Auf dem PASS Summit vor einigen Wochen hat Microsoft CTP2.1 von SQL Server 2019 veröffentlicht, und eine der großen Funktionserweiterungen, die im CTP enthalten sind, ist Scalar UDF Inlining. Vor dieser Version wollte ich mit dem Leistungsunterschied zwischen dem Inlining von skalaren UDFs und der RBAR-Ausführung (row-by-agonizing-row) von skalaren UDFs in früheren Versionen von SQL Server herumspielen und bin auf eine Syntaxoption für die FUNKTION ERSTELLEN Anweisung in der SQL Server-Onlinedokumentation, die ich noch nie zuvor gesehen hatte.
Die DDL für CREATE FUNCTION unterstützt eine WITH-Klausel für Funktionsoptionen, und beim Lesen der Online-Dokumentation ist mir aufgefallen, dass die Syntax Folgendes enthält:
-- Transact-SQL Function Clauses
<function_option>::=
{
[ ENCRYPTION ]
| [ SCHEMABINDING ]
| [ RETURNS NULL ON NULL INPUT | CALLED ON NULL INPUT ]
| [ EXECUTE_AS_Clause ]
} Ich war wirklich neugierig auf RETURNS NULL ON NULL INPUT Funktionsoption, also beschloss ich, einige Tests durchzuführen. Ich war sehr überrascht, als ich herausfand, dass es sich tatsächlich um eine Form der skalaren UDF-Optimierung handelt, die mindestens seit SQL Server 2008 R2 im Produkt enthalten ist.
Es stellt sich heraus, dass, wenn Sie wissen, dass eine skalare UDF immer ein NULL-Ergebnis zurückgibt, wenn eine NULL-Eingabe bereitgestellt wird, die UDF IMMER mit RETURNS NULL ON NULL INPUT erstellt werden sollte Option, da SQL Server dann die Funktionsdefinition überhaupt nicht für Zeilen ausführt, in denen die Eingabe NULL ist – was sie effektiv kurzschließt und die verschwendete Ausführung des Funktionskörpers vermeidet.
Um Ihnen dieses Verhalten zu zeigen, verwende ich eine SQL Server 2017-Instanz, auf die das neueste kumulative Update angewendet wurde, und AdventureWorks2017 Datenbank von GitHub (Sie können sie hier herunterladen), die mit einem dbo.ufnLeadingZeros ausgeliefert wird Funktion, die dem Eingabewert einfach führende Nullen hinzufügt und eine Zeichenfolge mit acht Zeichen zurückgibt, die diese führenden Nullen enthält. Ich werde eine neue Version dieser Funktion erstellen, die RETURNS NULL ON NULL INPUT enthält Option, damit ich sie mit der ursprünglichen Funktion für die Ausführungsleistung vergleichen kann.
USE [AdventureWorks2017];
GO
CREATE FUNCTION [dbo].[ufnLeadingZeros_new](
@Value int
)
RETURNS varchar(8)
WITH SCHEMABINDING, RETURNS NULL ON NULL INPUT
AS
BEGIN
DECLARE @ReturnValue varchar(8);
SET @ReturnValue = CONVERT(varchar(8), @Value);
SET @ReturnValue = REPLICATE('0', 8 - DATALENGTH(@ReturnValue)) + @ReturnValue;
RETURN (@ReturnValue);
END;
GO Um die Unterschiede in der Ausführungsleistung innerhalb der Datenbank-Engine der beiden Funktionen zu testen, habe ich mich entschieden, eine Sitzung für erweiterte Ereignisse auf dem Server zu erstellen, um das sqlserver.module_end zu verfolgen -Ereignis, das am Ende jeder Ausführung der skalaren UDF für jede Zeile ausgelöst wird. Dadurch konnte ich die zeilenweise Verarbeitungssemantik demonstrieren und auch nachverfolgen, wie oft die Funktion während des Tests tatsächlich aufgerufen wurde. Ich habe mich entschieden, auch sql_batch_completed zu sammeln und sql_statement_completed Ereignisse und filtern Sie alles nach session_id um sicherzustellen, dass ich nur Informationen zu der Sitzung erfasst habe, in der ich die Tests tatsächlich ausgeführt habe (wenn Sie diese Ergebnisse replizieren möchten, müssen Sie die 74 an allen Stellen im folgenden Code in die Sitzungs-ID Ihres Tests ändern Code wird ausgeführt). Die Ereignissitzung verwendet TRACK_CAUSALITY so dass es einfach ist, zu zählen, wie viele Ausführungen der Funktion durch die activity_id.seq_no erfolgt sind Wert für die Ereignisse (der sich für jedes Ereignis, das die session_id erfüllt, um eins erhöht Filter).
