Anfang dieses Monats habe ich einen Tipp zu etwas veröffentlicht, von dem wir wahrscheinlich alle wünschen, dass wir es nicht tun müssten:Sortieren oder Entfernen von Duplikaten aus getrennten Zeichenfolgen, normalerweise mit benutzerdefinierten Funktionen (UDFs). Manchmal müssen Sie die Liste (ohne die Duplikate) in alphabetischer Reihenfolge neu zusammenstellen, und manchmal müssen Sie möglicherweise die ursprüngliche Reihenfolge beibehalten (z. B. die Liste der Schlüsselspalten in einem fehlerhaften Index).
Für meine Lösung, die beide Szenarien abdeckt, habe ich eine Zahlentabelle zusammen mit zwei benutzerdefinierten Funktionen (UDFs) verwendet – eine, um die Zeichenfolge zu teilen, die andere, um sie wieder zusammenzusetzen. Sie können diesen Tipp hier sehen:
- Entfernen von Duplikaten aus Zeichenfolgen in SQL Server
Natürlich gibt es mehrere Möglichkeiten, dieses Problem zu lösen; Ich habe lediglich eine Methode bereitgestellt, um zu versuchen, ob Sie mit diesen Strukturdaten nicht weiterkommen. @Phil_Factor von Red-Gate folgte mit einem kurzen Beitrag, der seinen Ansatz zeigte, der die Funktionen und die Zahlentabelle vermeidet und sich stattdessen für die Inline-XML-Manipulation entscheidet. Er sagt, dass er Abfragen mit nur einer Anweisung bevorzugt und sowohl Funktionen als auch zeilenweise Verarbeitung vermeidet:
- Deduplizieren von durch Trennzeichen getrennten Listen in SQL Server
Dann hat ein Leser, Steve Mangiameli, eine Schleifenlösung als Kommentar zum Tipp gepostet. Seine Begründung war, dass ihm die Verwendung einer Zahlentabelle übertrieben erschien.
Wir drei haben es alle drei versäumt, einen Aspekt davon anzusprechen, der normalerweise sehr wichtig ist, wenn Sie die Aufgabe oft genug oder in einem beliebigen Umfang ausführen:Leistung .
Testen
Neugierig zu sehen, wie gut die Inline-XML- und Schleifenansätze im Vergleich zu meiner auf Zahlentabellen basierenden Lösung funktionieren würden, habe ich eine fiktive Tabelle erstellt, um einige Tests durchzuführen. Mein Ziel waren 5.000 Zeilen mit einer durchschnittlichen Zeichenfolgenlänge von mehr als 250 Zeichen und mindestens 10 Elementen in jeder Zeichenfolge. Mit einem sehr kurzen Zyklus von Experimenten konnte ich mit dem folgenden Code etwas erreichen, das dem sehr nahe kommt:
CREATE TABLE dbo.SourceTable
(
[RowID] int IDENTITY(1,1) PRIMARY KEY CLUSTERED,
DelimitedString varchar(8000)
);
GO
;WITH s(s) AS
(
SELECT TOP (250) o.name + REPLACE(REPLACE(REPLACE(REPLACE(REPLACE(
(
SELECT N'/column_' + c.name
FROM sys.all_columns AS c
WHERE c.[object_id] = o.[object_id]
ORDER BY NEWID()
FOR XML PATH(N''), TYPE).value(N'.[1]', N'nvarchar(max)'
),
-- make fake duplicates using 5 most common column names:
N'/column_name/', N'/name/name/foo/name/name/id/name/'),
N'/column_status/', N'/id/status/blat/status/foo/status/name/'),
N'/column_type/', N'/type/id/name/type/id/name/status/id/type/'),
N'/column_object_id/', N'/object_id/blat/object_id/status/type/name/'),
N'/column_pdw_node_id/', N'/pdw_node_id/name/pdw_node_id/name/type/name/')
FROM sys.all_objects AS o
WHERE EXISTS
(
SELECT 1 FROM sys.all_columns AS c
WHERE c.[object_id] = o.[object_id]
)
ORDER BY NEWID()
)
INSERT dbo.SourceTable(DelimitedString)
SELECT s FROM s;
GO 20 Dies erzeugte eine Tabelle mit Beispielzeilen, die so aussehen (Werte abgeschnitten):
RowID DelimitedString ----- --------------- 1 master_files/column_redo_target_fork_guid/.../column_differential_base_lsn/... 2 allocation_units/column_used_pages/.../column_data_space_id/type/id/name/type/... 3 foreign_key_columns/column_parent_object_id/column_constraint_object_id/...
