Dieser Artikel verwendet eine einfache Abfrage, um einige tiefgreifende Interna in Bezug auf Aktualisierungsabfragen zu untersuchen.
Beispieldaten und Konfiguration
Das Beispielskript für die Datenerstellung unten erfordert eine Tabelle mit Zahlen. Wenn Sie noch keines davon haben, kann das folgende Skript verwendet werden, um eines effizient zu erstellen. Die resultierende Zahlentabelle enthält eine einzelne Integer-Spalte mit Zahlen von 1 bis 1 Million:
WITH Ten(N) AS
(
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1
)
SELECT TOP (1000000)
n = IDENTITY(int, 1, 1)
INTO dbo.Numbers
FROM Ten T10,
Ten T100,
Ten T1000,
Ten T10000,
Ten T100000,
Ten T1000000;
ALTER TABLE dbo.Numbers
ADD CONSTRAINT PK_dbo_Numbers_n
PRIMARY KEY CLUSTERED (n)
WITH (SORT_IN_TEMPDB = ON, MAXDOP = 1, FILLFACTOR = 100); Das folgende Skript erstellt eine geclusterte Beispieldatentabelle mit 10.000 IDs mit etwa 100 unterschiedlichen Startdaten pro ID. Die Spalte Enddatum ist zunächst auf den festen Wert '99991231' gesetzt.
CREATE TABLE dbo.Example
(
SomeID integer NOT NULL,
StartDate date NOT NULL,
EndDate date NOT NULL
);
GO
INSERT dbo.Example WITH (TABLOCKX)
(SomeID, StartDate, EndDate)
SELECT DISTINCT
1 + (N.n % 10000),
DATEADD(DAY, 50000 * RAND(CHECKSUM(NEWID())), '20010101'),
CONVERT(date, '99991231', 112)
FROM dbo.Numbers AS N
WHERE
N.n >= 1
AND N.n <= 1000000
OPTION (MAXDOP 1);
CREATE CLUSTERED INDEX
CX_Example_SomeID_StartDate
ON dbo.Example
(SomeID, StartDate)
WITH (MAXDOP = 1, SORT_IN_TEMPDB = ON); Während die Punkte in diesem Artikel ziemlich allgemein für alle aktuellen Versionen von SQL Server gelten, können die folgenden Konfigurationsinformationen verwendet werden, um sicherzustellen, dass Sie ähnliche Ausführungspläne und Leistungseffekte sehen:
- SQL Server 2012 Service Pack 3 x64-Entwickleredition
- Max. Serverspeicher auf 2048 MB eingestellt
- Vier logische Prozessoren für die Instanz verfügbar
- Keine Trace-Flags aktiviert
- Standard-Isolationsstufe für Lesezugriff
- RCSI- und SI-Datenbankoptionen deaktiviert
Verschütten von Hash-Aggregaten
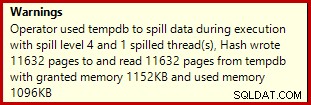
Wenn Sie das obige Datenerstellungsskript mit aktivierten tatsächlichen Ausführungsplänen ausführen, wird das Hash-Aggregat möglicherweise an tempdb weitergegeben und erzeugt ein Warnsymbol:

Bei der Ausführung auf SQL Server 2012 Service Pack 3 werden zusätzliche Informationen zum Überlaufen in der Quickinfo angezeigt:
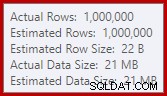
Dieser Überlauf könnte überraschend sein, da die Schätzungen der Eingabezeilen für das Hash-Match genau richtig sind:
Wir sind es gewohnt, Schätzungen auf der Eingabe zu vergleichen für Sortierungen und Hash-Joins (nur Build-Eingabe), aber Eifer-Hash-Aggregate sind anders. Ein Hash-Aggregat funktioniert, indem es gruppierte Ergebniszeilen in der Hash-Tabelle akkumuliert, also ist es die Anzahl der Ausgabe Zeilen, die wichtig sind:
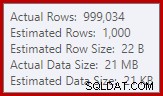
Der Kardinalitätsschätzer in SQL Server 2012 schätzt die Anzahl der erwarteten unterschiedlichen Werte ziemlich schlecht ein (1.000 gegenüber 999.034 tatsächlich); Das Hash-Aggregat springt als Folge davon zur Laufzeit rekursiv auf Ebene 4. Der „neue“ Kardinalitätsschätzer, der ab SQL Server 2014 verfügbar ist, erzeugt zufällig eine genauere Schätzung für die Hash-Ausgabe in dieser Abfrage, sodass Sie in diesem Fall keinen Hash-Überlauf sehen:

Die Anzahl der tatsächlichen Zeilen kann für Sie leicht abweichen, da im Skript ein Pseudo-Zufallszahlengenerator verwendet wird. Der wichtige Punkt ist, dass Hash Aggregate Spills von der Anzahl der ausgegebenen eindeutigen Werte abhängen, nicht von der Eingabegröße.
