Im Januar 2015 schrieb mein guter Freund und Kollege Rob Farley, MVP von SQL Server, über eine neuartige Lösung für das Problem, den Median in SQL Server-Versionen vor 2012 zu finden ein großartiges Beispiel, um eine erweiterte Ausführungsplananalyse zu demonstrieren und einige subtile Verhaltensweisen des Abfrageoptimierers und der Ausführungsengine hervorzuheben.
Einzelner Median
Obwohl Robs Artikel speziell auf eine gruppierte Medianberechnung abzielt, werde ich damit beginnen, seine Methode auf ein großes einzelnes Medianberechnungsproblem anzuwenden, da sie die wichtigen Probleme am deutlichsten hervorhebt. Die Beispieldaten stammen wieder aus dem ursprünglichen Artikel von Aaron Bertrand:
CREATE TABLE dbo.obj
(
id integer NOT NULL IDENTITY(1,1),
val integer NOT NULL
);
INSERT dbo.obj WITH (TABLOCKX)
(val)
SELECT TOP (10000000)
AO.[object_id]
FROM sys.all_columns AS AC
CROSS JOIN sys.all_objects AS AO
CROSS JOIN sys.all_objects AS AO2
WHERE AO.[object_id] > 0
ORDER BY
AC.[object_id];
CREATE UNIQUE CLUSTERED INDEX cx
ON dbo.obj(val, id); Die Anwendung von Rob Farleys Technik auf dieses Problem ergibt den folgenden Code:
-- 5800ms
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE @Count bigint = 10000000
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
SELECT
Median = AVG(0E + f.val)
FROM
(
SELECT TOP (2 - @Count % 2)
t.val
FROM
(
SELECT TOP (@Count / 2 + 1)
z.val
FROM dbo.obj AS z
ORDER BY
z.val ASC
) AS t
ORDER BY
t.val DESC
) AS f;
SELECT RF = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME()); Wie üblich habe ich das Zählen der Anzahl der Zeilen in der Tabelle auskommentiert und durch eine Konstante ersetzt, um eine Quelle für Leistungsabweichungen zu vermeiden. Der Ausführungsplan für die wichtige Abfrage lautet wie folgt:

Diese Abfrage wird 5800 ms ausgeführt auf meiner Testmaschine.
Der Sort Spill
Der Hauptgrund für diese schlechte Leistung sollte aus dem obigen Ausführungsplan ersichtlich sein:Die Warnung für den Sort-Operator zeigt, dass eine unzureichende Gewährung des Arbeitsbereichsspeichers einen Überlauf der Ebene 2 (Multi-Pass) in die physische tempdb Festplatte:
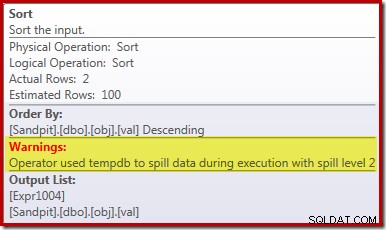
In Versionen von SQL Server vor 2012 müssten Sie separat auf Sortierüberlaufereignisse überwachen, um dies zu sehen. Jedenfalls wird die unzureichende Sortierspeicherreservierung durch einen Kardinalitätsschätzungsfehler verursacht, wie der (geschätzte) Plan vor der Ausführung zeigt:

Die 100-Zeilen-Kardinalitätsschätzung an der Sort-Eingabe ist eine (völlig ungenaue) Schätzung des Optimierers, aufgrund des lokalen Variablenausdrucks im vorangehenden Top-Operator:

Beachten Sie, dass dieser Kardinalitätsschätzungsfehler kein Zeilenzielproblem ist. Durch Anwenden des Ablaufverfolgungsflags 4138 wird der Zeilenzieleffekt unter dem ersten Top entfernt, aber die Post-Top-Schätzung wird immer noch eine 100-Zeilen-Schätzung sein (daher ist die Speicherreservierung für die Sortierung immer noch viel zu klein):

Hinweis auf den Wert der lokalen Variablen
Es gibt mehrere Möglichkeiten, wie wir dieses Problem der Kardinalitätsschätzung lösen könnten. Eine Möglichkeit besteht darin, einen Hinweis zu verwenden, um dem Optimierer Informationen über den in der Variablen enthaltenen Wert bereitzustellen:
-- 3250ms
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE @Count bigint = 10000000
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
SELECT
Median = AVG(0E + f.val)
FROM
(
SELECT TOP (2 - @Count % 2)
t.val
FROM
(
SELECT TOP (@Count / 2 + 1)
z.val
FROM dbo.obj AS z
ORDER BY
z.val ASC
) AS t
ORDER BY
t.val DESC
) AS f
OPTION (MAXDOP 1, OPTIMIZE FOR (@Count = 11000000)); -- NEW!