Die Daten insgesamt hatten das folgende Profil, das ausreichen sollte, um potenzielle Leistungsprobleme aufzudecken:
;WITH cte([Length], ElementCount) AS
(
SELECT 1.0*LEN(DelimitedString),
1.0*LEN(REPLACE(DelimitedString,'/',''))
FROM dbo.SourceTable
)
SELECT row_count = COUNT(*),
avg_size = AVG([Length]),
max_size = MAX([Length]),
avg_elements = AVG(1 + [Length]-[ElementCount]),
sum_elements = SUM(1 + [Length]-[ElementCount])
FROM cte;
EXEC sys.sp_spaceused N'dbo.SourceTable';
/* results (numbers may vary slightly, depending on SQL Server version the user objects in your database):
row_count avg_size max_size avg_elements sum_elements
--------- ---------- -------- ------------ ------------
5000 299.559000 2905.0 17.650000 88250.0
reserved data index_size unused
-------- ------- ---------- ------
1672 KB 1648 KB 16 KB 8 KB
*/
Beachten Sie, dass ich zu varchar gewechselt bin hier von nvarchar im ursprünglichen Artikel, da die von Phil und Steve bereitgestellten Beispiele varchar voraussetzten , Zeichenfolgen, die auf nur 255 oder 8000 Zeichen begrenzt sind, Einzelzeichen-Trennzeichen usw. Ich habe meine Lektion auf die harte Tour gelernt, dass, wenn Sie die Funktion von jemandem nehmen und sie in Leistungsvergleiche einbeziehen, Sie sich so wenig wie möglich ändern möglich – idealerweise nichts. In Wirklichkeit würde ich immer nvarchar verwenden und nichts über die längste mögliche Saite annehmen. In diesem Fall wusste ich, dass ich keine Daten verliere, da die längste Zeichenfolge nur 2.905 Zeichen lang ist und ich in dieser Datenbank keine Tabellen oder Spalten habe, die Unicode-Zeichen verwenden.
Als nächstes habe ich meine Funktionen erstellt (die eine Zahlentabelle erfordern). Ein Leser hat ein Problem in der Funktion in meinem Tipp entdeckt, bei dem ich davon ausgegangen bin, dass das Trennzeichen immer ein einzelnes Zeichen sein würde, und das hier korrigiert. Ich habe auch so ziemlich alles in varchar(8000) konvertiert um das Spielfeld in Bezug auf Saitentypen und -längen anzugleichen.