CREATE EVENT SESSION [Session72] ON SERVER ADD EVENT sqlserver.module_end( WHERE ([package0].[equal_uint64]([sqlserver].[session_id],(74)))), ADD EVENT sqlserver.sql_batch_completed( WHERE ([package0].[equal_uint64]([sqlserver].[session_id],(74)))), ADD EVENT sqlserver.sql_batch_starting( WHERE ([package0].[equal_uint64]([sqlserver].[session_id],(74)))), ADD EVENT sqlserver.sql_statement_completed( WHERE ([package0].[equal_uint64]([sqlserver].[session_id],(74)))), ADD EVENT sqlserver.sql_statement_starting( WHERE ([package0].[equal_uint64]([sqlserver].[session_id],(74)))) WITH (TRACK_CAUSALITY=ON) GO
Nachdem ich die Ereignissitzung gestartet und den Live Data Viewer in Management Studio geöffnet hatte, führte ich zwei Abfragen aus; eine, die die Originalversion der Funktion verwendet, um die CurrencyRateID mit Nullen aufzufüllen Spalte im Sales.SalesOrderHeader Tabelle und die neue Funktion, um die identische Ausgabe zu erzeugen, aber unter Verwendung von RETURNS NULL ON NULL INPUT Option, und ich habe die Informationen zum tatsächlichen Ausführungsplan zum Vergleich erfasst.
SELECT SalesOrderID, dbo.ufnLeadingZeros(CurrencyRateID) FROM Sales.SalesOrderHeader; GO SELECT SalesOrderID, dbo.ufnLeadingZeros_new(CurrencyRateID) FROM Sales.SalesOrderHeader; GO
Die Überprüfung der Daten der erweiterten Ereignisse zeigte einige interessante Dinge. Erstens wurde die ursprüngliche Funktion 31.465 Mal ausgeführt (ab der Zählung von module_end Ereignisse) und die gesamte CPU-Zeit für sql_statement_completed Das Ereignis dauerte 204 ms mit einer Dauer von 482 ms.
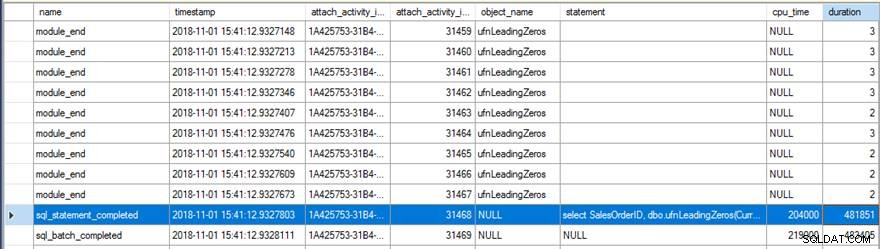
Die neue Version mit dem RETURNS NULL ON NULL INPUT Die angegebene Option wurde nur 13.976 Mal ausgeführt (wieder ausgehend von der Zählung von module_end Ereignisse) und die CPU-Zeit für sql_statement_completed Das Ereignis dauerte 78 ms mit einer Dauer von 359 ms.

Ich fand das interessant, also habe ich zur Überprüfung der Ausführungszähler die folgende Abfrage ausgeführt, um NOT NULL zu zählen Wertzeilen, NULL-Wertzeilen und Gesamtzeilen in Sales.SalesOrderHeader Tabelle.
SELECT SUM(CASE WHEN CurrencyRateID IS NOT NULL THEN 1 ELSE 0 END) AS NOTNULL, SUM(CASE WHEN CurrencyRateID IS NULL THEN 1 ELSE 0 END) AS NULLVALUE, COUNT(*) FROM Sales.SalesOrderHeader;
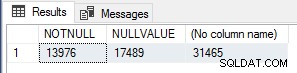
Diese Nummern entsprechen genau der Nummer von module_end Ereignisse für jeden der Tests, daher ist dies definitiv eine sehr einfache Leistungsoptimierung für skalare UDFs, die verwendet werden sollte, wenn Sie wissen, dass das Ergebnis der Funktion NULL ist, wenn die Eingabewerte NULL sind, um die Ausführung der Funktion kurzzuschließen/zu umgehen ausschließlich für diese Zeilen.
Die QueryTimeStats-Informationen in den tatsächlichen Ausführungsplänen spiegelten auch die Leistungssteigerungen wider:
<QueryTimeStats CpuTime="204" ElapsedTime="482" UdfCpuTime="160" UdfElapsedTime="218" /> <QueryTimeStats CpuTime="78" ElapsedTime="359" UdfCpuTime="52" UdfElapsedTime="64" />
Dies ist eine ziemlich erhebliche Reduzierung der CPU-Zeit, was für einige Systeme ein erheblicher Schmerzpunkt sein kann.
Die Verwendung von skalaren UDFs ist ein bekanntes Design-Antimuster für die Leistung, und es gibt eine Vielzahl von Methoden zum Umschreiben des Codes, um deren Verwendung und Leistungseinbußen zu vermeiden. Wenn sie jedoch bereits vorhanden sind und nicht einfach geändert oder entfernt werden können, erstellen Sie einfach die UDF mit RETURNS NULL ON NULL INPUT neu Die Option könnte eine sehr einfache Möglichkeit sein, die Leistung zu verbessern, wenn es viele NULL-Eingaben im gesamten Datensatz gibt, in dem die UDF verwendet wird.