SELECT RF = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME()); Durch die Verwendung des Hinweises wird die Leistung auf 3250 ms verbessert ab 5800ms. Der Plan nach der Ausführung zeigt, dass die Sortierung nicht mehr verschüttet wird:

Es gibt jedoch ein paar Nachteile. Erstens erfordert dieser neue Ausführungsplan 388 MB Speicherzuteilung – Speicher, der ansonsten vom Server zum Zwischenspeichern von Plänen, Indizes und Daten verwendet werden könnte:
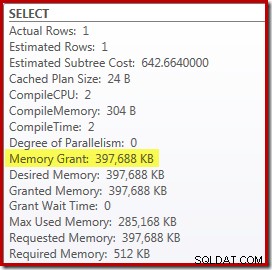
Zweitens kann es schwierig sein, eine gute Zahl für den Hinweis zu wählen, die für alle zukünftigen Ausführungen gut funktioniert, ohne unnötig Speicher zu reservieren.
Beachten Sie auch, dass wir einen Wert für die Variable angeben mussten, der 10 % höher ist als der tatsächliche Wert der Variablen, um den Überlauf vollständig zu beseitigen. Dies ist nicht ungewöhnlich, da der allgemeine Sortieralgorithmus etwas komplexer ist als eine einfache In-Place-Sortierung. Das Reservieren von Speicher gleich der Größe des zu sortierenden Satzes wird nicht immer (oder sogar im Allgemeinen) ausreichen, um einen Überlauf zur Laufzeit zu vermeiden.
Einbetten und Neukompilieren
Eine weitere Option besteht darin, die Parametereinbettungsoptimierung zu nutzen, die durch Hinzufügen eines Neukompilierungshinweises auf Abfrageebene in SQL Server 2008 SP1 CU5 oder höher aktiviert wird. Diese Aktion ermöglicht es dem Optimierer, den Laufzeitwert der Variablen zu sehen und entsprechend zu optimieren:
-- 3150ms
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE @Count bigint = 10000000
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
SELECT
Median = AVG(0E + f.val)
FROM
(
SELECT TOP (2 - @Count % 2)
t.val
FROM
(
SELECT TOP (@Count / 2 + 1)
z.val
FROM dbo.obj AS z
ORDER BY
z.val ASC
) AS t
ORDER BY
t.val DESC
) AS f
OPTION (MAXDOP 1, RECOMPILE);
SELECT RF = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME());
Dadurch wird die Ausführungszeit auf 3150 ms verbessert – 100 ms besser als die Verwendung von OPTIMIZE FOR Hinweis. Der Grund für diese weitere kleine Verbesserung ist dem neuen Post-Execution-Plan zu entnehmen:

Der Ausdruck (2 – @Count % 2) – wie zuvor im zweiten Top-Operator zu sehen – kann nun auf einen einzigen bekannten Wert heruntergeklappt werden. Ein Neuschreiben nach der Optimierung kann dann das Top mit dem Sort kombinieren, was zu einem einzigen Top-N-Sort führt. Diese Umschreibung war zuvor nicht möglich, da das Zusammenfassen von Top + Sort in Top N Sort nur mit einem konstanten Top-Literalwert (nicht Variablen oder Parametern) funktioniert.
Das Ersetzen von Top und Sort durch ein Top N Sort hat einen kleinen positiven Effekt auf die Leistung (hier 100 ms), aber es eliminiert auch fast vollständig den Speicherbedarf, da ein Top N Sort nur die N höchsten (oder niedrigsten) verfolgen muss. Zeilen, und nicht den ganzen Satz. Aufgrund dieser Änderung des Algorithmus zeigt der Nachausführungsplan für diese Abfrage, dass das Minimum 1 MB beträgt Speicher wurde in diesem Plan für die Top-N-Sortierung reserviert, und zwar nur 16 KB wurde zur Laufzeit verwendet (denken Sie daran, dass der Full-Sort-Plan 388 MB benötigte):
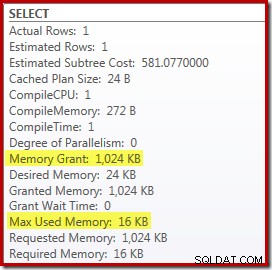
Neukompilierung vermeiden
Der (offensichtliche) Nachteil der Verwendung des Recompile-Abfragehinweises besteht darin, dass bei jeder Ausführung eine vollständige Kompilierung erforderlich ist. In diesem Fall ist der Overhead ziemlich gering – etwa 1 ms CPU-Zeit und 272 KB Speicher. Trotzdem gibt es eine Möglichkeit, die Abfrage so zu optimieren, dass wir die Vorteile einer Top-N-Sortierung nutzen, ohne irgendwelche Hinweise zu verwenden und ohne neu zu kompilieren.
