECOND, @s, SYSUTCDATETIME()); Der wichtige Teil des Ausführungsplans ist unten dargestellt:

In der obersten Zeile des Plans geht es darum, die Anzahl der Gruppenzeilen für jeden Vertriebsmitarbeiter zu ermitteln. Die untere Reihe verwendet dieselben Planelemente, die für die Einzelgruppen-Medianlösung zu sehen sind, um den Median für jeden Vertriebsmitarbeiter zu berechnen. Bei Ausführung mit warmem Cache und deaktivierten Ausführungsplänen wird diese Abfrage in 320 ms ausgeführt im Durchschnitt auf meinem Laptop.
Einen dynamischen Cursor verwenden
Es mag verrückt erscheinen, auch nur daran zu denken, einen Cursor zur Berechnung des Medians zu verwenden. Transact-SQL-Cursor haben den (größtenteils wohlverdienten) Ruf, langsam und ineffizient zu sein. Es wird auch oft angenommen, dass dynamische Cursor der schlechteste Cursortyp sind. Diese Punkte gelten unter bestimmten Umständen, aber nicht immer.
Transact-SQL-Cursor sind auf die gleichzeitige Verarbeitung einer einzelnen Zeile beschränkt, sodass sie tatsächlich langsam sein können, wenn viele Zeilen abgerufen und verarbeitet werden müssen. Bei der Berechnung des Medians ist dies jedoch nicht der Fall:Alles, was wir tun müssen, ist, effizient die ein oder zwei Mittelwerte zu finden und abzurufen . Wie wir sehen werden, ist ein dynamischer Cursor für diese Aufgabe sehr gut geeignet.
Dynamischer Cursor mit einzelnem Median
Die dynamische Cursorlösung für eine einzelne Medianberechnung besteht aus den folgenden Schritten:
- Erstellen Sie einen dynamischen scrollbaren Cursor über der geordneten Liste von Elementen.
- Berechnen Sie die Position der ersten Medianreihe.
- Positionieren Sie den Cursor mit
FETCH RELATIVEneu . - Entscheiden Sie, ob eine zweite Zeile benötigt wird, um den Median zu berechnen.
- Falls nicht, gib sofort den einzelnen Medianwert zurück.
- Andernfalls holen Sie sich den zweiten Wert mit
FETCH NEXT. - Berechnen Sie den Durchschnitt der beiden Werte und geben Sie zurück.
Beachten Sie, wie genau diese Liste das einfache Verfahren zum Ermitteln des Medians widerspiegelt, das am Anfang dieses Artikels angegeben ist. Eine vollständige Implementierung des Transact-SQL-Codes ist unten dargestellt:
-- Dynamic cursor
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE
@RowCount bigint, -- Total row count
@Row bigint, -- Median row number
@Amount1 integer, -- First amount
@Amount2 integer, -- Second amount
@Median float; -- Calculated median
SET @RowCount = 10000000;
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
DECLARE Median CURSOR
LOCAL
SCROLL
DYNAMIC
READ_ONLY
FOR
SELECT
O.val
FROM dbo.obj AS O
ORDER BY
O.val;
OPEN Median;
-- Calculate the position of the first median row
SET @Row = (@RowCount + 1) / 2;
-- Move to the row
FETCH RELATIVE @Row
FROM Median
INTO @Amount1;
IF @Row = (@RowCount + 2) / 2
BEGIN
-- No second row, median is the single value we have
SET @Median = @Amount1;
END
ELSE
BEGIN
-- Get the second row
FETCH NEXT
FROM Median
INTO @Amount2;
-- Calculate the median value from the two values
SET @Median = (@Amount1 + @Amount2) / 2e0;
END;
SELECT Median = @Median;
SELECT DynamicCur = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME());
Der Ausführungsplan für FETCH RELATIVE -Anweisung zeigt, wie der dynamische Cursor effizient in die erste Zeile positioniert wird, die für die Medianberechnung erforderlich ist:
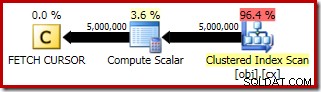
Der Plan für FETCH NEXT (nur erforderlich, wenn es eine zweite mittlere Zeile gibt, wie in diesen Tests) ist ein einzelner Zeilenabruf von der gespeicherten Position des Cursors:
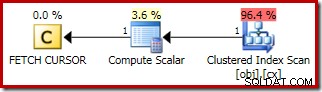
Die Vorteile der Verwendung eines dynamischen Cursors sind hier:
- Es vermeidet das Durchlaufen des gesamten Satzes (das Lesen stoppt, nachdem die mittleren Zeilen gefunden wurden); und
- Es wird keine temporäre Kopie der Daten in tempdb erstellt , wie es bei einem statischen oder Keyset-Cursor der Fall wäre.