Die Update-Spezifikation
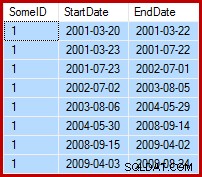
Die Aufgabe besteht darin, die Beispieldaten so zu aktualisieren, dass die Enddaten auf den Tag vor dem folgenden Startdatum (per SomeID) gesetzt werden. Beispielsweise könnten die ersten paar Zeilen der Beispieldaten vor der Aktualisierung so aussehen (alle Enddaten auf 9999-12-31 gesetzt):

Dann nach dem Update so:
1. Baseline-Update-Abfrage
Eine einigermaßen natürliche Möglichkeit, das erforderliche Update in T-SQL auszudrücken, ist wie folgt:
UPDATE dbo.Example WITH (TABLOCKX)
SET EndDate =
ISNULL
(
(
SELECT TOP (1)
DATEADD(DAY, -1, E2.StartDate)
FROM dbo.Example AS E2 WITH (TABLOCK)
WHERE
E2.SomeID = dbo.Example.SomeID
AND E2.StartDate > dbo.Example.StartDate
ORDER BY
E2.StartDate ASC
),
CONVERT(date, '99991231', 112)
)
OPTION (MAXDOP 1); Der (tatsächliche) Ausführungsplan nach der Ausführung lautet:
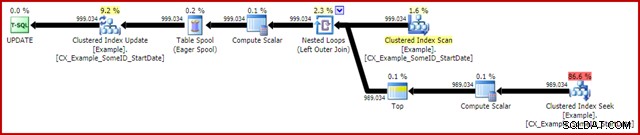
Das bemerkenswerteste Merkmal ist die Verwendung einer Eager Table Spool, um Halloween-Schutz zu bieten. Dies ist hier aufgrund des Self-Join der Aktualisierungszieltabelle für den korrekten Betrieb erforderlich. Der Effekt besteht darin, dass alles rechts von der Spule vollständig ausgeführt wird, wobei alle Informationen gespeichert werden, die zum Vornehmen von Änderungen in einer tempdb-Arbeitstabelle erforderlich sind. Sobald der Lesevorgang abgeschlossen ist, wird der Inhalt der Arbeitstabelle wiedergegeben, um die Änderungen im Clustered Index Update-Iterator anzuwenden.
Leistung
Um uns auf das maximale Leistungspotenzial dieses Ausführungsplans zu konzentrieren, können wir dieselbe Aktualisierungsabfrage mehrmals ausführen. Natürlich führt nur der erste Durchlauf zu Änderungen an den Daten, aber das stellt sich als Nebensache heraus. Wenn Sie das stört, können Sie die Enddatumsspalte vor jedem Lauf mit dem folgenden Code zurücksetzen. Die allgemeinen Punkte, die ich machen werde, hängen nicht von der Anzahl der tatsächlich vorgenommenen Datenänderungen ab.
UPDATE dbo.Example WITH (TABLOCKX) SET EndDate = CONVERT(date, '99991231', 112);
Bei deaktivierter Ausführungsplanerfassung, allen erforderlichen Seiten im Pufferpool und ohne Zurücksetzen der Enddatumswerte zwischen Ausführungen wird diese Abfrage normalerweise in etwa 5700 ms ausgeführt Auf meinem Laptop. Die Statistik-IO-Ausgabe sieht wie folgt aus:(Read-Ahead-Reads und LOB-Zähler waren Null und werden aus Platzgründen weggelassen)
Table 'Example'. Scan count 999035, logical reads 6186219, physical reads 0 Table 'Worktable'. Scan count 1, logical reads 2895875, physical reads 0
Die Scananzahl gibt an, wie oft ein Scanvorgang gestartet wurde. Für die Beispieltabelle ist dies 1 für den Clustered-Index-Scan und 999.034 für jedes Mal, wenn der korrelierte Clustered-Index-Suchvorgang zurückprallt. Die von Eager Spool verwendete Arbeitstabelle hat nur einmal einen Scanvorgang gestartet.
Logische Lesevorgänge
Die interessantere Information in der IO-Ausgabe ist die Anzahl der logischen Lesevorgänge:über 6 Millionen für die Beispieltabelle und fast 3 Millionen für den Arbeitstisch.
Die logischen Lesevorgänge der Beispieltabelle sind hauptsächlich mit Seek und Update verbunden. Der Seek erfordert 3 logische Lesevorgänge für jede Iteration:jeweils 1 für die Stamm-, Zwischen- und Blattebene des Index. Das Update kostet ebenfalls 3 Lesevorgänge pro Zeile wird aktualisiert, wenn die Engine den B-Baum nach unten navigiert, um die Zielzeile zu lokalisieren. Der Clustered Index Scan ist nur für wenige tausend Lesevorgänge verantwortlich, einen pro Seite lesen.