Die Idee kommt von der Erkenntnis, dass ein Maximum von zwei Zeilen werden für die endgültige Medianberechnung benötigt. Es kann eine Zeile sein, oder es können zwei zur Laufzeit sein, aber es kann nie mehr sein. Diese Erkenntnis bedeutet, dass wir der Abfrage einen logisch redundanten Zwischenschritt Top (2) wie folgt hinzufügen können:
-- 3150ms
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE @Count bigint = 10000000
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
SELECT
Median = AVG(0E + f.val)
FROM
(
SELECT TOP (2 - @Count % 2)
t.val
FROM
(
SELECT TOP (2) -- NEW!
z.val
FROM
(
SELECT TOP (@Count / 2 + 1)
z.val
FROM dbo.obj AS z
ORDER BY
z.val ASC
) AS z
ORDER BY z.val DESC
) AS t
ORDER BY
t.val DESC
) AS f
OPTION (MAXDOP 1);
SELECT RF = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME()); Das neue Top (mit dem überaus wichtigen konstanten Literal) bedeutet, dass der endgültige Ausführungsplan den gewünschten Top-N-Sort-Operator ohne Neukompilierung enthält:

Die Leistung dieses Ausführungsplans ist gegenüber der Version mit Hinweisen zur Neukompilierung bei 3150 ms unverändert und der Speicherbedarf ist der gleiche. Beachten Sie jedoch, dass das Fehlen der Parametereinbettung bedeutet, dass die Kardinalitätsschätzungen unterhalb der Sortierung 100-Zeilen-Schätzungen sind (obwohl dies hier keine Auswirkungen auf die Leistung hat).
Die wichtigste Erkenntnis in dieser Phase ist, dass Sie, wenn Sie eine Top-N-Sortierung mit geringem Speicher wünschen, ein konstantes Literal verwenden oder es dem Optimierer ermöglichen müssen, ein Literal über die Parametereinbettungsoptimierung zu sehen.
Der Rechenskalar
Wegfall der 388 MB Die Speicherzuweisung (bei gleichzeitiger Leistungssteigerung von 100 ms) lohnt sich sicherlich, aber es steht ein viel größerer Leistungsgewinn zur Verfügung. Das unwahrscheinliche Ziel dieser letzten Verbesserung ist der Compute Scalar direkt über dem Clustered Index Scan.
Dieser Compute Scalar bezieht sich auf den Ausdruck (0E + f.val) im AVG enthalten Aggregat in der Abfrage. Falls Ihnen das komisch vorkommt, dies ist ein ziemlich verbreiteter Trick beim Schreiben von Abfragen (wie das Multiplizieren mit 1,0), um die ganzzahlige Arithmetik in der Durchschnittsberechnung zu vermeiden, aber er hat einige sehr wichtige Nebeneffekte.
Hier gibt es eine bestimmte Abfolge von Ereignissen, die wir Schritt für Schritt befolgen müssen.
Beachten Sie zuerst, dass 0E ist eine konstante wörtliche Null mit einem float Datentyp. Um dies zu der Integer-Spalte val hinzuzufügen, muss der Abfrageprozessor die Spalte von Integer in Float umwandeln (in Übereinstimmung mit den Datentyp-Vorrangregeln). Eine ähnliche Konvertierung wäre notwendig, wenn wir die Spalte mit 1,0 multipliziert hätten (ein Literal mit einem impliziten numerischen Datentyp). Der wichtige Punkt ist, dass dieser Routinetrick einen Ausdruck einführt .