Beachten Sie, dass wir keinen FAST_FORWARD angeben können Cursor hier (wobei die Wahl eines statischen oder dynamischen Plans dem Optimierer überlassen wird), da der Cursor scrollbar sein muss, um FETCH RELATIVE zu unterstützen . Dynamic ist hier sowieso die optimale Wahl.
Bei Ausführung mit warmem Cache und deaktivierter Ausführungsplanerfassung wird diese Abfrage 930 ms ausgeführt im Durchschnitt auf meiner Testmaschine. Dies ist etwas langsamer als die 910 ms für den OFFSET Lösung, aber der dynamische Cursor ist erheblich schneller als die anderen von Aaron und Rob getesteten Methoden und erfordert keinen SQL Server 2012 (oder höher).
Ich werde die anderen Methoden aus der Zeit vor 2012 hier nicht noch einmal testen, aber als Beispiel für die Größe der Leistungslücke benötigt die folgende Zeilennummerierungslösung 1550 ms im Durchschnitt (70 % langsamer):
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE @Count bigint = 10000000
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
SELECT AVG(1.0 * SQ1.val) FROM
(
SELECT
O.val,
rn = ROW_NUMBER() OVER (
ORDER BY O.val)
FROM dbo.obj AS O WITH (PAGLOCK)
) AS SQ1
WHERE
SQ1.rn BETWEEN (@Count + 1)/2 AND (@Count + 2)/2;
SELECT RowNumber = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME());

Gruppierter dynamischer Median-Cursor-Test
Es ist einfach, die dynamische Einzel-Median-Cursor-Lösung zu erweitern, um gruppierte Mediane zu berechnen. Aus Gründen der Konsistenz werde ich verschachtelte Cursor verwenden (ja, wirklich):
- Öffnen Sie einen statischen Cursor über den Verkäufern und der Zeilenanzahl.
- Berechnen Sie den Median für jede Person, indem Sie jedes Mal einen neuen dynamischen Cursor verwenden.
- Speichern Sie jedes Ergebnis in einer Tabellenvariablen, während wir fortfahren.
Der Code wird unten gezeigt:
-- Timing
DECLARE @s datetime2 = SYSUTCDATETIME();
-- Holds results
DECLARE @Result AS table
(
SalesPerson integer PRIMARY KEY,
Median float NOT NULL
);
-- Variables
DECLARE
@SalesPerson integer, -- Current sales person
@RowCount bigint, -- Current row count
@Row bigint, -- Median row number
@Amount1 float, -- First amount
@Amount2 float, -- Second amount
@Median float; -- Calculated median
-- Row counts per sales person
DECLARE SalesPersonCounts
CURSOR
LOCAL
FORWARD_ONLY
STATIC
READ_ONLY
FOR
SELECT
SalesPerson,
COUNT_BIG(*)
FROM dbo.Sales
GROUP BY SalesPerson
ORDER BY SalesPerson;
OPEN SalesPersonCounts;
-- First person
FETCH NEXT
FROM SalesPersonCounts
INTO @SalesPerson, @RowCount;
WHILE @@FETCH_STATUS = 0
BEGIN
-- Records for the current person
-- Note dynamic cursor
DECLARE Person CURSOR
LOCAL
SCROLL
DYNAMIC
READ_ONLY
FOR
SELECT
S.Amount
FROM dbo.Sales AS S
WHERE
S.SalesPerson = @SalesPerson
ORDER BY
S.Amount;
OPEN Person;
-- Calculate median row 1
SET @Row = (@RowCount + 1) / 2;
-- Move to median row 1
FETCH RELATIVE @Row
FROM Person
INTO @Amount1;
IF @Row = (@RowCount + 2) / 2
BEGIN
-- No second row, median is the single value
SET @Median = @Amount1;
END
ELSE
BEGIN
-- Get the second row
FETCH NEXT
FROM Person
INTO @Amount2;
-- Calculate the median value
SET @Median = (@Amount1 + @Amount2) / 2e0;
END;
-- Add the result row
INSERT @Result (SalesPerson, Median)
VALUES (@SalesPerson, @Median);
-- Finished with the person cursor
CLOSE Person;
DEALLOCATE Person;
-- Next person
FETCH NEXT
FROM SalesPersonCounts
INTO @SalesPerson, @RowCount;
END;
---- Results
--SELECT
-- R.SalesPerson,
-- R.Median
--FROM @Result AS R;
-- Tidy up
CLOSE SalesPersonCounts;
DEALLOCATE SalesPersonCounts;
-- Show elapsed time
SELECT NestedCur = DATEDIFF(MILLISECOND, @s, SYSUTCDATETIME()); Der äußere Cursor ist absichtlich statisch, da alle Zeilen in diesem Satz berührt werden (auch ein dynamischer Cursor ist aufgrund der Gruppierungsoperation in der zugrunde liegenden Abfrage nicht verfügbar). Diesmal gibt es in den Ausführungsplänen nichts besonders Neues oder Interessantes zu sehen.
