Einführung
Eine eifrige Indexspule liest alle Zeilen von seinem untergeordneten Operator in eine indizierte Arbeitstabelle, bevor er beginnt, Zeilen an seinen übergeordneten Operator zurückzugeben. In gewisser Hinsicht ist eine eifrige Indexspule der ultimative fehlende Indexvorschlag , aber es wird nicht als solches gemeldet.
Kostenschätzung
Das Einfügen von Zeilen in eine indizierte Arbeitstabelle ist relativ kostengünstig, aber nicht kostenlos. Der Optimierer muss bedenken, dass der Arbeitsaufwand mehr spart als kostet. Damit sich dies zugunsten der Spule auswirkt, muss der Plan so geschätzt werden, dass er Zeilen von der Spule mehr als einmal verbraucht. Andernfalls könnte es genauso gut die Spule überspringen und nur dieses eine Mal die zugrunde liegende Operation ausführen.
- Um mehr als einmal darauf zugreifen zu können, muss der Spool auf der Innenseite eines Join-Operators mit verschachtelten Schleifen erscheinen.
- Jede Iteration der Schleife sollte nach einem bestimmten Index-Spool-Schlüsselwert suchen, der von der äußeren Seite der Schleife bereitgestellt wird.
Das bedeutet, dass der Join ein apply sein muss , kein Join mit verschachtelten Schleifen . Den Unterschied zwischen den beiden finden Sie in meinem Artikel Apply versus Nested Loops Join.
Bemerkenswerte Funktionen
Während eine eifrige Indexspule nur auf der Innenseite einer verschachtelten Schleife anwenden erscheinen kann , es ist keine „Leistungsspule“. Ein Eifer-Index-Spool kann nicht mit Ablaufverfolgungsflag 8690 oder NO_PERFORMANCE_SPOOL deaktiviert werden Abfragehinweis.
Zeilen, die in die Index-Spool-Datei eingefügt werden, werden normalerweise nicht in der Reihenfolge der Indexschlüssel vorsortiert, was zu Indexseitenteilungen führen kann. Das undokumentierte Trace-Flag 9260 kann verwendet werden, um eine Sortierung zu generieren Operator vor der Indexspule, um dies zu vermeiden. Der Nachteil ist, dass die zusätzlichen Sortierkosten den Optimierer möglicherweise davon abhalten, die Spool-Option überhaupt zu wählen.
SQL Server unterstützt keine parallelen Einfügungen in einen B-Tree-Index. Das bedeutet, dass alles unterhalb eines parallelen Eager-Index-Spools auf einem einzigen Thread läuft. Die Operatoren unter der Spule sind immer noch (irreführend) mit dem Parallelitätssymbol gekennzeichnet. Ein Thread wird zum Schreiben ausgewählt zur Spule. Die anderen Threads warten auf EXECSYNC während das abgeschlossen ist. Sobald die Spule gefüllt ist, kann sie ausgelesen werden durch parallele Threads.
Index-Spools teilen dem Optimierer nicht mit, dass sie eine nach den Indexschlüsseln der Spule geordnete Ausgabe unterstützen. Wenn eine sortierte Ausgabe von der Spule erforderlich ist, sehen Sie möglicherweise ein unnötiges Sortieren Operator. Eifrige Indexspulen sollten ohnehin oft durch einen permanenten Index ersetzt werden, daher ist dies die meiste Zeit ein untergeordnetes Problem.
Es gibt fünf Optimierungsregeln, die einen Eager Index Spool generieren können Option (intern als index on-the-fly bezeichnet ). Wir werden uns drei davon im Detail ansehen, um zu verstehen, woher eifrige Indexspulen kommen.
SelToIndexOnTheFly
Dies ist die häufigste. Es stimmt mit einer oder mehreren relationalen Auswahlen (auch bekannt als Filter oder Prädikate) direkt über einem Datenzugriffsoperator überein. Der SelToIndexOnTheFly Die Regel ersetzt die Prädikate durch ein Suchprädikat auf einer eifrigen Indexspule.
Demo
Ein AdventureWorks Beispieldatenbankbeispiel ist unten gezeigt:
SELECT
P.ProductID,
P.[Name],
P.SafetyStockLevel,
TH.Quantity
FROM Production.Product AS P
CROSS APPLY
(
SELECT MAX(TH.Quantity)
FROM Production.TransactionHistory AS TH
WHERE
TH.ProductID = P.ProductID
AND TH.Quantity < P.SafetyStockLevel
GROUP BY ()
) AS TH (Quantity)
WHERE
P.[Name] LIKE N'A%';
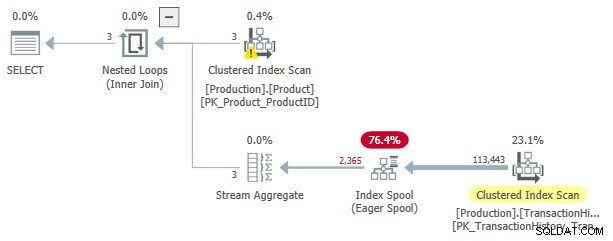
Dieser Ausführungsplan hat geschätzte Kosten von 3,0881 Einheiten. Einige Punkte von Interesse:
- Der innere Join mit verschachtelten Schleifen Operator ist ein apply , mit
ProductIDundSafetyStockLevelaus demProductTabelle als äußere Referenzen . - Bei der ersten Iteration des apply, der Eager Index Spool wird vollständig aus dem Clustered Index Scan ausgefüllt des
TransactionHistoryTabelle. - Die Arbeitstabelle der Spule hat einen gruppierten Index, der auf
(ProductID, Quantity)codiert ist . - Zeilen, die den Prädikaten
TH.ProductID = P.ProductIDentsprechen undTH.Quantity < P.SafetyStockLevelwerden von der Spule mit ihrem Index beantwortet. Dies gilt für jede Iteration der Anwendung, einschließlich der ersten. - Der
TransactionHistoryTabelle wird nur einmal gescannt.
Sortierte Eingabe in die Spule
Es ist möglich, eine sortierte Eingabe in den Eifer-Index-Spool zu erzwingen, aber dies wirkt sich auf die geschätzten Kosten aus, wie in der Einführung erwähnt. Für das obige Beispiel erzeugt das Aktivieren des undokumentierten Trace-Flags einen Plan ohne Spool:
SELECT
P.ProductID,
P.[Name],
P.SafetyStockLevel,
TH.Quantity
FROM Production.Product AS P
CROSS APPLY
(
SELECT
MAX(TH.Quantity)
FROM Production.TransactionHistory AS TH
WHERE
TH.ProductID = P.ProductID
AND TH.Quantity < P.SafetyStockLevel
GROUP BY ()
) AS TH (Quantity)
WHERE
P.[Name] LIKE N'A%'
OPTION (QUERYTRACEON 9260);
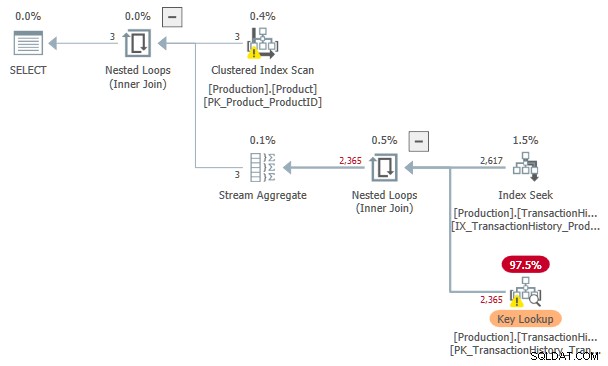
Die geschätzten Kosten dieser Indexsuche und Schlüsselsuche Plan ist 3.11631 Einheiten. Das ist mehr als die Kosten für den Plan mit Index-Spool allein, aber weniger als für den Plan mit Index-Spool und sortierter Eingabe.
Um einen Plan mit sortierter Eingabe in die Spule zu sehen, müssen wir die erwartete Anzahl von Schleifeniterationen erhöhen. Dies gibt der Spule die Möglichkeit, die zusätzlichen Kosten des Sortierens zurückzuzahlen . Eine Möglichkeit, die Anzahl der vom Product erwarteten Zeilen zu erweitern Tabelle soll den Name bilden Prädikat weniger restriktiv:
SELECT
P.ProductID,
P.[Name],
P.SafetyStockLevel,
TH.Quantity
FROM Production.Product AS P
CROSS APPLY
(
SELECT
MAX(TH.Quantity)
FROM Production.TransactionHistory AS TH
WHERE
TH.ProductID = P.ProductID
AND TH.Quantity < P.SafetyStockLevel
GROUP BY ()
) AS TH (Quantity)
WHERE
P.[Name] LIKE N'[A-P]%'
OPTION (QUERYTRACEON 9260); Dies gibt uns einen Ausführungsplan mit sortierter Eingabe in die Spule:
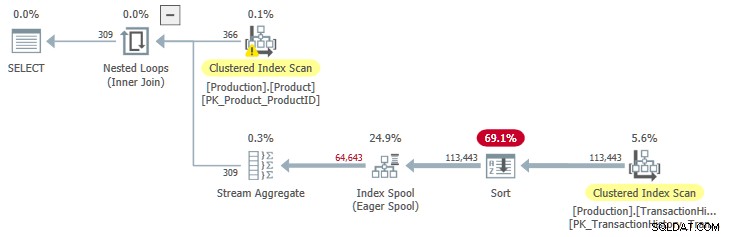
JoinToIndexOnTheFly
Diese Regel transformiert einen Inner Join zu einer Bewerbung , mit einer eifrigen Indexspule auf der Innenseite. Mindestens eines der Join-Prädikate muss eine Ungleichheit sein, damit diese Regel übereinstimmt.
Dies ist eine viel spezialisiertere Regel als SelToIndexOnTheFly , aber die Idee ist die gleiche. In diesem Fall wird die in eine Index-Spool-Suche umgewandelte Auswahl (Prädikat) dem Join zugeordnet. Die Transformation von join zu apply ermöglicht das Verschieben des Join-Prädikats vom Join selbst auf die Innenseite des apply.
Demo
SELECT
P.ProductID,
P.[Name],
P.SafetyStockLevel,
Quantity = MAX(TH.Quantity)
FROM Production.Product AS P
JOIN Production.TransactionHistory AS TH
ON TH.ProductID = P.ProductID
AND TH.Quantity < P.SafetyStockLevel
WHERE
P.[Name] LIKE N'[A-P]%'
GROUP BY
P.ProductID,
P.[Name],
P.SafetyStockLevel
OPTION (LOOP JOIN);
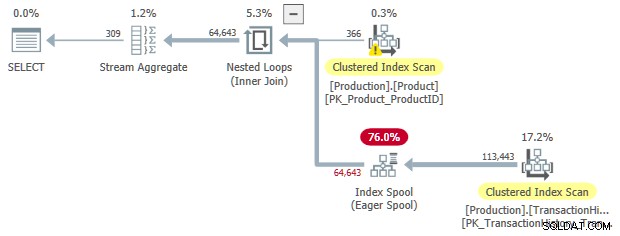
Wie zuvor können wir eine sortierte Eingabe für die Spule anfordern:
SELECT
P.ProductID,
P.[Name],
P.SafetyStockLevel,
Quantity = MAX(TH.Quantity)
FROM Production.Product AS P
JOIN Production.TransactionHistory AS TH
ON TH.ProductID = P.ProductID
AND TH.Quantity < P.SafetyStockLevel
WHERE
P.[Name] LIKE N'[A-P]%'
GROUP BY
P.ProductID,
P.[Name],
P.SafetyStockLevel
OPTION (LOOP JOIN, QUERYTRACEON 9260);
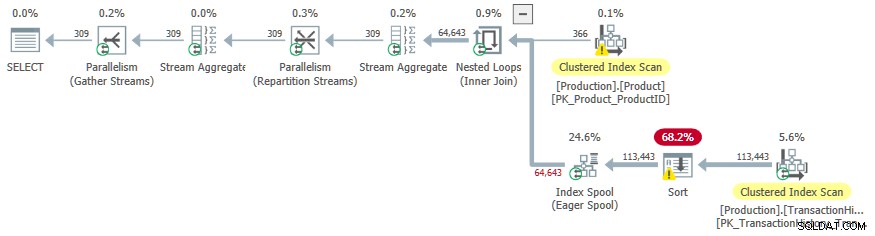
Diesmal haben die zusätzlichen Kosten für die Sortierung den Optimierer dazu veranlasst, einen parallelen Plan zu wählen.
Ein unerwünschter Nebeneffekt ist das Sortieren Operator wird zu tempdb verschüttet . Die zum Sortieren verfügbare Gesamtspeicherzuteilung ist ausreichend, wird aber (wie üblich) gleichmäßig auf parallele Threads aufgeteilt. Wie in der Einführung erwähnt, unterstützt SQL Server keine parallelen Einfügungen in einen B-Tree-Index, sodass die Operatoren unterhalb des Eager-Index-Spools in einem einzigen Thread ausgeführt werden. Dieser einzelne Thread bekommt nur einen Bruchteil der Speicherzuteilung, also die Sortierung verschüttet zu tempdb .
Dieser Nebeneffekt ist vielleicht ein Grund dafür, dass das Trace-Flag nicht dokumentiert ist und nicht unterstützt wird.
SelSTVFToIdxOnFly
Diese Regel macht dasselbe wie SelToIndexOnTheFly , aber für eine Streaming-Tabellenwertfunktion (sTVF) Zeilenquelle. Diese sTVFs werden intern ausgiebig verwendet, um unter anderem DMVs und DMFs zu implementieren. Sie erscheinen in modernen Ausführungsplänen als Table Valued Function Operatoren (ursprünglich als Remote Table Scans ).
In der Vergangenheit konnten viele dieser sTVFs keine korrelierten Parameter von einem apply. akzeptieren Sie könnten Literale, Variablen und Modulparameter akzeptieren, aber nicht anwenden äußere Bezüge. Es gibt immer noch Warnungen dazu in der Dokumentation, aber sie sind jetzt etwas veraltet.
Wie auch immer, der Punkt ist, dass es SQL Server manchmal nicht möglich ist, ein apply zu übergeben äußere Referenz als Parameter zu einem sTVF. In dieser Situation kann es sinnvoll sein, einen Teil des sTVF-Ergebnisses in einer eifrigen Indexspule zu materialisieren. Die vorliegende Regel bietet diese Möglichkeit.
Demo
Das nächste Codebeispiel zeigt eine DMV-Abfrage, die erfolgreich von einem Join in ein apply konvertiert wurde . Äußere Referenzen werden als Parameter an die zweite DMV übergeben:
-- Transformed to an apply
-- Outer reference passed as a parameter
SELECT
DES.session_id,
DES.login_time,
DESWS.waiting_tasks_count
FROM sys.dm_exec_sessions AS DES
JOIN sys.dm_exec_session_wait_stats AS DESWS
ON DESWS.session_id = DES.session_id
OPTION (FORCE ORDER);
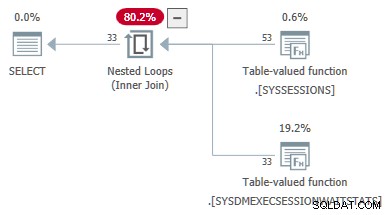
Die Planeigenschaften der Wartestatistik TVF zeigen die Eingabeparameter. Der zweite Parameterwert wird als äußere Referenz bereitgestellt aus den Sitzungen DMV:
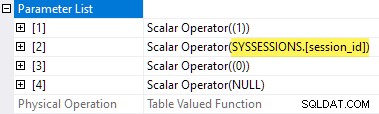
Schade, dass sys.dm_exec_session_wait_stats ist eine Ansicht, keine Funktion, denn das hindert uns daran, ein apply zu schreiben direkt.
Die folgende Umschreibung reicht aus, um die interne Konvertierung zu verhindern:
-- Rewrite to avoid TVF parameter trickery
SELECT
DES.session_id,
DES.login_time,
DESWS.waiting_tasks_count
FROM sys.dm_exec_sessions AS DES
JOIN sys.dm_exec_session_wait_stats AS DESWS
ON DESWS.session_id >= DES.session_id
AND DESWS.session_id <= DES.session_id
OPTION (FORCE ORDER);
Mit der session_id Prädikate werden jetzt nicht als Parameter verwendet, der SelSTVFToIdxOnFly Regel steht es frei, sie in einen Eifer-Index-Spool umzuwandeln:
Ich möchte nicht den Eindruck hinterlassen, dass knifflige Umschreibungen erforderlich sind, um einen eifrigen Index-Spool über eine DMV-Quelle zu bekommen – es macht nur eine einfachere Demo. Wenn Sie zufällig auf eine Abfrage mit DMV-Joins stoßen, die einen Plan mit einem eifrigen Spool erzeugt, wissen Sie zumindest, wie er dorthin gelangt ist.
Sie können keine Indizes auf DMVs erstellen, daher müssen Sie möglicherweise einen Hash- oder Merge-Join verwenden, wenn der Ausführungsplan nicht gut genug funktioniert.
Rekursive CTEs
Die verbleibenden zwei Regeln sind SelIterToIdxOnFly und JoinIterToIdxOnFly . Sie sind direkte Gegenstücke zu SelToIndexOnTheFly und JoinToIndexOnTheFly für rekursive CTE-Datenquellen. Diese sind meiner Erfahrung nach äußerst selten, daher werde ich keine Demos für sie bereitstellen. (Ebenso der Iter Teil des Regelnamens sinnvoll:Er kommt daher, dass SQL Server die Endrekursion als verschachtelte Iteration implementiert.)
Wenn innerhalb einer Anwendung mehrmals auf einen rekursiven CTE verwiesen wird, gilt eine andere Regel (SpoolOnIterator ) kann das Ergebnis des CTE zwischenspeichern:
WITH R AS
(
SELECT 1 AS n
UNION ALL
SELECT R.n + 1
FROM R
WHERE R.n < 10
)
SELECT
R1.n
FROM R AS R1
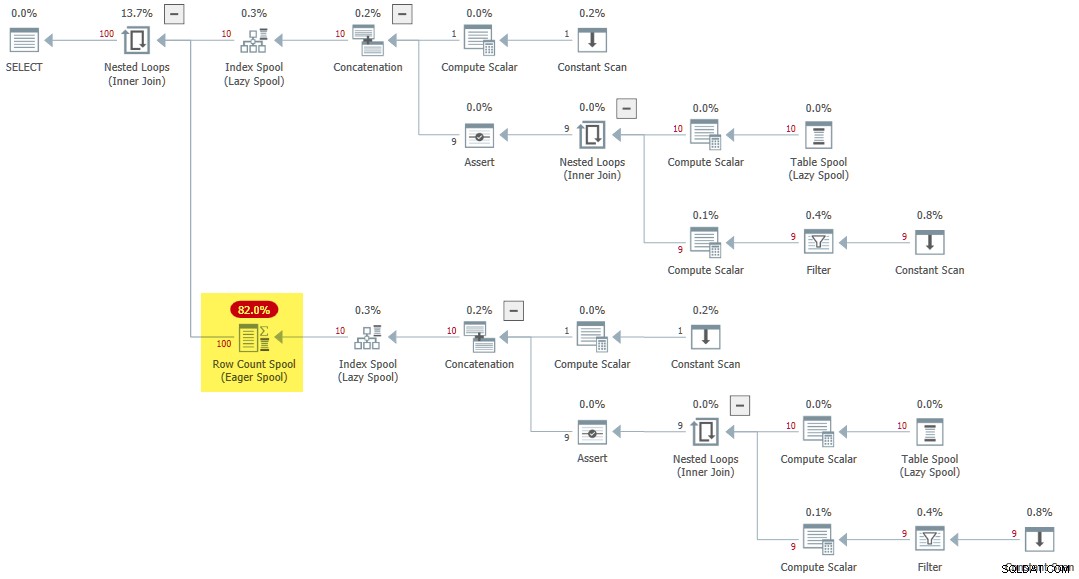
CROSS JOIN R AS R2; Der Ausführungsplan enthält eine seltene Eager Row Count Spool :
Abschließende Gedanken
Eifrige Index-Spools sind oft ein Zeichen dafür, dass dem Datenbankschema ein nützlicher permanenter Index fehlt. Dies ist nicht immer der Fall, wie die Beispiele für Streaming-Tabellenwertfunktionen zeigen.