Nun versucht SQL Server im Allgemeinen, Ausdrücke nach unten zu verschieben den Planbaum während der Kompilierung und Optimierung so weit wie möglich. Dies geschieht aus mehreren Gründen, unter anderem um das Abgleichen von Ausdrücken mit berechneten Spalten zu vereinfachen und Vereinfachungen mithilfe von Einschränkungsinformationen zu erleichtern. Diese Pushdown-Richtlinie erklärt, warum der Compute-Skalar viel näher an der Blattebene des Plans erscheint, als die ursprüngliche Textposition des Ausdrucks in der Abfrage vermuten lässt.
Ein Risiko bei der Durchführung dieses Pushdowns besteht darin, dass der Ausdruck möglicherweise öfter als nötig berechnet wird. Die meisten Pläne weisen aufgrund der Auswirkung von Verknüpfungen, Aggregation und Filtern eine abnehmende Zeilenanzahl auf, wenn wir uns in der Planstruktur nach oben bewegen. Das Verschieben von Ausdrücken im Baum nach unten birgt daher das Risiko, dass diese Ausdrücke öfter (d. h. in mehr Zeilen) als nötig ausgewertet werden.
Um dies abzumildern, führte SQL Server 2005 eine Optimierung ein, bei der Compute Scalars einfach definieren können ein Ausdruck, mit der Arbeit des eigentlichen Evaluierens der Ausdruck verzögert bis ein späterer Operator im Plan das Ergebnis benötigt. Wenn diese Optimierung wie beabsichtigt funktioniert, besteht der Effekt darin, alle Vorteile des Verschiebens von Ausdrücken in der Baumstruktur zu nutzen, während der Ausdruck immer noch nur so oft wie tatsächlich benötigt ausgewertet wird.
Was all dieses Compute Scalar-Zeug bedeutet
In unserem laufenden Beispiel der 0E + val Ausdruck war ursprünglich mit AVG verknüpft aggregiert, so dass wir erwarten können, es bei (oder kurz nach) dem Stream Aggregate zu sehen. Dieser Ausdruck wurde jedoch nach unten gedrückt Der Baum wird direkt nach dem Scan zu einem neuen Compute-Skalar mit dem als [Expr1004] bezeichneten Ausdruck.
Wenn wir uns den Ausführungsplan ansehen, können wir sehen, dass [Expr1004] durch das Stream-Aggregat referenziert wird (Auszug der Registerkarte "Ausdrücke des Plan-Explorers" unten gezeigt):

Wenn alle Dinge gleich sind, würde die Auswertung des Ausdrucks [Expr1004] verzögert werden bis das Aggregat diese Werte für den Summenteil der Durchschnittsberechnung benötigt. Da das Aggregat immer nur auf eine oder zwei Zeilen treffen kann, sollte dies dazu führen, dass [Expr1004] nur ein- oder zweimal ausgewertet wird:
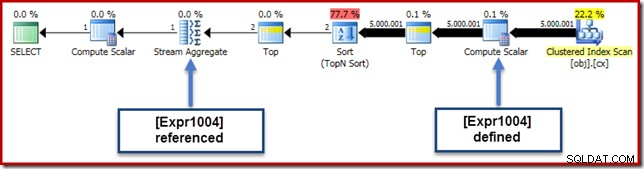
Leider funktioniert das hier nicht ganz so. Das Problem ist der blockierende Sort-Operator:
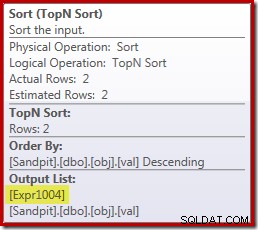
Dies erzwingt die Auswertung von [Expr1004]. Anstatt also nur ein- oder zweimal im Stream Aggregate ausgewertet zu werden, bedeutet Sort, dass wir am Ende den val konvertieren -Spalte in einen Float und Hinzufügen von Null 5.000.001 Mal!
Ein Workaround
Im Idealfall wäre SQL Server bei all dem etwas klüger, aber so funktioniert es heute nicht. Es gibt keinen Abfragehinweis, um zu verhindern, dass Ausdrücke in der Planstruktur nach unten verschoben werden, und wir können die Berechnung von Skalaren auch nicht mit einem Planleitfaden erzwingen. Es gibt zwangsläufig ein undokumentiertes Trace-Flag, aber es ist eines, über das ich im vorliegenden Kontext nicht verantwortungsvoll sprechen kann.