Das Interessante ist die Leistung. Trotz der wiederholten Erstellung und Freigabe des inneren dynamischen Cursors funktioniert diese Lösung wirklich gut auf dem Testdatensatz. Wenn ein warmer Cache und Ausführungspläne deaktiviert sind, wird das Cursorskript in 330 ms abgeschlossen im Durchschnitt auf meiner Testmaschine. Dies ist wieder ein kleines bisschen langsamer als die 320 ms aufgezeichnet durch den OFFSET Gruppierter Median, aber es schlägt die anderen Standardlösungen, die in Aarons und Robs Artikeln aufgeführt sind, bei weitem.
Als Beispiel für den Leistungsunterschied zu den anderen Methoden, die nicht aus dem Jahr 2012 stammen, wird die folgende Zeilennummerierungslösung für 485 ms ausgeführt im Durchschnitt auf meinem Prüfstand (50 % schlechter):
DECLARE @s datetime2 = SYSUTCDATETIME();
DECLARE @Result AS table
(
SalesPerson integer PRIMARY KEY,
Median numeric(38, 6) NOT NULL
);
INSERT @Result
SELECT
S.SalesPerson,
CA.Median
FROM
(
SELECT
SalesPerson,
NumRows = COUNT_BIG(*)
FROM dbo.Sales
GROUP BY SalesPerson
) AS S
CROSS APPLY
(
SELECT AVG(1.0 * SQ1.Amount) FROM
(
SELECT
S2.Amount,
rn = ROW_NUMBER() OVER (
ORDER BY S2.Amount)
FROM dbo.Sales AS S2 WITH (PAGLOCK)
WHERE
S2.SalesPerson = S.SalesPerson
) AS SQ1
WHERE
SQ1.rn BETWEEN (S.NumRows + 1)/2 AND (S.NumRows + 2)/2
) AS CA (Median);
SELECT RowNumber = DATEDIFF(MILLISECOND, @s, SYSUTCDATETIME());

Ergebniszusammenfassung
Im Single-Median-Test lief der dynamische Cursor für 930 ms gegenüber 910 ms für den OFFSET Methode.
Im gruppierten Mediantest lief der verschachtelte Cursor für 330 ms gegenüber 320 ms für OFFSET .
In beiden Fällen war die Cursormethode deutlich schneller als die andere Nicht-OFFSET Methoden. Wenn Sie einen einzelnen oder gruppierten Median auf einer Instanz vor 2012 berechnen müssen, könnte ein dynamischer Cursor oder ein verschachtelter Cursor wirklich die optimale Wahl sein.
Cold-Cache-Leistung
Einige von Ihnen wundern sich vielleicht über die Cold-Cache-Leistung. Führen Sie vor jedem Test Folgendes aus:
CHECKPOINT; DBCC DROPCLEANBUFFERS;
Dies sind die Ergebnisse für den Single-Median-Test:
OFFSET Methode:940 ms
Dynamischer Cursor:955 ms
Für den gruppierten Median:
OFFSET Methode:380 ms
Verschachtelte Cursor:385 ms
Abschließende Gedanken
Die dynamischen Cursorlösungen sind wirklich erheblich schneller als die Nicht-OFFSET Methoden sowohl für einzelne als auch für gruppierte Mediane, zumindest mit diesen Beispieldatensätzen. Ich habe mich bewusst dafür entschieden, Aarons Testdaten wiederzuverwenden, damit die Datensätze nicht absichtlich in Richtung des dynamischen Cursors verschoben wurden. Es vielleicht andere Datenverteilungen sein, für die der dynamische Cursor keine gute Option ist. Dennoch zeigt es, dass es immer noch Zeiten gibt, in denen ein Cursor eine schnelle und effiziente Lösung für die richtige Art von Problem sein kann. Sogar dynamische und verschachtelte Cursor.
Scharfäugigen Lesern ist vielleicht das PAGLOCK aufgefallen Hinweis im OFFSET Gruppierter Mediantest. Dies ist für die beste Leistung erforderlich, aus Gründen, die ich in meinem nächsten Artikel behandeln werde. Ohne sie verliert die Lösung von 2012 gegenüber dem verschachtelten Cursor tatsächlich mit einem anständigen Vorsprung (590 ms gegenüber 330 ms ).