Ich habe zuvor über die Eigenschaft Actual Rows Read geschrieben. Es sagt Ihnen, wie viele Zeilen tatsächlich von einer Indexsuche gelesen werden, sodass Sie sehen können, wie selektiv das Seek-Prädikat ist, verglichen mit der Selektivität des Seek-Prädikats plus Residual-Prädikat kombiniert.
Aber werfen wir einen Blick darauf, was tatsächlich im Seek-Operator vor sich geht. Weil ich nicht davon überzeugt bin, dass „Actual Rows Read“ unbedingt eine genaue Beschreibung dessen ist, was vor sich geht.
Ich möchte ein Beispiel betrachten, das Adressen bestimmter Adresstypen für einen Kunden abfragt, aber das Prinzip hier würde sich leicht auf viele andere Situationen anwenden lassen, wenn die Form Ihrer Abfrage passt, z. B. das Nachschlagen von Attributen in einer Schlüssel-Wert-Paar-Tabelle, zum Beispiel.
SELECT AddressTypeID, FullAddress FROM dbo.Addresses WHERE CustomerID = 783 AND AddressTypeID IN (2,4,5);
Ich weiß, dass ich Ihnen nichts über die Metadaten gezeigt habe – ich werde gleich darauf zurückkommen. Lassen Sie uns über diese Abfrage nachdenken und welche Art von Index wir dafür haben möchten.
Erstens kennen wir die CustomerID genau. Eine Gleichheitsübereinstimmung wie diese macht sie im Allgemeinen zu einem hervorragenden Kandidaten für die erste Spalte in einem Index. Wenn wir einen Index für diese Spalte hätten, könnten wir direkt in die Adressen dieses Kunden eintauchen – also würde ich sagen, dass das eine sichere Annahme ist.
Das nächste, was zu berücksichtigen ist, ist der Filter auf AddressTypeID. Das Hinzufügen einer zweiten Spalte zu den Schlüsseln unseres Indexes ist absolut sinnvoll, also machen wir das. Unser Index ist jetzt aktiviert (CustomerID, AddressTypeID). Und lassen Sie uns auch die vollständige Adresse einschließen, damit wir keine Nachschlagevorgänge durchführen müssen, um das Bild zu vervollständigen.
Und ich denke, wir sind fertig. Wir sollten davon ausgehen können, dass der ideale Index für diese Abfrage lautet:
CREATE INDEX ixIdealIndex ON dbo.Addresses (CustomerID, AddressTypeID) INCLUDE (FullAddress);
Wir könnten ihn möglicherweise als eindeutigen Index deklarieren – wir werden uns später mit den Auswirkungen befassen.
Lassen Sie uns also eine Tabelle erstellen (ich verwende tempdb, weil ich sie nicht über diesen Blogbeitrag hinaus benötige) und testen.
CREATE TABLE dbo.Addresses ( AddressID INT IDENTITY(1,1) PRIMARY KEY, CustomerID INT NOT NULL, AddressTypeID INT NOT NULL, FullAddress NVARCHAR(MAX) NOT NULL, SomeOtherColumn DATE NULL );
Ich interessiere mich nicht für Fremdschlüsseleinschränkungen oder welche anderen Spalten es geben könnte. Mich interessiert nur mein idealer Index. Erstellen Sie das also auch, falls Sie es noch nicht getan haben.
Mein Plan scheint ziemlich perfekt zu sein.