DECLARE @UpperLimit INT = 1000000;
;WITH n(rn) AS
(
SELECT ROW_NUMBER() OVER (ORDER BY s1.[object_id])
FROM sys.all_columns AS s1
CROSS JOIN sys.all_columns AS s2
)
SELECT [Number] = rn
INTO dbo.Numbers FROM n
WHERE rn <= @UpperLimit;
CREATE UNIQUE CLUSTERED INDEX n ON dbo.Numbers([Number]);
GO
CREATE FUNCTION [dbo].[SplitString] -- inline TVF
(
@List varchar(8000),
@Delim varchar(32)
)
RETURNS TABLE
WITH SCHEMABINDING
AS
RETURN
(
SELECT
rn,
vn = ROW_NUMBER() OVER (PARTITION BY [Value] ORDER BY rn),
[Value]
FROM
(
SELECT
rn = ROW_NUMBER() OVER (ORDER BY CHARINDEX(@Delim, @List + @Delim)),
[Value] = LTRIM(RTRIM(SUBSTRING(@List, [Number],
CHARINDEX(@Delim, @List + @Delim, [Number]) - [Number])))
FROM dbo.Numbers
WHERE Number <= LEN(@List)
AND SUBSTRING(@Delim + @List, [Number], LEN(@Delim)) = @Delim
) AS x
);
GO
CREATE FUNCTION [dbo].[ReassembleString] -- scalar UDF
(
@List varchar(8000),
@Delim varchar(32),
@Sort varchar(32)
)
RETURNS varchar(8000)
WITH SCHEMABINDING
AS
BEGIN
RETURN
(
SELECT newval = STUFF((
SELECT @Delim + x.[Value]
FROM dbo.SplitString(@List, @Delim) AS x
WHERE (x.vn = 1) -- filter out duplicates
ORDER BY CASE @Sort
WHEN 'OriginalOrder' THEN CONVERT(int, x.rn)
WHEN 'Alphabetical' THEN CONVERT(varchar(8000), x.[Value])
ELSE CONVERT(SQL_VARIANT, NULL) END
FOR XML PATH(''), TYPE).value(N'(./text())[1]',N'varchar(8000)'),1,LEN(@Delim),'')
);
END
GO Als Nächstes habe ich eine einzelne Inline-Tabellenwertfunktion erstellt, die die beiden obigen Funktionen kombiniert, etwas, das ich mir jetzt wünschte, ich hätte es im Originalartikel getan, um die Skalarfunktion vollständig zu vermeiden. (Es stimmt zwar, dass nicht alle Skalarfunktionen sind im Maßstab schrecklich, es gibt nur sehr wenige Ausnahmen.)
CREATE FUNCTION [dbo].[RebuildString]
(
@List varchar(8000),
@Delim varchar(32),
@Sort varchar(32)
)
RETURNS TABLE
WITH SCHEMABINDING
AS
RETURN
(
SELECT [Output] = STUFF((
SELECT @Delim + x.[Value]
FROM
(
SELECT rn, [Value], vn = ROW_NUMBER() OVER (PARTITION BY [Value] ORDER BY rn)
FROM
(
SELECT rn = ROW_NUMBER() OVER (ORDER BY CHARINDEX(@Delim, @List + @Delim)),
[Value] = LTRIM(RTRIM(SUBSTRING(@List, [Number],
CHARINDEX(@Delim, @List + @Delim, [Number]) - [Number])))
FROM dbo.Numbers
WHERE Number <= LEN(@List)
AND SUBSTRING(@Delim + @List, [Number], LEN(@Delim)) = @Delim
) AS y
) AS x
WHERE (x.vn = 1)
ORDER BY CASE @Sort
WHEN 'OriginalOrder' THEN CONVERT(int, x.rn)
WHEN 'Alphabetical' THEN CONVERT(varchar(8000), x.[Value])
ELSE CONVERT(sql_variant, NULL) END
FOR XML PATH(''), TYPE).value(N'(./text())[1]',N'varchar(8000)'),1,LEN(@Delim),'')
);
GO
Ich habe auch separate Versionen des Inline-TVF erstellt, die jeder der beiden Sortiermöglichkeiten gewidmet waren, um die Volatilität des CASE zu vermeiden Ausdruck, aber es stellte sich heraus, dass es überhaupt keine dramatischen Auswirkungen hatte.