Die Spool-Arbeitstabelle ist ebenfalls intern als B-Baum strukturiert und zählt mehrere Lesevorgänge, wenn die Spule die Einfügeposition lokalisiert, während sie ihre Eingabe verarbeitet. Vielleicht entgegen der Intuition zählt die Spule keine logischen Lesevorgänge, während sie gelesen wird, um das Clustered Index Update zu steuern. Dies ist einfach eine Folge der Implementierung:Ein logischer Lesevorgang wird immer dann gezählt, wenn der Code BPool::Get ausführt Methode. Das Schreiben in die Spule ruft diese Methode auf jeder Ebene des Index auf; Das Lesen aus der Spule folgt einem anderen Codepfad, der BPool::Get nicht aufruft überhaupt.
Beachten Sie auch, dass die Statistik-E/A-Ausgabe eine einzige Summe für die Beispieltabelle meldet, obwohl auf sie von drei verschiedenen Iteratoren im Ausführungsplan (Scan, Seek und Update) zugegriffen wird. Diese letztere Tatsache macht es schwierig, logische Lesevorgänge mit dem Iterator zu korrelieren, der sie verursacht hat. Ich hoffe, dass diese Einschränkung in einer zukünftigen Version des Produkts behoben wird.
2. Aktualisierung mit Zeilennummern
Eine andere Möglichkeit, die Aktualisierungsabfrage auszudrücken, besteht darin, die Zeilen pro ID zu nummerieren und zu verbinden:
WITH Numbered AS
(
SELECT
E.SomeID,
E.StartDate,
E.EndDate,
rn = ROW_NUMBER() OVER (
PARTITION BY E.SomeID
ORDER BY E.StartDate ASC)
FROM dbo.Example AS E
)
UPDATE This WITH (TABLOCKX)
SET EndDate =
ISNULL
(
DATEADD(DAY, -1, NextRow.StartDate),
CONVERT(date, '99991231', 112)
)
FROM Numbered AS This
LEFT JOIN Numbered AS NextRow WITH (TABLOCK)
ON NextRow.SomeID = This.SomeID
AND NextRow.rn = This.rn + 1
OPTION (MAXDOP 1, MERGE JOIN); Der Nachausführungsplan sieht wie folgt aus:
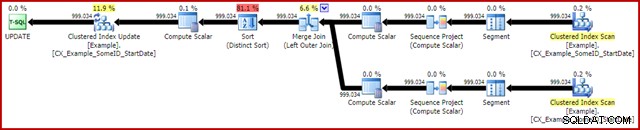
Diese Abfrage wird normalerweise in 2950 ms ausgeführt auf meinem Laptop, was im Vergleich zu den 5700 ms (unter den gleichen Umständen) für die ursprüngliche Update-Anweisung günstig ist. Die Statistik-IO-Ausgabe ist:
Table 'Example'. Scan count 2, logical reads 3001808, physical reads 0 Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0
Dies zeigt zwei Scans, die für die Beispieltabelle gestartet wurden (einer für jeden Clustered Index Scan-Iterator). Die logischen Lesevorgänge sind wiederum ein Aggregat über alle Iteratoren, die auf diese Tabelle im Abfrageplan zugreifen. Das Fehlen einer Aufschlüsselung macht es nach wie vor unmöglich festzustellen, welcher Iterator (der beiden Scans und des Updates) für die 3 Millionen Lesevorgänge verantwortlich war.
Trotzdem kann ich Ihnen sagen, dass die Clustered Index Scans jeweils nur wenige tausend logische Lesevorgänge zählen. Die überwiegende Mehrheit der logischen Lesevorgänge wird durch das Clustered Index Update verursacht, das den Index-B-Baum nach unten navigiert, um die Aktualisierungsposition für jede Zeile zu finden, die es verarbeitet. Für den Moment müssen Sie sich auf mein Wort verlassen; Weitere Erläuterungen folgen in Kürze.
Die Nachteile
Das ist so ziemlich das Ende der guten Nachrichten für diese Form der Abfrage. Es funktioniert viel besser als das Original, ist aber aus einer Reihe anderer Gründe viel weniger zufriedenstellend. Das Hauptproblem wird durch eine Einschränkung des Optimierungsprogramms verursacht, was bedeutet, dass es nicht erkennt, dass die Zeilennummerierungsoperation eine eindeutige Nummer für jede Zeile innerhalb einer SomeID-Partition erzeugt.
Diese einfache Tatsache führt zu einer Reihe unerwünschter Folgen. Zum einen ist der Merge-Join so konfiguriert, dass er im Viele-zu-Viele-Join-Modus ausgeführt wird. Dies ist der Grund für die (unbenutzte) Arbeitstabelle in der Statistik-IO (viele-zu-viele-Merge erfordert eine Arbeitstabelle für doppelte Join-Key-Rückläufe). Das Erwarten eines Viele-zu-Viele-Joins bedeutet auch, dass die Kardinalitätsschätzung für die Join-Ausgabe hoffnungslos falsch ist:
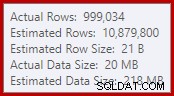
Als Folge davon verlangt Sort viel zu viel Speicherzuweisung. Die Eigenschaften des Stammknotens zeigen, dass Sort 812.752 KB Arbeitsspeicher gewünscht hätte, obwohl ihm aufgrund der eingeschränkten maximalen Serverspeichereinstellung (2048 MB) nur 379.440 KB gewährt wurden. Die Sortierung verbrauchte zur Laufzeit tatsächlich maximal 58.968 KB:
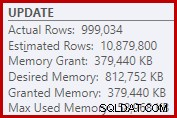
Übermäßige Arbeitsspeicherzuweisungen stehlen Arbeitsspeicher von anderen produktiven Verwendungen und können dazu führen, dass Abfragen warten, bis Arbeitsspeicher verfügbar wird. In vielerlei Hinsicht können übermäßige Arbeitsspeicherzuteilungen ein größeres Problem darstellen als Unterschätzungen.
Die Einschränkung des Optimierers erklärt auch, warum für die beste Leistung ein Merge-Join-Hinweis für die Abfrage erforderlich war. Ohne diesen Hinweis geht der Optimierer fälschlicherweise davon aus, dass ein Hash-Join billiger wäre als ein Many-to-Many-Merge-Join. Der Hash-Join-Plan wird im Durchschnitt in 3350 ms ausgeführt.
Beachten Sie als letzte negative Konsequenz, dass die Sortierung im Plan eine eindeutige Sortierung ist. Nun, es gibt ein paar Gründe für diese Sorte (nicht zuletzt, weil sie den erforderlichen Halloween-Schutz bieten kann), aber sie ist nur eine Distinct Sortieren, da dem Optimierer die Eindeutigkeitsinformationen fehlen. Insgesamt fällt es schwer, an diesem Ausführungsplan über die Leistung hinaus viel zu mögen.
3. Aktualisierung mit der LEAD-Analysefunktion
Da dieser Artikel hauptsächlich auf SQL Server 2012 und höher abzielt, können wir die Aktualisierungsabfrage ganz natürlich mithilfe der LEAD-Analysefunktion ausdrücken. In einer idealen Welt könnten wir eine sehr kompakte Syntax verwenden wie:
-- Not allowed
UPDATE dbo.Example WITH (TABLOCKX)
SET EndDate = LEAD(StartDate) OVER (
PARTITION BY SomeID ORDER BY StartDate); Leider ist dies nicht legal. Dies führt zu Fehlermeldung 4108, „Fensterfunktionen können nur in den Klauseln SELECT oder ORDER BY erscheinen“. Das ist etwas frustrierend, weil wir auf einen Ausführungsplan gehofft hatten, der einen Selbstbeitritt (und das damit verbundene Update Halloween Protection) vermeiden könnte.
Die gute Nachricht ist, dass wir den Self-Join immer noch vermeiden können, indem wir einen gemeinsamen Tabellenausdruck oder eine abgeleitete Tabelle verwenden. Die Syntax ist etwas ausführlicher, aber die Idee ist ziemlich dieselbe:
WITH CED AS
(
SELECT
E.EndDate,
CalculatedEndDate =
DATEADD(DAY, -1,
LEAD(E.StartDate) OVER (
PARTITION BY E.SomeID
ORDER BY E.StartDate))
FROM dbo.Example AS E
)
UPDATE CED WITH (TABLOCKX)
SET CED.EndDate =
ISNULL
(
CED.CalculatedEndDate,
CONVERT(date, '99991231', 112)
)
OPTION (MAXDOP 1); Der Nachausführungsplan lautet:

Dies dauert normalerweise etwa 3400 ms auf meinem Laptop, der langsamer ist als die Zeilennummerlösung (2950 ms), aber immer noch viel schneller als das Original (5700 ms). Eine Sache, die sich vom Ausführungsplan abhebt, ist der Sortierüberlauf (wiederum zusätzliche Überlaufinformationen dank der Verbesserungen in SP3):
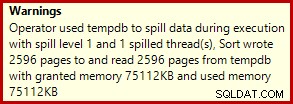
Dies ist eine ziemlich kleine Leckage, aber sie kann die Leistung immer noch in gewissem Maße beeinträchtigen. Das Seltsame daran ist, dass die Eingabeschätzung für Sort genau richtig ist:
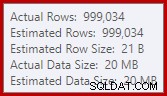
Glücklicherweise gibt es in SQL Server 2012 SP2 CU8 (und anderen Versionen – Einzelheiten finden Sie im KB-Artikel) eine „Korrektur“ für diese spezielle Bedingung. Das Ausführen der Abfrage mit aktiviertem Fix und erforderlichem Trace-Flag 7470 bedeutet, dass die Sortierung genügend Arbeitsspeicher anfordert, um sicherzustellen, dass sie niemals auf die Festplatte überläuft, wenn die geschätzte Größe der Eingabesortierung nicht überschritten wird.
LEAD-Aktualisierungsabfrage ohne Sortierüberlauf
Der Abwechslung halber verwendet die Fix-aktivierte Abfrage unten eine abgeleitete Tabellensyntax anstelle eines CTE:
UPDATE CED WITH (TABLOCKX)
SET CED.EndDate =
ISNULL
(
CED.CalculatedEndDate, CONVERT(date, '99991231', 112)
)
FROM
(
SELECT
E.EndDate,
CalculatedEndDate =
DATEADD(DAY, -1,
LEAD(E.StartDate) OVER (
PARTITION BY E.SomeID
ORDER BY E.StartDate))
FROM dbo.Example AS E
) AS CED
OPTION (MAXDOP 1, QUERYTRACEON 7470); Der neue Nachausführungsplan lautet:

Das Eliminieren des kleinen Überlaufs verbessert die Leistung von 3.400 ms auf 3.250 ms . Die Statistik-IO-Ausgabe ist:
Table 'Example'. Scan count 1, logical reads 2999455, physical reads 0 Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0
Wenn Sie dies mit den logischen Lesevorgängen für die Abfrage mit Zeilennummerierung vergleichen, werden Sie feststellen, dass die logischen Lesevorgänge von 3.001.808 auf 2.999.455 gesunken sind – eine Differenz von 2.353 Lesevorgängen. Dies entspricht genau der Entfernung eines einzelnen Clustered-Index-Scans (ein Lesevorgang pro Seite).
Sie erinnern sich vielleicht, dass ich erwähnt habe, dass die überwiegende Mehrheit der logischen Lesevorgänge für diese Aktualisierungsabfragen mit dem Clustered Index Update verbunden sind und dass die Scans mit „nur ein paar tausend Lesevorgängen“ verbunden waren. Wir können dies jetzt etwas direkter sehen, indem wir eine einfache Zeilenzählungsabfrage für die Beispieltabelle ausführen:
SET STATISTICS IO ON; SELECT COUNT(*) FROM dbo.Example WITH (TABLOCK); SET STATISTICS IO OFF;
Die IO-Ausgabe zeigt genau die Differenz von 2.353 logischen Lesevorgängen zwischen der Zeilennummer und den Lead-Aktualisierungen:
Table 'Example'. Scan count 1, logical reads 2353, physical reads 0
Weitere Verbesserung?
Die Spill-Fixed-Lead-Abfrage (3250 ms) ist immer noch etwas langsamer als die zweireihige nummerierte Abfrage (2950 ms), was ein wenig überraschend sein kann. Intuitiv könnte man erwarten, dass eine einzige Scan- und Analysefunktion (Window Spool und Stream Aggregate) schneller ist als zwei Scans, zwei Zeilennummerierungen und ein Join.
Unabhängig davon ist das, was aus dem Ausführungsplan für Lead-Abfragen hervorsticht, die Sortierung. Es war auch in der zeilennummerierten Abfrage vorhanden, wo es zum Halloween-Schutz sowie zu einer optimierten Sortierreihenfolge für das Clustered Index Update (das die DMLRequestSort-Eigenschaft gesetzt hat) beigetragen hat.
Die Sache ist, dass diese Sortierung im Lead-Abfrageplan völlig unnötig ist. Es wird für den Halloween-Schutz nicht benötigt, da der Selbstbeitritt weg ist. Es wird auch nicht für die optimierte Sortierreihenfolge beim Einfügen benötigt:Die Zeilen werden in der Reihenfolge der Clustered Keys gelesen, und es gibt nichts im Plan, um diese Reihenfolge zu stören. Das eigentliche Problem wird deutlich, wenn man sich die Sort-Eigenschaften ansieht:

Beachten Sie dort den Abschnitt Sortieren nach. Die Sortierung erfolgt nach SomeID und StartDate (den gruppierten Indexschlüsseln), aber auch nach [Uniq1002], dem Uniquifier. Dies ist eine Folge davon, dass der gruppierte Index nicht als eindeutig deklariert wurde, obwohl wir in der Datenauffüllungsabfrage Schritte unternommen haben, um sicherzustellen, dass die Kombination aus SomeID und StartDate tatsächlich eindeutig ist. (Das war Absicht, also konnte ich darüber sprechen.)
Trotzdem ist dies eine Einschränkung. Die Zeilen werden der Reihe nach aus dem Clustered-Index gelesen, und die erforderlichen internen Garantien sind vorhanden, damit der Optimierer diese Sortierung sicher vermeiden kann. Es ist einfach ein Versehen, dass der Optimierer nicht erkennt, dass der eingehende Stream sowohl nach Uniquifier als auch nach SomeID und StartDate sortiert ist. Es erkennt, dass die Reihenfolge (SomeID, StartDate) beibehalten werden konnte, aber nicht (SomeID, StartDate, Uniquifier). Auch hier hoffe ich, dass dies in einer zukünftigen Version behoben wird.
Um dies zu umgehen, können wir tun, was wir von Anfang an hätten tun sollen:Erstellen Sie den Clustered-Index als eindeutig:
CREATE UNIQUE CLUSTERED INDEX CX_Example_SomeID_StartDate ON dbo.Example (SomeID, StartDate) WITH (DROP_EXISTING = ON, MAXDOP = 1);
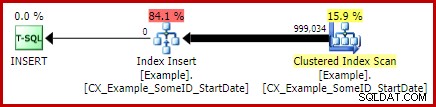
Ich überlasse es dem Leser als Übung, zu zeigen, dass die ersten beiden (Nicht-LEAD) Abfragen nicht von dieser Indizierungsänderung profitieren (aus Platzgründen weggelassen – es gibt viel zu behandeln).
Das endgültige Formular der Lead-Update-Abfrage
Mit dem einzigartigen Wenn ein gruppierter Index vorhanden ist, erzeugt die exakt gleiche LEAD-Abfrage (CTE oder abgeleitete Tabelle, wie Sie möchten) den geschätzten Plan (vor der Ausführung), den wir erwarten:

Das scheint ziemlich optimal zu sein. Ein einzelner Lese- und Schreibvorgang mit einem Minimum an Operatoren dazwischen. Sicherlich scheint es viel besser als die vorherige Version mit dem unnötigen Sortieren zu sein, das in 3250 ms ausgeführt wurde, nachdem der vermeidbare Überlauf entfernt wurde (auf Kosten einer etwas höheren Speicherzuteilung).
Der Plan nach der Ausführung (tatsächlich) ist fast genau derselbe wie der Plan vor der Ausführung:

Alle Schätzungen sind genau richtig, mit Ausnahme der Ausgabe der Fensterspule, die um 2 Zeilen daneben liegt. Die statistischen IO-Informationen sind genau die gleichen wie vor dem Entfernen von Sort, wie Sie es erwarten würden:
Table 'Example'. Scan count 1, logical reads 2999455, physical reads 0 Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0
Kurz zusammengefasst besteht der einzige offensichtliche Unterschied zwischen diesem neuen Plan und dem unmittelbar vorherigen darin, dass der Sort (mit einem geschätzten Kostenbeitrag von fast 80 %) entfernt wurde.
Es mag daher überraschen, zu erfahren, dass die neue Abfrage – ohne Sort – in 5000 ms ausgeführt wird . Das ist viel schlimmer als die 3250 ms mit der Sortierung und fast so lang wie die 5700 ms der ursprünglichen Loop-Join-Abfrage. Die Lösung mit doppelter Zeilennummerierung ist mit 2950 ms immer noch weit voraus.
Erklärung
Die Erklärung ist etwas esoterisch und bezieht sich auf die Art und Weise, wie Latches für die letzte Abfrage gehandhabt werden. Wir können diesen Effekt auf verschiedene Arten zeigen, aber am einfachsten ist es wahrscheinlich, sich die Warte- und Latch-Statistiken mit DMVs anzusehen:
DBCC SQLPERF('sys.dm_os_wait_stats', CLEAR);
DBCC SQLPERF('sys.dm_os_latch_stats', CLEAR);
WITH CED AS
(
SELECT
E.EndDate,
CalculatedEndDate =
DATEADD(DAY, -1,
LEAD(E.StartDate) OVER (
PARTITION BY E.SomeID
ORDER BY E.StartDate))
FROM dbo.Example AS E
)
UPDATE CED WITH (TABLOCKX)
SET CED.EndDate =
ISNULL
(
CED.CalculatedEndDate,
CONVERT(date, '99991231', 112)
)
OPTION (MAXDOP 1);
SELECT * FROM sys.dm_os_latch_stats AS DOLS
WHERE DOLS.waiting_requests_count > 0
ORDER BY DOLS.latch_class;
SELECT * FROM sys.dm_os_wait_stats AS DOWS
WHERE DOWS.waiting_tasks_count > 0
ORDER BY DOWS.waiting_tasks_count DESC; Wenn der gruppierte Index nicht eindeutig ist und eine Sortierung im Plan vorhanden ist, gibt es keine nennenswerten Wartezeiten, nur ein paar PAGEIOLATCH_UP-Wartezeiten und die erwarteten SOS_SCHEDULER_YIELDs.
Wenn der gruppierte Index eindeutig ist und die Sortierung entfernt wird, sind die Wartezeiten:
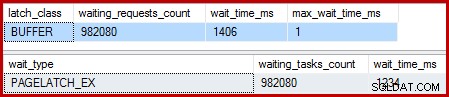
Dort gibt es 982.080 exklusive Seitenlatches mit einer Wartezeit, die so ziemlich die gesamte zusätzliche Ausführungszeit erklärt. Um es zu betonen, das ist fast eine Latch-Wartezeit pro aktualisierter Zeile! Wir könnten einen Latch pro Zeilenwechsel erwarten, aber kein Latch warten , insbesondere wenn die Testabfrage die einzige Aktivität auf der Instanz ist. Die Latch Waits sind kurz, aber es gibt sehr viele davon.
Lazy Latches
Nach der Abfrageausführung mit einem angeschlossenen Debugger und Analysator lautet die Erklärung wie folgt.
Der Clustered Index Scan verwendet Lazy Latches – eine Optimierung, die bedeutet, dass Latches nur freigegeben werden, wenn ein anderer Thread Zugriff auf die Seite benötigt. Normalerweise werden Latches unmittelbar nach dem Lesen oder Schreiben freigegeben. Lazy Latches optimieren den Fall, in dem das Scannen einer ganzen Seite andernfalls denselben Seitenlatch für jede Zeile erfassen und freigeben würde. Wenn Lazy Latch ohne Konkurrenz verwendet wird, wird nur ein einziger Latch für die ganze Seite verwendet.
Das Problem besteht darin, dass die Pipeline-Natur des Ausführungsplans (keine blockierenden Operatoren) bedeutet, dass sich Lesevorgänge mit Schreibvorgängen überschneiden. Wenn das Clustered Index Update versucht, einen EX-Latch zu erwerben, um eine Zeile zu modifizieren, wird es fast immer feststellen, dass die Seite bereits SH gelatcht ist (das faule Latch, das vom Clustered Index Scan verwendet wird). Diese Situation führt zu einem Latch Wait.
Als Teil der Vorbereitung auf das Warten und Wechseln zum nächsten ausführbaren Element im Planer achtet der Code darauf, alle faulen Latches freizugeben. Das Loslassen des faulen Riegels signalisiert dem ersten berechtigten Kellner, der zufällig er selbst ist. Wir haben also die seltsame Situation, in der ein Thread sich selbst blockiert, seinen Lazy Latch freigibt und sich dann selbst signalisiert, dass er wieder lauffähig ist. Der Thread nimmt wieder Fahrt auf und fährt fort, aber erst, nachdem all die vergeudete Suspend- und Switch-, Signal- und Resume-Arbeit erledigt wurde. Wie ich schon sagte, die Wartezeiten sind kurz, aber es gibt viele davon.
Soweit ich weiß, ist diese seltsame Abfolge von Ereignissen beabsichtigt und hat gute interne Gründe. Trotzdem kommt man nicht umhin, dass es hier einen ziemlich dramatischen Einfluss auf die Leistung hat. Ich werde diesbezüglich einige Nachforschungen anstellen und den Artikel aktualisieren, wenn es eine öffentliche Erklärung zu geben gibt. In der Zwischenzeit könnten übermäßige Self-Latch-Wartezeiten bei Pipeline-Aktualisierungsabfragen aufpassen, obwohl nicht klar ist, was aus Sicht des Abfrageautors dagegen getan werden sollte.
Bedeutet dies, dass die doppelte Zeilennummerierung das Beste ist, was wir für diese Abfrage tun können? Nicht ganz.
4. Manueller Halloween-Schutz
Diese letzte Option mag ein bisschen verrückt klingen und aussehen. Die allgemeine Idee besteht darin, alle Informationen zu schreiben, die zum Vornehmen der Änderungen an einer Tabellenvariablen erforderlich sind, und dann die Aktualisierung als separaten Schritt durchzuführen.
In Ermangelung einer besseren Beschreibung nenne ich dies den "manuellen HP"-Ansatz, weil es konzeptionell ähnlich dem Schreiben aller Änderungsinformationen in einen Eager Table Spool (wie in der ersten Abfrage zu sehen) ist, bevor das Update von diesem Spool ausgeführt wird.
Wie auch immer, der Code ist wie folgt:
DECLARE @U AS table
(
SomeID integer NOT NULL,
StartDate date NOT NULL,
NewEndDate date NULL,
PRIMARY KEY CLUSTERED (SomeID, StartDate)
);
INSERT @U
(SomeID, StartDate, NewEndDate)
SELECT
E.SomeID,
E.StartDate,
DATEADD(DAY, -1,
LEAD(E.StartDate) OVER (
PARTITION BY E.SomeID
ORDER BY E.StartDate))
FROM dbo.Example AS E WITH (TABLOCK)
OPTION (MAXDOP 1);
UPDATE E WITH (TABLOCKX)
SET E.EndDate =
ISNULL
(
U.NewEndDate, CONVERT(date, '99991231', 112)
)
FROM dbo.Example AS E
JOIN @U AS U
ON U.SomeID = E.SomeID
AND U.StartDate = E.StartDate
OPTION (MAXDOP 1, MERGE JOIN); Dieser Code verwendet absichtlich eine Tabellenvariable um die Kosten für automatisch erstellte Statistiken zu vermeiden, die durch die Verwendung einer temporären Tabelle entstehen würden. Dies ist hier in Ordnung, da ich die gewünschte Planform kenne und nicht von Kostenschätzungen oder statistischen Informationen abhängt.
Der einzige Nachteil der Tabellenvariablen (ohne Trace-Flag) besteht darin, dass der Optimierer normalerweise eine einzelne Zeile schätzt und verschachtelte Schleifen für die Aktualisierung auswählt. Um dies zu verhindern, habe ich einen Merge-Join-Hinweis verwendet. Auch dies wird durch die genaue Kenntnis der zu erreichenden Planform vorangetrieben.
Der Nachausführungsplan für das Einfügen der Tabellenvariable sieht genauso aus wie die Abfrage, bei der das Problem mit den Latch-Wartezeiten aufgetreten ist:

Der Vorteil dieses Plans besteht darin, dass er nicht dieselbe Tabelle ändert, aus der er liest. Es ist kein Halloween-Schutz erforderlich, und es besteht keine Möglichkeit einer Verriegelungsstörung. Darüber hinaus gibt es erhebliche interne Optimierungen für tempdb-Objekte (Sperren und Protokollieren) und andere normale Massenladeoptimierungen werden ebenfalls angewendet. Denken Sie daran, dass Massenoptimierungen nur für Einfügungen verfügbar sind, nicht für Aktualisierungen oder Löschungen.
Der Post-Execution-Plan für die Update-Anweisung lautet:
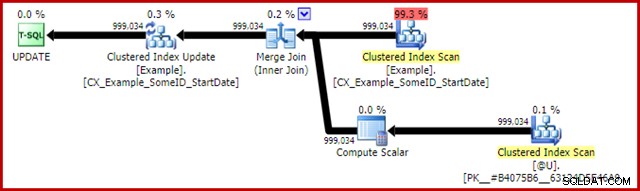
Der Merge Join ist hier der effiziente One-to-Many-Typ. Genauer gesagt qualifiziert sich dieser Plan für eine spezielle Optimierung, was bedeutet, dass der Clustered-Index-Scan und die Clustered-Index-Aktualisierung denselben Rowset verwenden. Die wichtige Konsequenz ist, dass das Update die zu aktualisierende Zeile nicht mehr lokalisieren muss – sie wird bereits durch das Lesen korrekt positioniert. Das spart eine Menge logischer Lesevorgänge (und andere Aktivitäten) beim Update.
In normalen Ausführungsplänen gibt es nichts, was zeigt, wo diese Shared Rowset-Optimierung angewendet wird, aber die Aktivierung des undokumentierten Ablaufverfolgungsflags 8666 macht zusätzliche Eigenschaften in Update und Scan verfügbar, die zeigen, dass die Rowset-Freigabe verwendet wird, und dass Schritte unternommen werden, um sicherzustellen, dass das Update sicher ist aus dem Halloween-Problem.
Die Statistik-IO-Ausgabe für die beiden Abfragen lautet wie folgt:
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0 Table 'Example'. Scan count 1, logical reads 2353, physical reads 0 (999034 row(s) affected) Table 'Example'. Scan count 1, logical reads 2353, physical reads 0 Table '#B9C034B8'. Scan count 1, logical reads 2353, physical reads 0
Beide Lesevorgänge der Beispieltabelle umfassen einen einzelnen Scan und einen logischen Lesevorgang pro Seite (siehe die einfache Abfrage zum Zählen von Zeilen weiter oben). Die Tabelle #B9C034B8 ist der Name des internen tempdb-Objekts, das die Tabellenvariable unterstützt. Die gesamten logischen Lesevorgänge für beide Abfragen betragen 3 * 2353 =7.059. Die Arbeitstabelle ist der interne Speicher im Arbeitsspeicher, der von der Windows-Spool verwendet wird.
Die typische Ausführungszeit für diese Abfrage beträgt 2300 ms . Endlich haben wir etwas, das die Abfrage mit doppelter Zeilennummerierung (2950 ms) übertrifft, so unwahrscheinlich es scheinen mag.
Abschließende Gedanken
Möglicherweise gibt es sogar noch bessere Möglichkeiten, dieses Update zu schreiben, die noch besser funktionieren als die oben genannte „manuelle HP“-Lösung. Die Leistungsergebnisse können je nach Hardware und SQL Server-Konfiguration sogar unterschiedlich sein, aber beides ist nicht der Hauptpunkt dieses Artikels. Das soll nicht heißen, dass ich nicht an besseren Abfragen oder Leistungsvergleichen interessiert bin – das bin ich.
Der Punkt ist, dass innerhalb von SQL Server sehr viel mehr vor sich geht, als in Ausführungsplänen offengelegt wird. Hoffentlich sind einige der in diesem ziemlich langen Artikel besprochenen Details für einige Leute interessant oder sogar nützlich.
Es ist gut, Erwartungen an die Leistung zu haben und zu wissen, welche Planformen und -eigenschaften im Allgemeinen vorteilhaft sind. Diese Art von Erfahrung und Wissen wird Ihnen bei 99 % oder mehr der Anfragen, die Sie jemals tunen müssen, von Nutzen sein. Manchmal ist es jedoch gut, etwas Seltsames oder Ungewöhnliches auszuprobieren, nur um zu sehen, was passiert, und um diese Erwartungen zu bestätigen.