Auf Gedeih und Verderb müssen wir also versuchen, eine Abfrageumschreibung zu finden, die verhindert, dass SQL Server den Ausdruck vom Aggregat trennt und ihn über die Sortierung hinaus nach unten schiebt, ohne das Ergebnis der Abfrage zu ändern. Das ist nicht so einfach, wie Sie vielleicht denken, aber die (zugegebenermaßen etwas seltsam aussehende) Modifikation unten erreicht dies mit einem CASE Ausdruck auf einer nicht-deterministischen intrinsischen Funktion:
-- 2150ms
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE @Count bigint = 10000000
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
SELECT
-- NEW!
Median = AVG(CASE WHEN GETDATE() >= {D '1753-01-01'} THEN 0E + f.val END)
FROM
(
SELECT TOP (2 - @Count % 2)
t.val
FROM
(
SELECT TOP (2)
z.val
FROM
(
SELECT TOP (@Count / 2 + 1)
z.val
FROM dbo.obj AS z
ORDER BY
z.val ASC
) AS z
ORDER BY z.val DESC
) AS t
ORDER BY
t.val DESC
) AS f
OPTION (MAXDOP 1);
SELECT RF = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME()); Der Ausführungsplan für diese letzte Form der Abfrage ist unten dargestellt:

Beachten Sie, dass zwischen dem Clustered Index Scan und Top kein Compute Scalar mehr angezeigt wird. Der 0E + val -Ausdruck wird jetzt beim Stream Aggregate auf maximal zwei Zeilen (statt fünf Millionen!) berechnet und die Leistung steigt um weitere 32 % von 3150 ms auf 2150 ms als Ergebnis.
Dies ist immer noch nicht so gut vergleichbar mit der Subsekundenleistung des OFFSET und dynamische Cursor-Median-Berechnungslösungen, aber es stellt immer noch eine sehr signifikante Verbesserung gegenüber den ursprünglichen 5800 ms dar für diese Methode auf einem großen Single-Median-Problemsatz.
Der CASE-Trick funktioniert natürlich nicht garantiert in der Zukunft. Es geht nicht so sehr um die Verwendung seltsamer Tricks für Groß- und Kleinschreibung, sondern um die potenziellen Auswirkungen von Compute Scalars auf die Leistung. Sobald Sie über diese Art von Dingen Bescheid wissen, überlegen Sie es sich vielleicht zweimal, bevor Sie mit 1,0 multiplizieren oder Float-Null in eine Durchschnittsberechnung einfügen.
Aktualisierung: Bitte lesen Sie den ersten Kommentar für eine nette Problemumgehung von Robert Heinig, die keine undokumentierten Tricks erfordert. Etwas, das Sie bedenken sollten, wenn Sie das nächste Mal versucht sind, eine Ganzzahl mit einer Dezimalzahl (oder Gleitkommazahl) in einem durchschnittlichen Aggregat zu multiplizieren.
Gruppierter Median
Der Vollständigkeit halber und um diese Analyse enger mit Robs ursprünglichem Artikel zu verknüpfen, wenden wir zum Abschluss die gleichen Verbesserungen auf eine Berechnung des gruppierten Medians an. Die kleineren Set-Größen (pro Gruppe) bedeuten natürlich geringere Effekte.
Die gruppierten Median-Beispieldaten (wieder ursprünglich von Aaron Bertrand erstellt) umfassen zehntausend Zeilen für jeden von hundert imaginären Verkäufern:
CREATE TABLE dbo.Sales
(
SalesPerson integer NOT NULL,
Amount integer NOT NULL
);
WITH X AS
(
SELECT TOP (100)
V.number
FROM master.dbo.spt_values AS V
GROUP BY
V.number
)
INSERT dbo.Sales WITH (TABLOCKX)
(
SalesPerson,
Amount
)
SELECT
X.number,
ABS(CHECKSUM(NEWID())) % 99
FROM X
CROSS JOIN X AS X2
CROSS JOIN X AS X3;
CREATE CLUSTERED INDEX cx
ON dbo.Sales
(SalesPerson, Amount); Die direkte Anwendung der Lösung von Rob Farley ergibt den folgenden Code, der in 560 ms ausgeführt wird auf meinem Rechner.