Dann habe ich Steves zwei Funktionen erstellt:
CREATE FUNCTION [dbo].[gfn_ParseList] -- multi-statement TVF
(@strToPars VARCHAR(8000), @parseChar CHAR(1))
RETURNS @parsedIDs TABLE
(ParsedValue VARCHAR(255), PositionID INT IDENTITY)
AS
BEGIN
DECLARE
@startPos INT = 0
, @strLen INT = 0
WHILE LEN(@strToPars) >= @startPos
BEGIN
IF (SELECT CHARINDEX(@parseChar,@strToPars,(@startPos+1))) > @startPos
SELECT @strLen = CHARINDEX(@parseChar,@strToPars,(@startPos+1)) - @startPos
ELSE
BEGIN
SET @strLen = LEN(@strToPars) - (@startPos -1)
INSERT @parsedIDs
SELECT RTRIM(LTRIM(SUBSTRING(@strToPars,@startPos, @strLen)))
BREAK
END
SELECT @strLen = CHARINDEX(@parseChar,@strToPars,(@startPos+1)) - @startPos
INSERT @parsedIDs
SELECT RTRIM(LTRIM(SUBSTRING(@strToPars,@startPos, @strLen)))
SET @startPos = @startPos+@strLen+1
END
RETURN
END
GO
CREATE FUNCTION [dbo].[ufn_DedupeString] -- scalar UDF
(
@dupeStr VARCHAR(MAX), @strDelimiter CHAR(1), @maintainOrder BIT
)
-- can't possibly return nvarchar, but I'm not touching it
RETURNS NVARCHAR(MAX)
AS
BEGIN
DECLARE @tblStr2Tbl TABLE (ParsedValue VARCHAR(255), PositionID INT);
DECLARE @tblDeDupeMe TABLE (ParsedValue VARCHAR(255), PositionID INT);
INSERT @tblStr2Tbl
SELECT DISTINCT ParsedValue, PositionID FROM dbo.gfn_ParseList(@dupeStr,@strDelimiter);
WITH cteUniqueValues
AS
(
SELECT DISTINCT ParsedValue
FROM @tblStr2Tbl
)
INSERT @tblDeDupeMe
SELECT d.ParsedValue
, CASE @maintainOrder
WHEN 1 THEN MIN(d.PositionID)
ELSE ROW_NUMBER() OVER (ORDER BY d.ParsedValue)
END AS PositionID
FROM cteUniqueValues u
JOIN @tblStr2Tbl d ON d.ParsedValue=u.ParsedValue
GROUP BY d.ParsedValue
ORDER BY d.ParsedValue
DECLARE
@valCount INT
, @curValue VARCHAR(255) =''
, @posValue INT=0
, @dedupedStr VARCHAR(4000)='';
SELECT @valCount = COUNT(1) FROM @tblDeDupeMe;
WHILE @valCount > 0
BEGIN
SELECT @posValue=a.minPos, @curValue=d.ParsedValue
FROM (SELECT MIN(PositionID) minPos FROM @tblDeDupeMe WHERE PositionID > @posValue) a
JOIN @tblDeDupeMe d ON d.PositionID=a.minPos;
SET @dedupedStr+=@curValue;
SET @valCount-=1;
IF @valCount > 0
SET @dedupedStr+='/';
END
RETURN @dedupedStr;
END
GO
Dann füge ich Phils direkte Abfragen in meine Testumgebung ein (beachten Sie, dass seine Abfragen < kodieren als < um sie vor XML-Parsing-Fehlern zu schützen, aber sie kodieren nicht > oder & – Ich habe Platzhalter hinzugefügt, falls Sie sich vor Zeichenfolgen schützen müssen, die möglicherweise diese problematischen Zeichen enthalten):
-- Phil's query for maintaining original order
SELECT /*the re-assembled list*/
stuff(
(SELECT '/'+TheValue FROM
(SELECT x.y.value('.','varchar(20)') AS Thevalue,
row_number() OVER (ORDER BY (SELECT 1)) AS TheOrder
FROM XMLList.nodes('/list/i/text()') AS x ( y )
)Nodes(Thevalue,TheOrder)
GROUP BY TheValue
ORDER BY min(TheOrder)
FOR XML PATH('')
),1,1,'')
as Deduplicated
FROM (/*XML version of the original list*/
SELECT convert(XML,'<list><i>'
--+replace(replace(
+replace(replace(ASCIIList,'<','<') --,'>','>'),'&','&')
,'/','</i><i>')+'</i></list>')
FROM (SELECT DelimitedString FROM dbo.SourceTable
)XMLlist(AsciiList)
)lists(XMLlist);
-- Phil's query for alpha
SELECT
stuff( (SELECT DISTINCT '/'+x.y.value('.','varchar(20)')
FROM XMLList.nodes('/list/i/text()') AS x ( y )
FOR XML PATH('')),1,1,'') as Deduplicated
FROM (
SELECT convert(XML,'<list><i>'
--+replace(replace(
+replace(replace(ASCIIList,'<','<') --,'>','>'),'&','&')
,'/','</i><i>')+'</i></list>')
FROM (SELECT AsciiList FROM
(SELECT DelimitedString FROM dbo.SourceTable)ListsWithDuplicates(AsciiList)
)XMLlist(AsciiList)
)lists(XMLlist);
Der Prüfstand waren im Wesentlichen diese beiden Abfragen und auch die folgenden Funktionsaufrufe. Nachdem ich bestätigt hatte, dass sie alle die gleichen Daten zurückgaben, fügte ich das Skript mit DATEDIFF ein ausgegeben und in einer Tabelle protokolliert:
-- Maintain original order
-- My UDF/TVF pair from the original article
SELECT UDF_Original = dbo.ReassembleString(DelimitedString, '/', 'OriginalOrder')
FROM dbo.SourceTable ORDER BY RowID;
-- My inline TVF based on the original article
SELECT TVF_Original = f.[Output] FROM dbo.SourceTable AS t
CROSS APPLY dbo.RebuildString(t.DelimitedString, '/', 'OriginalOrder') AS f
ORDER BY t.RowID;
-- Steve's UDF/TVF pair:
SELECT Steve_Original = dbo.ufn_DedupeString(DelimitedString, '/', 1)
FROM dbo.SourceTable;
-- Phil's first query from above
-- Reassemble in alphabetical order
-- My UDF/TVF pair from the original article
SELECT UDF_Alpha = dbo.ReassembleString(DelimitedString, '/', 'Alphabetical')
FROM dbo.SourceTable ORDER BY RowID;
-- My inline TVF based on the original article
SELECT TVF_Alpha = f.[Output] FROM dbo.SourceTable AS t
CROSS APPLY dbo.RebuildString(t.DelimitedString, '/', 'Alphabetical') AS f
ORDER BY t.RowID;
-- Steve's UDF/TVF pair:
SELECT Steve_Alpha = dbo.ufn_DedupeString(DelimitedString, '/', 0)
FROM dbo.SourceTable;
-- Phil's second query from above Und dann habe ich Leistungstests auf zwei verschiedenen Systemen (einem Quad-Core mit 8 GB und einer 8-Core-VM mit 32 GB) und jeweils sowohl auf SQL Server 2012 als auch auf SQL Server 2016 CTP 3.2 (13.0.900.73) durchgeführt /P>
Ergebnisse
Die von mir beobachteten Ergebnisse sind im folgenden Diagramm zusammengefasst, das die Dauer in Millisekunden für jeden Abfragetyp, gemittelt über die alphabetische und ursprüngliche Reihenfolge, die vier Server-/Versionskombinationen und eine Reihe von 15 Ausführungen für jede Permutation zeigt. Zum Vergrößern anklicken:
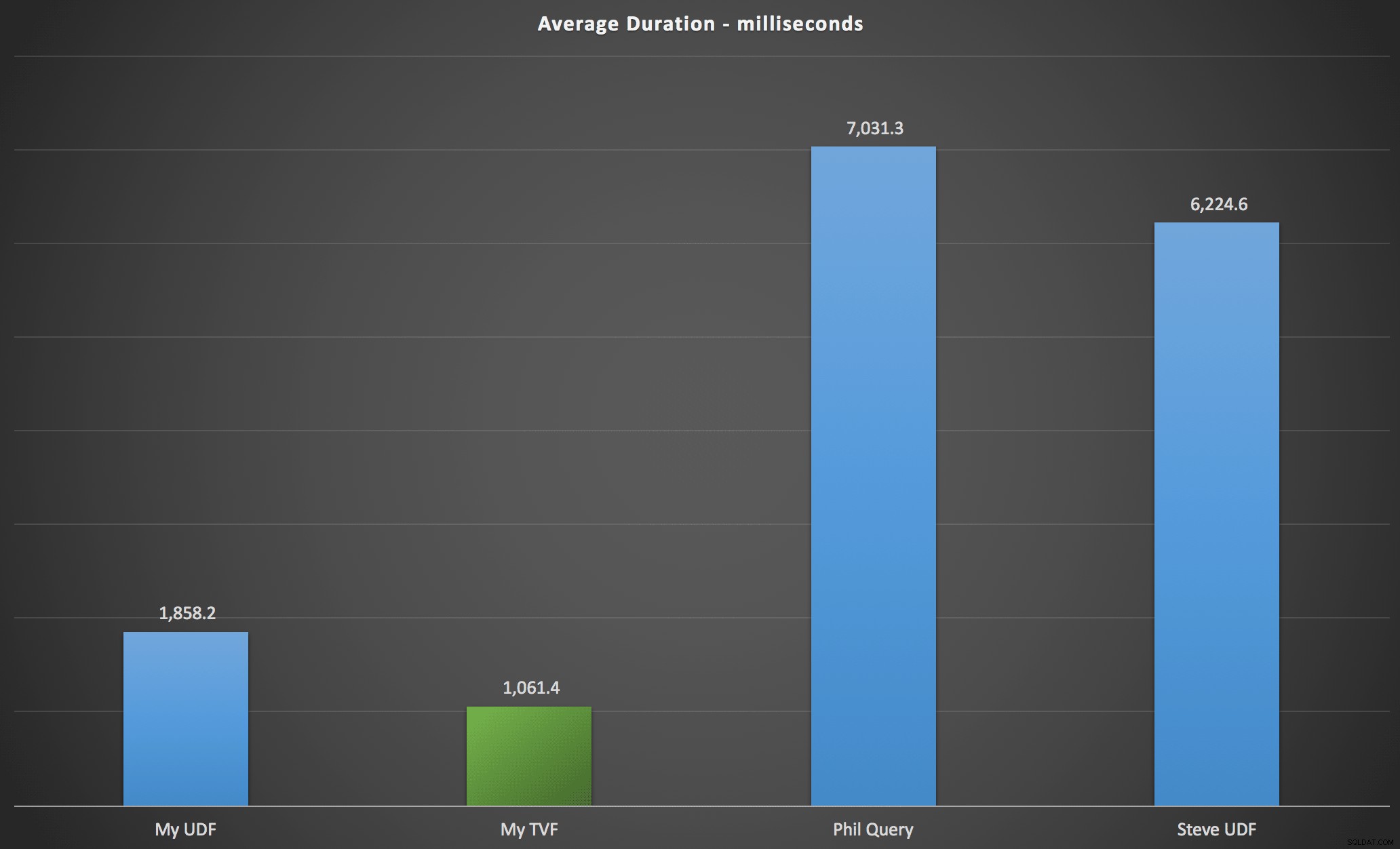
Dies zeigt, dass die Zahlentabelle, obwohl sie als überentwickelt gilt, tatsächlich die effizienteste Lösung (zumindest in Bezug auf die Dauer) lieferte. Das war natürlich mit dem Single-TVF, das ich vor kurzem implementiert habe, besser als mit den verschachtelten Funktionen aus dem ursprünglichen Artikel, aber beide Lösungen drehen sich um die beiden Alternativen.
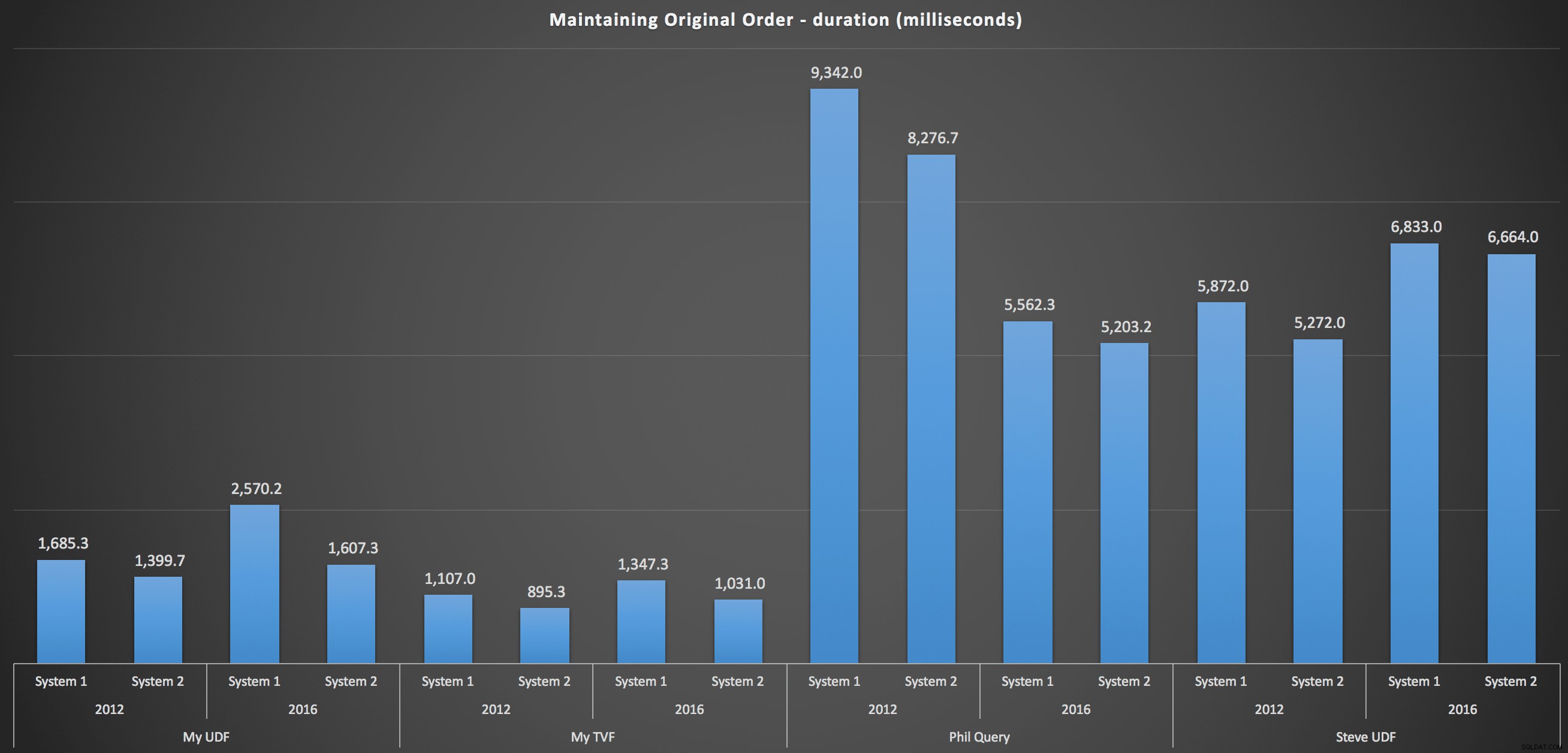
Um mehr ins Detail zu gehen, sind hier die Aufschlüsselungen für jeden Computer, jede Version und jeden Abfragetyp, um die ursprüngliche Reihenfolge beizubehalten:
…und zum erneuten Zusammenstellen der Liste in alphabetischer Reihenfolge:
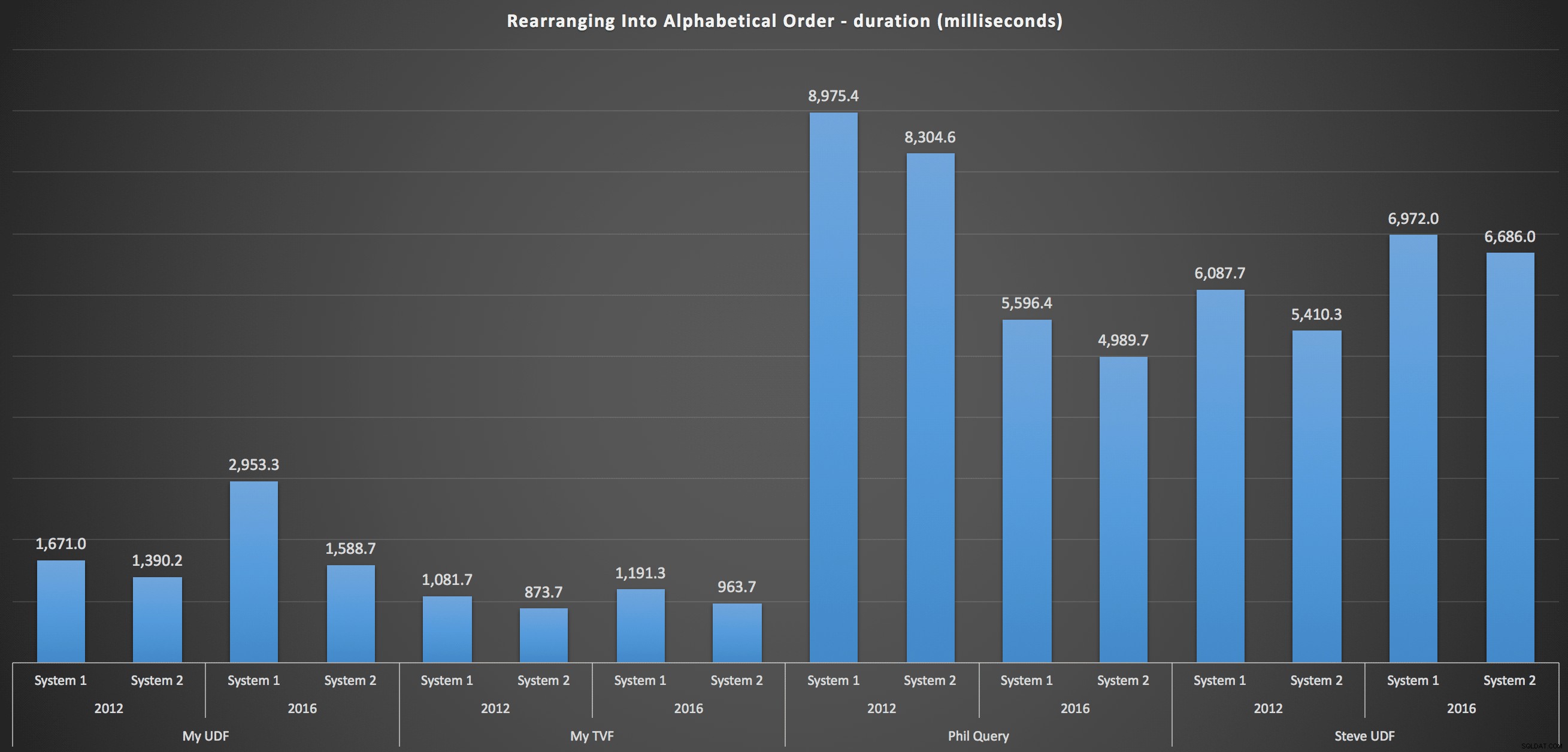
Diese zeigen, dass die Wahl der Sortierung wenig Einfluss auf das Ergebnis hatte – beide Diagramme sind praktisch identisch. Und das macht Sinn, denn angesichts der Form der Eingabedaten kann ich mir keinen Index vorstellen, der das Sortieren effizienter machen würde – es ist ein iterativer Ansatz, egal wie Sie es aufteilen oder wie Sie die Daten zurückgeben. Aber es ist klar, dass einige iterative Ansätze im Allgemeinen schlechter sein können als andere, und es ist nicht unbedingt die Verwendung einer UDF (oder einer Zahlentabelle), die sie so macht.
Schlussfolgerung
Bis wir eine native Teilungs- und Verkettungsfunktionalität in SQL Server haben, werden wir alle Arten von nicht intuitiven Methoden verwenden, um die Arbeit zu erledigen, einschließlich benutzerdefinierter Funktionen. Wenn Sie jeweils nur eine Saite bearbeiten, werden Sie keinen großen Unterschied feststellen. Aber wenn Ihre Daten skalieren, lohnt es sich, verschiedene Ansätze zu testen (und ich behaupte keineswegs, dass die oben genannten Methoden die besten sind, die Sie finden werden – ich habe mir zum Beispiel nicht einmal CLR angesehen, oder andere T-SQL-Ansätze aus dieser Reihe).