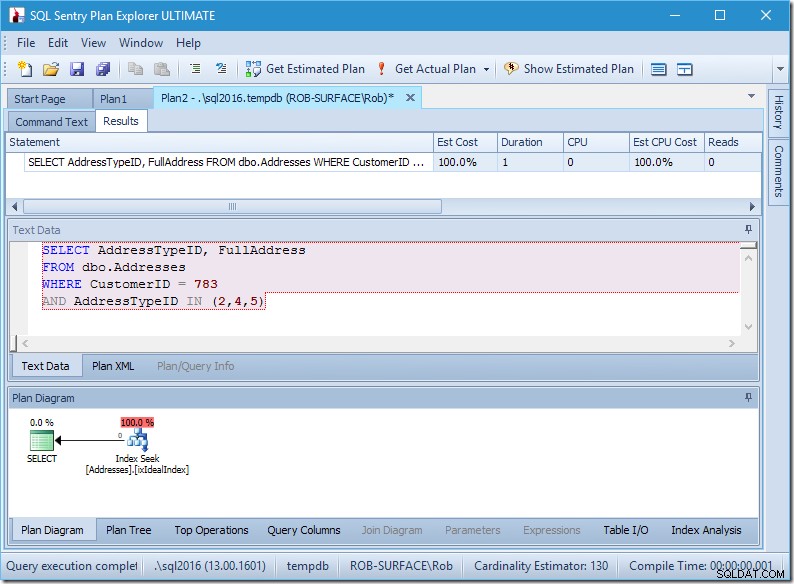
Ich habe eine Indexsuche, und das war's.
Zugegeben, es gibt keine Daten, also keine Lesevorgänge, keine CPU, und es läuft auch ziemlich schnell. Wenn nur alle Abfragen so gut abgestimmt werden könnten.
Lassen Sie uns etwas genauer sehen, was vor sich geht, indem wir uns die Eigenschaften von Seek ansehen.
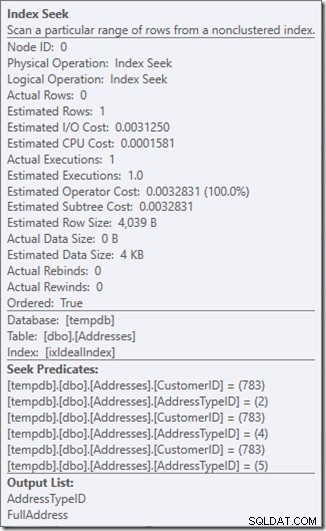
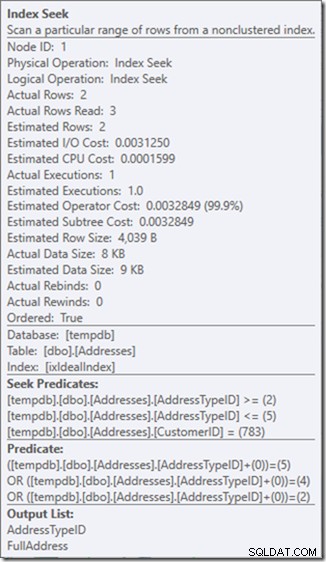
Wir können die Suchprädikate sehen. Es gibt sechs. Drei über die CustomerID und drei über die AddressTypeID. Was wir hier tatsächlich haben, sind drei Sätze von Suchprädikaten, die drei Suchoperationen innerhalb des einzelnen Seek-Operators anzeigen. Die erste Suche sucht nach Customer 783 und AddressType 2. Die zweite sucht nach 783 und 4 und die letzte 783 und 5. Unser Seek-Operator tauchte einmal auf, aber es gab drei Suchvorgänge darin.
Wir haben nicht einmal Daten, aber wir können sehen, wie unser Index verwendet wird.
Lassen Sie uns einige Dummy-Daten einfügen, damit wir uns einige der Auswirkungen ansehen können. Ich werde Adressen für die Typen 1 bis 6 eingeben. Jeder Kunde (über 2000, basierend auf der Größe von master..spt_values ) wird eine Adresse vom Typ 1 haben. Vielleicht ist das die primäre Adresse. Ich lasse 80 % eine Adresse vom Typ 2 haben, 60 % eine Adresse vom Typ 3 und so weiter, bis zu 20 % für Typ 5. Zeile 783 erhält Adressen vom Typ 1, 2, 3 und 4, aber nicht 5. Ich wäre lieber mit zufälligen Werten gegangen, aber ich möchte sicherstellen, dass wir uns bei den Beispielen auf derselben Seite befinden.
WITH nums AS (
SELECT row_number() OVER (ORDER BY (SELECT 1)) AS num
FROM master..spt_values
)
INSERT dbo.Addresses (CustomerID, AddressTypeID, FullAddress)
SELECT num AS CustomerID, 1 AS AddressTypeID, N'Some sample text for the address' AS FullAddress
FROM nums
UNION ALL
SELECT num AS CustomerID, 2 AS AddressTypeID, N'Some sample text for the address' AS FullAddress
FROM nums
WHERE num % 10 < 8
UNION ALL
SELECT num AS CustomerID, 3 AS AddressTypeID, N'Some sample text for the address' AS FullAddress
FROM nums
WHERE num % 10 < 6
UNION ALL
SELECT num AS CustomerID, 4 AS AddressTypeID, N'Some sample text for the address' AS FullAddress
FROM nums
WHERE num % 10 < 4
UNION ALL
SELECT num AS CustomerID, 5 AS AddressTypeID, N'Some sample text for the address' AS FullAddress
FROM nums
WHERE num % 10 < 2
; Sehen wir uns nun unsere Abfrage mit Daten an. Zwei Reihen kommen heraus. Es ist wie zuvor, aber wir sehen jetzt die zwei Zeilen, die aus dem Seek-Operator kommen, und wir sehen sechs Lesevorgänge (oben rechts).
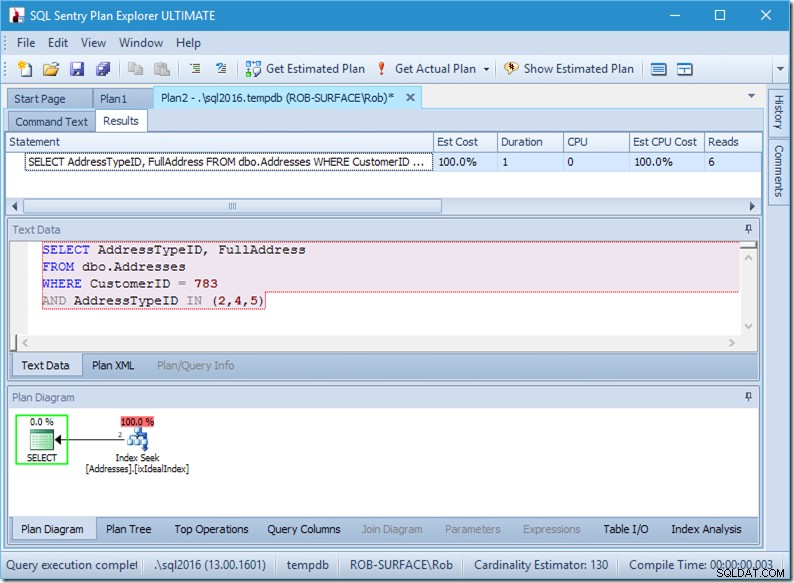
Sechs Lesevorgänge machen für mich Sinn. Wir haben eine kleine Tabelle, und der Index passt auf nur zwei Ebenen. Wir führen drei Suchvorgänge durch (innerhalb unseres einen Operators), also liest die Engine die Stammseite, findet heraus, zu welcher Seite sie heruntergehen muss, und liest diese, und das dreimal.
Wenn wir nur nach zwei AddressTypeIDs suchen würden, würden wir nur 4 Lesevorgänge sehen (und in diesem Fall eine einzelne Zeile, die ausgegeben wird). Ausgezeichnet.
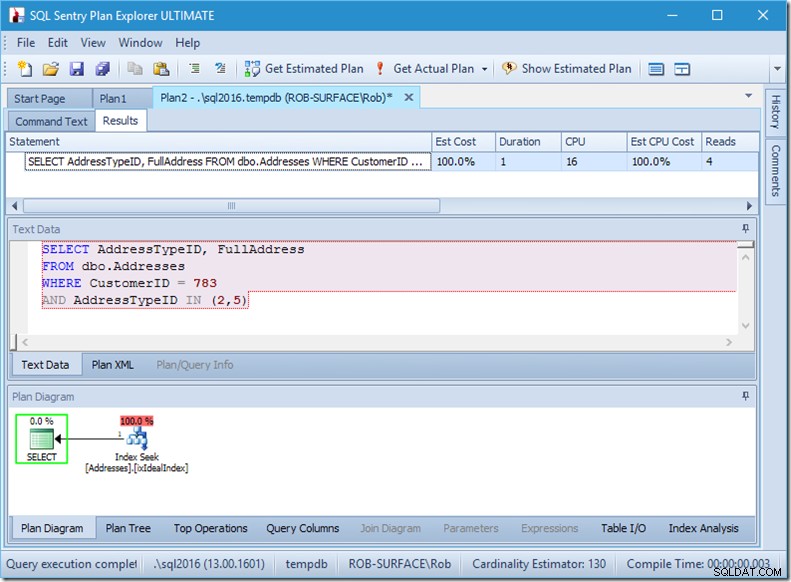
Und wenn wir nach 8 Adresstypen suchen würden, würden wir 16 sehen.
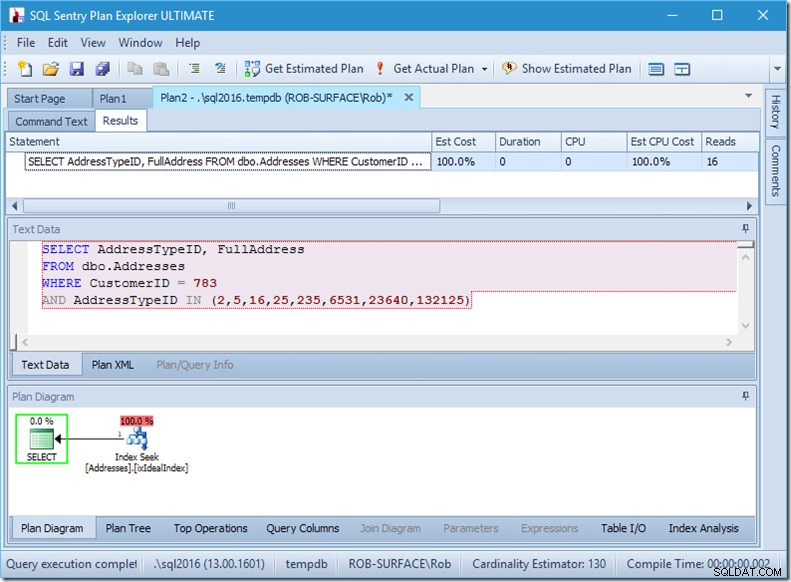
Dennoch zeigen alle, dass die tatsächlich gelesenen Zeilen genau mit den tatsächlichen Zeilen übereinstimmen. Überhaupt keine Ineffizienz!
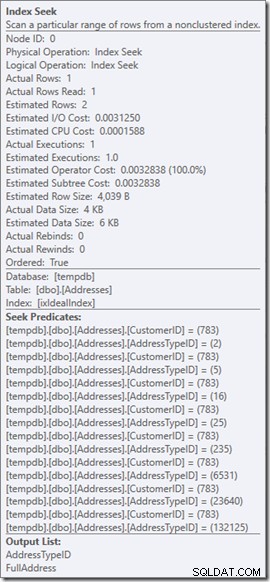
Kehren wir zu unserer ursprünglichen Abfrage zurück, suchen nach den Adresstypen 2, 4 und 5 (die 2 Zeilen zurückgeben) und überlegen, was in der Suche vor sich geht.
Ich gehe davon aus, dass die Abfrage-Engine bereits die Arbeit erledigt hat, um herauszufinden, dass die Indexsuche die richtige Operation ist und dass sie die Seitenzahl des Indexstamms zur Hand hat.
An diesem Punkt lädt es diese Seite in den Speicher, falls sie nicht bereits vorhanden ist. Das ist der erste Lesevorgang, der bei der Ausführung der Suche gezählt wird. Dann findet es die Seitenzahl für die gesuchte Zeile und liest diese Seite ein. Das ist der zweite Lesevorgang.
Aber wir beschönigen oft das Bit „findet die Seitenzahl“.
Durch die Verwendung von DBCC IND(2, N'dbo.Address', 2); (die erste 2 ist die Datenbank-ID, weil ich tempdb verwende; die zweite 2 ist die Index-ID von ixIdealIndex ), kann ich feststellen, dass die 712 in Datei 1 die Seite mit dem höchsten IndexLevel ist. Im Screenshot unten kann ich sehen, dass Seite 668 IndexLevel 0 ist, was die Stammseite ist.

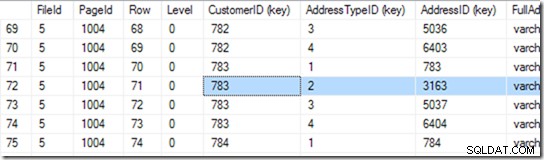
Jetzt kann ich also DBCC TRACEON(3604); DBCC PAGE (2,1,712,3); um den Inhalt von Seite 712 zu sehen. Auf meinem Rechner bekomme ich 84 Zeilen zurück, und ich kann sagen, dass die Kunden-ID 783 auf Seite 1004 von Datei 5 sein wird.
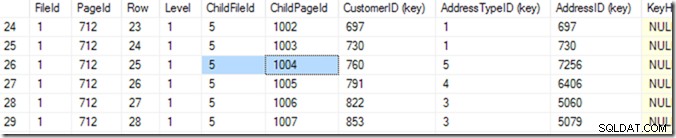
Aber ich weiß das, indem ich durch meine Liste scrolle, bis ich die sehe, die ich will. Ich begann damit, ein wenig nach unten zu scrollen, und kam dann wieder nach oben, bis ich die gewünschte Zeile gefunden hatte. Ein Computer nennt dies eine binäre Suche, und sie ist etwas präziser als ich. Es wird nach der Zeile gesucht, in der die Kombination (CustomerID, AddressTypeID) kleiner ist als die, nach der ich suche, wobei die nächste Seite größer oder gleich ist. Ich sage „dasselbe“, weil es zwei geben könnte, die übereinstimmen, verteilt auf zwei Seiten. Es weiß, dass es 84 Zeilen (0 bis 83) mit Daten auf dieser Seite gibt (das liest es im Seitenkopf), also beginnt es mit der Überprüfung von Zeile 41. Von dort weiß es, in welcher Hälfte es suchen muss und (in In diesem Beispiel) liest es Zeile 20. Ein paar weitere Lesevorgänge (insgesamt 6 oder 7)* und es kennt diese Zeile 25 (bitte schauen Sie sich die Spalte mit dem Namen "Row" für diesen Wert an, nicht die von SSMS bereitgestellte Zeilennummer ) ist zu klein, aber Zeile 26 ist zu groß – also ist 25 die Antwort!
*Bei einer binären Suche kann die Suche geringfügig schneller sein, wenn sie Glück hat, wenn der Block in zwei Teile geteilt wird, wenn es keinen mittleren Slot gibt, und je nachdem, ob der mittlere Slot eliminiert werden kann oder nicht.
Jetzt kann es auf Seite 1004 in Datei 5 gehen. Lassen Sie uns DBCC PAGE auf dieser Seite verwenden.
Dieser gibt mir 94 Zeilen. Es führt eine weitere binäre Suche durch, um den Anfang des gesuchten Bereichs zu finden. Es muss 6 oder 7 Zeilen durchsuchen, um das zu finden.
„Beginn des Bereichs?“ Ich kann dich fragen hören. Aber wir suchen den Adresstyp 2 des Kunden 783.
Richtig, aber wir haben diesen Index nicht als eindeutig deklariert. Es könnten also zwei sein. Wenn es eindeutig ist, kann die Suche eine Singleton-Suche durchführen und könnte während der binären Suche darüber stolpern, aber in diesem Fall muss es die binäre Suche abschließen, um die erste Zeile im Bereich zu finden. In diesem Fall ist es die Zeile 71.
Aber wir hören hier nicht auf. Jetzt müssen wir sehen, ob es wirklich einen zweiten gibt! Es liest also auch Zeile 72 und stellt fest, dass das Paar CustomerID+AddressTypeiD tatsächlich zu groß ist, und die Suche ist abgeschlossen.
Und das passiert dreimal. Beim dritten Mal findet es keine Zeile für Kunde 783 und Adresstyp 5, aber es weiß dies nicht im Voraus und muss die Suche noch abschließen.
Die Zeilen, die tatsächlich über diese drei Suchvorgänge gelesen werden (um zwei Zeilen für die Ausgabe zu finden), sind also viel mehr als die zurückgegebene Zahl. Es gibt ungefähr 7 auf Indexebene 1 und ungefähr 7 weitere auf Blattebene, nur um den Anfang des Bereichs zu finden. Dann liest es die Zeile, die uns wichtig ist, und dann die Zeile danach. Das klingt für mich eher nach 16, und das dreimal, was ungefähr 48 Zeilen ergibt.
Bei Actual Rows Read geht es jedoch nicht um die Anzahl der tatsächlich gelesenen Zeilen, sondern um die Anzahl der vom Suchprädikat zurückgegebenen Zeilen, die gegen das Restprädikat getestet werden. Und dabei werden nur die 2 Zeilen von den 3 Suchvorgängen gefunden.
Sie könnten an dieser Stelle denken, dass hier eine gewisse Ineffektivität vorliegt. Die zweite Suche hätte auch Seite 712 gelesen, die gleichen 6 oder 7 Zeilen dort überprüft und dann Seite 1004 gelesen und sie durchsucht … genau wie die dritte Suche.
Vielleicht wäre es also besser gewesen, dies in einer einzigen Suche zu bekommen und Seite 712 und Seite 1004 jeweils nur einmal zu lesen. Wenn ich dies mit einem papierbasierten System tun würde, hätte ich schließlich nach Kunde 783 gesucht und dann alle seine Adresstypen durchsucht. Weil ich weiß, dass ein Kunde nicht viele Adressen hat. Das ist ein Vorteil, den ich gegenüber der Datenbank-Engine habe. Die Datenbank-Engine weiß durch ihre Statistiken, dass eine Suche am besten ist, aber sie weiß nicht, dass die Suche nur eine Ebene tiefer gehen sollte, wenn sie erkennen kann, dass sie einen scheinbar idealen Index hat.
Wenn ich meine Abfrage so ändere, dass sie eine Reihe von Adresstypen von 2 bis 5 erfasst, erhalte ich fast das gewünschte Verhalten:
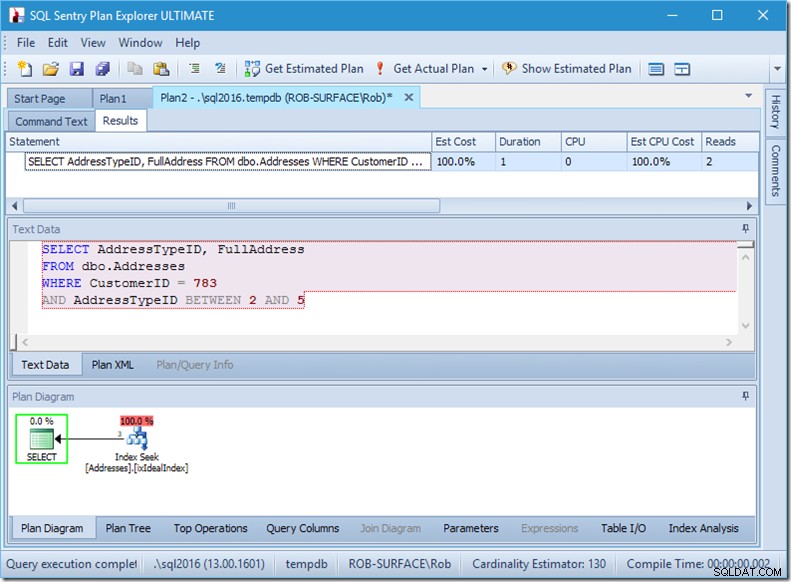
Schauen Sie – die Lesevorgänge sind auf 2 gesunken, und ich weiß, welche Seiten sie sind …
…aber meine Ergebnisse sind falsch. Weil ich nur die Adresstypen 2, 4 und 5 haben möchte, nicht 3. Ich muss ihm sagen, dass es nicht 3 haben soll, aber ich muss vorsichtig sein, wie ich das mache. Sehen Sie sich die nächsten beiden Beispiele an.
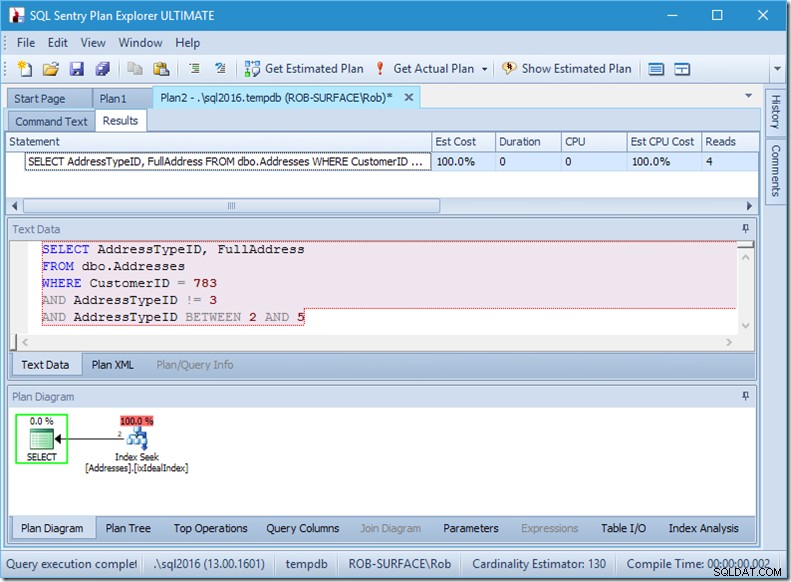
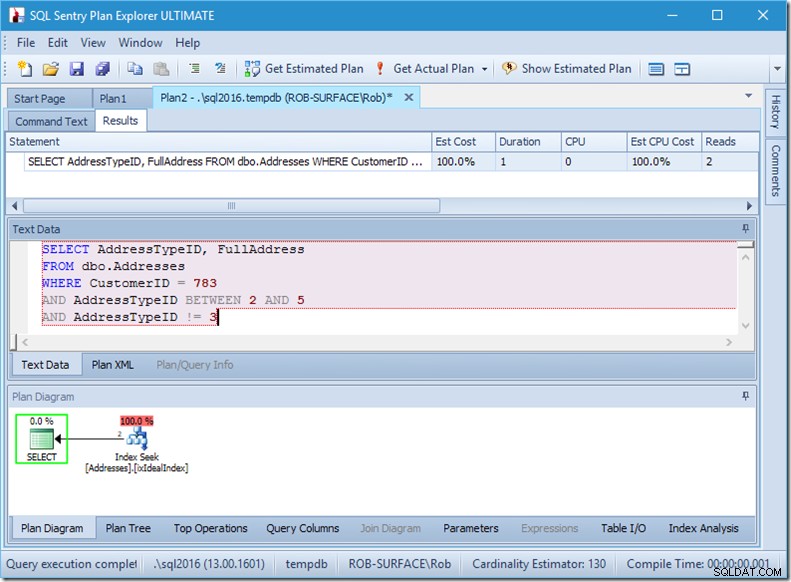
Ich kann Ihnen versichern, dass die Reihenfolge der Prädikate keine Rolle spielt, aber hier ist sie es eindeutig. Wenn wir „nicht 3“ an erster Stelle setzen, führt es zwei Suchvorgänge aus (4 Lesevorgänge), aber wenn wir „nicht 3“ an zweiter Stelle setzen, wird ein einzelner Suchvorgang ausgeführt (2 Lesevorgänge).
Das Problem ist, dass AddressTypeID !=3 in (AddressTypeID> 3 OR AddressTypeID <3) konvertiert wird, was dann als zwei sehr nützliche Suchprädikate angesehen wird.
Daher ziehe ich es vor, ein nicht-sargbares Prädikat zu verwenden, um ihm mitzuteilen, dass ich nur die Adresstypen 2, 4 und 5 möchte. Und das kann ich tun, indem ich AddressTypeID auf irgendeine Weise ändere, z. B. indem ich eine Null hinzufüge.
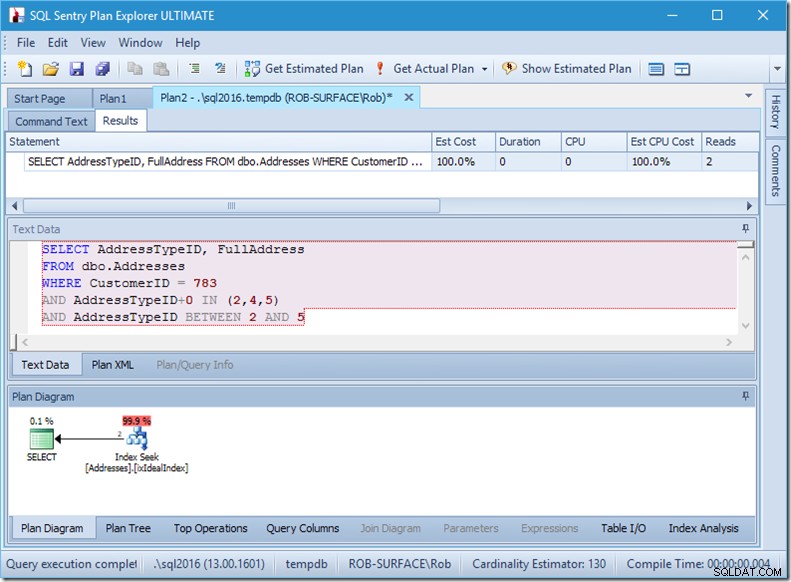
Jetzt habe ich einen netten und engen Bereichsscan innerhalb einer einzigen Suche, und ich stelle immer noch sicher, dass meine Abfrage nur die Zeilen zurückgibt, die ich will.
Oh, aber diese Eigenschaft „Actual Rows Read“? Das ist jetzt höher als die Eigenschaft Actual Rows, weil das Seek-Prädikat den Adresstyp 3 findet, den das Residual-Prädikat ablehnt.
Ich habe drei perfekte Suchvorgänge gegen einen einzigen unvollkommenen Suchvorgang eingetauscht, den ich mit einem Restprädikat korrigiere.
Und für mich ist das manchmal ein Preis, der es wert ist, bezahlt zu werden, um mir einen Abfrageplan zu verschaffen, über den ich viel glücklicher bin. Es ist nicht wesentlich billiger, obwohl es nur ein Drittel der Lesevorgänge hat (weil es immer nur zwei physische Lesevorgänge geben würde), aber wenn ich an die Arbeit denke, die es leistet, fühle ich mich viel wohler mit dem, was ich verlange auf diese Weise zu tun.