-- 560ms Original
DECLARE @s datetime2 = SYSUTCDATETIME();
SELECT
d.SalesPerson,
w.Median
FROM
(
SELECT S.SalesPerson, COUNT_BIG(*) AS y
FROM dbo.Sales AS S
GROUP BY S.SalesPerson
) AS d
CROSS APPLY
(
SELECT AVG(0E + f.Amount)
FROM
(
SELECT TOP (2 - d.y % 2)
t.Amount
FROM
(
SELECT TOP (d.y / 2 + 1)
z.Amount
FROM dbo.Sales AS z
WHERE z.SalesPerson = d.SalesPerson
ORDER BY z.Amount ASC
) AS t
ORDER BY t.Amount DESC
) AS f
) AS w (Median)
OPTION (MAXDOP 1);
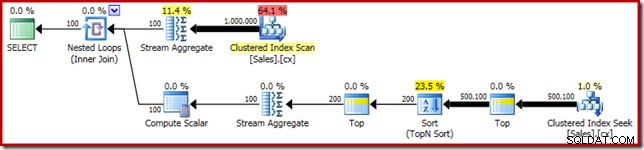
SELECT DATEDIFF(MILLISECOND, @s, SYSUTCDATETIME()); Der Ausführungsplan hat offensichtliche Ähnlichkeiten mit dem einzelnen Median:
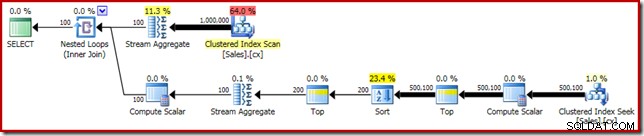
Unsere erste Verbesserung besteht darin, Sort durch Top N Sort zu ersetzen, indem wir ein explizites Top (2) hinzufügen. Dadurch wird die Ausführungszeit leicht von 560 ms auf 550 ms verbessert .
-- 550ms
DECLARE @s datetime2 = SYSUTCDATETIME();
SELECT
d.SalesPerson,
w.Median
FROM
(
SELECT S.SalesPerson, COUNT_BIG(*) AS y
FROM dbo.Sales AS S
GROUP BY S.SalesPerson
) AS d
CROSS APPLY
(
SELECT AVG(0E + f.Amount)
FROM
(
SELECT TOP (2 - d.y % 2)
q.Amount
FROM
(
-- NEW!
SELECT TOP (2) t.Amount
FROM
(
SELECT TOP (d.y / 2 + 1)
z.Amount
FROM dbo.Sales AS z
WHERE z.SalesPerson = d.SalesPerson
ORDER BY z.Amount ASC
) AS t
ORDER BY t.Amount DESC
) AS q
ORDER BY q.Amount DESC
) AS f
) AS w (Median)
OPTION (MAXDOP 1);
SELECT DATEDIFF(MILLISECOND, @s, SYSUTCDATETIME()); Der Ausführungsplan zeigt die Top-N-Sortierung wie erwartet:
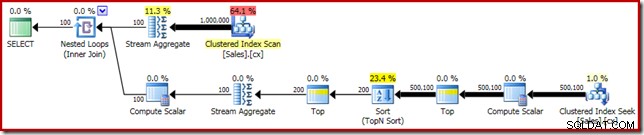
Schließlich setzen wir den seltsam aussehenden CASE-Ausdruck ein, um den gepushten Compute Scalar-Ausdruck zu entfernen. Dadurch wird die Leistung weiter auf 450 ms verbessert (eine Verbesserung von 20 % gegenüber dem Original):
-- 450ms
DECLARE @s datetime2 = SYSUTCDATETIME();
SELECT
d.SalesPerson,
w.Median
FROM
(
SELECT S.SalesPerson, COUNT_BIG(*) AS y
FROM dbo.Sales AS S
GROUP BY S.SalesPerson
) AS d
CROSS APPLY
(
-- NEW!
SELECT AVG(CASE WHEN GETDATE() >= {D '1753-01-01'} THEN 0E + Amount END)
FROM
(
SELECT TOP (2 - d.y % 2)
q.Amount
FROM
(
SELECT TOP (2) t.Amount
FROM
(
SELECT TOP (d.y / 2 + 1)
z.Amount
FROM dbo.Sales AS z
WHERE z.SalesPerson = d.SalesPerson
ORDER BY z.Amount ASC
) AS t
ORDER BY t.Amount DESC
) AS q
ORDER BY q.Amount DESC
) AS f
) AS w (Median)
OPTION (MAXDOP 1);
SELECT DATEDIFF(MILLISECOND, @s, SYSUTCDATETIME()); Der fertige Ausführungsplan sieht wie folgt aus: